Command Palette
Search for a command to run...
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
Shengkun Tang Zekun Wang Bo Zheng Liangyu Wang Rui Men Siqi Zhang Xiulong Yuan Zihan Qiu Zhiqiang Shen Dayiheng Liu
Abstract
Structured pruning and knowledge distillation (KD) are typical techniques for compressing large language models, but it remains unclear how they should be applied at pretraining scale, especially to recent mixture-of-experts (MoE) models. In this work, we systematically study MoE compression in large-scale pretraining, focusing on three key questions: whether pruning provides a better initialization than training from scratch, how expert compression choices affect the final model after continued training, and which training strategy is most effective. We have the following findings: First, across depth, width, and expert compression, pruning a pretrained MoE consistently outperforms training the target architecture from scratch under the same training budget. Second, different one-shot expert compression methods converge to similar final performance after large-scale continual pretraining. Motivated by this, we introduce a simple partial-preservation expert merging strategy that improves downstream performance across most benchmarks. Third, combining KD with the language modeling loss outperforms KD alone, particularly on knowledge-intensive tasks. We further propose multi-token prediction (MTP) distillation, which yields consistent gains.
One-sentence Summary
SlimQwen systematically investigates pruning and distillation within large-scale mixture-of-experts model pre-training, demonstrating that pruning pretrained models outperforms training from scratch, introducing a partial-preservation expert merging strategy, and combining knowledge distillation with language modeling loss alongside multi-token prediction distillation to improve downstream performance across various benchmarks.
Key Contributions
- Structured pruning of pretrained MoE models provides a stronger initialization than training from scratch under the same budget across depth, width, and expert dimensions. This is demonstrated by compressing Qwen3-Next-80A3B into a 23A2B model.
- A partial-preservation expert merging strategy is introduced to improve downstream performance across benchmarks including general reasoning, mathematics, and coding. This approach is motivated by the observation that different one-shot expert compression methods converge to similar final performance after large-scale continual pretraining.
- Multi-token prediction distillation extends standard next-token distillation by supervising multiple future tokens. Combining this approach with language modeling loss yields consistent gains, particularly on knowledge-intensive tasks.
Introduction
Mixture-of-Experts architectures dominate large language model scaling but remain expensive to pretrain and serve. While structured pruning and knowledge distillation compress dense models effectively, applying these techniques to MoE systems at pretraining scale introduces unique challenges regarding expert handling. Prior research typically evaluates one-shot compression without accounting for performance recovery during large-scale continual pretraining. The authors systematically investigate MoE compression and find that pruning a pretrained model offers a superior initialization compared to training from scratch. They propose a partial-preservation expert merging strategy and multi-token prediction distillation to enhance downstream performance. Furthermore, the study demonstrates that progressive pruning schedules yield better optimization trajectories than one-shot methods, enabling the compression of a Qwen3 model while retaining competitive benchmark results.
