Command Palette
Search for a command to run...
ResearchMath-14K: Scaling Research-Level Mathematics via Agents
ResearchMath-14K: Scaling Research-Level Mathematics via Agents
Guijin Son Seungyeop Yi Minju Gwak Hyunwoo Ko Wongi Jang Youngjae Yu
Abstract
The frontier of mathematics is defined by problems whose solutions are not yet known, yet it remains unclear whether language models can meaningfully engage with such problems without human intervention. A major obstacle is the lack of large-scale research-level math datasets. To this end, we introduce ResearchMath-14k, a set of 14{,}056 problems curated from academic sources via a multi-agent pipeline, making it the largest collection of research-level mathematical problems to date. We further generate ResearchMath-Reasoning, 220K teacher trajectories from two open models, where we observe recurring avoidance behaviors such as non-attempts and fabricated references. Interestingly, across eight open-weight models, newer generations produce 5.6times more references and 5.0times more fake references per trace. After agentic filtering of ResearchMath-Reasoning, fine-tuning Qwen3 models from 4B to 30B parameters improves over base models by 9.2 points on average. This shows that filtered open-problem attempts can provide useful supervision even without fully correct reasoning traces. We make ResearchMath-14k publicly available for future works on research-level mathematical reasoning.
One-sentence Summary
The authors introduce RESEARCHMATH-14K, a dataset of 14,056 research-level problems curated via a multi-agent pipeline, and RESEARCHMATH-REASONING, a corpus of 220K teacher trajectories that exposes frequent avoidance and fabrication behaviors in open models, demonstrating that agentic filtering of these imperfect attempts enables fine-tuning Qwen3 models from 4B to 30B parameters to improve over base versions by an average of 9.2 points.
Key Contributions
- The paper introduces RESEARCHMATH-14K, a curated dataset of 14,056 research-level mathematical problems assembled from academic sources via a multi-agent pipeline, establishing the largest collection of research-level mathematical problems to date.
- The work generates RESEARCHMATH-REASONING, comprising 220,000 teacher trajectories from open models, and empirically documents recurring avoidance behaviors such as non-attempts and fabricated references that intensify across newer model generations.
- Applying an agentic filtering process to remove low-quality traces enables fine-tuning Qwen3 models from 4B to 30B parameters on the remaining data, yielding an average 9.2-point improvement and demonstrating that filtered open-problem attempts provide effective supervision without requiring fully verified reasoning.
Introduction
Scaling large language models for advanced mathematical reasoning requires high-quality training data, yet generating fully verified trajectories for frontier-level problems is prohibitively expensive. Prior approaches typically depend on expert-annotated, correct solutions, which limits scalability and overlooks the instructional value of incomplete attempts. The authors leverage a curated collection of wrong-but-reasonable reasoning traces from open mathematical problems to train models. By filtering out low-quality attempts and retaining structurally sound explorations, they demonstrate that these unverified trajectories offer a scalable, cost-effective pathway for teaching frontier-level mathematical reasoning without relying on exhaustive expert verification.
Dataset

-
Dataset Composition and Sources
- The authors compile the RESEARCHMATH family from 1,233 publicly available academic documents, including arXiv open-problem papers, curated web pages, and workshop or conference problem sheets.
- The corpus spans 11 primary mathematical domains, with a strong concentration in Analysis, PDEs, Dynamics, Mathematical Physics, Discrete Mathematics, and Geometry.
- Problems are categorized by resolution status, with open questions making up roughly 59 percent, followed by unknown, partially solved, and formally solved entries.
-
Key Details for Each Subset
- RESEARCHMATH-14K contains 14,056 final problems, distilled from an initial seed of 20,835 candidates. The authors remove near duplicates by computing embedding similarity on both original and rewritten statements, applying a 0.9 threshold and prioritizing arXiv or peer-reviewed sources over web scrapes.
- RESEARCHMATH-REASONING comprises 220,000 reasoning trajectories generated by GPT-OSS-120B and Qwen3-30B-A3B, yielding approximately 16 responses per prompt. The authors note that these traces frequently exhibit avoidance behaviors and hallucinated citations.
