Command Palette
Search for a command to run...
When to Trust Imagination: Adaptive Action Execution for World Action Models
When to Trust Imagination: Adaptive Action Execution for World Action Models
Rui Wang Yue Zhang Jiehong Lin Kuncheng Luo Jianan Wang Zhongrui Wang Xiaojuan Qi
Abstract
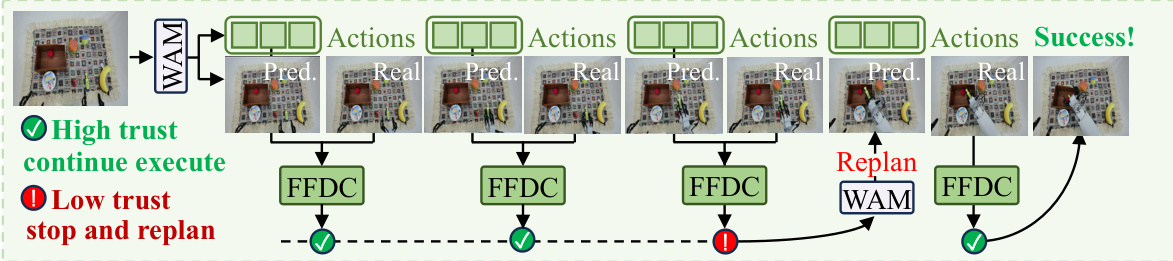
World Action Models (WAMs) have recently emerged as a promising paradigm for robotic manipulation by jointly predicting future visual observations and future actions. However, current WAMs typically execute a fixed number of predicted actions after each model inference, leaving the robot blind to whether the imagined future remains consistent with the actual physical rollout. In this work, we formulate adaptive WAM execution as a future-reality verification problem: the robot should execute longer when the WAM-predicted future remains reliable, and replan earlier when reality deviates from imagination. To this end, we propose Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to estimate whether the remaining action rollout can still be trusted. FFDC enables adaptive action chunk sizes as an emergent consequence of prediction-observation consistency, preserving the efficiency of long-horizon execution while restoring responsiveness in contact-rich or difficult phases. We further introduce Mixture-of-Horizon Training to improve long-horizon trajectory coverage for adaptive execution. Experiments on the RoboTwin benchmark and in the real world demonstrate that our method achieves a strong robustness-efficiency trade-off: on RoboTwin, it reduces WAM forward passes by 69.10% and execution time by 34.02%, while improving success rate by 2.54% over the short-chunk baseline; in real-world experiments, it improves success rate by 35%.
One-sentence Summary
This work introduces an adaptive execution framework for World Action Models that replaces fixed rollouts with Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier assessing prediction-observation consistency to dynamically adjust action chunk sizes, thereby preserving long-horizon efficiency while enabling early replanning during contact-rich phases through Mixture-of-Horizon Training.
Key Contributions
- This work formulates adaptive World Action Model execution as a future-reality verification problem and introduces Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to dynamically adjust action chunk sizes based on prediction-observation consistency.
- To support this adaptive execution paradigm, the framework incorporates Mixture-of-Horizon Training, a training objective that improves long-horizon trajectory coverage and sustains reliable consistency signals across varying temporal scales.
- Empirical evaluations demonstrate that the proposed approach achieves higher task success rates and significantly reduces completion times compared to fixed-chunk baselines, establishing execution length as an emergent consequence of future-reality verification rather than a manually tuned hyperparameter.
Introduction
World Action Models have emerged as a powerful framework for robotic manipulation by jointly forecasting future visual states and action sequences, which significantly improves policy generalization across diverse physical tasks. However, current implementations rely on fixed action chunks per inference, making them computationally wasteful in predictable scenarios and highly vulnerable to failure during complex or contact-heavy interactions. Prior adaptive execution methods also fall short because they depend on action uncertainty or policy confidence rather than leveraging the model's inherent capacity to predict visual dynamics for self-verification. To address this, the authors introduce Future Forward Dynamics Causal Attention, a lightweight verifier that continuously aligns predicted visual trajectories with real-time observations and task instructions. This mechanism dynamically adjusts execution length based on prediction-reality consistency, allowing the robot to safely extend action rollouts during stable phases and trigger early replanning when deviations occur.
