Command Palette
Search for a command to run...
A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
Hamid Kazemi Atoosa Chegini Maria Safi
Abstract
Safety alignment in language models operates through two mechanistically distinct systems: refusal neurons that gate whether harmful knowledge is expressed, and concept neurons that encode the harmful knowledge itself. By targeting a single neuron in each system, we demonstrate both directions of failure — bypassing safety on explicit harmful requests via suppression, and inducing harmful content from innocent prompts via amplification — across seven models spanning two families and 1.7B to 70B parameters, without any training or prompt engineering. Our findings suggest that safety alignment is not robustly distributed across model weights but is mediated by individual neurons that are each causally sufficient to gate refusal behavior — suppressing any one of the identified refusal neurons bypasses safety alignment across diverse harmful requests.
One-sentence Summary
By targeting a single neuron in the refusal and concept systems across seven models spanning two families and 1.7B to 70B parameters without training or prompt engineering, the authors demonstrate that safety alignment is mediated by individual neurons causally sufficient to gate refusal behavior rather than being robustly distributed across model weights.
Key Contributions
- The paper identifies two mechanistically distinct systems governing safety alignment in language models, specifically distinguishing between refusal neurons that gate expression and concept neurons that encode harmful knowledge.
- This work demonstrates that suppressing or amplifying a single neuron in each system allows for bypassing safety on harmful requests or inducing harmful content from innocent prompts without any training or prompt engineering.
- Experiments validate these findings across seven models spanning two families and parameter sizes from 1.7B to 70B, showing that individual refusal neurons are causally sufficient to gate refusal behavior across diverse harmful requests.
Introduction
Large language model safety alignment is typically assumed to emerge from a broad reorganization of weights distributed across the network. While recent mechanistic work has identified global directions or subsets of neurons that modulate refusal behavior, previous methods have not isolated a single component as causally sufficient for safety gating. The authors demonstrate that intervening on a single MLP neuron is enough to bypass safety alignment entirely across seven models spanning 1.7B to 70B parameters without requiring training or prompt engineering. They further show that amplifying specific concept neurons can inject harmful content into innocent prompts, indicating that safety relies on identifiable individual bottlenecks rather than diffuse robustness.
Dataset

- The authors analyze a diverse corpus of text data inferred from activation snippets across Qwen3 and Meta-Llama-3.1 model families.
- Dataset composition includes web text, technical documentation, legal records, news articles, and informal forum discussions.
- Key details for each subset involve specific feature activations identified by layer number and feature ID within models ranging from 1.7B to 70B parameters.
- The paper uses the data to probe safety-relevant concepts by examining top and bottom activation examples for specific neurons.
- Processing involves ranking text snippets by activation magnitude to isolate coherent semantic themes such as hate speech or privacy policies.
- Metadata construction links each feature to its corresponding model layer and activation score.
- Cropping strategies focus on retaining peak tokens that trigger the highest or lowest responses.
Method
The proposed method focuses on identifying and intervening upon specific MLP neurons that mediate refusal behavior in large language models. The authors leverage a hook-based mechanism to monitor the pre-down-projection intermediate activations h=ϕ(Wgate(x))⊙Wup(x) at each monitored layer ℓ. During the feature selection phase, forward passes are run on a dataset containing both harmful and harmless prompts. For each prompt, a hook is registered on the activation h to capture scalar coordinates hi, referred to as neurons.
To rank these neurons, the authors compute the gradient of a refusal log-odds loss L with respect to h at post-instruction token positions. The loss is defined as L=−log1−prefusalprefusal, where prefusal represents the probability mass over refusal phrases. A combined gradient signal Gi,t is calculated as the sum of mean signed gradients over harmful and harmless prompts. The final feature score combines this gradient signal with the activation difference between prompt types:
scorei,t=Gi,t×(ai,t(h)−ai,t(H))This scoring mechanism prioritizes neurons that are strongly active on harmful inputs but near-silent on harmless ones, while also exhibiting a gradient direction that opposes refusal. The top-scoring candidates are then empirically reranked by sweeping multiplier values m on a validation set to maximize the Attack Success Rate (ASR).
Two intervention strategies are employed once a target neuron (l,i) is identified. The first is a Constant intervention, where the activation is pinned to a constant value m (hi←m) at every token position. The second is an Anchor-based intervention, which addresses the coherence issues of the constant method by using a context-sensitive scaling. This variant calculates an anchor value v based on the neuron's natural activation during a hook-free forward pass and scales the intervention relative to the harmful-harmless activation gap d. The intervention is applied as:
hi←clamp(k⋅m∗⋅dv−d,m∗)where m∗ is the optimal multiplier from the constant intervention sweep and k is a scaling factor.
