Command Palette
Search for a command to run...
MMSkills: Towards Multimodal Skills for General Visual Agents
MMSkills: Towards Multimodal Skills for General Visual Agents
Abstract
Reusable skills have become a core substrate for improving agent capabilities, yet most existing skill packages encode reusable behavior primarily as textual prompts, executable code, or learned routines. For visual agents, however, procedural knowledge is inherently multimodal: reuse depends not only on what operation to perform, but also on recognizing the relevant state, interpreting visual evidence of progress or failure, and deciding what to do next. We formalize this requirement as multimodal procedural knowledge and address three practical challenges: (I) what a multimodal skill package should contain; (II) where such packages can be derived from public interaction experience; and (III) how agents can consult multimodal evidence at inference time without excessive image context or over-anchoring to reference screenshots. We introduce MMSkills, a framework for representing, generating, and using reusable multimodal procedures for runtime visual decision making. Each MMSkill is a compact, state-conditioned package that couples a textual procedure with runtime state cards and multi-view keyframes. To construct these packages, we develop an agentic trajectory-to-skill Generator that transforms public non-evaluation trajectories into reusable multimodal skills through workflow grouping, procedure induction, visual grounding, and meta-skill-guided auditing. To use them, we introduce a branch-loaded multimodal skill agent: selected state cards and keyframes are inspected in a temporary branch, aligned with the live environment, and distilled into structured guidance for the main agent. Experiments across GUI and game-based visual-agent benchmarks show that MMSkills consistently improve both frontier and smaller multimodal agents, suggesting that external multimodal procedural knowledge complements model-internal priors.
One-sentence Summary
MMSkills equips visual agents with reusable multimodal procedural knowledge by coupling textual procedures with runtime state cards and multi-view keyframes, leveraging an agentic trajectory-to-skill Generator for package construction and a branch-loaded multimodal skill agent for live-environment alignment, which consistently improves both frontier and smaller multimodal agents across GUI and game-based visual-agent benchmarks.
Key Contributions
- MMSkills is introduced as a framework that formalizes multimodal procedural knowledge by encoding reusable behaviors into compact packages coupling textual procedures with runtime state cards and multi-view keyframes.
- An agentic trajectory-to-skill Generator automatically constructs these packages from public interaction logs through workflow grouping, procedure induction, visual grounding, and meta-skill-guided auditing.
- A branch-loaded inference mechanism inspects selected evidence in a temporary branch to distill structured guidance, mitigating long-context degradation while consistently improving performance for frontier and smaller multimodal agents across GUI and game-based benchmarks.
Introduction
The authors address the growing reliance on reusable procedural knowledge to enhance multimodal AI agents operating in complex visual environments like desktop automation and interactive games. While prior skill representations effectively encode behaviors as text or code, they struggle to capture the visual state cues and conditional decision-making required when agents must interpret live screen evidence. Existing methods either produce verbose text-only instructions, rely on inflexible raw demonstrations, or overwhelm context windows by directly injecting full skill libraries, which often causes agents to anchor to reference screenshots rather than current observations. To bridge this gap, the authors introduce MMSkills, a framework that structures reusable knowledge into compact multimodal packages coupling textual procedures with runtime state cards and multi-view keyframes. They further develop an automated pipeline to distill these packages from public interaction trajectories and propose branch loading, a runtime mechanism that selectively aligns skill evidence with live observations to deliver precise, state-aware guidance without context saturation.
Dataset
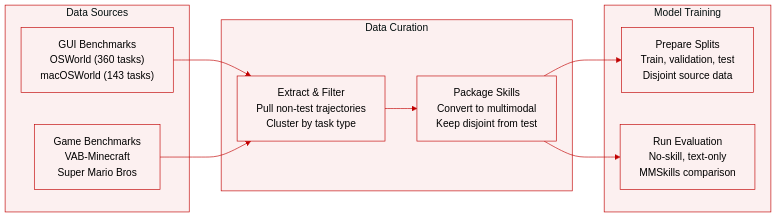
- Dataset composition and sources: The authors use four visual-agent benchmarks spanning realistic graphical user interfaces and open game environments. Skill data is drawn from the OpenCUA trajectory dataset, official training splits, and multiple gameplay runs, with all source material strictly separated from evaluation sets.