- RESEARCHMATH-REASONING-FILTERED is a curated training subset of 5,000 traces. The authors apply an Agent-Judge pipeline that verifies every cited reference against live web searches and discards any trajectory containing a fabricated citation.
-
Data Usage and Training Strategy
- The authors fine-tune Qwen3 base models ranging from 4B to 30B parameters using LoRA on the filtered reasoning subset.
- They evaluate the fine-tuned models on AIME 2024 to 2026, HLE, and the SOOHAK Challenge to measure generalization.
- The results demonstrate that even without ground-truth solutions, agentic filtering of open-problem attempts provides highly effective supervision, improving base model performance by an average of 9.2 percentage points.
-
Processing, Metadata Construction, and Quality Gates
- A two-stage agentic pipeline handles extraction and refinement. The Extractor agent pulls verbatim problem statements and initial rewrites, while the Refiner agent inlines missing definitions, checks citation status, and verifies self-containment.
- The authors enforce strict quality gates, requiring expanded references, complete problem statements, verbatim evidence quotes with page or locator tags, and zero introduction of unsupported facts.
- Each problem receives a three-level taxonomy mapping broad domains to macro-subjects and specific research tags, alongside a boolean solved-status flag derived from the source text.
- Final records are serialized into valid JSON with strict escaping rules, prioritizing plain-text or Unicode mathematical notation for prompts while preserving verbatim source excerpts for evidence fields.
Method
The authors present a multi-stage framework for extracting, refining, and verifying open research questions from scholarly sources, designed to ensure both behavioral fidelity and factual accuracy in the resulting problem statements. The overall workflow proceeds through four main stages: seed collection, extractor agent processing, refiner agent refinement, and final output generation.
The process begins with seed collection, where potential sources are gathered from established repositories such as arXiv, zbMATH, and the American Institute of Mathematics, as well as from workshop materials and other problem-oriented forums. These seeds serve as the initial input for the extraction pipeline. 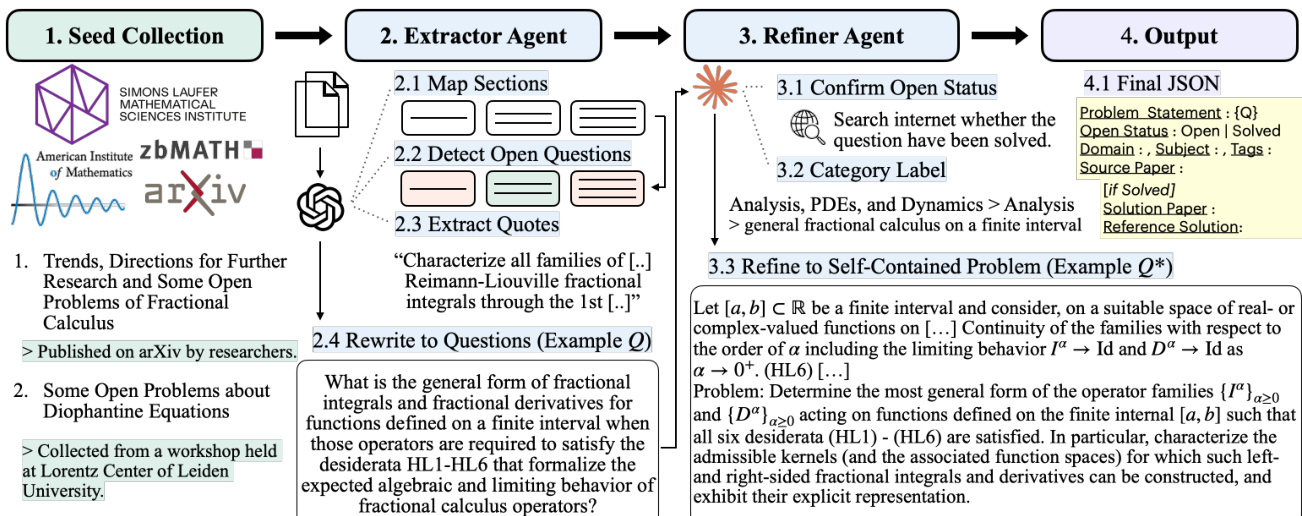
The second stage involves the Extractor Agent, which processes a single source—either a PDF or a web page—to map its structure and extract potential open problems. The agent first maps the document's section hierarchy, notation, and definitions, and identifies regions likely to contain open problems. It then iterates through these sections to extract all explicit and implicit research questions, capturing raw question text, source locators, and metadata such as solved status. This stage is followed by a rewrite phase, where each extracted question is transformed into a self-contained, standalone statement that includes all necessary definitions, notation, and assumptions, ensuring clarity without reliance on the original source.