Method
The authors leverage a framework called FFDC-WAM, which integrates low-frequency macro planning with high-frequency lightweight verification to enable efficient adaptive action execution by exploiting the joint video-action modeling capability of World Action Models (WAMs). The core of this framework is a modular design that separates long-horizon planning from real-time trust assessment, allowing the system to dynamically decide whether to continue executing a predicted action sequence or to replan based on current environmental feedback.
At the heart of the system is a WAM that jointly predicts future actions and visual observations conditioned on the current observation and a language instruction. During inference, the WAM generates a future action chunk and corresponding latent visual tokens. Standard action chunking executes these predictions in an open-loop manner, which can accumulate errors in dynamic environments. To address this, FFDC-WAM introduces a lightweight verifier, FFDC, that continuously assesses the reliability of the remaining predicted rollout.
Refer to the framework diagram. The overall architecture consists of a WAM that produces a predicted action sequence and latent visual tokens. At each check step t, the FFDC verifier evaluates the current state by taking as input the latest real observation Ot, the language instruction L, the historical and future predicted visual tokens O^tp and O^tf, the future action segment A^t, and a learnable [CLS] token. These inputs are structured into a sequence Xt that serves as the input to the verifier.

As shown in the figure below, the FFDC verifier is implemented as an N-layer Transformer. A key component is the structured causal attention mechanism, which enforces temporally aligned interactions between predicted actions and visual dynamics. The attention mask ensures that future visual tokens only attend to past and future visual tokens up to the same timestep, and future action tokens only attend to future visual tokens and actions up to the same timestep. This design preserves temporal causality, prevents information leakage, and maintains efficiency. To further reduce computation, the attention is applied within a local window over temporally ordered future tokens. The [CLS] token aggregates the entire visible sequence into a compact representation, which is then passed through a multi-layer perceptron (MLP) head to produce a confidence score et.
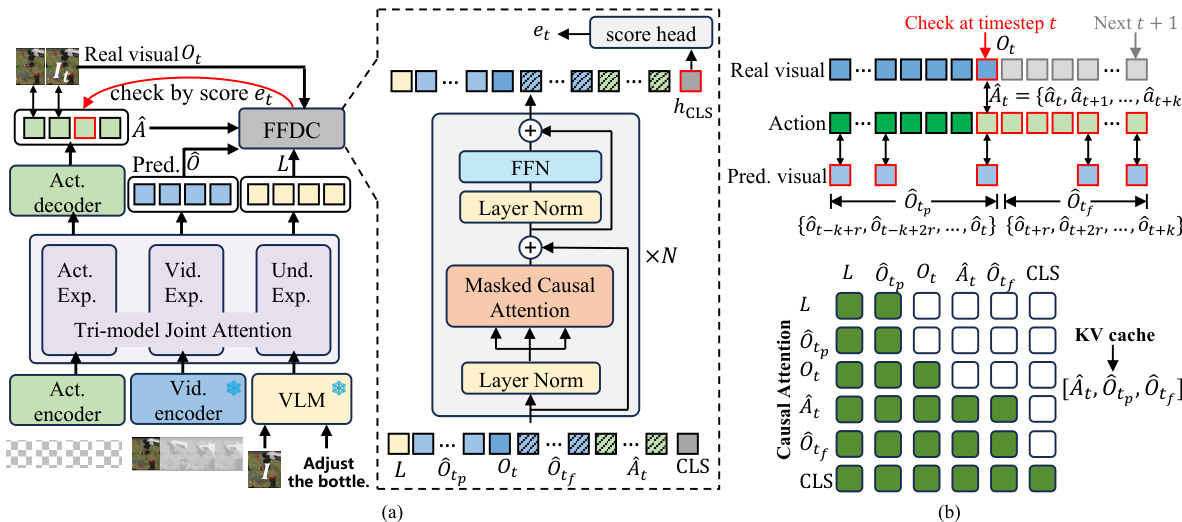
The training strategy for the WAM involves a mixture-of-horizon sampling approach, where conditioning timesteps are uniformly sampled across an episode to improve trajectory coverage for long-horizon inference. For the FFDC verifier, a binary classification task is formulated, where the goal is to predict whether a future action segment is executable. The training dataset is constructed from successful demonstrations, failed rollouts, and synthetically corrupted segments generated through data augmentation techniques such as temporal swapping, gripper flipping, and late-stage noise injection. The verifier is trained using a binary cross-entropy loss to learn the distinction between valid and invalid action sequences.
