Command Palette
Search for a command to run...
AI for Auto-Research: Roadmap & User Guide
AI for Auto-Research: Roadmap & User Guide
Abstract
AI-assisted research is crossing a threshold: fully automated systems can now generate research papers for as little as $15, while long-horizon agents can execute experiments, draft manuscripts, and simulate critique with minimal human input. Yet this productivity frontier exposes a deeper integrity problem: under scientific pressure, even frontier LLMs still fabricate results, miss hidden errors, and fail to judge novelty reliably. Studying developments through April 2026, we present an end-to-end analysis of AI across the complete research lifecycle, organized into four epistemological phases: Creation (idea generation, literature review, coding & experiments, tables & figures), Writing (paper writing), Validation (peer review, rebuttal & revision), and Dissemination (posters, slides, videos, social media, project pages, and interactive agents). We identify a sharp, stage-dependent boundary between reliable assistance and unreliable autonomy: AI excels at structured, retrieval-grounded, and tool-mediated tasks, but remains fragile for genuinely novel ideas, research-level experiments, and scientific judgment. Generated ideas often degrade after implementation, research code lags far behind pattern-matching benchmarks, and end-to-end autonomous systems have not yet consistently reached major-venue acceptance standards. We further show that greater automation can obscure rather than eliminate failure modes, making human-governed collaboration the most credible deployment paradigm. Finally, we provide a structured taxonomy, benchmark suite, and tool inventory, cross-stage design principles, and a practitioner-oriented playbook, with resources maintained at our project page.
One-sentence Summary
The authors analyze AI-assisted research through April 2026 across the Creation, Writing, Validation, and Dissemination phases to map a sharp stage-dependent boundary where automated systems reliably handle structured, retrieval-grounded, and tool-mediated tasks but remain fragile for genuinely novel ideas and scientific judgment, ultimately advocating for human-governed collaboration alongside a structured taxonomy, benchmark suite, and practitioner playbook to preserve methodological integrity.
Key Contributions
- This work introduces a lifecycle framework that structures AI-assisted research into four epistemological phases and eight distinct stages, mapping how tool capabilities and errors propagate across the research process.
- An end-to-end analysis identifies a sharp reliability boundary, demonstrating that current systems perform reliably on structured and retrieval-grounded tasks but remain fragile for novel idea generation, experimental execution, and scientific judgment.
- The study provides a structured taxonomy, benchmark suite, tool inventory, and practitioner playbook that codify cross-stage design principles and establish human-governed collaboration as the most credible paradigm for maintaining research accountability.
Introduction
AI-driven research tools are rapidly evolving from isolated writing or coding assistants into end-to-end systems capable of orchestrating complete scientific workflows. This transition matters because it fundamentally reshapes how hypotheses are generated, experiments are executed, and findings are validated, yet it exposes a critical integrity gap: current models excel at producing surface-level artifacts while struggling to verify novelty, maintain experimental faithfulness, or preserve traceable provenance across stages. To address these limitations, the authors introduce a comprehensive lifecycle framework that maps AI capabilities across four epistemological phases and eight research stages, supported by a unified taxonomy, benchmark suite, and tool inventory. They demonstrate that fully autonomous systems remain prone to compounding errors and unfulfilled commitments, ultimately arguing that human-governed collaboration with explicit verification checkpoints offers the most scientifically credible path forward.
Dataset

-
Dataset composition and sources: The authors compile a comprehensive survey corpus tracking AI tools, methods, and benchmarks that support human-driven academic research. They gather these resources through systematic keyword searches across Google Scholar, Semantic Scholar, arXiv, and DBLP, snowball citation tracing from representative seed papers, and continuous monitoring of open-source repositories and community leaderboards.
-
Key details for each subset: The corpus spans four research lifecycle phases but shows uneven distribution, with Creation tools most extensively documented. Notable benchmarks include IdeaBench (2,374 papers across eight domains), LiveIdeaBench (1,180 keyword prompts across twenty-two domains), AI Idea Bench 2025 (3,495 papers), ReviewMT (26,841 papers and 92,017 reviews from ICLR and Nature Communications), and Re² (19,926 submissions, 70,668 reviews, and 53,818 rebuttals across twenty-four conferences). The collection also tracks specialized systems for scientific visualization, formula rendering, and LaTeX generation.