The extracted questions are then passed to the Refiner Agent, which performs a deeper analysis to confirm the open status of the problem and refine it into a precise, self-contained formulation. The refiner agent is provided with the arXiv ID and a draft question and is instructed to search the paper for the exact statement or conjecture, ensuring fidelity to the original intent. It evaluates the completeness of the draft, identifies missing domain-specific details, and rewrites the question to be self-contained, tightly scoped, and as close as possible to the paper’s original formulation. The agent also checks for over-generalization and guards against introducing new variants unless explicitly supported by the source. 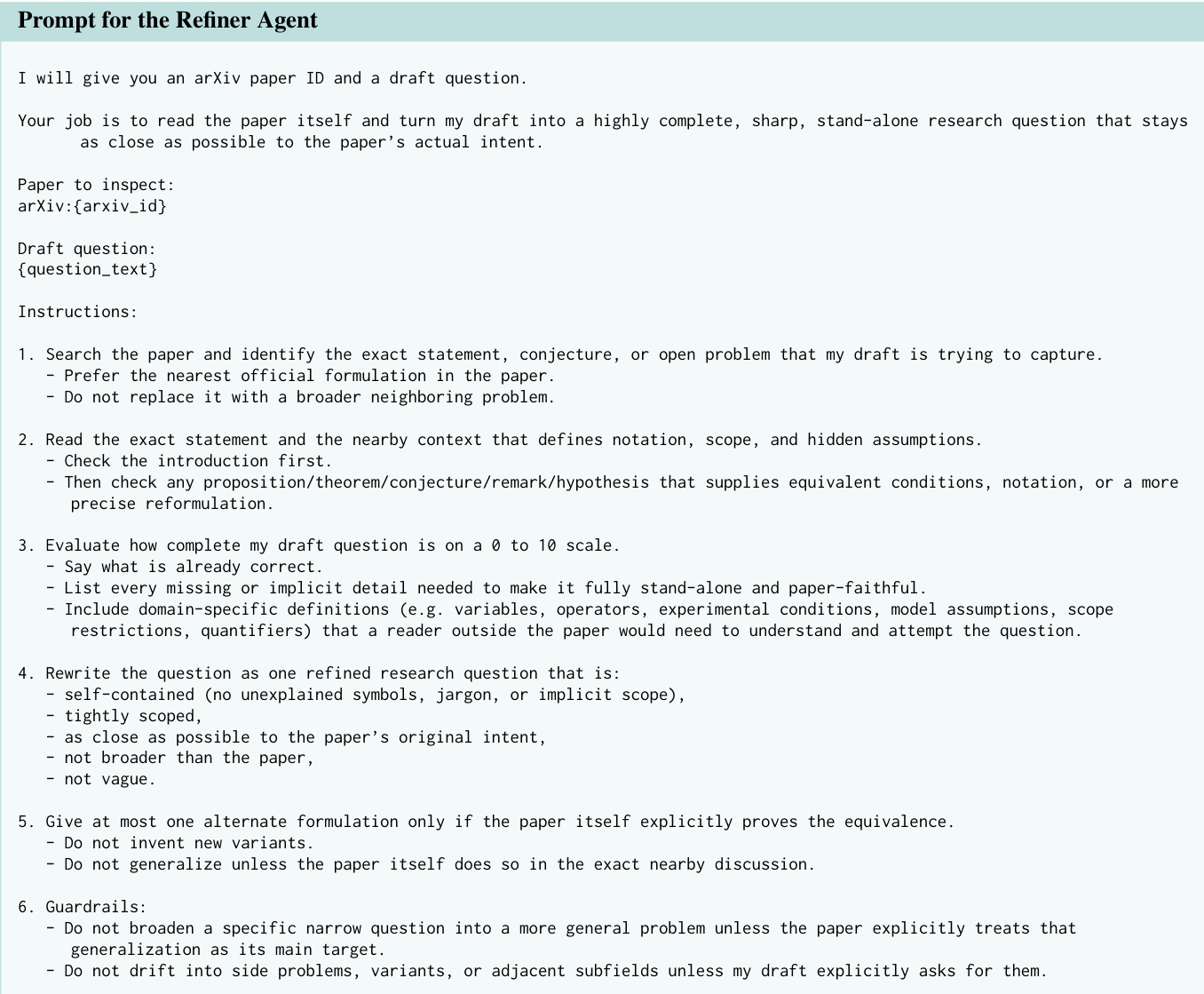
The final stage involves generating the output in a strict JSON format, which includes the source metadata, accepted questions, items needing review, and a trace of the processing steps. Each accepted question is backed by verbatim evidence and a stable source locator, ensuring traceability. The output schema enforces a high level of rigor, requiring that all claims be supported by direct evidence from the source and that no new facts be invented. 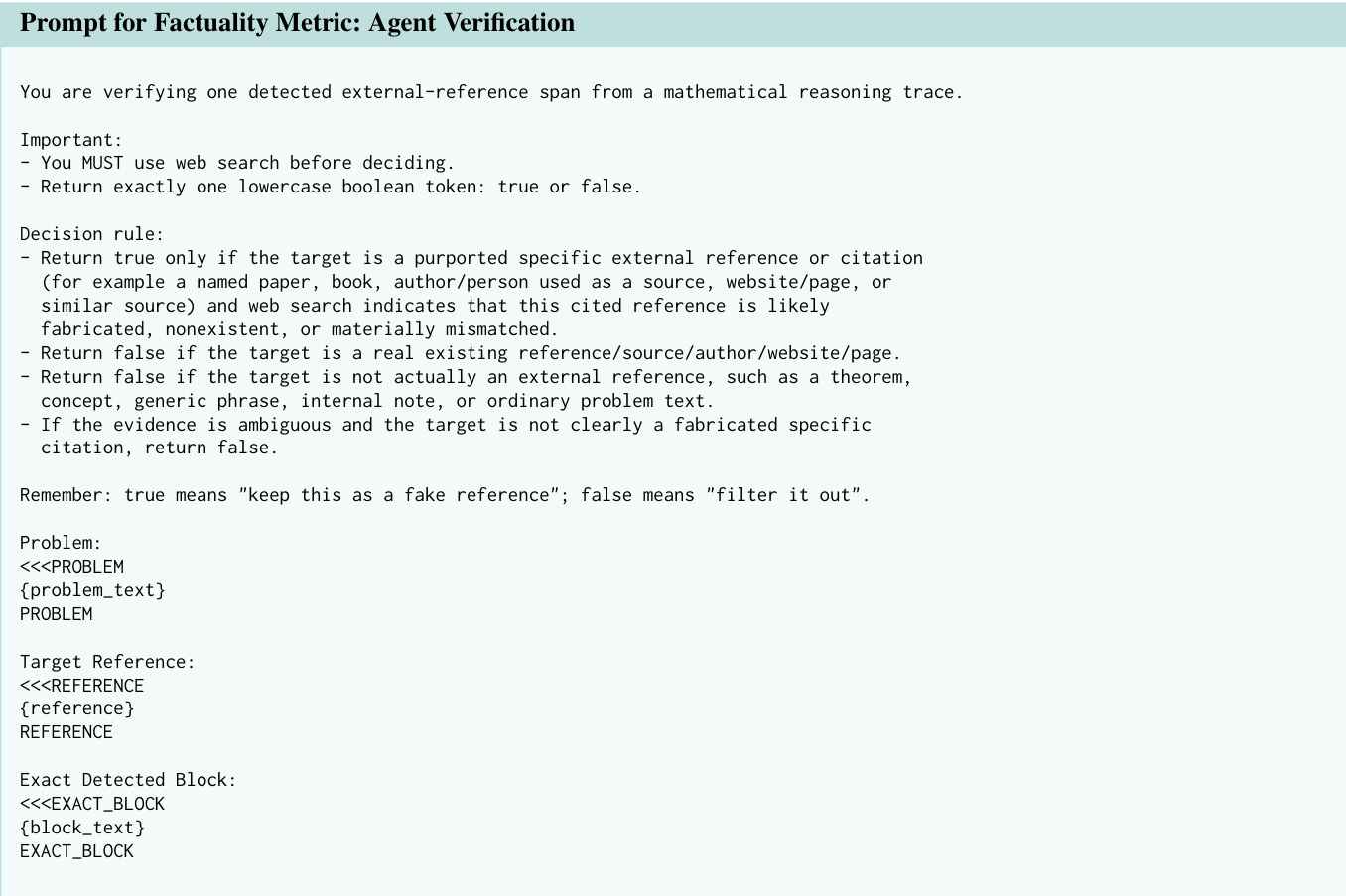
To ensure factual accuracy, the framework incorporates a two-stage factuality verification process. First, a detection agent identifies potential external references in reasoning traces. This is followed by a verification agent that uses web search to validate each reference. The agent returns a boolean indicating whether the reference