Experiment
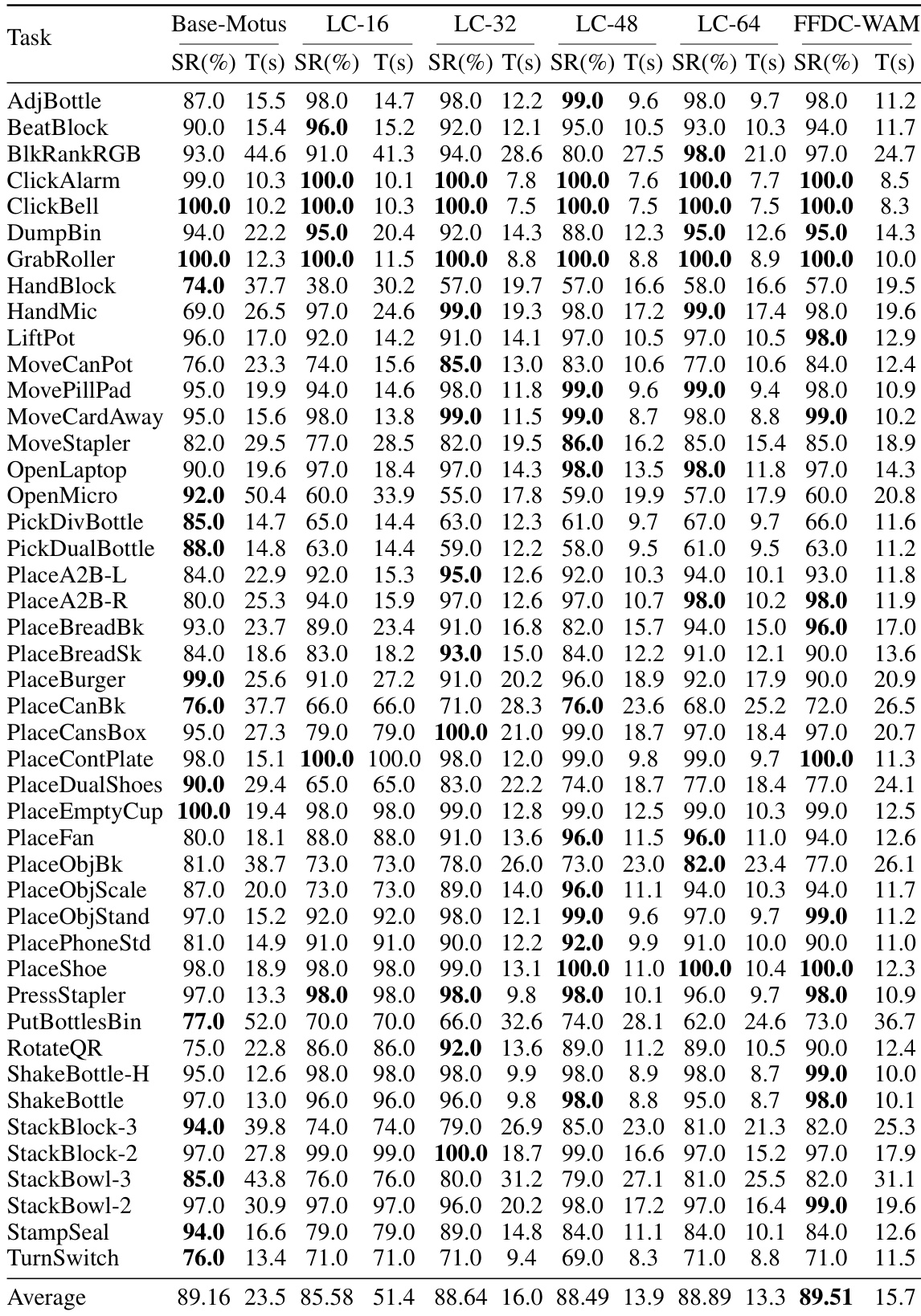
Evaluated in the RoboTwin simulator across fifty tasks under clean and perturbed conditions, as well as in real-world pick-and-place trials, the experiments validate the system's ability to balance efficiency and robustness through adaptive execution. The simulation results demonstrate that the verifier dynamically adjusts inference frequency based on predicted future-reality consistency, reducing unnecessary computations on straightforward tasks while triggering timely replanning during complex phases to prevent open-loop failures. Real-world testing further confirms that this online verification effectively counters perception noise and actuation drift, substantially improving task success compared to fixed-horizon baselines. Finally, an ablation study validates that jointly modeling predicted visuals, real observations, action rollouts, and language instructions is essential, with imagined future observations proving to be the most critical signal for reliable confidence estimation.