Method
The authors leverage a hybrid-attention Mixture-of-Experts (MoE) architecture as the foundation for their compression framework. The base model, referred to as Qwen3-Next, consists of L layers where each block integrates Gated DeltaNet or Gated Attention modules alongside an MoE module. The MoE module comprises nrouted routed experts and nshared shared experts. Each expert is implemented as a SwiGLU MLP defined as:
Expert(x)=(SiLU(xW1e)⊙(xW2e))W3ewhere W1e,W2e∈Rd×dff and W3e∈Rdff×d. The router generates top-k gating scores for routed experts, while a separate shared gate handles shared experts. The final MoE output combines these contributions:
MoE(x)=e=1∑nroutedze(x)Experte(x) + s=1∑nsharedzs(x)Experts(x)To reduce model size, the authors introduce structured pruning across three dimensions: depth, width, and experts. Depth pruning involves directly removing the last N layers of the model. Width pruning reduces the hidden dimension by estimating importance via activation statistics on a calibration dataset. The importance of the k-th hidden dimension is calculated as:
Inorm(k)=[L∑i=0LMean(RMSNorm(X))]kExpert compression employs metrics such as frequency, soft-logits, and router-weighted expert activation (REAP) to quantify expert importance. To balance knowledge preservation and consolidation, a partial-preservation merging strategy is proposed. This approach retains half of the target experts with the highest importance scores intact, while the remaining target experts are constructed by merging discarded experts into selected bases. The merging process is formulated as:
E~i=Ii+Im(i)IiEi+Ii+Im(i)Im(i)Em(i)The overall framework for structured pruning and the subsequent progressive distillation pipeline is illustrated below:

Following the structural compression, the authors employ a Multi-Token Prediction (MTP) distillation strategy to recover performance. The MTP module predicts future tokens at various depths k. For the i-th input token, the representation at depth k is computed by combining the previous depth representation with the embedding of the future token ti+k:
hik=Mk[RMSNorm(hik−1);RMSNorm(Emb(ti+k))]The training objective combines standard language modeling, knowledge distillation, and their MTP variants. The total loss function balances these components using hyperparameters λ and β:
L=(1−λ)LLM+λLKD+β((1−λ)LMTP−LM+λLMTP−KD)To mitigate knowledge loss during aggressive compression, a progressive pruning and distillation schedule is utilized. This process interleaves structural pruning with fixed-token distillation phases. The authors evaluate three specific schedules: Depth-first, which prioritizes layer reduction before width reduction; Width-first, which reduces hidden dimensions first; and Joint, which simultaneously reduces both depth and width by half in the initial stage before completing the reduction in the second stage.
Experiment
The experiments evaluate a compressed hybrid MoE architecture across diverse benchmarks to validate the effectiveness of pruning initialization and expert compression strategies. Results demonstrate that pruning provides a superior starting point that accelerates convergence compared to random initialization, while progressive compression and partial expert preservation consistently outperform one-shot methods by retaining more pretrained knowledge. Additionally, combining multi-token prediction distillation with standard language modeling losses enhances both backbone performance and speculative decoding efficiency.
The authors evaluate various training loss configurations for a pruned MoE model to determine an effective recipe for continual pretraining. Results indicate that combining next-token prediction knowledge distillation with language modeling loss improves performance on knowledge-intensive benchmarks compared to using distillation alone. Additionally, integrating multi-token prediction knowledge distillation yields consistent gains, with the comprehensive objective achieving strong results on major benchmarks. Combining knowledge distillation with language modeling loss outperforms pure distillation on knowledge benchmarks. Incorporating multi-token prediction knowledge distillation leads to consistent performance improvements across various evaluation tasks. The full training objective achieves the highest performance on the MMLU benchmark among the tested configurations.

The study investigates whether pruning provides a better initialization for MoE models in large-scale pretraining compared to random initialization. The results demonstrate that a pruned model initialized with knowledge distillation consistently outperforms both random initialization and pruning with standard language modeling loss across multiple benchmarks. This approach allows the compact model to recover a substantial portion of the teacher model's performance, validating the effectiveness of structured pruning for preserving task-critical weights. Pruned initialization combined with knowledge distillation significantly outperforms random initialization across all evaluated benchmarks. The pruned model with distillation achieves the highest average score among the student configurations, closely approaching the teacher model's performance. Utilizing knowledge distillation with a pruned model yields better results than applying standard language modeling loss to the same pruned architecture.

