Command Palette
Search for a command to run...
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
Guankai Li Jiabin Chen Yi Xu Xichen Zhang Yuan Lu
Abstract
Existing multimodal search agents process target entities sequentially, issuing one tool call per entity and accumulating redundant interaction rounds whenever a query decomposes into independent sub-retrievals. We argue that effective multimodal agents should search wider rather than longer: dispatching multiple grounded queries concurrently within a round. To this end, we present HyperEyes, a parallel multimodal search agent that fuses visual grounding and retrieval into a single atomic action, enabling concurrent search across multiple entities while treating inference efficiency as a first-class training objective. HyperEyes is trained in two stages. For cold-start supervision, we develop a Parallel-Amenable Data Synthesis Pipeline covering visual multi-entity and textual multi-constraint queries, curating efficiency-oriented trajectories via Progressive Rejection Sampling. Building on this, our central contribution, a Dual-Grained Efficiency-Aware Reinforcement Learning framework, operates at two levels. At the macro level, we propose TRACE (Tool-use Reference-Adaptive Cost Efficiency), a trajectory-level reward whose reference is monotonically tightened during training to suppress superfluous tool calls without restricting genuine multi-hop search. At the micro level, we adapt On-Policy Distillation to inject dense token-level corrective signals from an external teacher on failed rollouts, mitigating the credit-assignment deficiency of sparse outcome rewards. Since existing benchmarks evaluate accuracy as the sole metric, omitting inference cost, we introduce IMEB, a human-curated benchmark of 300 instances that jointly evaluates search capability and efficiency. Across six benchmarks, HyperEyes-30B surpasses the strongest comparable open-source agent by 9.9% in accuracy with 5.3x fewer tool-call rounds on average.
One-sentence Summary
HyperEyes is a parallel multimodal search agent that replaces sequential entity processing with concurrent multi-entity retrieval by fusing visual grounding and retrieval into a single atomic action, utilizing a Parallel-Amenable Data Synthesis Pipeline with Progressive Rejection Sampling and a Dual-Grained Efficiency-Aware Reinforcement Learning framework to reduce redundant interaction rounds for decomposable queries.
Key Contributions
- Introduces HyperEyes, a parallel multimodal search agent that fuses visual grounding and retrieval into a single atomic action to execute concurrent multi-entity queries.
- Establishes a two-stage training protocol that utilizes a Parallel-Amenable Data Synthesis Pipeline and Progressive Rejection Sampling for cold-start supervision, followed by a Dual-Grained Efficiency-Aware Reinforcement Learning framework to penalize redundant tool invocations.
- Demonstrates through evaluations on FVQA, MMSearch-Plus, and BrowseComp-VL that the parallel architecture significantly reduces end-to-end inference latency and token consumption while preserving retrieval accuracy compared to sequential methods.
Introduction
Multimodal search agents are essential for overcoming the static knowledge cutoffs of large language models by actively retrieving real-time information, yet their practical deployment is constrained by high latency and excessive inference costs. Prior frameworks predominantly rely on sequential tool invocations, which generate severe interaction redundancy when queries naturally decompose into independent sub-retrievals. Even when parallel capabilities exist, accuracy-focused training objectives inadvertently incentivize verbose over-searching instead of compact, efficient trajectories. To resolve these bottlenecks, the authors introduce HyperEyes, a parallel multimodal search agent that fuses visual grounding and retrieval into a single atomic action to process multiple entities concurrently. They optimize the system using a dual-grained reinforcement learning framework that dynamically tightens trajectory-level efficiency rewards and injects dense token-level corrective signals to resolve sparse reward credit assignment. The authors also release IMEB, a human-curated benchmark that jointly measures answer accuracy and search efficiency, demonstrating that their approach achieves state-of-the-art accuracy while reducing tool-call rounds by more than fivefold.
Dataset
-
Dataset Composition and Sources
- The authors construct a training corpus of 271,000 tool-dependent queries designed to enforce parallel tool invocation and efficiency-aware optimization.
- The foundational pool aggregates 246,000 multi-hop reasoning and visual recognition queries from public benchmarks and internal human annotations.
- The authors supplement this collection with 25,000 novel synthetic queries generated via two bespoke pipelines: 20,000 visual multi-entity QA pairs and 5,000 textual multi-constraint queries.