The authors evaluate their proposed FFDC-WAM method against several baselines on a set of manipulation tasks in simulation and real-world settings. Results show that FFDC-WAM achieves the highest success rate and improves efficiency by adaptively adjusting the frequency of model inferences based on task difficulty and prediction reliability. The method demonstrates robust performance on both easy and hard tasks, with significant improvements over baseline models in terms of success rate and execution time. In real-world experiments, FFDC-WAM outperforms fixed-chunk baselines by detecting execution drift and triggering replanning when needed. Ablation studies confirm that all components of FFDC contribute to its performance, particularly the predicted visual tokens and real observation for confidence estimation. FFDC-WAM achieves the highest success rate and best balance between robustness and efficiency compared to baselines. The method adaptively reduces model calls on easy tasks and increases them on hard tasks based on prediction reliability. Ablation studies show that predicted visual tokens and real observations are most critical for reliable confidence estimation.
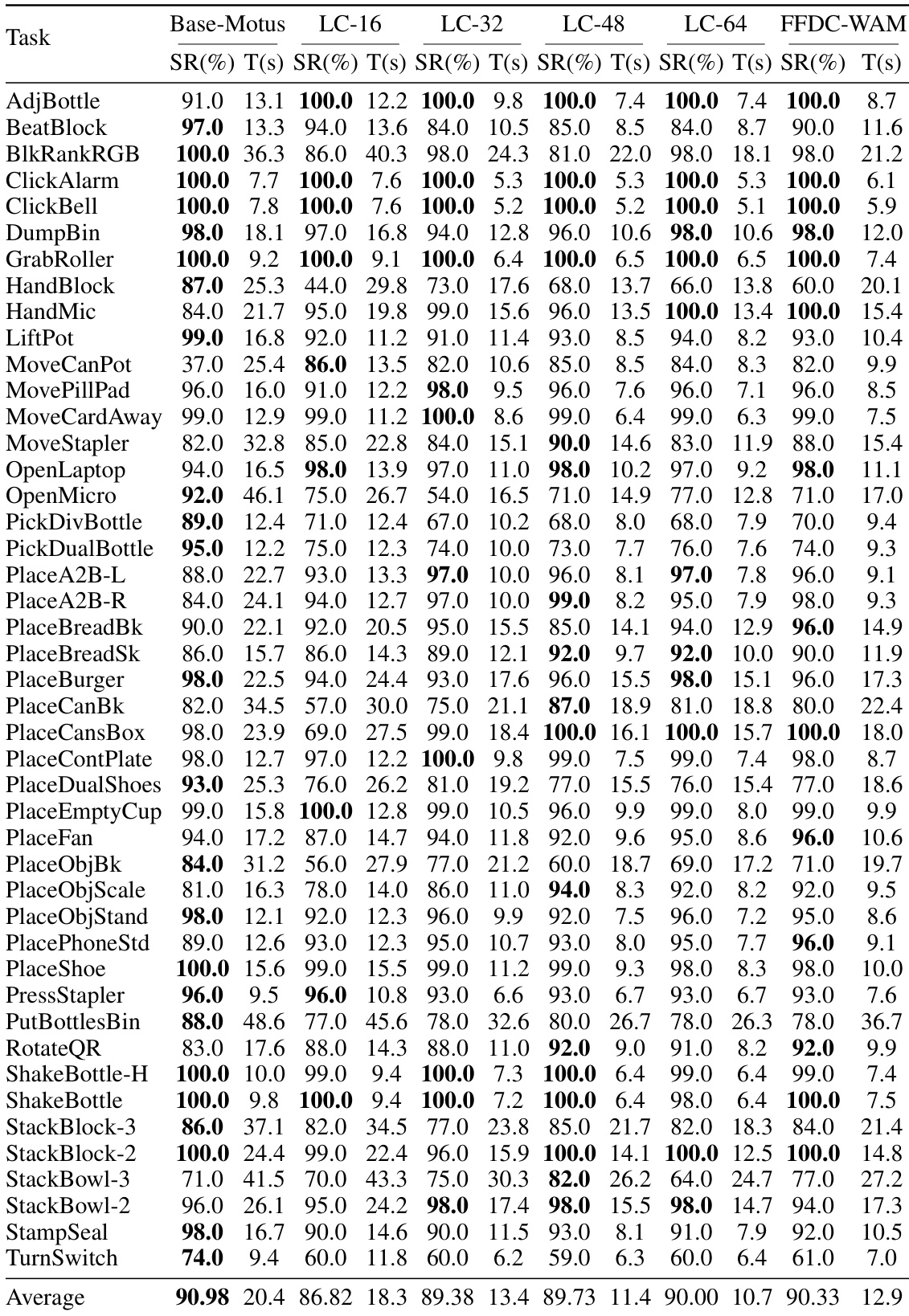
The authors evaluate their proposed FFDC-WAM method against several baselines on a set of manipulation tasks in simulation and real-world settings. Results show that FFDC-WAM achieves higher success rates and faster completion times compared to the base model, while also reducing the number of model inferences needed. The method adapts its execution strategy based on task difficulty, using fewer inferences on easy tasks and more on hard ones, demonstrating improved robustness and efficiency. In real-world experiments, FFDC-WAM outperforms a fixed long-chunk baseline by better detecting execution drift and triggering replanning when necessary. FFDC-WAM achieves higher success rates and faster task completion times compared to the base model in both simulation and real-world settings. The method reduces the number of model inferences by adapting execution frequency based on task difficulty, improving efficiency without sacrificing robustness. FFDC-WAM outperforms a fixed long-chunk baseline in real-world tasks by detecting execution drift and triggering replanning to avoid failure.