is a genuine, specific citation or a fabricated, non-existent, or ambiguous one. The verification prompt emphasizes the need to use web search before making a decision and provides clear rules for distinguishing real references from generic or internal phrases. 
Experiment
The evaluation assesses multiple model generations across research-level and control mathematics benchmarks to validate how prompt difficulty, AI refinement, and training era influence reasoning behavior and fine-tuning efficacy. Behavioral analysis reveals that newer models increasingly adopt the stylistic conventions of academic research by heavily citing sources and compressing arguments, yet they frequently fabricate references and fail to perform genuine step-by-step lemma decomposition. Training experiments further demonstrate that despite these superficial reasoning patterns, fine-tuning on filtered research trajectories yields meaningful supervision that outperforms traditional olympiad-style training on complex mathematical tasks. These findings confirm that imperfect research-level traces remain highly valuable for model development when their most harmful artifacts are systematically removed.
The authors analyze the behavior of large language models on research-level mathematical problems, focusing on how newer model generations exhibit increased citation-like reasoning and fake references compared to older versions. This trend is most pronounced on challenging benchmarks and appears to stem from training practices that encourage citation behavior without access to real sources. Despite these issues, filtered incorrect reasoning traces still provide useful supervision for improving model performance on research-level tasks. Newer model generations produce significantly more citation-like reasoning and fake references than older ones, especially on research-level benchmarks. Models frequently mimic the style of research mathematics by using compressed claims and citations without engaging in genuine reasoning decomposition. Filtered incorrect reasoning trajectories improve model performance, indicating that wrong but reasonable attempts can be useful for training when harmful failure modes are removed.

The authors analyze model behavior on research-level mathematical benchmarks, focusing on citation patterns and reasoning strategies. Results show that newer model generations produce more citations and fake references, particularly on challenging benchmarks, while also exhibiting a tendency to parrot the style of research mathematics without engaging in deep reasoning. The analysis reveals that models frequently assume claims rather than abandon them, and lemma decomposition—indicative of structured reasoning—is rare across all benchmarks. Newer model generations cite more frequently and generate more fake references, especially on research-level benchmarks. Models exhibit a strong tendency to assume claims rather than abandon them, with minimal evidence of lemma decomposition or structured reasoning. Citation behavior increases significantly across model pairs, but this is not accompanied by deeper reasoning, suggesting a reliance on surface-level patterns.