- A unified tool-necessity filter discards any QA pair that Qwen3-VL-235B resolves without external tool access, ensuring all retained data genuinely requires retrieval.
-
Key Subset Details
- Visual Multi-Entity: Derived from fine-grained classification datasets including CUB-200-2011, Oxford Flowers-102, Stanford Cars, FGVC-Aircraft, and Oxford-IIIIT Pets. The pipeline constructs per-class knowledge bases and uses mosaic augmentation to composite images from 2 to 8 distinct classes. QA pairs require integrating information across co-occurring entities, ensuring omitting any entity prevents correct deduction.
- Textual Multi-Constraint: Sourced from Wikidata using multi-hop random walks to collect candidate entities. The authors sample two or more predicates whose intersection defines a unique ground-truth set, creating queries that satisfy multiple independent attribute constraints.
- IMEB Benchmark: A dedicated evaluation set of 300 instances curated by PhD-level annotators with an average of 4.6 entities per image. The benchmark undergoes double-blind cross-validation to guarantee unambiguous solvability and strict necessity for concurrent tool invocation.
-
Usage, Splits, and Processing
- SFT Dataset: The authors distill the 271,000 initial queries into 30,000 high-fidelity trajectories for Supervised Fine-Tuning.
- Progressive Rejection Sampling: The authors apply this technique using Gemini-3.0-Flash as the policy model. The method samples trajectories across ascending turn budgets and retains the shortest successful trajectory for each query, promoting single-turn precision and parallel execution.
- Difficulty Filtering: Before sampling, the authors filter out trivial queries that Qwen3-VL-235B resolves in a single pass, retaining only challenging samples that demand rigorous multi-step or parallel planning.
- Quality Filtering: Post-sampling filtering removes trajectories with format violations, zero information gain, ungrounded reasoning, unimodal shortcuts, or inefficient sequential querying.
- RL Dataset: The authors isolate medium-difficulty samples for Reinforcement Learning, selecting 6,056 queries for the 30B model and 9,337 queries for the 235B model where the initial model fails under pass@1 but succeeds under pass@5 constraints. These samples establish dynamic efficiency boundaries for the reward mechanism.
-
Cropping Strategy and Metadata Construction
- Mosaic Layouts: The visual synthesis employs layouts such as 2x1, 1x4, and 2x4 to assemble composite images from selected classes.
- Spatial Metadata: The pipeline provides spatial position references for each target entity, such as "top-left" or grid coordinates, to the question synthesizer to fuse spatial references with knowledge content.
- Unified Grounded Search: The data supports a grounded search mechanism where the model specifies area coordinates for concurrent localization, as evidenced by examples using coordinate arrays for cropping regions.
- Knowledge Base Construction: For visual queries, the authors consolidate structured knowledge entries covering visual characteristics, taxonomic identifiers, and behavioral traits per class, which the model must retrieve and fuse with spatial references.
Method
The HyperEyes framework operates as an iterative reasoning-and-acting agent that follows the ReAct paradigm, producing a trajectory τ=(q,(r0,a0,o0),(r1,a1,o1),ldots,(rT,aT,oT),y) for a given query q. At each turn t, the agent generates a reasoning trace rt conditioned on the accumulated context ht, selects a tool call at from the available multimodal search tools, and receives an observation ot from the retrieval environment. This process continues until a final answer y is produced or the maximum allowed number of turns T is reached.
The agent is equipped with two primary tools: a text search tool, invoked via <text_search>, which retrieves textual evidence for natural language queries, and an image search tool, invoked via <image_search>, which retrieves visually relevant results for grounded visual inputs. To enable efficient interaction with the real-world internet, the framework introduces Unified Grounded Search (UGS), which reformulates visual grounding as a parameter of the retrieval action. This allows the policy to dispatch parallel search queries across modalities within a single turn by simultaneously predicting bounding boxes for all target entities, thereby eliminating the brittle dependencies and sequential bottlenecks of traditional two-stage "crop-then-search" pipelines.
The training process consists of two main phases. The first phase is a Parallel-Amenable Data Synthesis pipeline that constructs multi-entity QA pairs and curates efficient trajectories. This phase begins with diverse classes and information gathering, including web search and image augmentation, to generate QA pairs. The trajectories are then curated through progressive rejection sampling, where the need for search is evaluated and trajectories are filtered for efficiency. The second phase is a Dual-Grained Efficiency-Aware RL algorithm that optimizes parallel search behavior. This algorithm employs a macro-level reward and a micro-level correction signal.
