Command Palette
Search for a command to run...
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
Abstract
The landscape of high-performance image generation models is currently shifting from the inefficient multi-step ones to the efficient few-step counterparts (e.g, Z-Image-Turbo and FLUX.2-klein). However, these models present significant challenges for directly continuous supervised fine-tuning. For example, applying the commonly used fine-tuning technique would compromise their inherent few-step inference capability. To address this, we propose D-OPSD, a novel training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning. We first find that the modern diffusion model where the LLM/VLM serves as the encoder can inherit its encoder's in-context capabilities. This enables us to make the training as an on-policy self-distillation process. Specifically, during training, we make the model act as both the teacher and the student with different contexts, where the student is conditioned only on the text feature, while the teacher is conditioned on the multimodal feature of both the text prompt and the target image. Training minimizes the two predicted distributions over the student's own roll-outs. By optimizing on the model's own trajectory and under its own supervision, D-OPSD enables the model to learn new concepts, styles, etc., without sacrificing the original few-step capacity.
One-sentence Summary
The authors propose D-OPSD, a training paradigm for step-distilled diffusion models that enables continuous supervised fine-tuning via on-policy self-distillation by minimizing predicted distributions over the student's own roll-outs while conditioning the student on the text feature and the teacher on the multimodal feature of both the text prompt and the target image to preserve inherent few-step inference capability.
Key Contributions
- The paper introduces D-OPSD, a training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning.
- The framework utilizes the emergent in-context capabilities of modern encoders to facilitate self-distillation, where the model acts as both teacher and student under different multimodal and text-only conditions.
- Experiments across LoRA adaptation and full fine-tuning demonstrate that the method effectively learns new concepts and styles while preserving the original few-step generation ability.
Introduction
Text-to-image diffusion models have advanced significantly, yet their iterative sampling processes incur high computational costs that step-distillation techniques aim to mitigate. However, continually fine-tuning these efficient models poses significant challenges because conventional supervised fine-tuning disrupts learned few-step dynamics through a train-test mismatch. Online reinforcement learning offers a solution but demands reward functions that are often impractical for developers. The authors address these issues with D-OPSD, a novel on-policy self-distillation framework that leverages the emergent in-context capabilities of modern LLM-based encoders. By enabling the model to act as both a student and a teacher during training, this method allows for supervised adaptation on the model's own rollouts without external rewards. Consequently, new concepts are learned while preserving the original few-step inference capability.
Method
The authors propose D-OPSD, a training paradigm designed to enable on-policy learning for step-distilled diffusion models. This approach addresses the challenge where standard supervised fine-tuning compromises the inherent few-step inference capability of modern efficient models. The core idea leverages on-policy self-distillation, where the model acts as both a teacher and a student under different contextual conditions.
Refer to the framework diagram for a visual overview of the method.
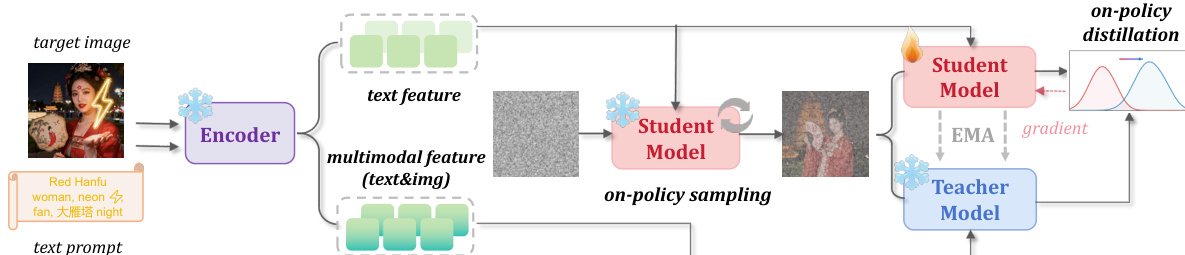
The process begins with an encoder that processes the input text prompt and the target image. For each training pair, the system constructs two distinct conditioning vectors. The student condition cs is derived solely from the text prompt, ensuring the student branch follows the original text-to-image generation pathway. In contrast, the teacher condition ct incorporates multimodal features from both the text prompt and the target image. This multimodal context allows the teacher to provide stronger supervision regarding the target concept or style without disrupting the student's sampling trajectory.
During training, the student model generates an on-policy trajectory by sampling from Gaussian noise using a few-step solver. Let xtks denote the latent state at step k. The student predicts the velocity field uks=vθ(xtks,tk,cs). Simultaneously, the teacher model, parameterized by an exponential moving average (EMA) of the student weights, predicts the velocity ukt=vθˉ(xtks,tk,ct) on the exact same states generated by the student. This setup ensures that the supervision is computed on the model's own trajectory rather than an external offline distribution.
The optimization objective minimizes the mean squared error between the student's velocity predictions and the teacher's predictions on these shared states. The loss function is formulated as:
LD-OPSD=E(x0,y)[K1k=1∑Kuks−sg(ukt)22]where sg(⋅) denotes the stop-gradient operation. By aligning the student's conditional generation dynamics with the teacher's stronger multimodal guidance, the model learns new concepts or styles while preserving the original few-step sampling behavior. After training, the teacher branch is discarded, and inference proceeds using the standard few-step pipeline conditioned only on text.