- Subset details: OSWorld contains 360 Ubuntu desktop test cases covering browsers, office software, media applications, and system workflows. macOSWorld provides 143 cross-platform GUI cases focused on file management, productivity, and interface tasks. VAB-Minecraft evaluates item-acquisition tasks that require visual grounding, inventory tracking, and tool manipulation. Super Mario Bros is selected from LMGaME-Bench for its recurring visual scenarios that naturally support reusable skill extraction.
- Data usage and splits: The authors extract all multimodal skills exclusively from non-test trajectories. They evaluate frontier and smaller models across three conditions: no-skill, text-only skills, and MMSkills. Source trajectories remain completely disjoint from the final test cases to ensure unbiased evaluation and prevent data leakage.
- Processing and metadata construction: Agents plan directly from visual observations captured as desktop or game screenshots. For macOS skill extraction, raw OpenCUA trajectories undergo additional clustering and relevance filtering to align with benchmark categories. The resulting skill packages are structured into multimodal formats to guide agent decision-making.
Method
The MMSkills framework is structured around a modular architecture that enables visual agents to leverage reusable, multimodal procedural knowledge through a combination of skill representation, generation, and inference mechanisms. At its core, the framework consists of three main components: a multimodal skill package, a skill generation pipeline, and a branch-loaded multimodal skill agent. The overall system operates by first constructing a library of reusable skills from public interaction trajectories and then using a branch-loaded inference mechanism to consult these skills during task execution without directly embedding the full skill context into the main agent's reasoning.
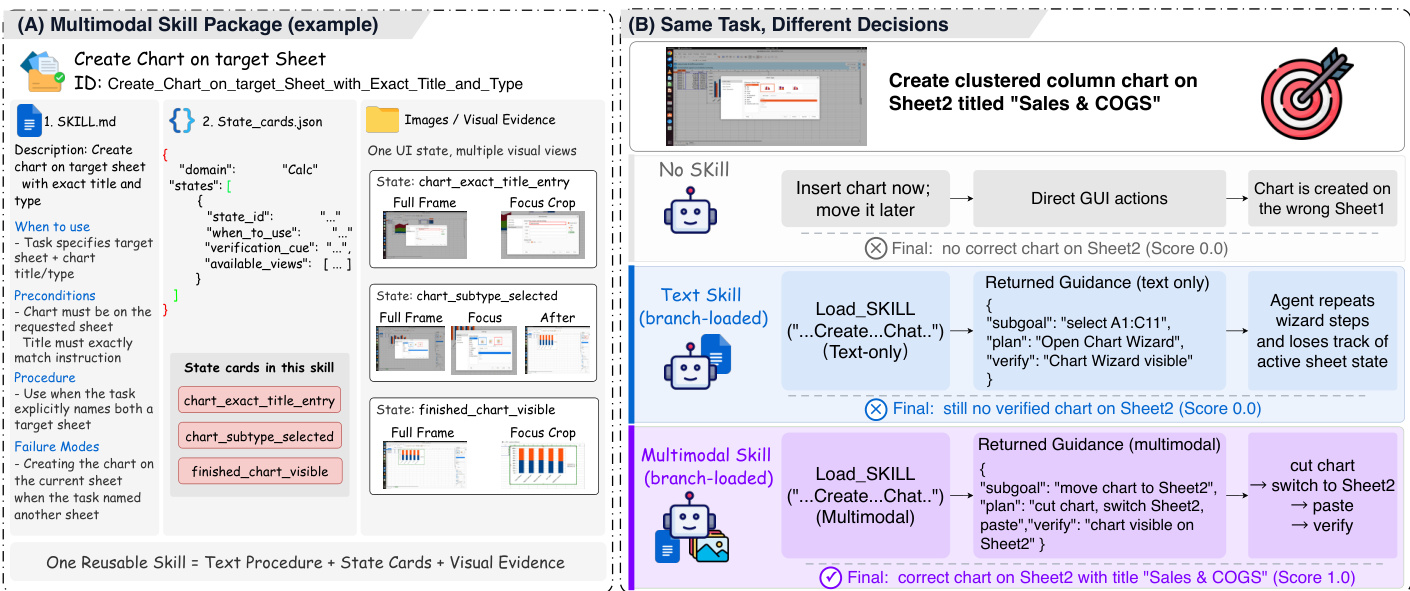