-
How the paper uses the data: The authors organize the collected works by research phase and stage maturity to analyze tool evolution, performance gaps, and workflow integration. They leverage the benchmarks to demonstrate that models often excel at generating plausible ideas but struggle with practical feasibility and temporal impact. The peer review datasets are used to quantify how rebuttals influence scoring outcomes and to evaluate multi-turn dialogue simulation for academic critique.
-
Processing and metadata construction: The corpus was filtered using three strict inclusion criteria: alignment with a defined research lifecycle stage, public accessibility, and sufficient methodological or evaluative detail. When multiple versions of a system exist, the authors retain the most recent or technically complete iteration while documenting historical milestones. Reviewer comments are decomposed into structured, actionable concerns to facilitate rebuttal generation, and visualization tools are evaluated against execution pass rates and multi-agent quality benchmarks. The authors also apply time-split impact metrics to separate apparent novelty from genuine research potential.
Method
The authors present a four-phase framework for AI-assisted research, organized around the functional stages of scientific inquiry: Creation, Writing, Validation, and Dissemination. This framework structures the research lifecycle into distinct, interconnected phases, each with specific objectives and methodological requirements. The overall architecture is designed to reflect the epistemological progression from idea formation to public communication, with feedback loops that allow for iterative refinement across stages. 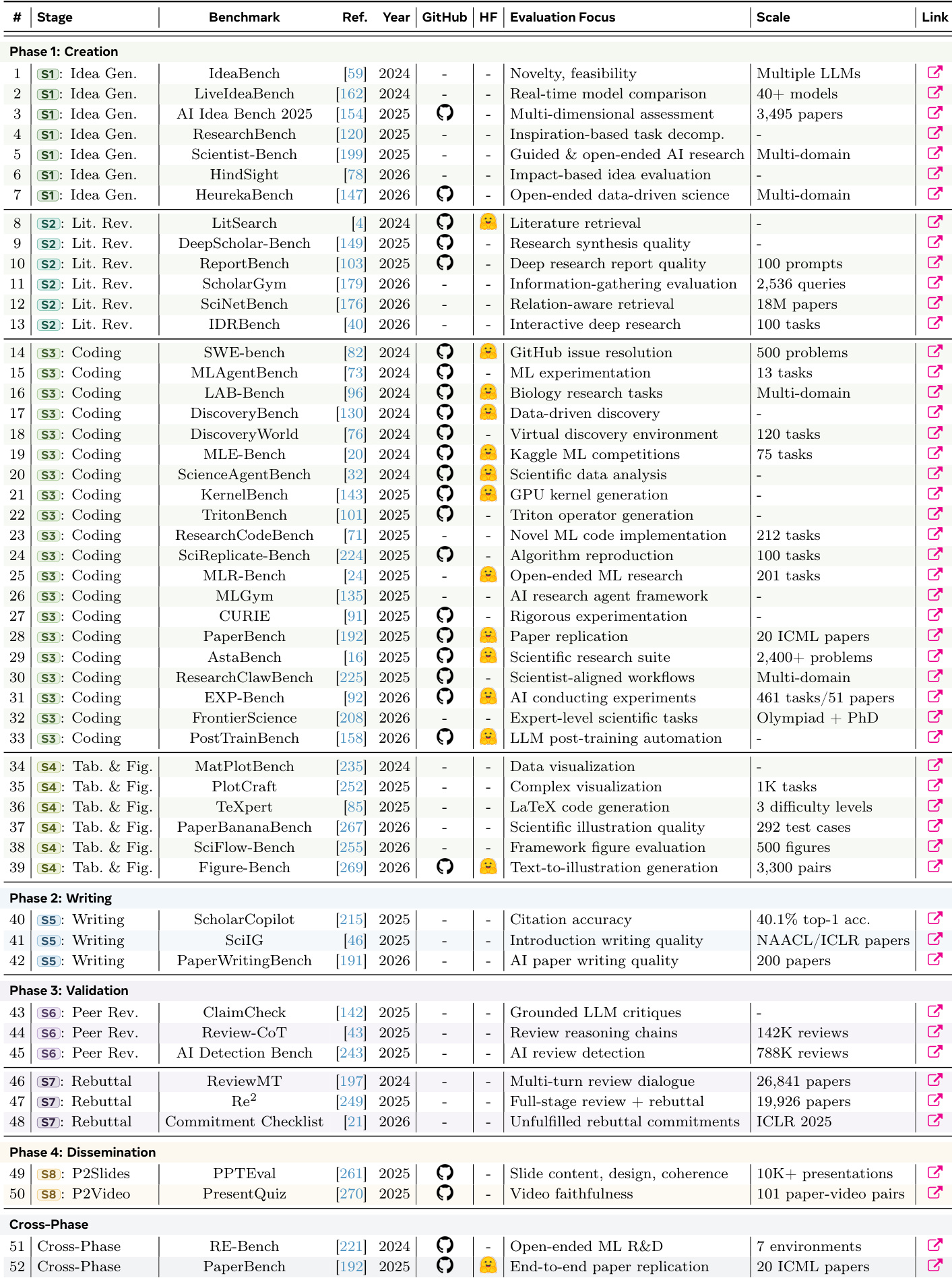