To illustrate the semantic properties of the identified refusal neurons, the authors analyze the top activations of specific features. For instance, a top-ranked neuron in Meta-Llama-3.1-70B-Instruct (Layer 31, Feature 24121) is found to fire on concepts related to invalid states, blocked execution, and obstruction. The specific tokens and code patterns associated with this feature are detailed below:

This analysis confirms that the selected neurons correspond to semantic concepts related to refusal or blocked states, validating the feature selection process.
Experiment
The study evaluates safety mechanisms across multiple instruction-tuned and base models using standard benchmarks and dual-judge assessment to measure attack success rates. Results indicate that intervening on single refusal neurons bypasses safety alignment as effectively as broader ablations while maintaining general capabilities, and analysis confirms these neurons emerge during pretraining rather than alignment training. Furthermore, amplifying specific concept neurons can induce harmful content from benign prompts, demonstrating that safety bottlenecks and harmful knowledge are localized to individual neurons within the network.
The the the table details specific refusal neurons identified across models from the Qwen3 and Llama-3.1 families. It records the network layer and index for each neuron and compares activation levels on harmful versus harmless prompts. The results show that these neurons consistently exhibit a strong separation between safety-relevant inputs, which enables targeted interventions to bypass safety alignment. Consistent Discrimination: Every listed neuron demonstrates a significant gap in activation values between harmful and harmless prompts, confirming their role in detecting unsafe content. Distributed Locations: The identified neurons are found at different layers and indices across the model families, suggesting safety mechanisms are not confined to a single architectural component. Diverse Intervention Needs: The optimal multiplier required to manipulate the neuron varies by model, with some needing positive adjustments and others requiring negative ones to successfully suppress refusal behavior.

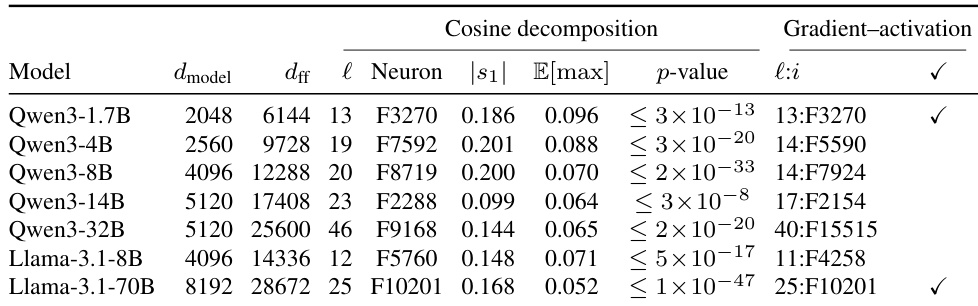
The authors compare three intervention strategies to evaluate their impact on general model capabilities using MMLU and GSM8K benchmarks. While the Constant intervention achieves high attack success, it incurs substantial performance degradation, particularly in knowledge-based tasks. In contrast, the Anchor variant significantly reduces this capability cost, aligning closely with the minimal degradation observed in the Arditi baseline. Constant intervention causes substantial degradation in general knowledge and reasoning tasks compared to other methods. Anchor and Arditi methods result in minimal capability loss, performing comparably to the unmodified baseline. Performance costs vary by model size, with larger models suffering greater losses under the Constant intervention.
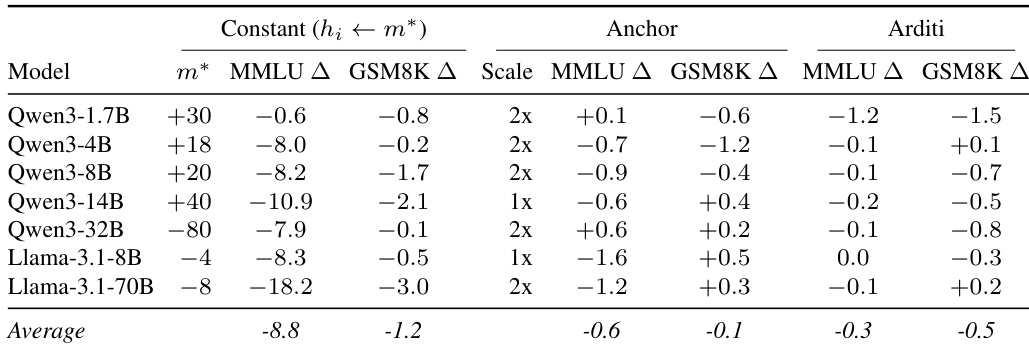
The authors evaluate single-neuron activation as a harmful prompt detector against the LlamaGuard 3 classifier on the XSTest benchmark. Results show that the refusal neuron from Llama-3.1-8B achieves performance comparable to the dedicated classifier in terms of accuracy and AUROC, while significantly improving recall at the expense of precision. Other models, particularly the Qwen3 family, generally show lower accuracy scores, with the smallest 1.7B variant performing the weakest. The Llama-3.1-8B refusal neuron matches the dedicated classifier's accuracy while achieving higher recall. Most Qwen3 models maintain strong detection performance with high AUROC, except for the smallest variant. Single-neuron detection serves as an efficient alternative to full classifier inference by relying on a single activation value.