A multimodal skill package encapsulates procedural knowledge as a state-conditioned procedure, represented as M=(D,P,S,K), where D is a compact descriptor, P is a textual procedure, S is a set of runtime state cards, and K is a set of keyframe bundles. Each state card Sj defines when a procedure should be applied or skipped, along with visible cues, verification cues, and available views, enabling the agent to make informed decisions about skill use. The keyframe bundles Kj provide multi-view visual evidence—such as full-frame, focus-crop, before, and after views—that grounds the skill in the environment. This representation allows the skill to be used both textually and visually, with the visual components serving as diagnostic references rather than direct action templates. The skill package is designed to be compact and reusable, with a text-only variant being the degenerate case where no visual evidence is included.
The skill generation pipeline transforms public, non-test trajectories into a domain-specific skill library. This process begins with embedding and clustering task instructions and trajectory metadata to form semantically focused clusters. For each cluster, a large language model (LLM)-based agent proposes atomic skills, defining workflow boundaries, completion conditions, and task coverage. These proposals are then merged and generalized into consolidated skill specifications, with overly broad skills being rejected. The next phase involves drafting the textual components of the skill—descriptor, procedure, and state cards—without referencing images. Finally, the skill is grounded by selecting keyframes, constructing multi-view bundles, and auditing the package to ensure consistency and relevance. This pipeline is controlled by a meta-skill that provides reusable scripts and quality gates, ensuring the generated skills are coherent and useful.
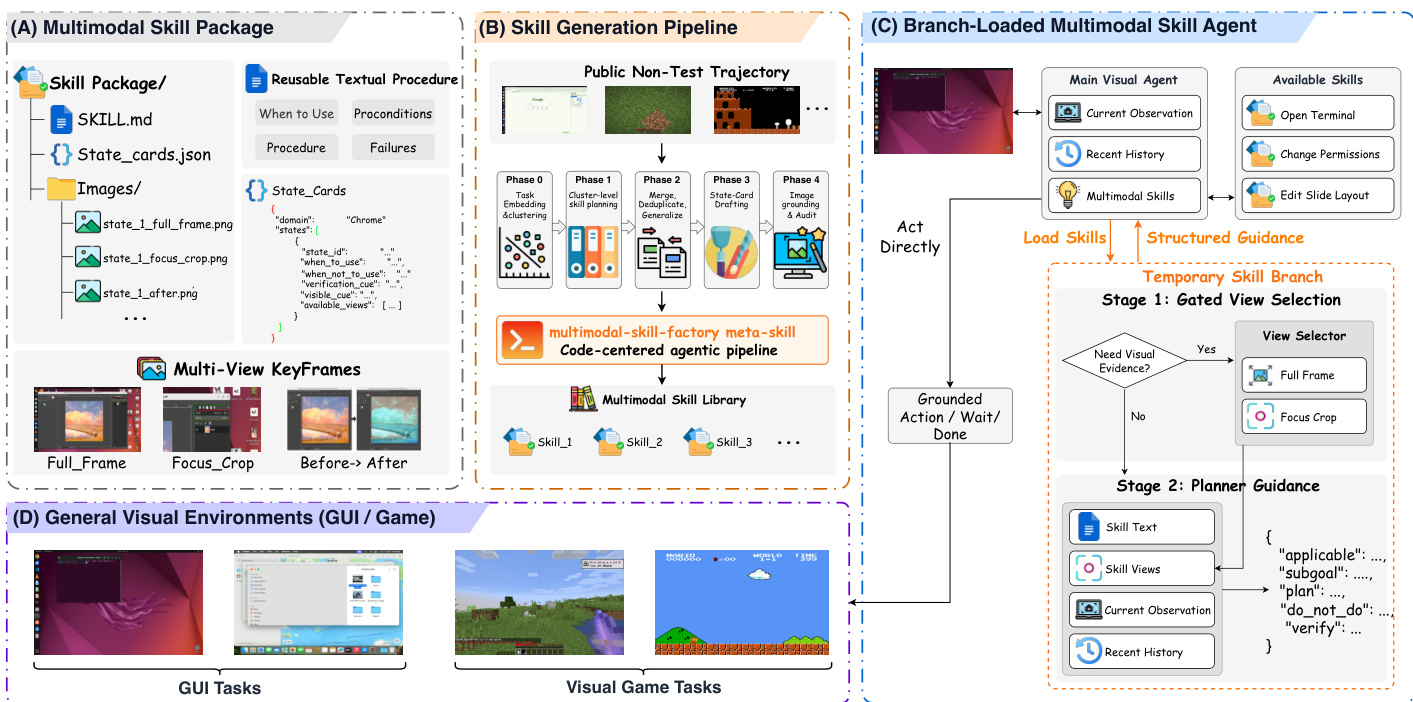
During inference, the main visual agent operates in a branch-loaded manner to avoid the contextual overload that would result from directly loading a full skill package. The agent maintains a short history and observes the current visual state, deciding at each step whether to act directly or consult a selected skill. When a skill is consulted, a temporary branch is activated, isolating the skill-environment grounding from the main trajectory. This branch operates in two stages. In the first stage, a gated view selector evaluates the current