The first phase, Creation, encompasses the generation, refinement, and evaluation of research hypotheses. This stage leverages techniques such as direct large language model (LLM) prompting, retrieval-augmented generation (RAG) grounded in external literature, knowledge-graph reasoning, and multi-agent collaboration to produce structured and well-grounded hypotheses. The authors emphasize that external signal-driven methods, including knowledge graphs and paper retrieval, are critical for connecting generated ideas to the existing research frontier, thereby enhancing novelty and feasibility. Multi-agent systems simulate collaborative scientific discourse, with role specialization and critique mechanisms, to improve idea quality. However, the efficacy of such systems is bounded by the risk of diversity collapse, where ideas cluster in narrow regions of the idea space. 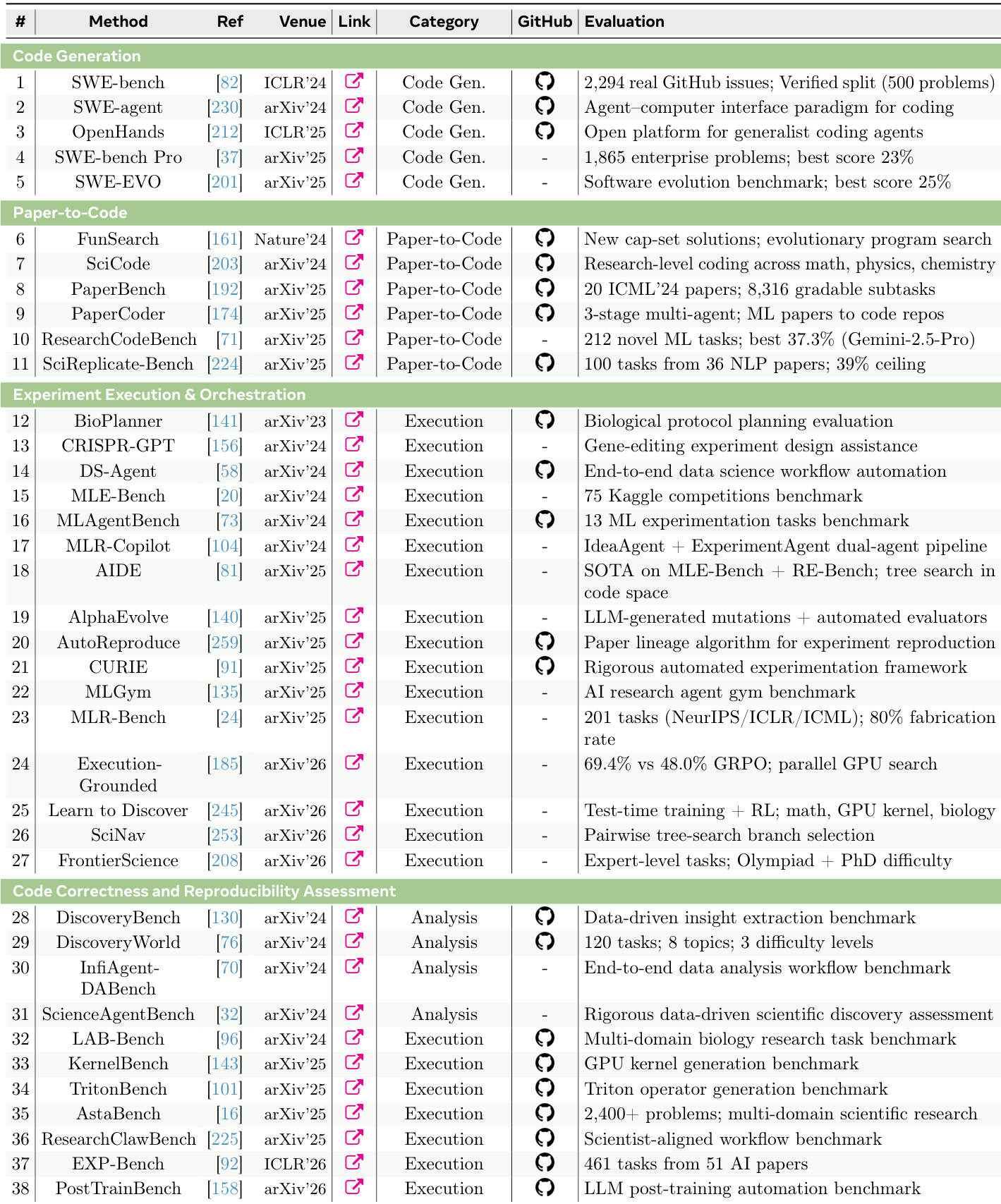
The second phase, Writing, focuses on transforming the artifacts from Creation into a coherent scholarly manuscript. This involves the generation of survey sections, related work, and the full paper. The process shifts from retrieval-oriented tasks to synthesis, requiring the identification of themes, comparison of methods, and articulation of research gaps. Systems in this phase employ increasingly structured designs, from single-pass generation to multi-agent decomposition that separates retrieval, verification, and narrative writing into specialized subtasks. Citation-aware systems further integrate synthesis with the writing environment, embedding reference discovery directly into tools like LaTeX editors. Despite advances, citation fidelity remains a significant challenge, as generating plausible text is easier than grounding each claim in the correct source. 
The third phase, Validation, centers on external scrutiny and revision. It begins with peer review, where AI systems generate critiques, summarize reviewer opinions, and assist in reviewer matching. The subsequent stage, Rebuttal and Revision, involves analyzing reviewer comments, identifying required evidence, drafting responses, and supporting manuscript revision. This phase is critical as it forms a feedback loop, where reviewer critiques can trigger new experiments, revised analyses, or updated figures, potentially