Command Palette
Search for a command to run...
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
Yipeng Gao Lei Shu Genzhi Ye Xi Xiong Ameesh Makadia Meiqi Guo Laurent Itti Jindong Chen
Abstract
Procedural 3D modeling through code is emerging as a versatile paradigm, offering deterministic, engine-ready, and precisely editable assets that neural 3D generators inherently lack. Authoring such procedural content, however, demands deep expertise in 3D software APIs, parametric design, and code-level geometric reasoning. In this paper, we propose 3DCodeBench, a systematic benchmark for evaluating vision-language model (VLM) agents for procedural 3D generation in 3D modeling software. Specifically, 3DCodeBench evaluates how effectively 12 advanced VLMs can serve as procedural 3D modelers by translating text and image references into procedural code for 3D modeling software. Recognizing that automated metrics may not fully capture the perceptual quality of 3D shapes, we build 3DCodeArena, a ranking platform based on pairwise human preferences over generated 3D outputs. From extensive evaluations and results, we observe that: (1) Failures mostly arise from API mismatches, while successful renders still suffer from disconnected or floating 3D geometric components. (2) Test-time scaling, such as higher thinking budgets and multi-turn refinement, improves performance overall. Our findings highlight a critical need for high-quality procedural coding data to advance commercial VLMs. Furthermore, effective procedural 3D modeling requires a robust execution environment that provides high-fidelity feedback for iterative refinement. We release 3DCodeBench, including the curated large-scale dataset of multimodal (text/image) prompts, procedural code, 3D object triplets, evaluation protocol, and the public 3DCodeArena platform as a foundational toolkit for exploring VLM-based procedural 3D modelers.
One-sentence Summary
The paper proposes 3DCodeBench, a benchmark evaluating 12 advanced vision-language models on translating text and image prompts into procedural 3D code, paired with 3DCodeArena for pairwise human preference ranking, revealing that failures mainly arise from API mismatches and disconnected or floating geometry while test-time scaling via higher thinking budgets and multi-turn refinement improves performance, and releasing the curated dataset and platform to advance VLM-based procedural generation.
Key Contributions
- The paper introduces 3DCodeBench, a benchmark for evaluating vision-language model agents on procedural 3D generation, built through an agentic curation pipeline that yields a dataset of 212 object categories with multimodal prompts, executable Blender scripts, and human-verified 3D triplets.
- This work constructs 3DCodeArena, a public platform that collects pairwise human preferences over generated 3D outputs, and demonstrates that SigLIP-2 view similarity can serve as a robust automated proxy for human judgment.
- Extensive evaluation of 12 frontier VLMs shows that test-time compute scaling and multi-turn agentic refinement improve procedural code quality, while identifying API mismatches and disconnected geometry as the predominant failure modes.
Introduction
Procedural 3D modeling through code is essential for creating deterministic, editable, and engine-ready assets in gaming, industrial design, and robotics simulation, but authoring such code demands deep expertise in 3D APIs and geometric reasoning. Prior benchmarks either lack the aligned procedural code needed for evaluating generative models, focus on simplistic shapes or scene editing rather than from-scratch generation, or ignore the iterative refinement loops that real 3D design workflows require. The authors introduce 3DCodeBench, a standardized benchmark that pairs 26K multimodal prompts with executable Blender code and 3D geometries across 212 diverse categories, and they complement it with 3DCodeArena, a platform for collecting pairwise human preferences. Their extensive evaluation of 12 frontier vision-language models demonstrates that while models can produce executable scripts, physical plausibility and geometric coherence remain major bottlenecks, and that multi-turn agentic refinement using runtime feedback significantly improves output quality.
Dataset
The authors construct two complementary datasets from Infinigen’s procedural factories, using an agentic curation pipeline with human verification. The benchmark, 3DCodeBench, is a compact evaluation set, while a larger curated corpus provides fine-tuning data for code-generation models.
-
3DCodeBench (evaluation benchmark)
- 212 distinct asset categories spanning organic entities, manufactured objects, and architectural fragments.
- Each instance is a high-fidelity (prompt, standalone Python code, 3D mesh) triplet.
- Scripts are complex (median 387 lines, mean 531 lines, some over 1,000 lines) and require reasoning about 3D structure and new Blender API functions.
- Used exclusively for zero-shot or few-shot evaluation of 3D code generation.