observation and recent history to determine whether visual evidence is needed and, if so, which state cards and view types to load. This decision is based on evidence goals such as locating a control, recognizing a pre-change state, or verifying a post-change result. The second stage, the planner guidance module, uses the selected evidence to generate a structured guidance tuple Gt=(applicablet,subgoalt,plant,do_not_dot,verifyt), which includes an applicability judgment, a local subgoal, a skill-conditioned plan, negative constraints, and a verification check. This guidance is returned to the main agent, which uses it as decision support while maintaining action grounding in the live observation.

The main agent’s decision to consult a skill is governed by a policy that evaluates the relevance of the skill’s hints and the current state of the task. The agent may consult a skill at most a limited number of times, and exhausted skills are removed from the available list. The branch-loaded design ensures that the agent receives compact, structured guidance without being distracted by irrelevant visual references, preserving the integrity of the live environment observation. This architecture allows the framework to be applied across diverse visual environments, including graphical user interfaces and video games, by adapting the skill representation and generation process to the specific domain.
Experiment
The evaluation tests multimodal procedural knowledge against no-skill and text-only baselines across desktop GUI and open-ended game environments to validate its impact on agent performance and decision dynamics. Component ablations confirm that combining runtime state discrimination cards with visual keyframes in a filtered branch-loading architecture is necessary for accurate skill retrieval and context preservation. Usage analysis reveals that multimodal guidance increases skill invocation frequency while effectively shortening task trajectories by reducing redundant exploration. Finally, behavioral tracking demonstrates that these skills fundamentally transform agent execution from trial-and-error clicking into structured, state-aware planning with stronger completion awareness.