Experiment
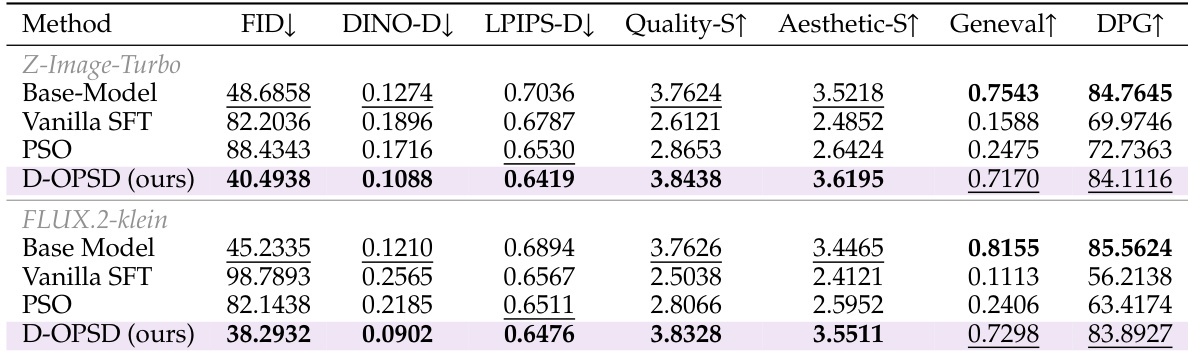
The evaluation utilizes Z-Image-Turbo and FLUX.2-klein models to compare the proposed method against baselines like Vanilla SFT and Dreambooth across small-scale LoRA and large-scale full finetuning scenarios. Experimental results demonstrate that while standard training approaches often compromise few-step generation quality or suffer from overfitting, the proposed method effectively learns new concepts and adapts to new domains without catastrophic forgetting. Furthermore, ablation studies validate that on-policy self-distillation is essential for maintaining high generation quality and achieving faster convergence compared to off-policy variants.
The authors compare the proposed D-OPSD method against baselines like Vanilla SFT and PSO across Z-Image-Turbo and FLUX.2-klein architectures. Results indicate that D-OPSD achieves superior alignment with target images while preserving the model's original few-step generation quality and general knowledge retention. In contrast, baseline methods suffer from significant degradation in image quality and capability retention. D-OPSD achieves lower error rates in image similarity metrics compared to Vanilla SFT and PSO. The proposed method preserves few-step sampling capacity with quality scores close to or exceeding the base model. Baseline methods exhibit significant drops in general knowledge benchmarks, whereas D-OPSD retains these capabilities.
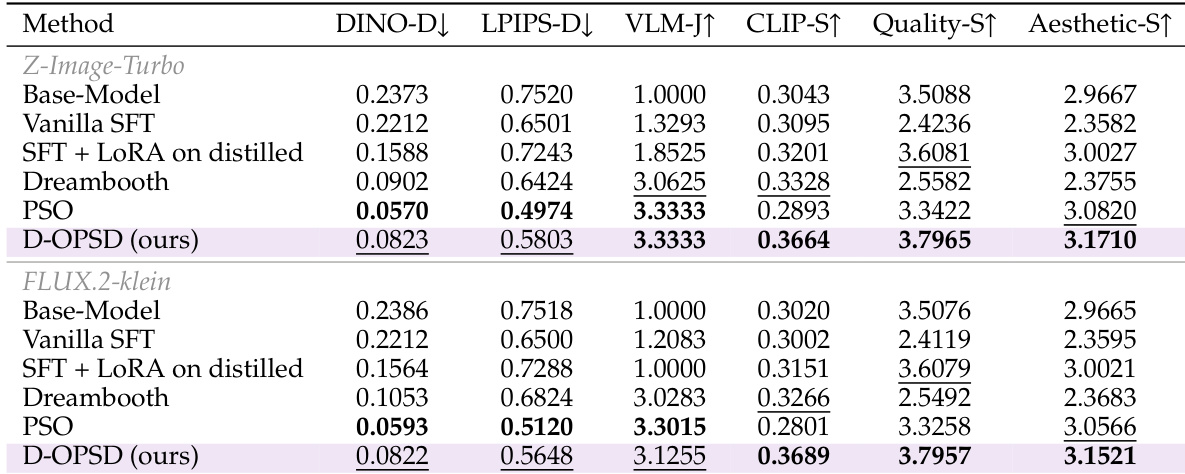
The authors compare their proposed D-OPSD method against several baselines including Vanilla SFT, Dreambooth, and PSO using Z-Image-Turbo and FLUX.2-klein models. The results demonstrate that D-OPSD effectively balances learning new concepts with maintaining high image quality and aesthetic standards, outperforming methods that degrade generation capabilities. D-OPSD achieves the highest Quality-S and Aesthetic-S scores in both model configurations, indicating it preserves few-step sampling capacity better than SFT and Dreambooth. The proposed method attains the highest CLIP-S scores and ties for the top VLM-J score, demonstrating strong generalization and subject consistency. While PSO achieves low distance metrics suggesting strong target alignment, D-OPSD avoids overfitting by maintaining significantly higher generalization and quality scores.
The the the table contrasts the proposed D-OPSD method with standard SFT, offline RL, and online RL baselines based on their supervision signals and training properties. It demonstrates that D-OPSD uniquely combines on-policy training with self-distilled velocity to ensure the training distribution matches the inference distribution without needing an external reward model. D-OPSD is the only method listed that achieves a match between training and inference conditions. The approach utilizes on-policy sampling with self-distilled velocity rather than ground truth or external rewards. Unlike online RL methods, D-OPSD does not require a separate reward model for supervision.

The authors evaluate D-OPSD against various baselines including Vanilla SFT and PSO across Z-Image-Turbo and FLUX.2-klein architectures to assess alignment and capability retention. Results indicate that the proposed method effectively balances learning new concepts with maintaining high image quality and general knowledge, whereas baseline methods suffer from significant degradation or overfitting. Additionally, the method uniquely aligns training and inference distributions through on-policy sampling without requiring external reward models.