The training proceeds in two stages. First, a Supervised Fine-Tuning (SFT) phase optimizes the base multimodal language model (MLLM) via next-token prediction on the curated trajectory corpus. This phase instills basic parallel retrieval behaviors by directly internalizing one-shot parallel dispatch, bypassing the need to learn iterative query reformulation. However, this approach lacks sequence-level optimization for end-to-end inference efficiency. To address this, a Reinforcement Learning (RL) stage is employed, which uses a Dual-Grained Efficiency-Aware RL framework. This framework combines a macro-level reward, Group Relative Policy Optimization (GRPO) with a novel Reference-Adaptive Cost Efficiency (TRACE) reward, to explicitly optimize tool-use efficiency, and a micro-level signal, On-Policy Distillation (OPD), to provide dense token-level corrective signals.

The TRACE reward is designed to adapt to query-specific efficiency targets. It is composed of three components: R=Racc+Rfmt+Rtool, where Racc is a binary correctness judge, Rfmt penalizes schema parsing failures, and Rtool is the core adaptive efficiency reward. The efficiency is characterized by the number of tool-call rounds tc and the total number of tool invocations ts. For each medium-difficulty sample, the initial references t^c(0) and t^s(0) are derived from its successful trajectory. During training, the primary round reference t^c tightens per epoch according to t^c(e+1)=min(t^c(e),tc(e+1)), forming an implicit curriculum. The total invocation reference t^s updates to mirror the tool consumption of the minimal-round trajectory. The TRACE reward Rtool is then defined with specific conditions for penalties and positive rewards based on trajectory efficiency and correctness.
Crucially, positive rewards are only assigned to trajectories that fall within the strictly efficient region (tc≤t^c and ts≤t^s), which prevents reward hacking. Correct trajectories with tc=0 receive Rtool=0 to prevent parametric guessing. The aggregated rewards Ri are normalized within a group to compute the relative advantage A^i=(Ri−μR)/σR for the GRPO objective. To address credit-assignment deficiencies on failed rollouts, OPD distills token-level supervision from a frozen teacher model πteacher into the student πθ, applied exclusively to failed trajectories. This is achieved by minimizing the reverse KL divergence over completion tokens, which drives the student to concentrate on the high-probability reasoning modes of the teacher. The final student loss combines the GRPO loss with the distillation loss, ensuring that successful exploration is shaped by TRACE while token-level correction is provided by OPD.

