Command Palette
Search for a command to run...
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
Abstract
We present GoLongRL, a fully open-source, capability-oriented post-training recipe for long-context reinforcement learning with verifiable rewards (RLVR). Existing long-context RL methods often treat data construction as a matter of designing increasingly complex retrieval paths, leading to homogeneous task coverage and reward formulations that inadequately reflect practical long-context requirements. Our work offers two contributions. (1) Capability-oriented data construction with full open release. We openly release a dataset of 23K RLVR samples, the complete construction pipeline, and all training code. Guided by a taxonomy of long-context capabilities, the dataset spans 9 task types, each paired with its natural evaluation metric. It comprises curated open-source samples from established corpora and synthetic samples whose QA pairs are generated from real source documents such as books, academic papers, and multi-turn dialogues. Under the same vanilla GRPO setup, our dataset alone outperforms the closed-source QwenLong-L1.5 dataset. Moreover, our Qwen3-30B-A3B model trained on this data delivers long-context performance comparable to DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking-2507, suggesting that broader coverage and greater reward diversity substantially benefit long-context capability improvement. (2) TMN-Reweight for heterogeneous multitask optimization. To address optimization challenges from heterogeneous rewards, we propose TMN-Reweight, which combines task-level mean normalization for cross-task reward scale alignment with difficulty-adaptive weighting for more reliable advantage estimation. TMN-Reweight further improves average performance over vanilla GRPO, with general capabilities preserved or improved across reported evaluations.
One-sentence Summary
The authors present GoLongRL, a fully open-source post-training framework for long-context reinforcement learning with verifiable rewards that integrates a 23K-sample dataset spanning nine capability-driven task types with TMN-Reweight, a multitask optimization strategy employing task-level mean normalization and difficulty-adaptive weighting to align heterogeneous rewards, enabling the Qwen3-30B-A3B model to match the long-context performance of DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking-2507 while preserving general capabilities over vanilla GRPO.
Key Contributions
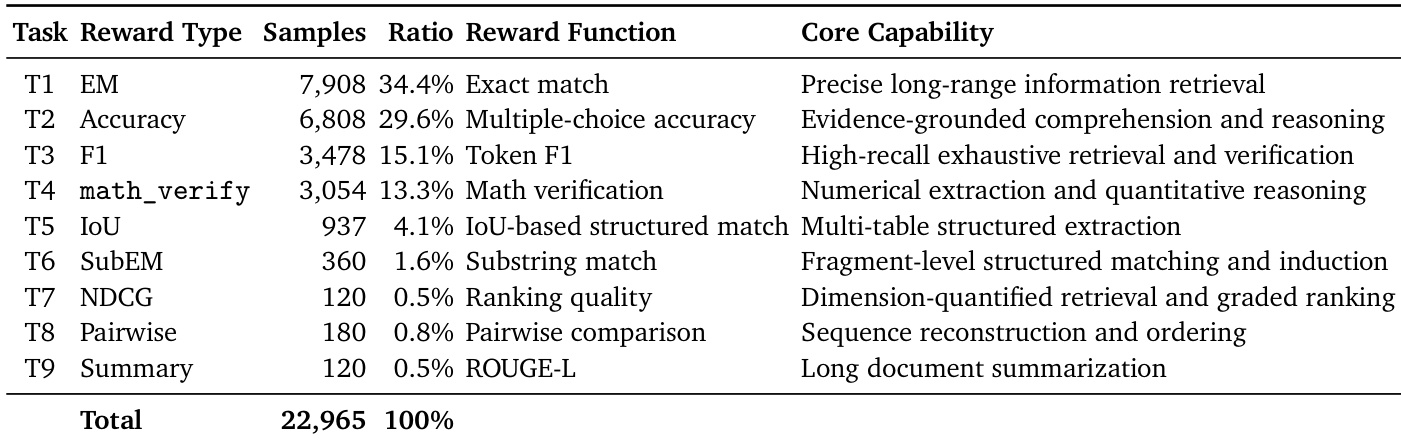
- The work introduces GoLongRL, a fully open-source capability-oriented dataset and construction pipeline containing 23,000 long-context RLVR samples. Guided by a nine-task taxonomy, the collection integrates curated and synthetically generated question-answer pairs from real documents to ensure broad task coverage and reward diversity.