-
Curated 3D Code Data (fine-tuning corpus)
- 12,963 instances derived from 212 random-seed-parameterized factories (filtered from 243 full object factories).
- Each instance provides:
- A text prompt paired with three caption styles (object description, procedural-modeling instruction, factory-level specification).
- 4 canonical multi-view reference images (45°, 135°, 225°, 315°).
- Two Blender 5.0 Python scripts: a textured factory script and a geometry-only variant, yielding ~26K code samples in total.
- A baked GLB ground-truth mesh.
- All triplets passed the full agentic curation pipeline and human-in-the-loop verification.
- Used for supervised fine-tuning of 3D code generation models.
-
Agentic curation pipeline
- Transforms deeply nested procedural factories into clean, standalone scripts.
- Skills Library provides objective feedback: a Code Simplifier, a sandboxed Blender 5.0 simulator, a VLM-based Visual Critic that compares multi-view renders to reference images, and a Mesh Analyzer for structural checks.
- Experience Library accumulates reusable knowledge: class deduplication to maintain diversity, parts-assembly templates, Blender 5.0 API migration rules, and code organization standards.
- Human-in-the-loop verification acts as final quality control; annotators manually review execution reliability, caption accuracy (via Gemini 3.1 Pro), and visual alignment, and intervene with targeted feedback when agents fail.
-
Multi-view image processing
- All reference renders follow a strict studio product-photography style: single object centered, occupying 70–80% of the frame, plain light-gray/off-white background, soft diffuse lighting from above-front, three-quarter front view (~30–45° rotation, ~15° above eye level), no scene elements, no text or labels, and photorealistic, true-to-life colors.
Method
The authors formulate procedural3D generation as a policy learning problem where a model synthesizes executable code that a 3D software runtime compiles into a target object. Formally, given a condition c comprising text and optional reference images, a policy π produces a script:
fπ=π(c)
A deterministic operator E then executes this script to yield a mesh:
Mπ=E(fπ)
The authors instantiate this formulation on Blender 5.0, making fπ a Blender Python script, though the approach is software-agnostic.
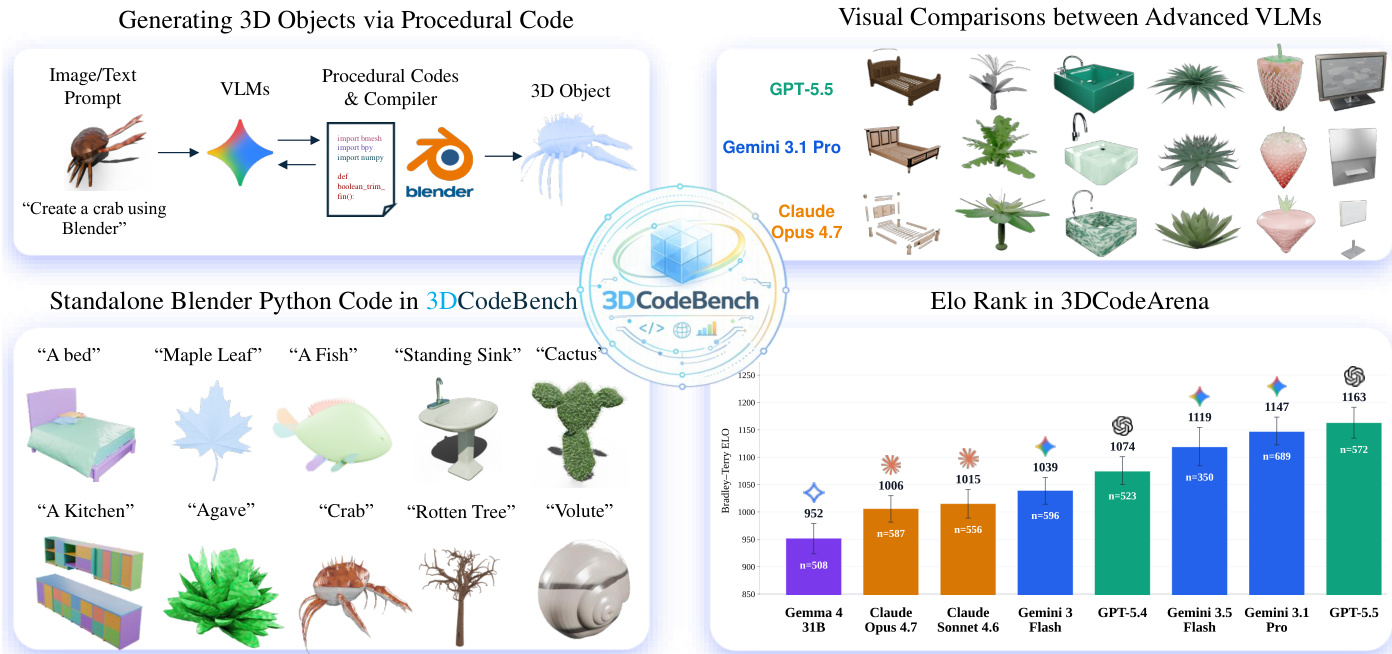
The high-level process of generating 3D objects via procedural code is illustrated in the figure below, where image or text prompts are processed by VLMs to produce procedural codes that a compiler executes into 3D objects.