redirecting the workflow back to earlier phases. AI systems in this stage move beyond simple text generation to evidence-grounded response planning, decomposing concerns into atomic issues and retrieving supporting literature. However, the core challenge remains ensuring that rebuttals are evidence-based and that author commitments are fulfilled.
The final phase, Dissemination, converts the validated manuscript into formats accessible to broader audiences, including posters, slides, videos, social media content, and interactive agents. This stage is distinct from earlier phases because its outputs are independent knowledge artifacts, each requiring tailored design choices and communication strategies. The central challenge is preserving scientific fidelity while adapting the work to new modalities. For example, a poster must compress the contribution into a visual narrative, while a video must synchronize visual, textual, and spoken channels. Evaluation in this phase focuses on fidelity, usability, and adoption, as dissemination artifacts often circulate independently of the original paper and can shape public understanding.
Experiment
The evaluation framework spans the entire research lifecycle, utilizing multi-dimensional benchmarks that validate process-aware workflows, artifact fidelity, and peer review support across distinct research stages. Qualitative analysis reveals that AI excels at structured, verifiable tasks but consistently struggles with open-ended judgment and scientific validation, highlighting a persistent gap between visual plausibility and factual accuracy. Consequently, the most reliable deployment strategy relies on human-governed collaboration where automated systems handle mechanical generation while researchers retain interpretive responsibility and accountability. Ultimately, the findings indicate that AI integration in research is evolving from a technical capability challenge into a governance and orchestration problem requiring robust disclosure practices and layered feedback architectures.