- The paper proposes TMN-Reweight, a training strategy that combines task-level mean normalization with difficulty-adaptive weighting to resolve cross-task reward scale inconsistency and difficulty-induced advantage bias. The mechanism aligns heterogeneous reward distributions and enables more reliable advantage estimation during policy updates.
- Models trained on the released dataset and optimization method achieve long-context performance comparable to DeepSeek-R1-0528 and Qwen3-235B-A22B-Thinking-2507. Specifically, the Qwen3-30B-A3B variant trained on this data surpasses the closed-source QwenLong-L1.5 baseline under standard GRPO setups while preserving general capabilities.
Introduction
As large language models expand into practical domains like retrieval-augmented generation and agentic workflows, effectively reasoning over tens of thousands of tokens has become a critical bottleneck for post-training optimization. Existing long-context reinforcement learning methods typically rely on narrow retrieval-focused datasets and standard algorithms like GRPO, which struggle with heterogeneous multitask objectives. Per-prompt normalization in GRPO distorts advantage estimates across varying prompt difficulties, while mixing evaluation metrics with different numerical scales causes gradient imbalance and unstable training trajectories. To address these limitations, the authors introduce GoLongRL, a capability-oriented framework that combines a fully open dataset of 23,000 samples spanning nine distinct task types with a novel optimization strategy called TMN-Reweight. By applying task-level mean normalization alongside difficulty-adaptive weighting, their approach aligns cross-task reward scales and produces more reliable advantage estimates, delivering substantial long-context gains while preserving general reasoning capabilities.
Dataset

-
Dataset Composition and Sources
- The authors construct a 22,965-sample dataset spanning 9 capability-oriented tasks with context lengths ranging from 0.1K to 256K tokens.
- The data draws from two complementary pools containing approximately 14,000 curated open-source samples and 9,000 synthetic question-answer pairs generated exclusively from real-world documents.
- Source materials include Project Gutenberg books, arXiv CC0 academic papers, PMC biomedical articles, legal filings, financial reports, and multi-turn dialogues from BEAM and Oolong.
-
Key Details for Each Subset
- Tasks T1 through T4 form the training backbone, comprising over 90 percent of the dataset due to abundant source availability.
- Tasks T6 through T9 account for less than 4 percent, with the authors prioritizing quality over volume given the scarcity of naturally supporting documents.
- The synthetic track focuses heavily on Task T2, which uses a multiple-choice format for reliable automatic verification. Subcategories include evidence integration, rule induction, and dialogue memory tracking requiring over 50 turns and 30K tokens.
- Open-source samples undergo compatibility filtering to ensure annotations align with the target reward format. For example, Task T1 retains only short reference spans to prevent exact match ambiguity.
- Synthetic samples are calibrated into difficulty tiers using model pass rates, yielding an approximate easy to medium to hard ratio of 3:6:1. Samples with consistently low pass rates across model scales are discarded as noisy.
-
Data Usage and Training Configuration
- The authors employ the dataset for long-context reinforcement learning with verifiable rewards, assigning each task its natural evaluation metric as the reward function to preserve semantic fidelity.
- The training mixture is intentionally non-uniform, emphasizing foundational retrieval and reasoning capabilities while maintaining sparse but high-quality samples for advanced tasks.
- During iterative refinement, the dataset is filtered against benchmark queries using 13-gram overlap checks to prevent data contamination.
- The authors continuously evaluate weak capability dimensions during training, removing samples that exhibit reward hacking or answer ambiguity while supplementing underperforming tasks with freshly synthesized pairs.
-
Processing, Metadata and Structural Details
- Documents are tokenized and routed to length-specific bins, directing shorter sequences to DeepSeek V3.2 and longer sequences to Gemini-2.5-Pro for question generation.
- The authors standardize output metadata by enforcing a unified structure that begins with an [Answer] identifier, followed by task-specific formatting such as ordered lists for ranking tasks or parsable expressions for numerical reasoning.
