Command Palette
Search for a command to run...
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Yaorui Shi Yuxin Chen Zhengxi Lu Yuchun Miao Shugui Liu Qi GU Xunliang Cai Xiang Wang An Zhang
Abstract
A persistent skill library allows language model agents to reuse successful strategies across tasks. Maintaining such a library requires three coupled capabilities. The agent selects a relevant skill, utilizes it during execution, and distills new skills from experience. Existing methods optimize these capabilities in isolation or with separate reward sources, resulting in partial and conflicting evolution. We propose Skill1, a framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective. The policy generates a query to search the skill library, re-ranks candidates to select one, solves the task conditioned on it, and distills a new skill from the trajectory. All learning derives from a single task-outcome signal. Its low-frequency trend credits selection and its high-frequency variation credits distillation. Experiments on ALFWorld and WebShop show that Skill1 outperforms prior skill-based and reinforcement learning baselines. Training dynamics confirm the co-evolution of the three capabilities, and ablations show that removing any credit signal degrades the evolution.
One-sentence Summary
Skill1 is a unified reinforcement learning framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective, leveraging frequency-based credit assignment to attribute low-frequency trends to selection and high-frequency variations to distillation, thereby outperforming prior baselines on ALFWorld and WebShop.
Key Contributions
- Skill1 introduces a unified framework that trains a single policy to co-evolve skill selection, utilization, and distillation toward a shared task-outcome objective. The method derives all learning from a single signal, attributing low-frequency trends to selection credit and high-frequency variations to distillation credit.
- Experiments on the ALFWorld and WebShop benchmarks demonstrate that the framework outperforms existing skill-based and reinforcement learning baselines.
- Training dynamics confirm the simultaneous co-evolution of the three capabilities, while ablation studies verify that removing either credit signal degrades the overall learning process.
Introduction
Large language model agents trained with reinforcement learning often treat each interaction as an isolated episode, causing them to discard successful strategies after a task concludes. Equipping these agents with a persistent skill library addresses this by enabling reusable knowledge transfer, which dramatically improves sample efficiency and long-term adaptability in complex interactive environments. Prior approaches typically optimize skill selection, utilization, and distillation as disjointed stages or rely on fragmented reward signals. This separation creates conflicting optimization pressures and leaves critical capabilities underdeveloped, ultimately bottlenecking agent evolution. The authors leverage a unified reinforcement learning framework called Skill1 that trains a single policy to co-evolve all three capabilities simultaneously. By decomposing a single task-outcome reward into low-frequency trends and high-frequency variations, the method assigns precise credit to skill selection and distillation without auxiliary signals, driving consistent joint improvement across the entire skill lifecycle.
Dataset
- Dataset Composition and Sources: The authors do not introduce or release any new datasets or scraped materials. The work relies entirely on existing open-source assets, explicitly citing Owen2.5 (distributed under the Apache 2.0 license).
- Subset Details: Rather than curating traditional training subsets, the pipeline utilizes prompt-driven evaluation and distillation components. One module processes WebShop shopping trajectories to generate structured JSON records containing task success flags, action lessons, navigation lessons, and general usage contexts. Another component maintains a library of retrieved agent skills, filtering historical interactions to extract optimal tool usage based on prior environmental reflections.
- Data Usage and Processing: The authors use these prompts and skill records to distill reasoning patterns and guide model decision-making. The provided documentation does not specify formal training splits or mixture ratios, as the approach emphasizes instruction distillation and trajectory evaluation over large-scale model training.
- Additional Processing Details: No cropping strategies or custom metadata construction are applied. Data handling centers on standardized JSON formatting for lesson extraction and contextual filtering of past agent interactions to ensure relevant skill retrieval.