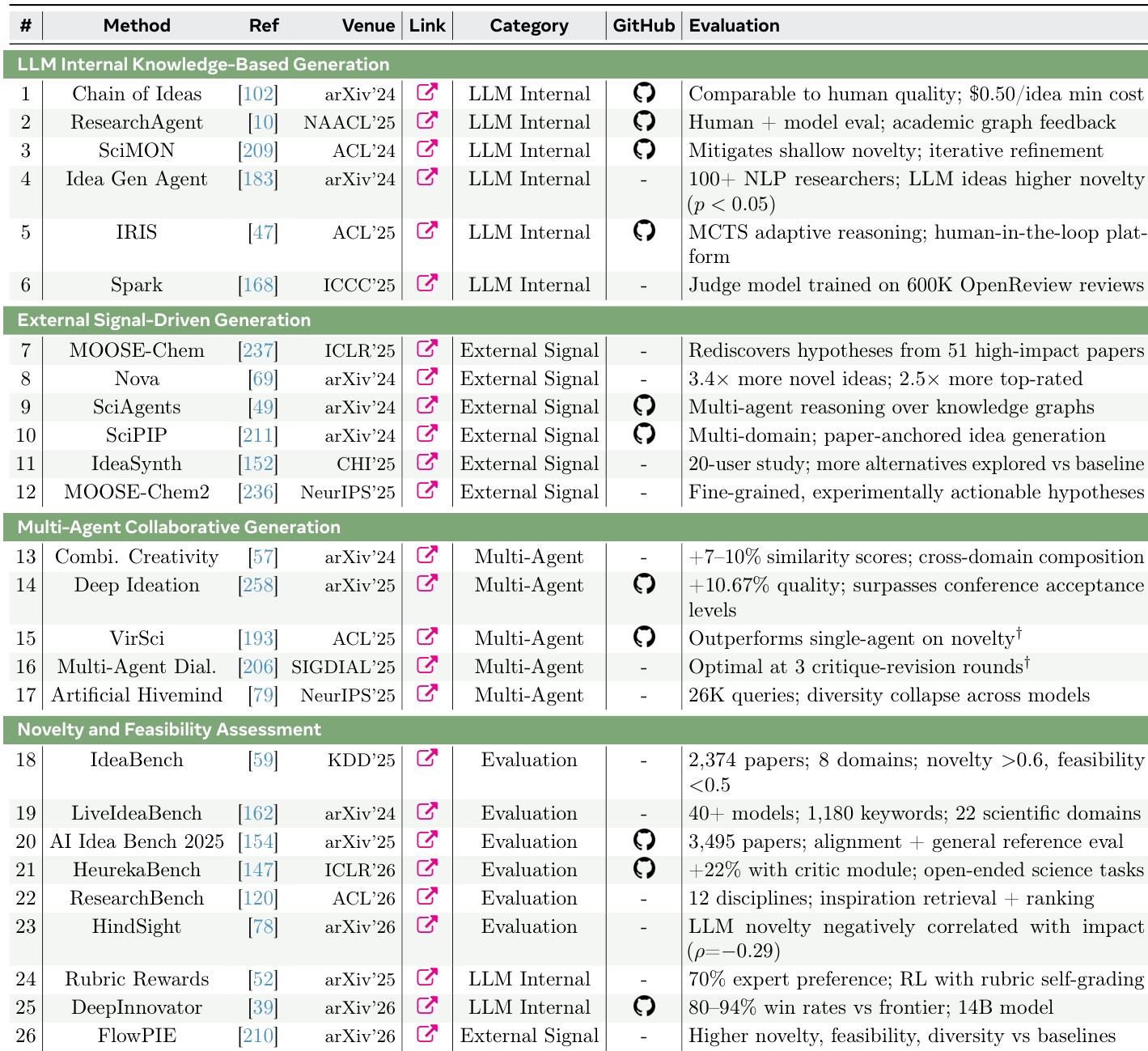
The the the table presents a comprehensive inventory of AI systems across different stages of the research lifecycle, including idea generation, coding, visualization, and peer review. It highlights a diversity of approaches, from single-agent LLM-based methods to multi-agent collaborative systems, with evaluations focusing on novelty, feasibility, and alignment with expert judgment. The systems are categorized by their underlying mechanisms, such as internal knowledge, external signals, or multi-agent coordination, and show varying degrees of maturity and performance across different research tasks. Systems are categorized by their approach, including LLM internal, external signal, and multi-agent methods, each targeting different aspects of the research process. Evaluation metrics emphasize novelty, feasibility, and alignment with expert judgment, reflecting a shift toward multi-dimensional assessment. Multi-agent systems demonstrate superior performance in certain tasks, such as novelty and cross-domain composition, compared to single-agent models.