- Synthetic prompts require the generation of plausible distractors, text-verifiable correct options, and explicit design rationales to ensure robust evaluation.
- The final dataset undergoes multiple version iterations, with each cycle validated on an 8K random subset before scaling to full model training.
Method
The authors leverage a multi-stage framework for constructing a capability-oriented long-context reinforcement learning (RL) dataset, which integrates both open-source and synthetic data. The overall process begins with a source corpus, from which metadata-based filtering isolates task-classified documents. These documents are then subjected to task-specific selection criteria to generate qualified samples, forming the foundation for a task-oriented filtering and assignment stage. This stage assigns each document to one of nine distinct task types, enabling the construction of a diverse training dataset.
The core of the dataset creation lies in the P3. Long-Context Sample Construction phase, which processes the filtered documents through two parallel tracks: Open-Source and Synthetic. The Open-Source track involves compatibility filtering and reward format standardization, ensuring consistency across data sources. The Synthetic track generates new long-contexts and overlong contexts, which are then used to create question-answer (QA) pairs. This generation process employs models such as DeepSeek-V3.2 and Gemini-2.5-Pro for initial QA pair creation, which are subsequently verified for quality.
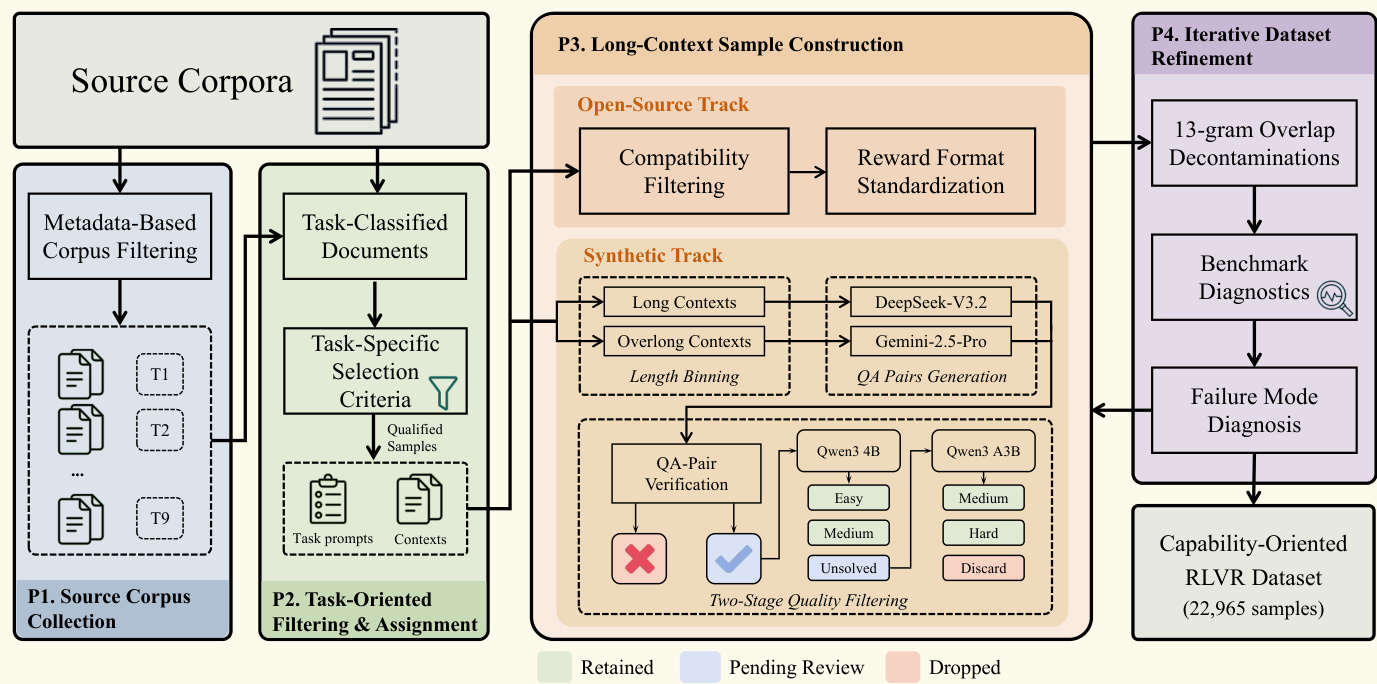
The framework diagram illustrates that the QA pairs are passed through a two-stage quality filtering process. The first stage is QA-pair verification, where a rigorous assessment by a model like Gemini-2.5-Pro checks for answer uniqueness, distractor quality, hallucination, task compliance, and language consistency. Pairs failing this verification are discarded. The second stage, Two-Stage Quality Filtering, further evaluates the remaining pairs using a model like Qwen3-4B to classify them into difficulty levels—Easy, Medium, Hard, Unsolved, or Discard—based on their response quality. This filtered dataset is then refined through an iterative process in P4. Iterative Dataset Refinement, which includes steps like 13-gram overlap decontamination, benchmark diagnostics, and failure mode diagnosis. The final output is a capability-oriented RLVR dataset containing 22,965 samples, designed to support robust and stable multitask training.