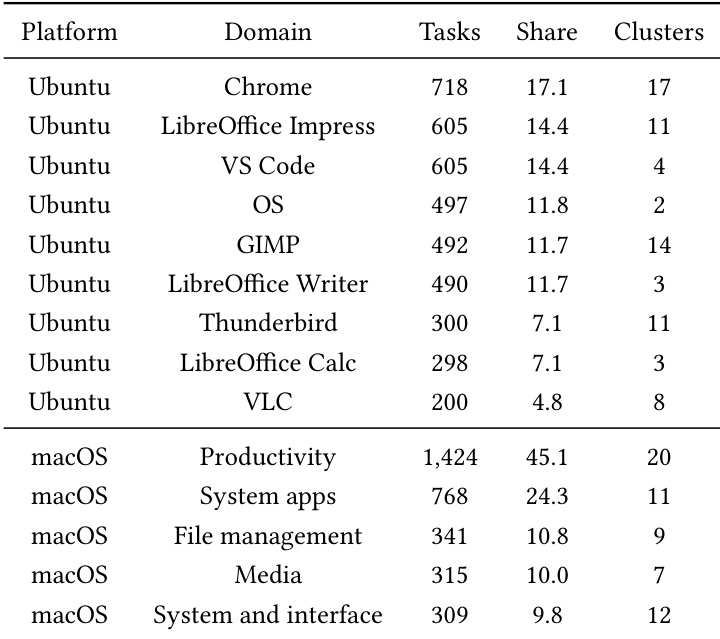
The authors analyze the distribution of tasks and trajectory clusters across different platforms and domains, showing that the majority of tasks and clusters are concentrated on the macOS platform, particularly in productivity and system apps. The data reflects a higher volume of tasks and more diverse clustering in macOS compared to Ubuntu, indicating a broader range of evaluated scenarios in the macOS environment. The majority of tasks and trajectory clusters are concentrated on the macOS platform. Productivity and system apps on macOS have the highest number of tasks and clusters. Ubuntu shows fewer tasks and clusters, with a more limited distribution across domains.
The authors evaluate the impact of MMSkills on visual agents across multiple models and tasks, showing that the integration of multimodal procedural knowledge improves success rates and alters agent behavior. Results demonstrate consistent performance gains across different model families and task domains, with MMSkills leading to shorter trajectories, reduced repetitive actions, and more efficient decision-making. MMSkills improve success rates across all evaluated models and tasks, with the largest gains seen