The authors present a comprehensive inventory of AI systems across the research lifecycle, focusing on code generation, experiment execution, and reproducibility assessment. The the the table highlights diverse methods and benchmarks, with a notable emphasis on evaluation frameworks that assess both technical performance and scientific validity in research workflows. The the the table categorizes systems by research stage, showing a progression from code generation to experiment execution and reproducibility assessment. Evaluation metrics vary widely, ranging from performance on specific tasks to broader assessments of scientific accuracy and reproducibility. Many systems are evaluated on real-world datasets or benchmarks, with some emphasizing human-in-the-loop validation or multi-stage workflows.
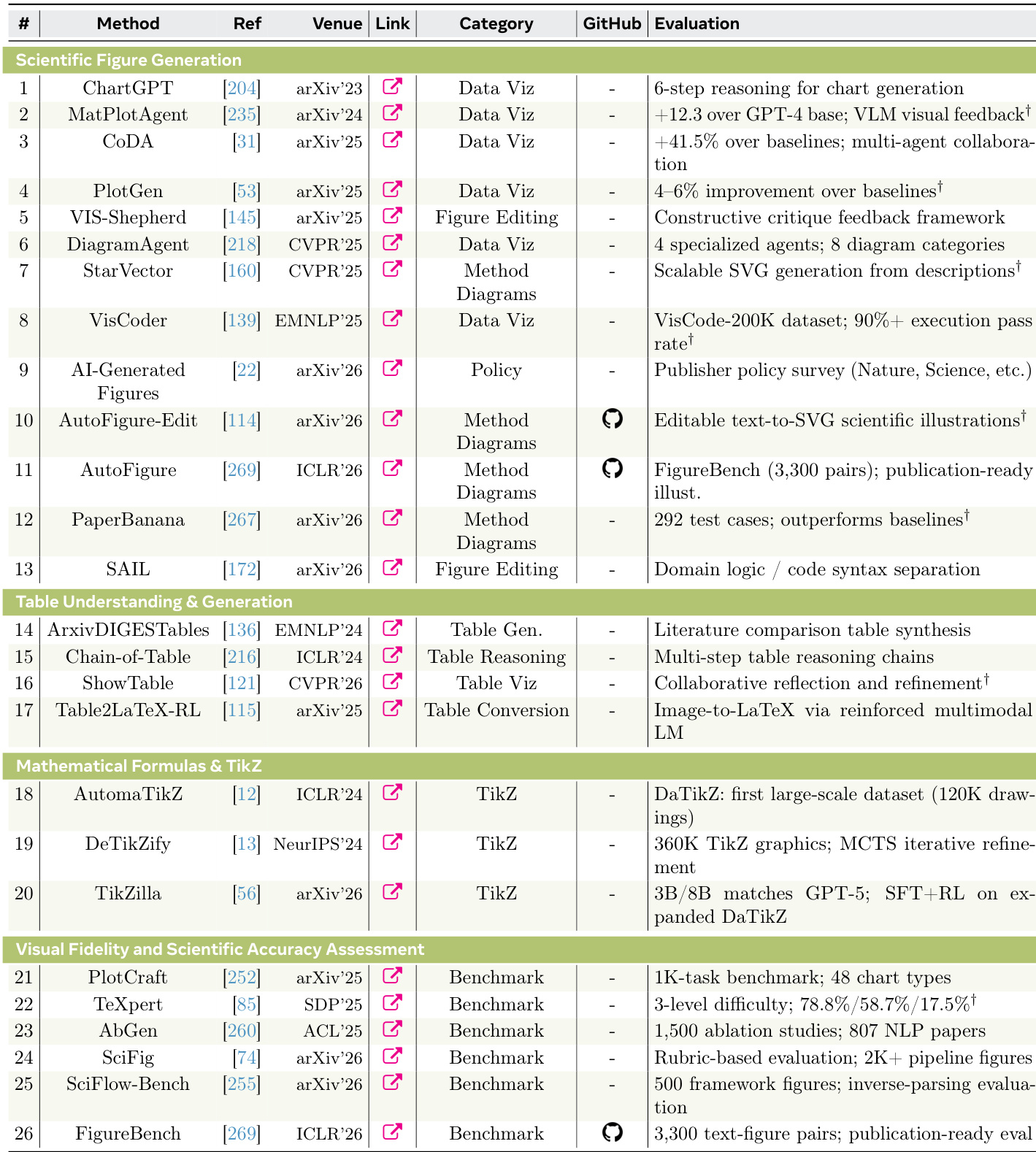
The authors analyze the state of AI systems for generating scientific artifacts, focusing on figure, the the table, and formula generation across different research stages. Results show that while many systems can produce visually plausible outputs, significant challenges remain in ensuring scientific accuracy and correctness, particularly in complex domains like method diagrams and ablation tables. The evaluation landscape is evolving toward multi-dimensional, process-aware benchmarks that assess both visual fidelity and semantic correctness. AI-generated scientific figures and tables often appear professional but can contain critical errors in labels, layouts, or quantitative relationships. Evaluation methods are shifting from assessing isolated outputs to measuring both visual quality and scientific correctness across multiple dimensions. The most advanced systems are those that combine structured data with domain-specific knowledge, while simpler visual outputs are more reliably generated.