The training process itself is built upon a Group Relative Policy Optimization (GRPO) framework, which serves as the base RL algorithm. Unlike traditional PPO, GRPO eliminates the need for a separate value network by estimating advantages through group-level z-score normalization of rewards. For each prompt, a group of candidate responses is sampled, and their rewards are normalized using the group's mean and standard deviation to compute response advantages. The policy is updated by maximizing a clipped surrogate objective that incorporates these advantages. To address biases in the standard GRPO formulation, the authors employ Dr. GRPO, which removes the per-prompt standard deviation normalization to mitigate question-level difficulty bias and replaces length normalization with a global constant to reduce response length bias. However, this approach can lead to cross-task scale discrepancies in multitask settings.
To resolve these issues, the authors introduce TMN-Reweight, a two-step method for advantage estimation. The first step, task-level mean normalization, replaces per-prompt standard deviation with a task-level aggregated standard deviation, computed as the root mean square of per-prompt standard deviations within the same task. This operation reduces cross-task scale differences while preserving the relative advantage magnitudes within each task. The second step, difficulty-adaptive reweighting, estimates prompt difficulty using a smoothed pass rate and applies exponential weighting to adjust the learning signal. This weighting is applied asymmetrically based on the sign of the normalized advantage to amplify gradients for rare successful rollouts on hard prompts and attenuate gradients for easy prompts to prevent entropy collapse. This four-quadrant gradient reallocation mechanism ensures that the model learns effectively across a wide range of difficulty levels without destabilizing the optimization process.
Experiment
Context Requirement: Full Metric: Accuracy
Output format: Output the "[Answer]" identifier first, then output the answer option letter (A/B/C/D), without any additional content.
[Answer] C
- B.4.3. T2-c: Long-Range Entity and Commitment Tracking
Track entity states and commitments across extended dialogue or narrative context.
T2-c: Long-Range Entity and Commitment Tracking
Primary Task: Dialogue Memory and Long-Horizon Tracking Track and respond to dialogue history.
Secondary Task: Long-Range Entity and Commitment Tracking Track entity states across the global context. Context Requirement: Full Metric: Accuracy
Output format: Output the "[Answer]" identifier first, then output A/B/C/D/E, without any additional content.
[Answer] B
- B.6. T4: Numerical Extraction and Quantitative Reasoning
T4 evaluates the model's ability to perform numerical calculations within structured text such as financial tables and reports. The reward function uses math_verify. Subtask prompts cover both multi-source consistency verification and single-source targeted aggregation.
- B.6.3. T4-c: Procedural State Tracking
Track entity state evolution across a long procedural narrative.
T4-c: Procedural State Tracking
Primary Task: Structured and Numeric Reasoning Numerical calculations in structured text.
Secondary Task: Long-Context Procedural State Tracking Track entity state evolution across the full context. Context Requirement: Full Metric: math_verify
Output format: Output the "[Answer]" identifier first, then output tracked states line by line, without any additional content.