in weaker models and visually grounded game settings. The use of MMSkills reduces interaction length and repetitive actions, indicating more efficient and goal-directed behavior. MMSkills shift agent behavior toward structured input and better completion awareness, reducing exploratory actions and increasing verification of task completion.
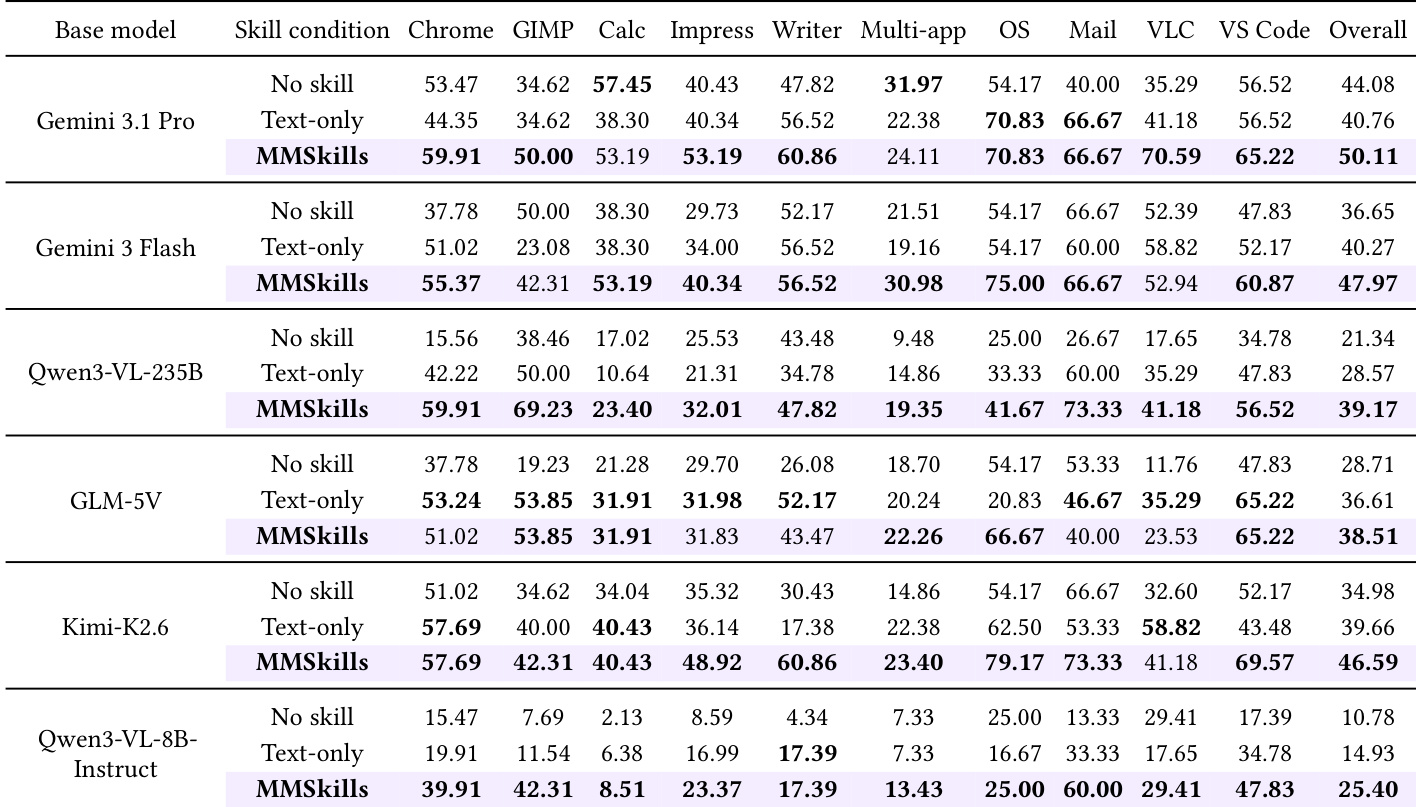
The authors analyze the impact of MMSkills on visual agents across multiple benchmarks, showing that the integration of multimodal procedural knowledge improves task success rates and alters agent behavior. Results indicate that MMSkills reduce the number of low-level actions, decrease repetitive behaviors, and shift action patterns toward more structured and goal-directed interactions, particularly for models with high click usage. MMSkills reduce the number of low-level actions and repetitive behaviors, leading to more efficient task execution. Agents using MMSkills exhibit a shift from click-heavy behaviors toward more structured input and completion judgments. The integration of multimodal skills shortens interaction trajectories and decreases the frequency of repeated actions across multiple models.
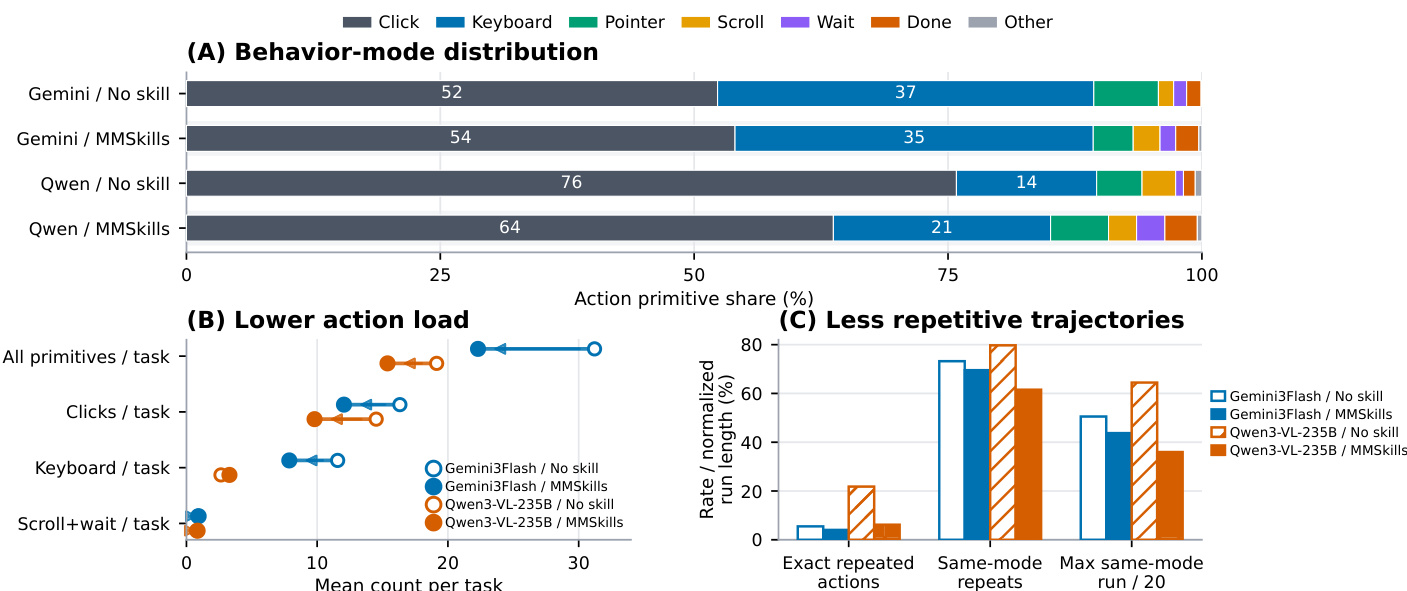