Method
The authors introduce Skill1, a framework that trains a single policy πθ to co-evolve skill selection, utilization, and distillation through a unified task-outcome objective. The overall workflow proceeds in three sequential stages for each task x∼D: skill selection, skill utilization, and skill distillation, forming a complete trajectory τ=(q,z,a1,o1,…,aT,oT,snew). The framework operates within a partially observable Markov decision process (POMDP) M, where the agent's state S includes the task instruction x, the environment state e, and a persistent skill library B. The policy generates a natural-language query q to search the skill library B, which is then retrieved by a frozen encoder E to obtain the top-K candidates BK. The policy subsequently re-ranks these candidates, selecting the top skill z for utilization. During utilization, the policy interacts with the environment for up to T turns, generating action–observation pairs conditioned on the selected skill's strategy z.strat. After each rollout, the policy reflects on the trajectory to distill a new skill snew, consisting of a strategy and a scenario description, which is added to the library only if the task is successfully completed.
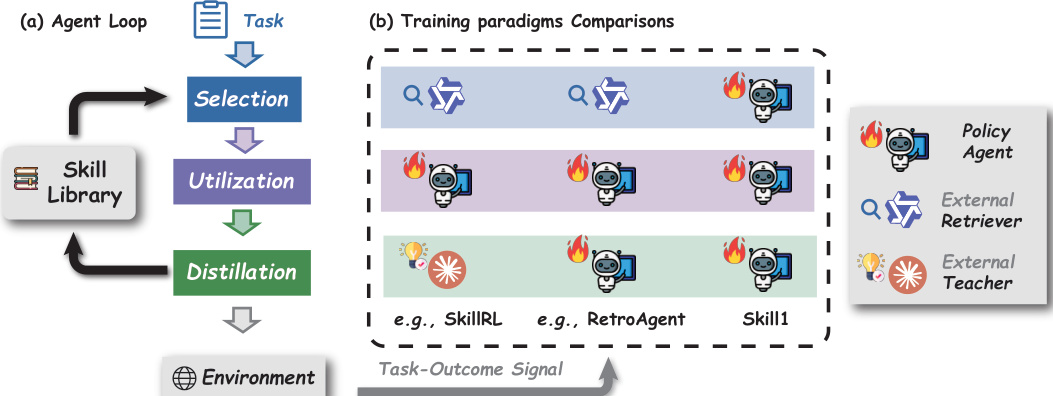
Refer to the framework diagram, which illustrates the three core stages of the agent loop. The selection stage begins with a task and a query generator that produces a search query to retrieve relevant skills from the library. The retrieved skills are re-ranked by a re-ranker, and the top skill is selected for utilization. The utilization stage involves the policy agent interacting with the environment, conditioned on the selected skill's strategy, producing multiple rollouts. Finally, the distillation stage involves the policy reflecting on successful trajectories to generate a new skill, which is added to the skill library. The policy agent is depicted as the central component, interacting with the external retriever and external teacher, with the task-outcome signal driving the co-evolution of all three capabilities.
The training process leverages a single policy πθ to generate all components of the trajectory, including the selection query, the re-ranking permutation, the action sequence, and the distilled skill. Each segment is optimized jointly in a single gradient step using Group Relative Policy Optimization (GRPO), which computes advantages relative to a group of rollouts sampled from the same task. The utilization reward Riutil is directly set to the task outcome r(τi), providing a direct signal for action generation. The selection process is optimized through two mechanisms: the query generation receives policy gradients via the utilization objective, as better queries lead to higher task outcomes, and the re-ranking is explicitly supervised using a normalized discounted cumulative gain (NDCG) metric that rewards the policy for producing a permutation agreeing with the utility ordering of retrieved skills. The utility score U(s) for each skill is updated via an exponential moving average after each rollout, capturing the long-term trend of its performance. The distillation reward Ridistill is derived from the variation of the current outcome relative to the library's trend, defined as r(τi)−U^i, where U^i is the highest trend among the retrieved candidates. This signal encourages the policy to distill skills that improve upon existing library coverage. The total optimization objective combines these three components: I(θ)=Iutil(θ)+λ1Irerank(θ)+λ2Idistill(θ), with separate advantage normalization for utilization and distillation rewards.