[Answer] state_1 state_2
- B.8. T6: Fragment-Level Structured Matching and Induction
T6 assesses the model's ability to perform clustering, rule induction, and structured matching at the fragment level. The reward function is Substring Exact Match (SubEM). This task covers large-scale document clustering, rule induction from examples, and related pattern recognition subtasks.
- B.9. T7: Dimension-Quantified Retrieval and Graded Ranking
T7 evaluates the model's ability to retrieve content and rank results by relevance or a quantified dimension. The reward function is NDCG.
- B.10. T8: Sequence Reconstruction and Ordering
T8 evaluates the model's ability to restore temporal, logical, or frequency-based orderings. The reward function is Pairwise Accuracy.
- B.11. T9: Long Document Summarization
T9 evaluates the model's ability to generate abstractive summaries under specified constraints. The reward function is ROUGE-L.
- C. Evaluation Alignment with QwenLong-L1.5
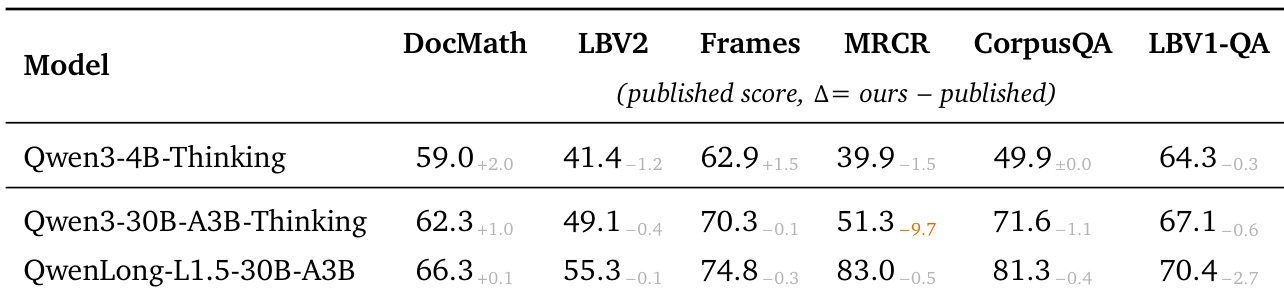
To ensure a fair comparison with QwenLong-L1.5, the paper verify that the evaluation pipeline faithfully reproduces the results reported in the original paper. Tables 9, 10, and 11 present the published scores with Δ=ours--published shown as a subscript next to each value. Deviations within a small margin are shown in gray; larger deviations are highlighted in orange. Across most benchmarks, the deviations are small, confirming that the evaluation protocol is well-aligned with that of QwenLong-L1.5.
the table | Evaluation protocol alignment against the QwenLong-L1.5 paper. Each cell reports the published score with Δ = ours – published as a subscript.
- D. Training Hyperparameters
the table summarizes the key hyperparameters used in the RL training. All configurations are shared across the two model scales.
the table | Evaluation protocol alignment on general reasoning benchmarks. Each cell reports the published score with Δ = ours – published as a subscript.

the table | Evaluation protocol alignment on agentic and dialogue memory benchmarks. Each cell reports the published score with Δ = ours – published as a subscript.
the table | Training hyperparameters for GoLongRL.