The detailed architecture, as shown in the figure below, involves Coding Agents that take inputs such as text instructions, reference images, and procedural simulators. These agents interact with VLM and Human Checkers to produce high-quality data pairs consisting of prompts and corresponding procedural code.
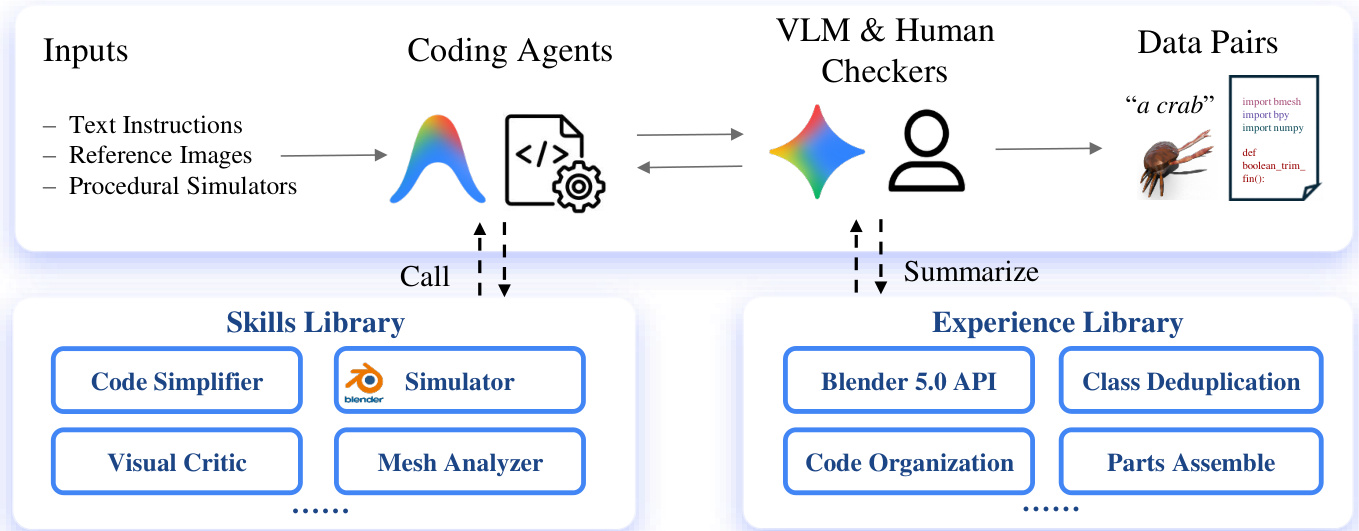
The framework is supported by two key libraries. The Skills Library provides tools such as a Code Simplifier, a Simulator, a Visual Critic, and a Mesh Analyzer. The Experience Library accumulates knowledge regarding the Blender 5.0 API, class deduplication, code organization, and parts assembly.
To ensure robust code generation, the authors employ strict system prompts for both text-to-3D and image-to-3D tasks. These prompts enforce three critical constraints: a strict output format requiring raw Blender 5.0 Python without Markdown formatting, a target environment limited to a closed allow-list of libraries, and behavioral code requirements such as generating a single object at the origin without rendering or file I/O.
For image-to-3D tasks, the model receives reference images and must infer unseen sides, cross-reference multiple views to resolve depth and proportions, and reproduce geometric details as real geometry rather than flat surfaces.
To probe agentic capabilities, the authors permit T≥1 refinement iterations. At step t, the policy updates fπ(t) based on execution logs or visual feedback. In the multi-turn error-feedback loop, if a script fails to execute, the system provides the previous code and truncated Blender stderr to the model in a stateless manner, asking for a corrected script.