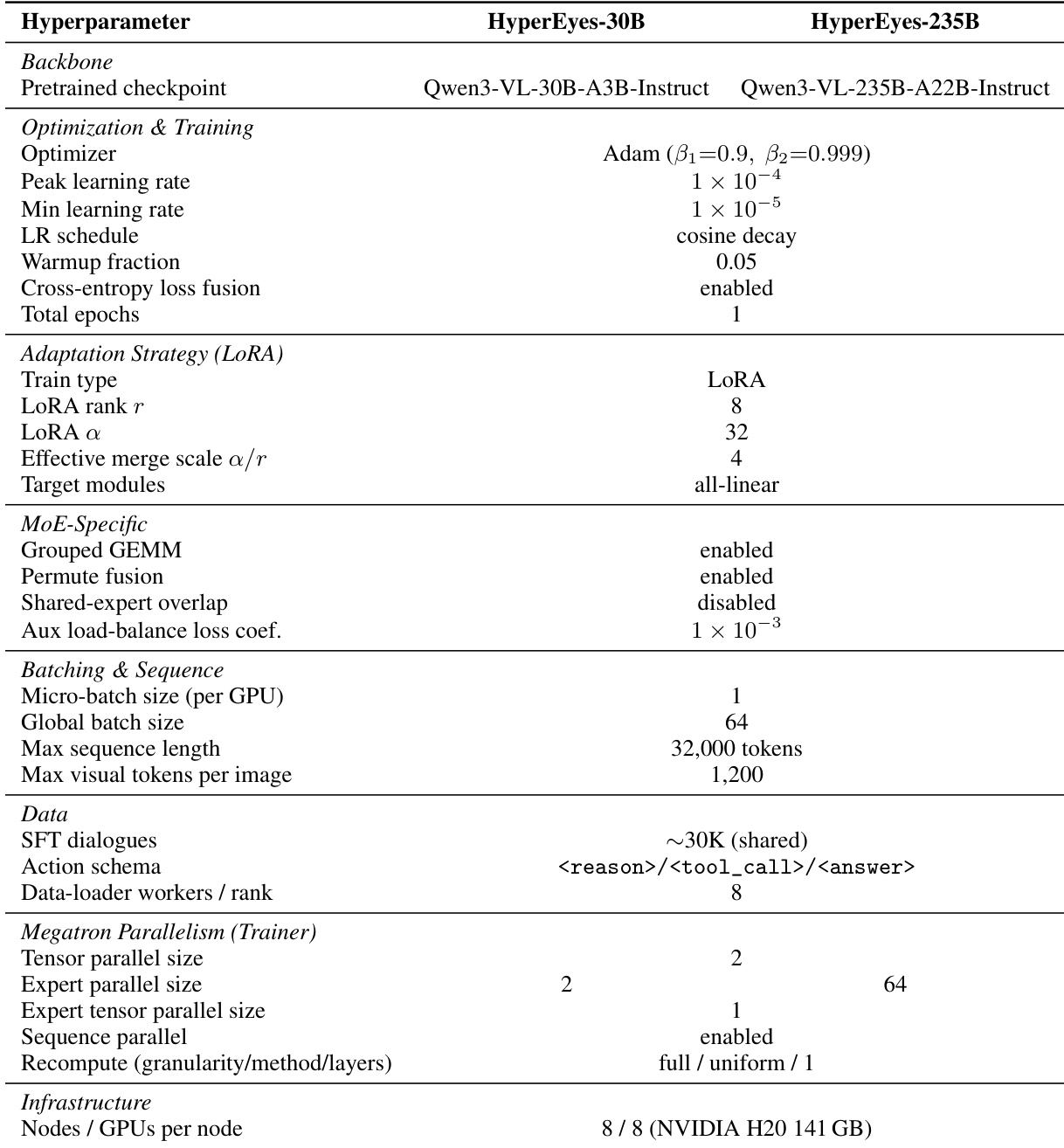
The training of HyperEyes proceeds in two stages and is run independently for the 30B and 235B model scales, sharing the same data recipes. In the SFT stage, LoRA-based fine-tuning is performed on the 30,000 curated trajectories using Qwen3-VL-30B-A3B-Instruct and Qwen3-VL-235B-A22B-Instruct as backbones. Each SFT run is conducted on 8 nodes (64 NVIDIA H20-141 GB GPUs) and converges in approximately 10 hours for the 30B variant and 20 hours for the 235B variant. In the RL stage, both variants are further optimized with GRPO under the proposed TRACE reward on medium-difficulty subsets. The training configurations differ between the variants: HyperEyes-235B (RL) is trained with TRACE only and serves as the frozen teacher for the 30B variant, while HyperEyes-30B (RL) adds OPD on top of TRACE. The RL stage takes approximately 48 hours for HyperEyes-30B and 72 hours for HyperEyes-235B.
The search backends are implemented under a unified asynchronous search adapter that supports parallel batched queries within a single turn. The text search backend is a real, web-scale retrieval service powered by SerpAPI, which wraps the Google Web Search engine. The image search backend uses SerpAPI's Google Reverse Image Search endpoint, allowing the agent to operate on either a whole image or user-specified normalized crop regions. Each rollout is capped at a maximum of 8 tool invocations per turn and 9 model turns, with concurrency to the retrieval service throttled to 64 in-flight requests. The two variants share the same generation settings: rollouts are generated by SGLang with a sampling temperature of 0.8 and top-p of 0.95, with a maximum prompt length of 15,000 tokens and a maximum response length per turn of 1,524 tokens. Each image consumes at most 1,200 visual tokens, and each rollout may attach up to 50 images.
Experiment
The evaluation spans six multimodal search benchmarks to assess accuracy and operational efficiency against open-source and proprietary agents. Main results and ablation studies validate that parallel unified grounded search significantly outperforms conventional serial retrieval paradigms by decoupling entity identification from reasoning, thereby minimizing redundant tool calls and cascading errors. Additional experiments confirm that rigorous data filtering combined with adaptive reinforcement learning effectively suppresses over-retrieval while enhancing robustness against noisy evidence. Ultimately, these findings establish a highly efficient framework that optimizes the accuracy-efficiency trade-off for complex visual reasoning tasks.