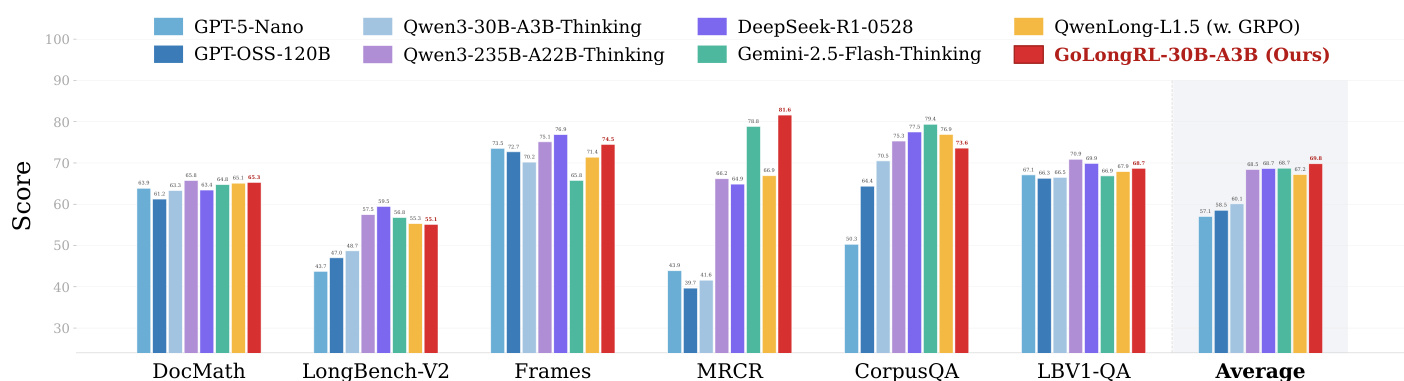
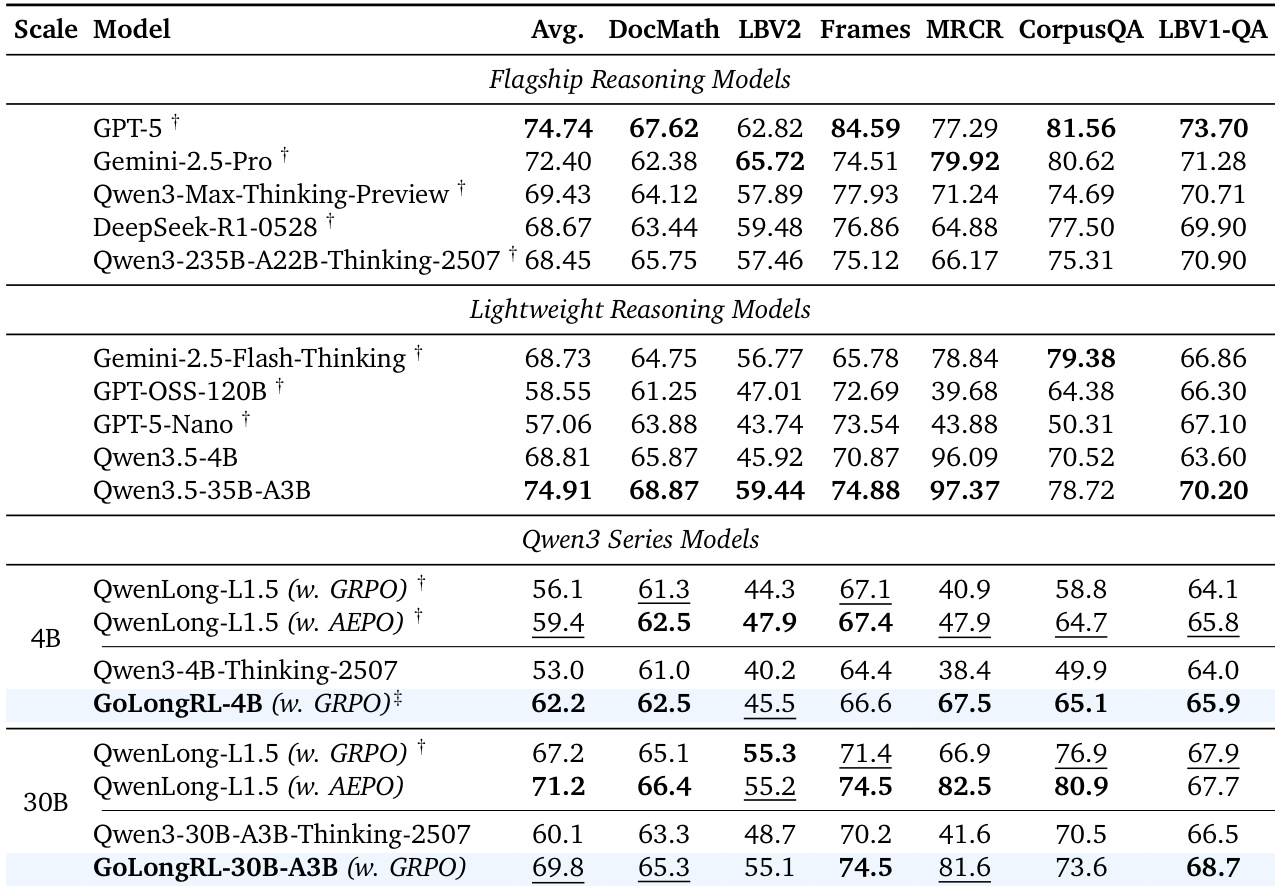
The authors compare their proposed GoLongRL method with QwenLong-L1.5 and other baselines on long-context benchmarks, using a controlled experimental setup that isolates the impact of data and algorithmic improvements. Results show that GoLongRL achieves higher average performance and better balance across diverse reasoning tasks, with notable gains on aggregation-intensive benchmarks. The method also demonstrates general capability retention and strong extrapolation to longer contexts. GoLongRL achieves higher average performance and better task balance compared to QwenLong-L1.5 and other baselines on long-context benchmarks. The method shows significant improvements on aggregation-intensive tasks like CorpusQA while maintaining strong performance on retrieval-oriented tasks. GoLongRL preserves general reasoning capabilities and demonstrates strong extrapolation to longer context lengths.