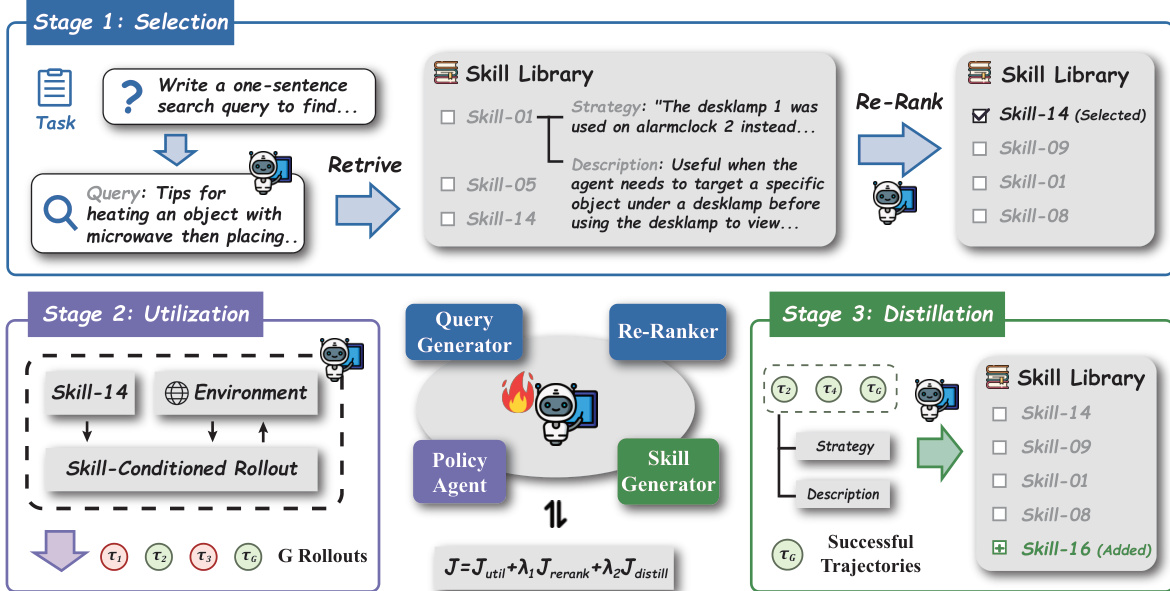
As shown in the figure below, the process begins with the selection stage, where the policy generates a query to retrieve skills from the library. The retrieved skills are then re-ranked, and the top skill is selected. The selected skill is then used in the utilization stage, where the policy interacts with the environment, generating multiple rollouts. The distillation stage involves the policy reflecting on successful trajectories to generate a new skill, which is added to the skill library. The policy agent is the central component, interacting with the external retriever and external teacher, with the task-outcome signal driving the co-evolution of all three capabilities. The figure illustrates the three stages of the agent loop, highlighting the interaction between the policy agent, the skill library, and the environment.
Experiment
Evaluated on the ALFWorld and WebShop environments, the experiments benchmark the proposed Skill1 method against training-free agents and reinforcement learning baselines that either lack skills or optimize skill management in fragmented ways. Ablation and co-evolution analyses validate that jointly optimizing skill selection, utilization, and distillation creates a mutually reinforcing cycle that significantly improves performance and training stability compared to isolated or parameter-only approaches. Qualitatively, this unified framework enables the agent to generate more precise selection queries, distill higher-quality and more diverse strategies, and effectively leverage reusable skills for failure avoidance and error correction. Ultimately, the results demonstrate that explicit, co-evolved skill libraries substantially enhance multi-step planning and execution capabilities beyond what implicit parameter learning or static skill management can achieve.