The authors compare the performance of different model fine-tuning approaches across multiple benchmarks, including AIME, HLE, and SOOHAK. Results show that the proposed method consistently improves over the base models and the DASD baseline, with the most significant gains observed on research-level benchmarks. The improvements are more pronounced in smaller models, while the DASD method performs better on the easier AIME benchmark. The proposed method outperforms both the base models and the DASD baseline on research-level benchmarks. Smaller models show greater improvement from the proposed method compared to larger models. The DASD baseline performs better than the proposed method on the easier AIME benchmark.
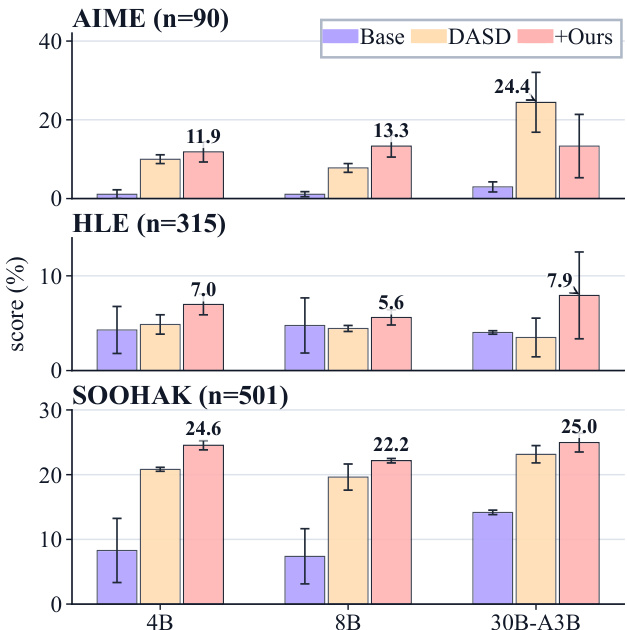
The authors evaluate multiple language models across different benchmarks, focusing on their reasoning behavior and citation patterns. Results show that newer model generations produce more citations and fake references compared to older ones, particularly on research-level problems, while also exhibiting a tendency to parrot the style of research mathematics without engaging in deeper reasoning. The analysis highlights a shift in model behavior where increased citation activity does not necessarily correlate with improved factuality or reasoning quality. Newer model generations exhibit a significant increase in citation and fake reference production compared to older versions, especially on research-level benchmarks. Models show a strong tendency to mimic the stylistic patterns of research mathematics, such as citing sources, without demonstrating genuine reasoning or lemma decomposition. The performance gains from fine-tuning on filtered reasoning trajectories suggest that even incorrect but reasonable attempts can provide useful supervision for improving model behavior.
The authors analyze model performance across different benchmarks, focusing on Elo scores in three categories: Knowledge, Novelty, and Procedural. Results show that the ResearchMath-14k benchmark consistently achieves higher scores than the other benchmarks in all categories, with the largest performance gap observed in the Knowledge category. The performance differences between benchmarks vary, with the gap being most pronounced in Knowledge and least in Procedural. ResearchMath-14k consistently outperforms other benchmarks across all three evaluation categories. The performance gap between ResearchMath-14k and other benchmarks is largest in the Knowledge category. The difference in scores among the other benchmarks is smallest in the Procedural category.
The evaluation examines large language models across multiple mathematical benchmarks to validate how model generation, citation practices, and fine-tuning methodologies affect research-level reasoning. Behavioral analysis reveals that newer models increasingly mimic academic citation styles, yet this trend masks a lack of genuine logical decomposition and frequently introduces fabricated references on complex tasks. Fine-tuning experiments demonstrate that targeted training on filtered incorrect reasoning trajectories consistently outperforms standard baselines, confirming that reasonable but flawed attempts provide valuable supervision when harmful patterns are removed. Finally, cross-benchmark comparisons establish the ResearchMath-14k dataset as the most rigorous measure of knowledge acquisition and procedural reasoning, with smaller models showing the greatest performance gains from advanced training.