The authors evaluate the robustness of the HyperEyes-30B (RL) model across different random seeds to assess the stability of its performance. The results show that the model's accuracy and tool-call efficiency remain consistent under varying initializations, with low standard deviations across all benchmarks. The average accuracy and average tool turns are stable, indicating that the reported performance is not sensitive to the choice of random seed. The model's performance is stable across different random seeds, with low standard deviation in accuracy and tool-call turns. The average accuracy and tool-call efficiency remain consistent, indicating robustness to initialization. The results confirm that the reported numbers are not due to a favorable random seed.
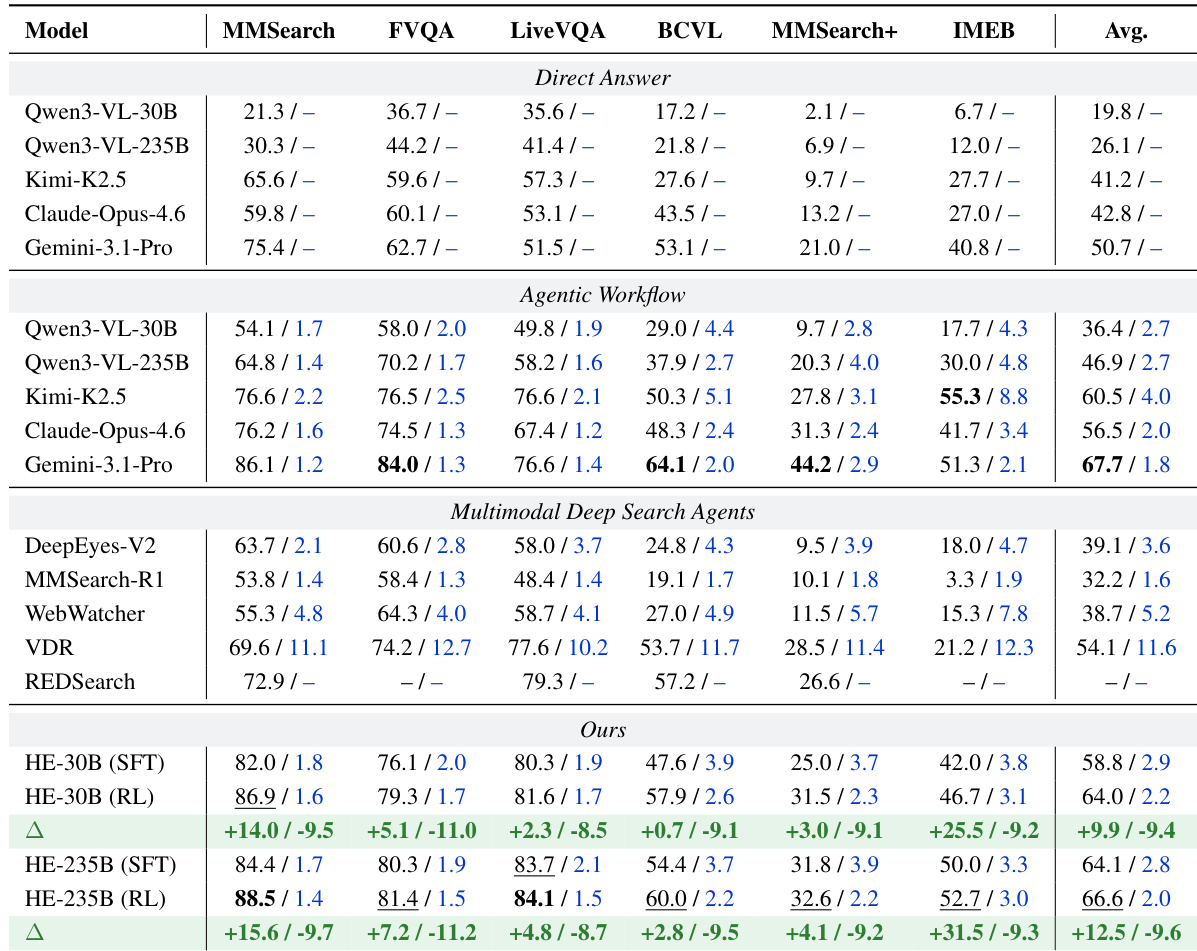
The authors evaluate HyperEyes, a multimodal search agent, across six benchmarks, demonstrating that it achieves higher accuracy and lower tool-call turns compared to existing open-source and proprietary models. The results show that HyperEyes-235B (RL) approaches the performance of leading commercial models while significantly outperforming open-source agents in both accuracy and efficiency. The framework's dual-stage training, combining supervised fine-tuning and reinforcement learning, enables it to deliver robust and efficient multi-entity grounded retrieval with minimal redundancy. HyperEyes achieves higher accuracy and fewer tool calls than leading open-source and commercial models, establishing a new standard for open-source search agents. The reinforcement learning stage simultaneously improves accuracy and reduces tool-call redundancy, confirming the effectiveness of adaptive efficiency constraints and distillation. HyperEyes demonstrates superior efficiency and robustness, with a parallel grounded search paradigm that reduces tool-use rounds and improves accuracy compared to serial approaches.