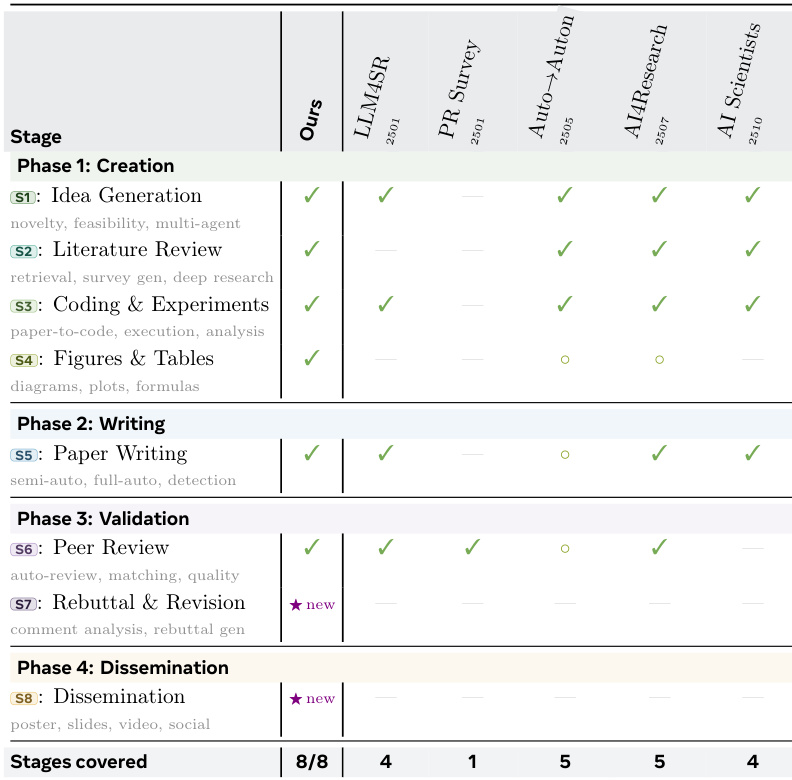
{"summary": "The authors present a structured evaluation of AI systems across multiple stages of the research lifecycle, highlighting the capabilities and coverage of different approaches. The the the table shows that while several systems cover multiple phases, the focus varies significantly, with some emphasizing creation and writing, while others prioritize validation and dissemination.", "highlights": ["The proposed system covers all eight stages of the research lifecycle, demonstrating comprehensive coverage compared to other systems.", "Most existing systems focus on a subset of stages, with limited overlap in their capabilities across different phases.", "The evaluation reveals that no single system addresses all aspects of research, particularly in validation and dissemination, where coverage is minimal."]