The authors evaluate the impact of multimodal procedural skills on visual agents across multiple benchmarks, including desktop environments and video games. Results show that incorporating these skills consistently improves success rates and behavioral efficiency, particularly for models with limited internal visual reasoning capabilities, while also reducing task-solving steps and repetitive actions. MMSkills improve success rates across all evaluated models and benchmarks, with the largest gains observed in weaker visual agents. MMSkills reduce the number of low-level actions and repetitive behaviors, leading to more efficient and structured task execution. The use of MMSkills results in shorter trajectories and more effective state recognition, especially when combined with branch loading and visual evidence filtering.
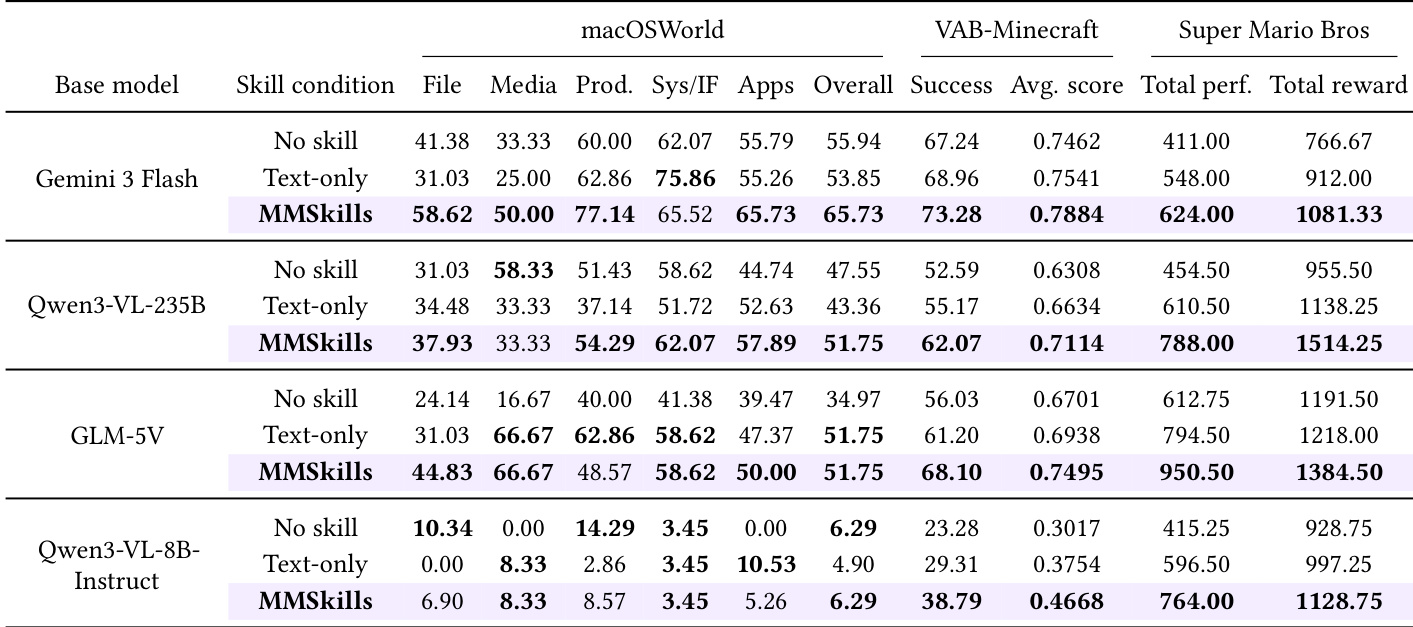
The authors evaluate the impact of MMSkills on visual agents across multiple benchmarks, including desktop applications and game environments. Results show that MMSkills consistently improve performance across different models and domains, with gains observed in both success rates and behavioral efficiency. The effectiveness of MMSkills is attributed to their