The authors evaluate their method on real-world pick-and-place tasks, comparing it against a baseline that uses fixed long-chunk execution. Results show that their approach achieves higher success rates on both tasks while maintaining comparable execution times and slightly increasing the number of model calls. This indicates that the method improves robustness through online verification, even if it requires more frequent replanning in uncertain real-world conditions. FFDC-WAM achieves higher success rates on both real-world tasks compared to the baseline. FFDC-WAM has slightly longer execution times and more model calls than the baseline, indicating increased online verification. The method maintains robustness in the presence of real-world uncertainties by triggering replanning when needed.
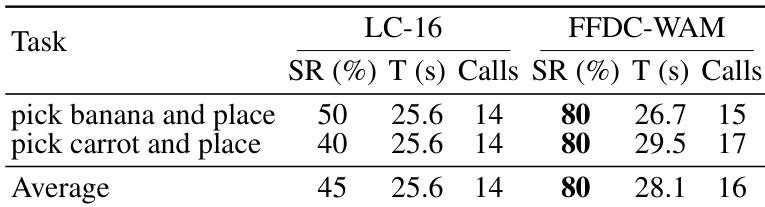
The authors evaluate their FFDC-WAM method on a set of manipulation tasks in simulation and real-world settings, comparing it against baseline models that use fixed chunk sizes or lack adaptive verification. Results show that FFDC-WAM achieves higher success rates and faster completion times by dynamically adjusting inference frequency based on confidence in predicted future states, while also demonstrating robustness in handling real-world uncertainty. The ablation study confirms that all components of the FFDC verifier contribute to performance, with predicted visual tokens and real observations being particularly important for reliable confidence estimation. FFDC-WAM improves success rates and reduces execution time by adaptively adjusting inference frequency based on prediction reliability. The method shows significant gains on hard tasks in simulation and real-world settings, outperforming fixed-chunk baselines that either sacrifice robustness or efficiency. Ablation results indicate that predicted visual tokens and real observations are critical inputs for accurate confidence estimation in the verifier.