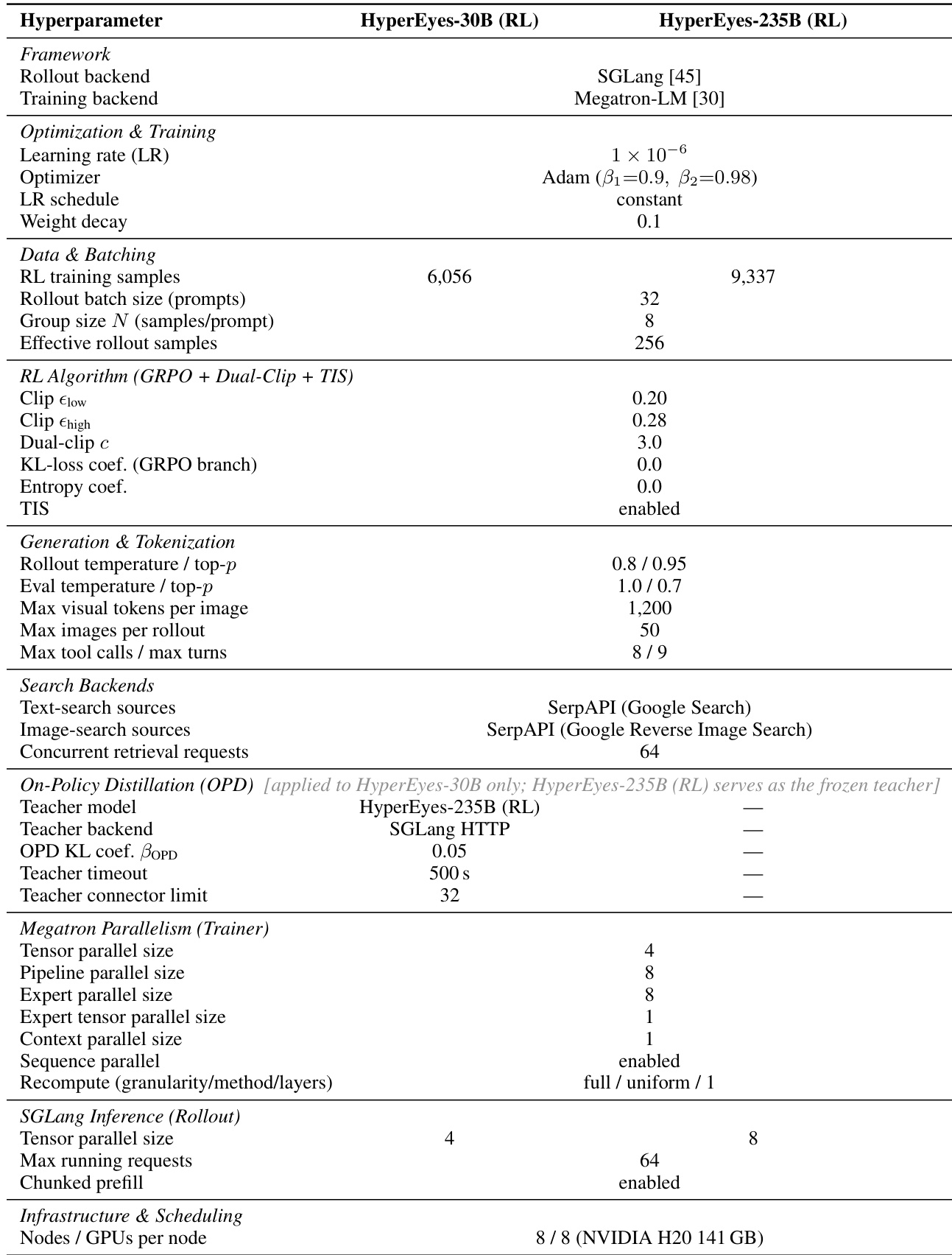
The the the table details the hyperparameters and training configurations for two variants of the HyperEyes model, HyperEyes-30B (RL) and HyperEyes-235B (RL), highlighting differences in their training backends, optimization settings, and RL algorithm components. The configurations reveal that the larger model employs a different training backend and has a higher number of training samples and rollout batch size, while the smaller model incorporates on-policy distillation with a separate teacher model. Both models utilize a similar RL framework with dual-clip and TIS, but differ in their inference and training parallelism strategies. HyperEyes-235B (RL) uses a different training backend and has a larger rollout batch size compared to HyperEyes-30B (RL). The larger model employs on-policy distillation with a separate teacher model, which is not used in the smaller variant. Both models use similar RL algorithms but differ in their inference and training parallelism strategies, with the larger model having more extensive parallelization.