For visual self-critique, the model evaluates baseline-OK instances. It compares the generated render against the reference and outputs a decision in the format NEEDS_FIX:NO or NEEDS_FIX:YES followed by an assessment and corrected code. The authors introduce a conservatism bias, preferring NEEDS_FIX:NO when the render is good enough to avoid breaking working code. Additionally, for a text-to-image-to-3D pipeline, a meta-prompt first generates a photographic reference image from a text description, which is then fed into the image-to-3D code generator.
Experiment
The evaluation combines per-mesh quantitative metrics with a human-vote arena to rank vision-language models on procedural 3D generation. Increased reasoning budgets consistently help lightweight models but quickly saturate for frontier models, while multi-turn error-feedback lifts executability across the board by addressing superficial API mismatches. Agent harnesses further improve reliability but leave conditional shape fidelity unchanged, and visual self-critique proves task-asymmetric, beneficial only for text-to-3D. LLM-as-a-judge agrees reasonably with humans when shown rendered images but is less reliable from code alone, and a sampling temperature of 0.7 is the recommended choice.
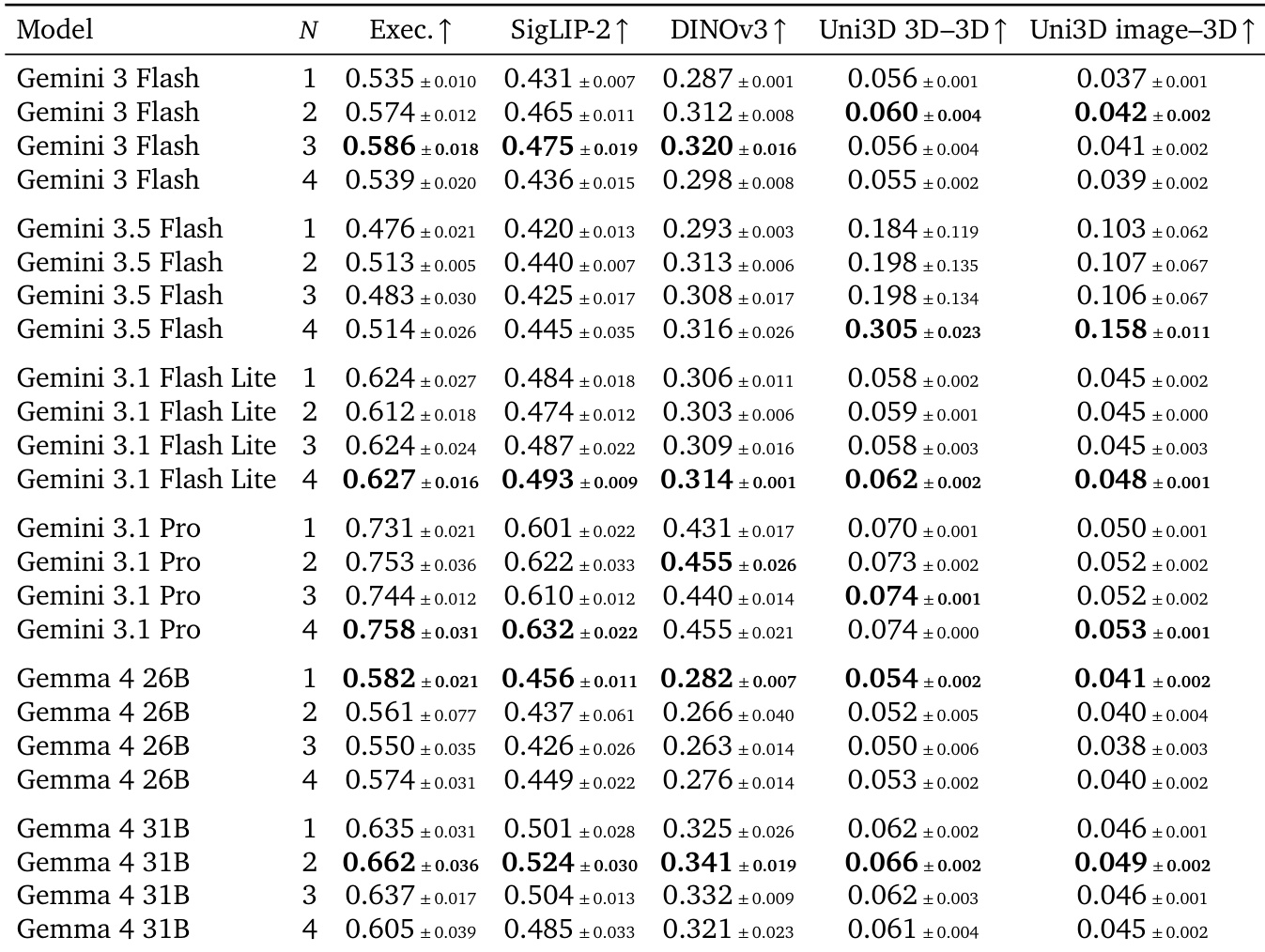
The authors evaluate the impact of varying the number of input views on the image-to-3D track across multiple model backbones. Results show that conditioned quality metrics remain largely stable as the input-view budget increases, with executability and perceptual similarity scores showing minimal variation. While some models exhibit modest gains in 3D structural alignment with additional views, there is no consistent improvement in view-based similarity over using a single input view. Increasing the number of input views yields negligible changes in executability and perceptual fidelity across all tested backbones. Structural alignment metrics show slight improvements for certain models with more views, but the gains are marginal and not universally consistent. Extra input views provide no consistent similarity gains over a single view, so the authors use multiple views primarily to test spatial understanding capabilities.