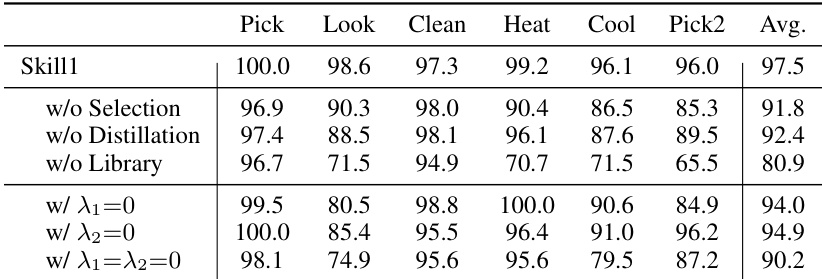
The authors present an experiment comparing their method Skill1 against various baselines on two environments, ALFWorld and WebShop, focusing on success rates. Skill1 achieves the highest performance in both environments, outperforming the previous best method RetroAgent and demonstrating the benefits of a unified optimization framework that co-evolves skill selection, utilization, and distillation. The results show that an explicit skill library and the joint optimization of all stages are crucial for high performance and robustness. Skill1 achieves the highest success rates on both ALFWorld and WebShop, surpassing previous best methods. The performance gain is attributed to the joint optimization of skill selection, utilization, and distillation, which enables mutual reinforcement across stages. An explicit skill library is essential, as removing it causes a significant drop in performance, particularly on complex tasks requiring multi-step planning.

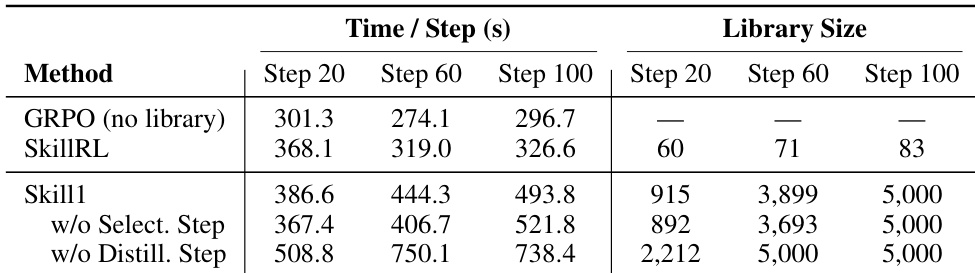
The authors compare the computational efficiency of Skill1 against baseline methods and ablations, focusing on wall-clock time per step and skill library size across training steps. Results show that Skill1 incurs higher computational cost than GRPO due to growing library context, with the largest increase observed when both selection and distillation are disabled. The skill library size grows rapidly in the absence of distillation, leading to significant slowdowns. Skill1 maintains a controlled library size through distillation, balancing performance and efficiency. Skill1 has higher computational cost than GRPO due to growing library context, with the largest increase when both selection and distillation are disabled. The absence of distillation causes rapid library growth, leading to significant slowdowns and early saturation of the skill capacity. Skill1 maintains a controlled library size through distillation, balancing performance and computational efficiency.
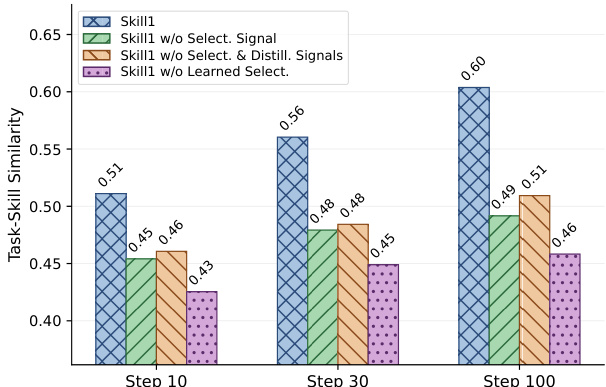
The authors analyze the co-evolution of skill selection, utilization, and distillation in their framework by tracking task-skill similarity across training steps. Results show that the full system achieves higher similarity compared to ablations that remove selection or distillation signals, indicating that unified training improves the policy's ability to generate precise selection queries. The trend suggests mutual reinforcement among the three capabilities, with improvements in one stage accelerating progress in the others. The full system achieves higher task-skill similarity than ablations that remove selection or distillation signals. Task-skill similarity increases over time, with the full system showing the most significant improvement. Removing selection signals slows the learning of precise selection queries, while removing distillation signals reduces the effectiveness of skill retrieval.