The authors analyze the impact of tool-call budget on model performance, observing that increasing the number of calls does not consistently improve accuracy and often leads to degradation. On shallow-hop tasks, accuracy peaks at the lowest budget and declines with additional calls, while on complex multi-hop tasks, performance peaks at a moderate budget before dropping. The average number of tool calls scales linearly with the imposed budget, indicating that higher costs do not yield better results and may introduce performance drops in certain regimes. Increasing the number of tool calls does not improve accuracy and often leads to performance degradation on both shallow-hop and complex multi-hop tasks. Accuracy peaks at a low tool-call budget on shallow-hop tasks and a moderate budget on complex multi-hop tasks, after which it declines. The average number of tool calls increases linearly with the imposed budget, showing that higher costs do not result in better accuracy.

The authors evaluate HyperEyes on multiple multimodal search benchmarks, comparing its performance against various open-source and commercial models. Results show that HyperEyes achieves higher accuracy and fewer tool calls than competing models, demonstrating superior efficiency and effectiveness in multi-entity grounded retrieval tasks. The ablation studies highlight the importance of data curation, reinforcement learning with adaptive efficiency constraints, and distillation from an efficiency-aligned teacher. HyperEyes achieves higher accuracy and fewer tool calls than competing models across multiple benchmarks. The reinforcement learning stage improves both accuracy and efficiency, reducing redundant tool usage while enhancing performance. Data curation and distillation from an efficiency-aligned teacher are critical for achieving high performance.
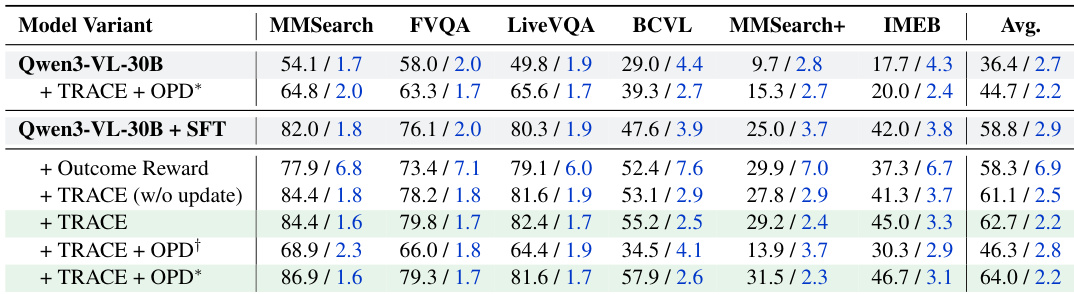
The authors evaluate HyperEyes across multiple multimodal search benchmarks to validate its accuracy and efficiency against existing open-source and commercial models. Stability tests across random seeds confirm that the framework is robust to initialization, while ablation studies demonstrate that dual-stage training, adaptive efficiency constraints, and teacher distillation are critical for optimal performance. Furthermore, tool-call budget analyses demonstrate that performance peaks at low to moderate retrieval limits and degrades with excessive usage, confirming the necessity of constrained tool strategies. Collectively, these experiments establish HyperEyes as a highly efficient and robust search agent that successfully balances high accuracy with minimal operational overhead.