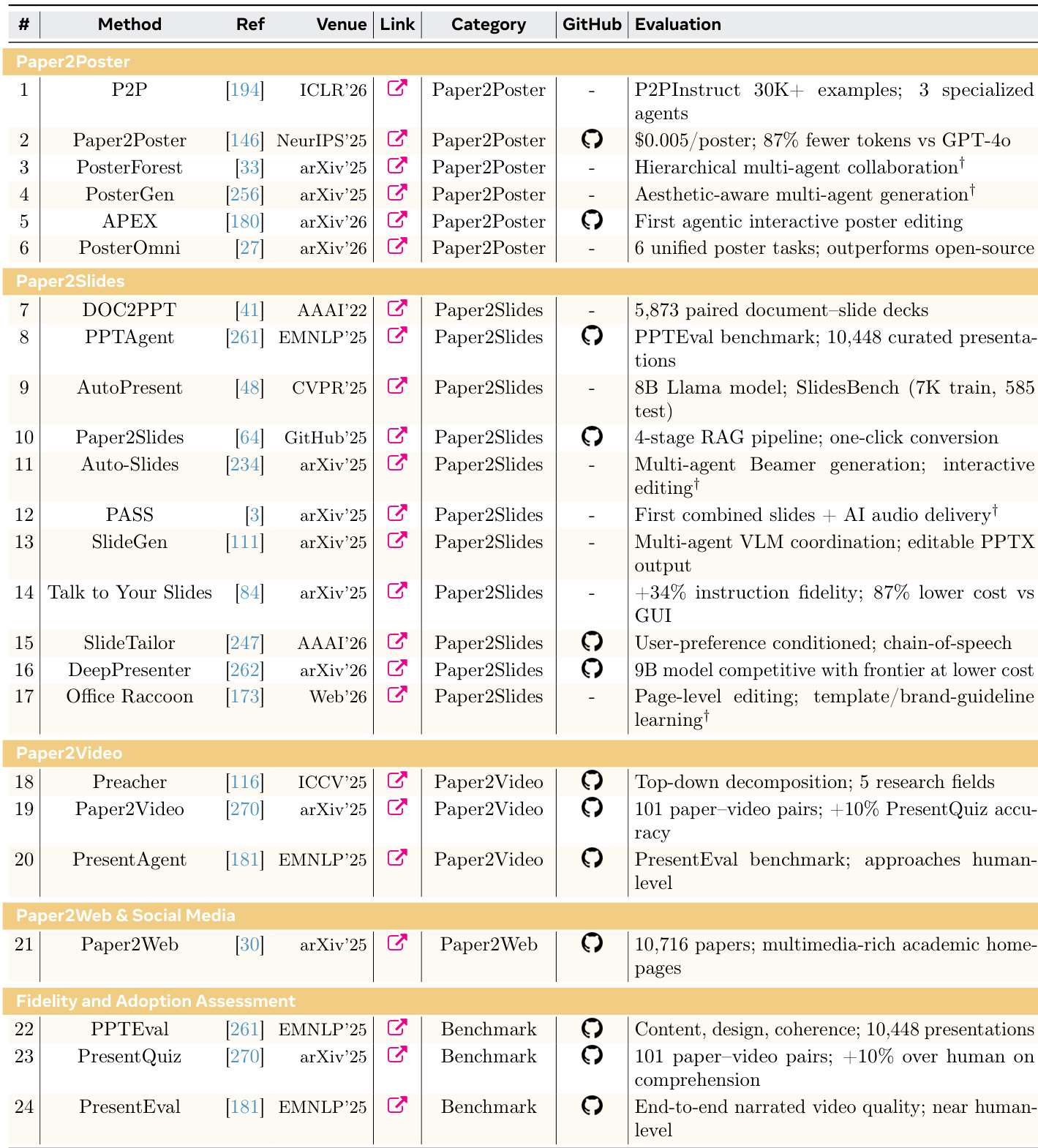
The the the table presents a comprehensive inventory of systems across various research artifact generation stages, including poster, slide, video, and web content creation, as well as fidelity assessment benchmarks. These systems vary in their evaluation methods and deployment contexts, with some relying on large-scale datasets and others focusing on interactive or user-guided workflows. The evaluation approaches span from automated benchmarking to human-level performance comparisons, highlighting diverse strategies for assessing output quality. Systems for generating research artifacts such as posters, slides, and videos are evaluated using both automated benchmarks and human-level comparisons. The the the table includes methods that rely on large-scale datasets and those that incorporate interactive or user-guided workflows. Evaluation strategies range from structured benchmarking to fidelity assessments, reflecting a broad spectrum of quality measures.
The experiments evaluate a diverse range of AI systems across the research lifecycle using multi-dimensional benchmarks that combine automated testing with human-in-the-loop validation to assess novelty, feasibility, scientific accuracy, and visual fidelity. These evaluations validate the effectiveness of different architectural approaches, lifecycle stage coverage, and the reliability of generated research artifacts. Qualitative findings reveal that multi-agent architectures consistently outperform single-agent models in novelty and cross-domain tasks, while integrated domain knowledge significantly improves output correctness. Despite these advances, current tools struggle with rigorous accuracy in complex scientific content and lack comprehensive coverage across all research phases, prompting a field-wide shift toward process-aware evaluation frameworks that prioritize semantic correctness and expert alignment over isolated performance metrics.