The authors evaluate their method, Skill1, on two environments, ALFWorld and WebShop, comparing it against various baselines including training-free agents, RL-trained methods without skills, and RL-trained methods with skills. Skill1 achieves the highest performance across both environments, particularly excelling in tasks requiring multi-step planning and object interaction. The results demonstrate that a unified optimization framework for skill selection, utilization, and distillation leads to superior performance compared to methods that optimize these components separately or not at all. Skill1 achieves the highest success rate on both ALFWorld and WebShop, outperforming all baseline methods. The inclusion of a skill library significantly boosts performance, with the largest gains observed on tasks requiring multi-step sub-procedure composition. Unified optimization of skill selection, utilization, and distillation leads to better performance compared to methods that optimize these stages separately or leave parts of the lifecycle unoptimized.
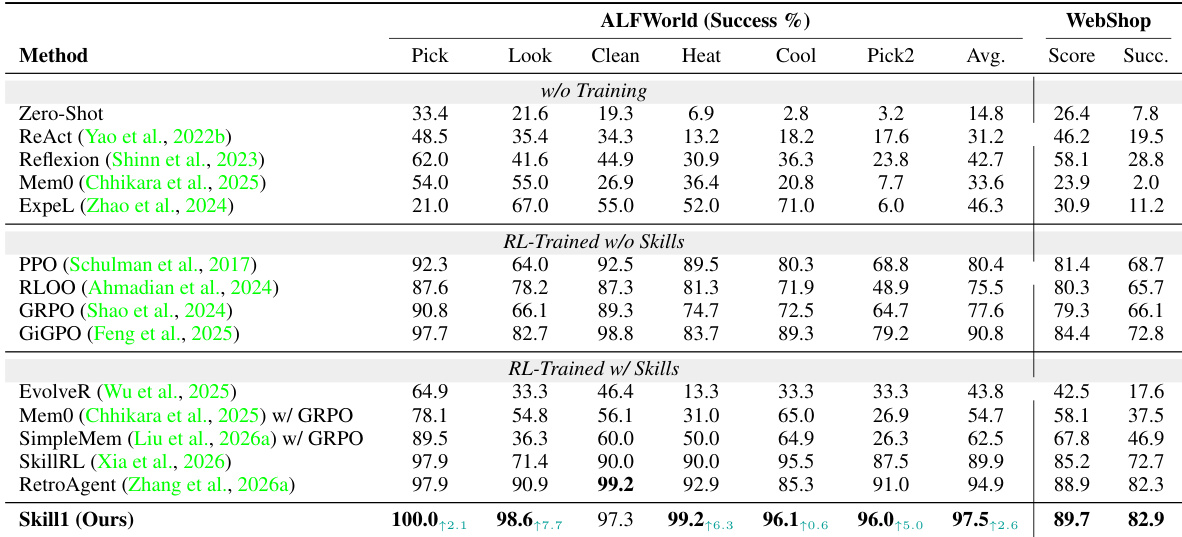
The authors evaluate their method, Skill1, on two environments and compare it against various baselines. Results show that Skill1 achieves the highest overall performance, particularly on tasks requiring multi-step planning and object interaction. The ablation study demonstrates that the skill library and the unified optimization of selection and distillation are critical for achieving high performance and efficient skill management. Skill1 achieves the highest success rates across all tasks and environments compared to all baselines. The skill library is essential for performance, with its removal causing the largest drop in success rates. Unified optimization of selection and distillation leads to faster convergence and better skill management compared to methods that optimize stages separately or not at all.
Evaluated across the ALFWorld and WebShop environments against multiple baselines, the experiments validate that Skill1 achieves superior task success rates while maintaining computational efficiency through controlled skill library management. Ablation studies and co-evolution tracking demonstrate that explicitly maintaining a skill library and jointly optimizing skill selection, utilization, and distillation are essential for robust performance, particularly in complex multi-step planning scenarios. The results confirm that this unified framework fosters mutual reinforcement across all stages, enabling precise query generation and efficient knowledge distillation without incurring excessive computational overhead.