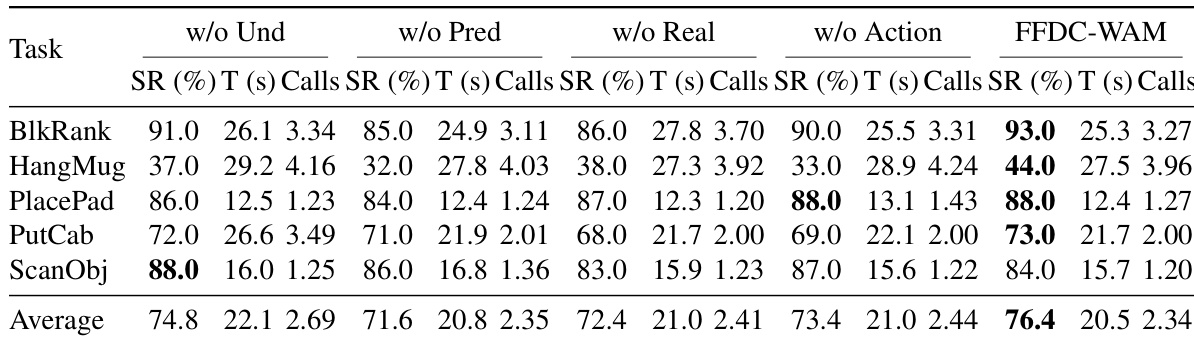
The authors evaluate their proposed FFDC-WAM method against several baselines on a set of manipulation tasks in simulation, focusing on success rate and execution time. Results show that FFDC-WAM achieves the highest average success rate and improved efficiency by adaptively adjusting inference frequency based on task difficulty and prediction reliability. In real-world experiments, FFDC-WAM outperforms a long-chunk baseline by significantly improving success rates through online verification and replanning when execution drift is detected. FFDC-WAM achieves the highest average success rate and improved efficiency by adapting inference frequency to task difficulty and prediction reliability. On hard tasks, FFDC-WAM substantially improves robustness over the baseline while maintaining high success rates on easy tasks. In real-world settings, FFDC-WAM improves success rates by detecting execution drift and triggering replanning, leading to better performance despite higher computation cost.
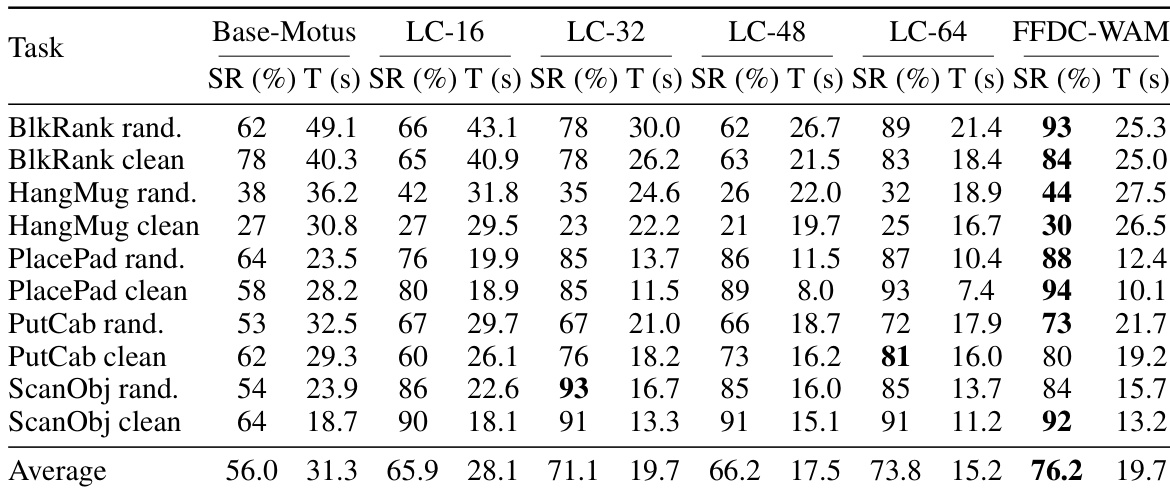
The proposed FFDC-WAM method is evaluated on manipulation tasks across both simulation and real-world environments, where it is compared against fixed-chunk and base model baselines. By dynamically adjusting inference frequency according to task difficulty and prediction reliability, the approach consistently achieves higher success rates and greater efficiency, particularly on challenging tasks and in uncertain real-world conditions. The method effectively detects execution drift and triggers necessary replanning, demonstrating a strong balance between robustness and computational efficiency. Ablation studies further confirm that the combination of predicted visual tokens and real observations is critical for reliable confidence estimation, validating the overall design.