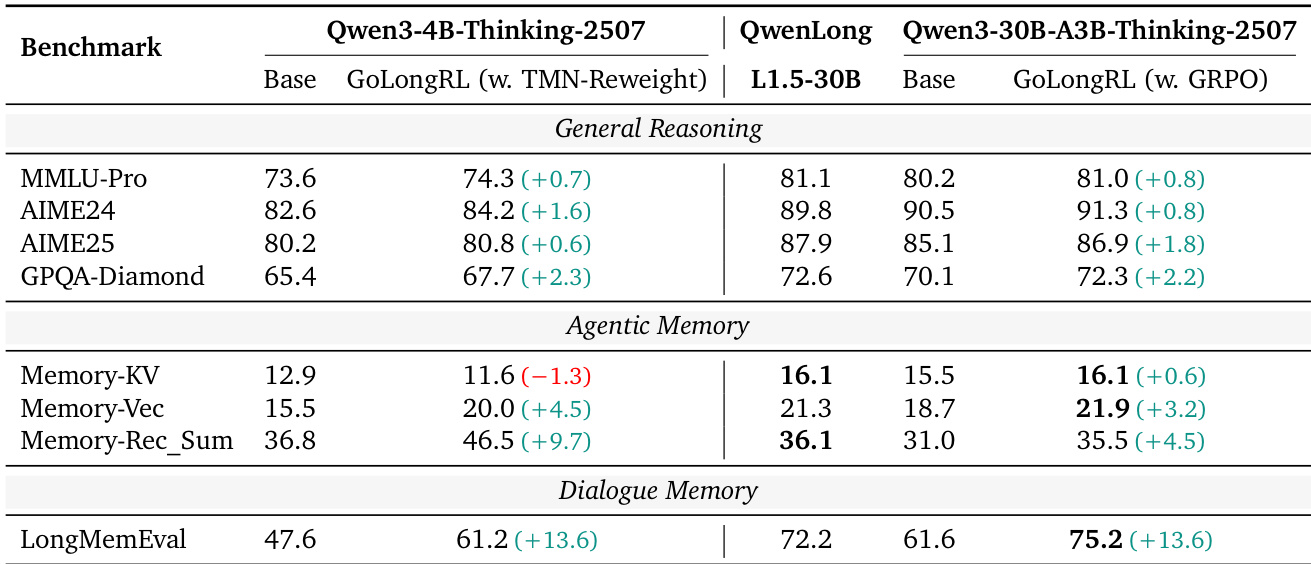
The authors evaluate the impact of their long-context reinforcement learning method, GoLongRL, on general reasoning and memory capabilities using Qwen3-30B and QwenLong-L1.5 models. Results show that GoLongRL preserves general reasoning skills while improving performance on memory and long-range context tasks. The evaluation confirms that the method maintains consistency with prior results on standard benchmarks, with minor deviations in scores due to protocol alignment. GoLongRL preserves general reasoning capabilities while improving performance on memory and long-range context tasks. The method maintains consistency with prior results on standard benchmarks, with minor deviations in scores. Both Qwen3-30B and QwenLong-L1.5 models show improvements in memory and long-range dependency handling.