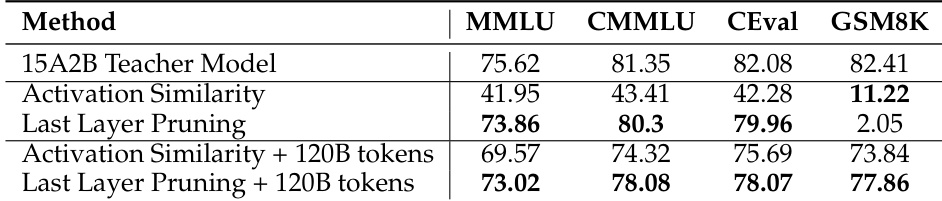
The authors compare pruning strategies for MoE models, specifically Activation Similarity versus Last Layer Pruning, both before and after training with 120B tokens. The results show that Last Layer Pruning provides a much stronger initialization than Activation Similarity, preserving general knowledge capabilities even without retraining. Additionally, training the pruned models allows them to recover math reasoning skills and reach performance levels close to the original teacher model. Last Layer Pruning retains strong general knowledge performance immediately after pruning, whereas Activation Similarity causes a significant drop in scores. Retraining the pruned models with 120B tokens successfully recovers math reasoning abilities that were nearly lost during the pruning phase. The final pruned model trained with distillation achieves results comparable to the larger teacher model across all evaluated benchmarks.
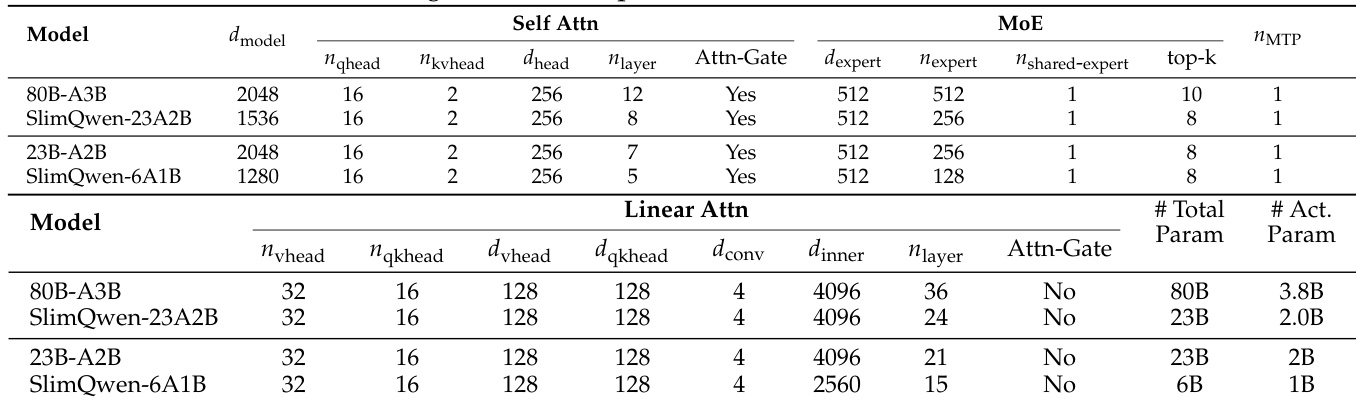
The the the table presents the architectural specifications for base models and their corresponding pruned SlimQwen variants, illustrating a structured approach to model compression. The pruned configurations achieve efficiency by reducing the depth of attention layers and decreasing the number of experts in the Mixture of Experts modules. Pruned models exhibit a significant decrease in both total and active parameters compared to their base counterparts. Structural compression involves reducing the layer count for Self-Attention and Linear Attention components. Expert capacity is lowered by reducing the total number of experts and the number of active experts per token.
The authors compare one-stage pruning with progressive pruning strategies to optimize training for compressed models. The results demonstrate that progressive methods consistently outperform the one-stage baseline across various benchmarks. The depth-first strategy with a specific two-stage token schedule achieves the best overall performance. Progressive pruning strategies consistently outperform the one-stage baseline across various benchmarks. The depth-first strategy with a two-stage token schedule achieves the best overall performance. Increasing the granularity of training stages does not provide additional performance gains over the standard two-stage approach.

The authors evaluate training loss configurations, initialization methods, and pruning schedules to optimize compressed Mixture of Experts models. Results indicate that combining knowledge distillation with language modeling loss and utilizing pruned initialization significantly outperforms standard baselines and random initialization. Additionally, Last Layer Pruning preserves general knowledge better than Activation Similarity, and progressive pruning strategies yield superior results compared to one-stage approaches, enabling compact models to recover teacher-level performance across major benchmarks.