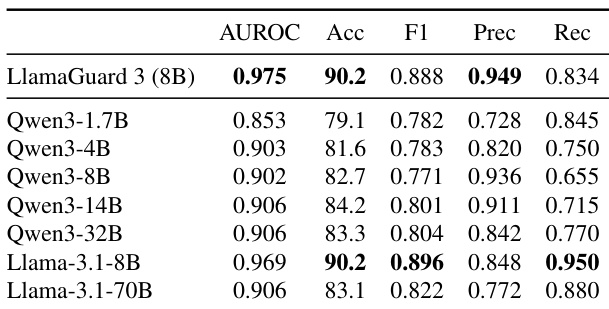
The authors compare two independent methods for identifying refusal neurons: a gradient-activation approach and a geometric alignment method based on a global refusal direction. The results demonstrate that for certain models, both strategies converge on the exact same neuron, and the alignment between the top neuron and the refusal direction is statistically significant across the board. Two independent identification strategies converge on the same single neuron for Qwen3-1.7B and Llama-3.1-70B. The cosine similarity between the top-ranked neuron and the refusal direction is statistically significant across all models. The geometric alignment method is restricted to the refusal-direction layer while the gradient method searches all layers, yet they still agree on the top neuron for the two models marked with a check.
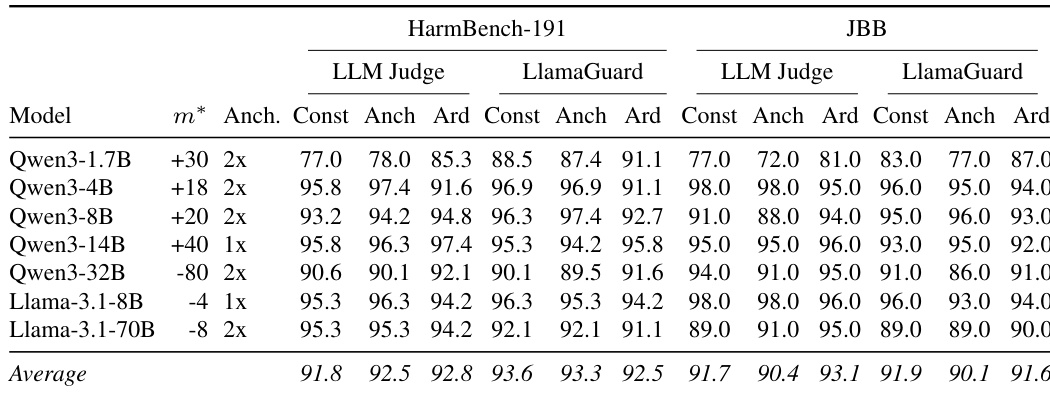
The authors evaluate three intervention strategies across seven instruction-tuned models using two benchmarks and two independent judges. The results show that single-neuron intervention methods achieve attack success rates comparable to the baseline method that ablates an entire direction across layers. Performance is consistent across different model families and scales, with high success rates observed on both the development and held-out test sets. Single-neuron intervention methods achieve attack success rates comparable to the full direction ablation baseline across all evaluated models. Intervention parameters selected on the development set transfer effectively to the held-out test set without requiring re-tuning. High attack success rates are maintained across different model families and parameter scales, indicating the robustness of the identified refusal neurons.
This research evaluates refusal neurons across Qwen3 and Llama-3.1 families to validate their role in detecting unsafe content and enabling targeted safety interventions. Experiments demonstrate that manipulating specific neurons allows for bypassing safety alignment with minimal capability degradation compared to broader ablation methods, while maintaining high success rates across different model scales. Furthermore, single-neuron activation serves as an efficient safety detector comparable to dedicated classifiers, and independent identification strategies consistently converge on the same critical neurons.