The authors compare the performance of various models on long-context reasoning benchmarks, focusing on the Qwen3 series. Results show that GoLongRL models, particularly at the 4B scale, achieve competitive or superior performance across multiple tasks, with notable improvements on aggregation-intensive benchmarks. The evaluation includes both flagship and lightweight models, with the GoLongRL-4B and GoLongRL-30B models demonstrating strong results in specific areas such as retrieval and reasoning. GoLongRL-4B achieves the highest average score among lightweight models on several benchmarks, including MRCR and CorpusQA. GoLongRL-30B shows significant improvements in retrieval and reasoning tasks compared to baseline models, particularly on MRCR and CorpusQA. The performance of GoLongRL models is competitive with or exceeds that of other state-of-the-art models in the Qwen3 series, indicating effective long-context training.
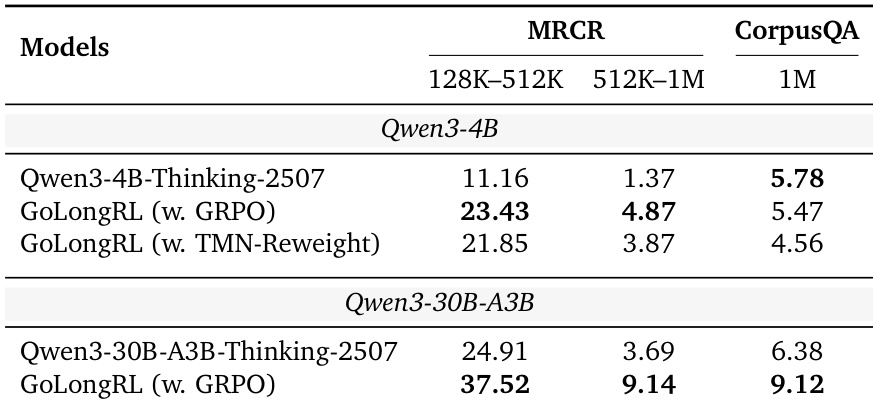
The authors evaluate the performance of their GoLongRL framework on long-context tasks using two model scales, 4B and 30B, comparing it against baseline models. Results show that GoLongRL improves performance on both MRCR and CorpusQA tasks across different context lengths, with the 30B model achieving higher scores than the 4B model. The improvements are consistent across both model scales, indicating scalability of the approach. GoLongRL improves performance on MRCR and CorpusQA tasks across different context lengths compared to baseline models. The 30B model outperforms the 4B model on both MRCR and CorpusQA tasks, indicating scalability of the approach. GoLongRL achieves higher scores on both MRCR and CorpusQA tasks compared to the baseline models at both model scales.
The authors evaluate the impact of their GoLongRL framework on general reasoning, agentic memory, and dialogue memory tasks across two model scales. Results show that the proposed TMN-Reweight algorithm improves performance on most benchmarks, particularly in dialogue memory, while maintaining or enhancing general reasoning capabilities. The improvements are consistent across both model sizes, with the 30B model generally achieving higher scores than the 4B model. TMN-Reweight improves performance on general reasoning and memory tasks across both model scales. The largest improvement is observed in dialogue memory, with a significant gain of 13.6 points for both models. The 30B model consistently outperforms the 4B model across all evaluated benchmarks.
The authors evaluate the GoLongRL framework and its TMN-Reweight algorithm against established baselines using Qwen3 models at 4B and 30B scales across long-context reasoning, memory, and dialogue benchmarks. These experiments validate the method's capacity to enhance performance on aggregation-intensive and long-range dependency tasks while successfully preserving general reasoning capabilities. The qualitative results demonstrate that the approach consistently outperforms baseline models, exhibits strong extrapolation to extended contexts, and scales effectively across different model sizes. Overall, the study confirms that GoLongRL delivers robust improvements in memory retention and complex reasoning without compromising foundational language understanding.