multimodal nature, which enables better state recognition and more structured task execution. MMSkills improve performance across diverse domains and models, including desktop applications and game environments. The multimodal nature of MMSkills leads to more efficient and goal-directed agent behavior, reducing unnecessary actions and repetitive patterns. MMSkills enable agents to better recognize relevant states and use external knowledge in a targeted manner, improving task-solving efficiency.
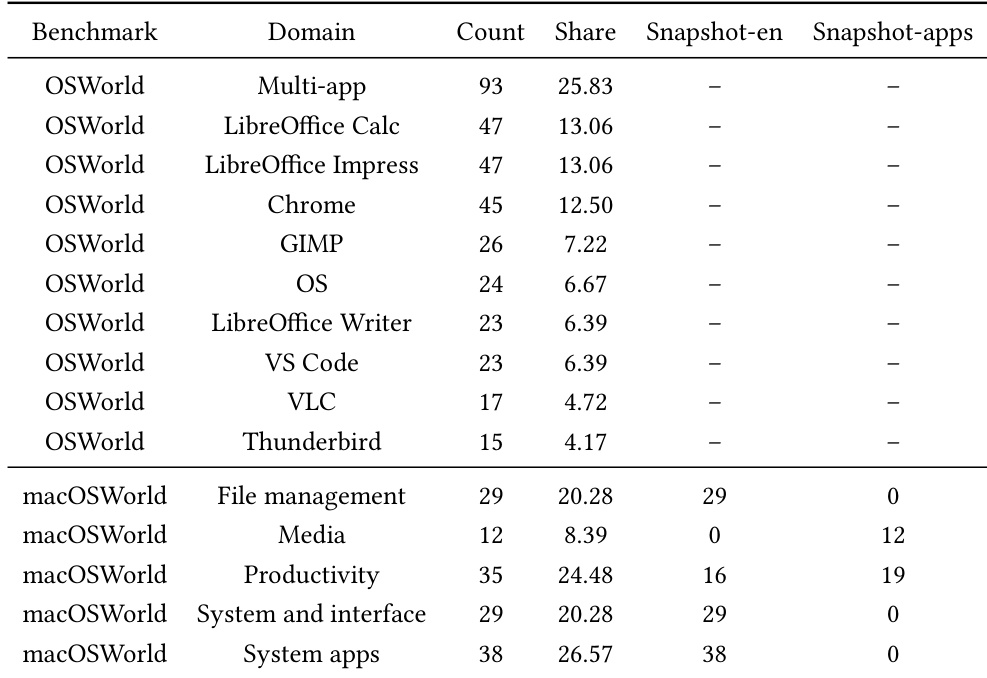
The experimental suite evaluates the integration of multimodal procedural skills into visual agents across various desktop platforms, application domains, and model architectures to validate their impact on task execution and behavioral efficiency. Results consistently demonstrate that incorporating these skills enhances overall success rates while fundamentally reshaping agent interactions by eliminating redundant actions and shortening interaction trajectories. Ultimately, the approach fosters more structured and goal-directed workflows with improved state recognition, delivering the most substantial behavioral improvements for models with weaker intrinsic visual reasoning capabilities.