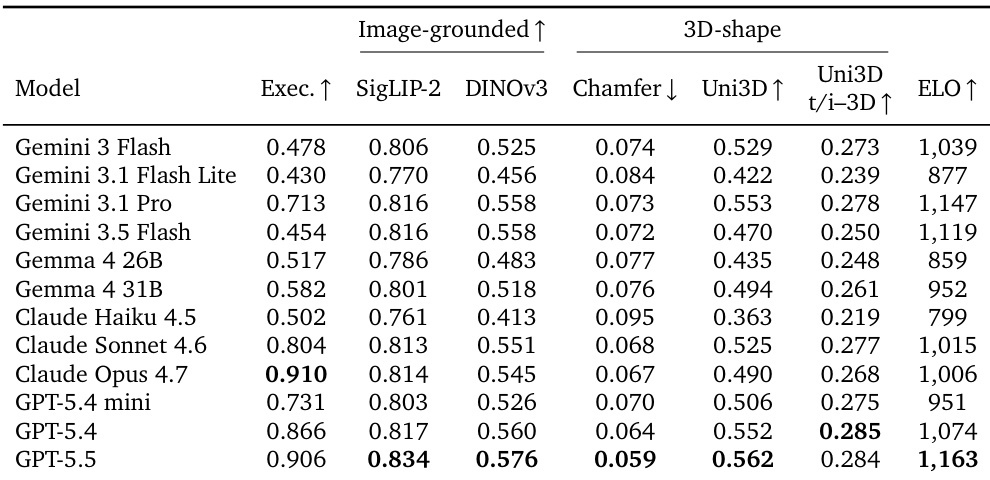
The authors evaluate multiple frontier Vision-Language Models on a 3D code generation benchmark, assessing executability, perceptual fidelity, 3D-shape accuracy, and human preference. GPT-5.5 emerges as the top performer overall, leading in human preference rankings and most quality metrics, while Claude Opus 4.7 achieves the highest script executability. The results demonstrate a clear capability gap, where heavier frontier models significantly outperform lighter variants in both generating valid code and producing accurate 3D geometry. GPT-5.5 achieves the highest human preference ranking and leads in most perceptual and geometric quality metrics. Claude Opus 4.7 demonstrates the strongest code executability among all tested models. Lighter models exhibit substantially lower executability and shape fidelity compared to their larger counterparts.
The authors evaluate a text-to-image-to-3D pipeline that inserts an intermediate image generation step before 3D code generation. Results show that relying solely on the generated image degrades performance compared to direct text-to-3D generation, particularly for lighter models. However, combining the generated image with the original text prompt recovers this loss and improves perceptual similarity for higher-capacity backbones. The image-only pipeline configuration consistently reduces SigLIP-2 similarity scores across all tested backbones compared to the direct text-to-3D baseline. The combined mode, which pairs the generated image with the original text prompt, improves SigLIP-2 scores over the baseline for high-capacity models such as Gemini 3.1 Pro and Gemma 4. Lighter models suffer significant performance drops in the image-only mode and fail to recover in the combined mode due to limited reasoning budgets.
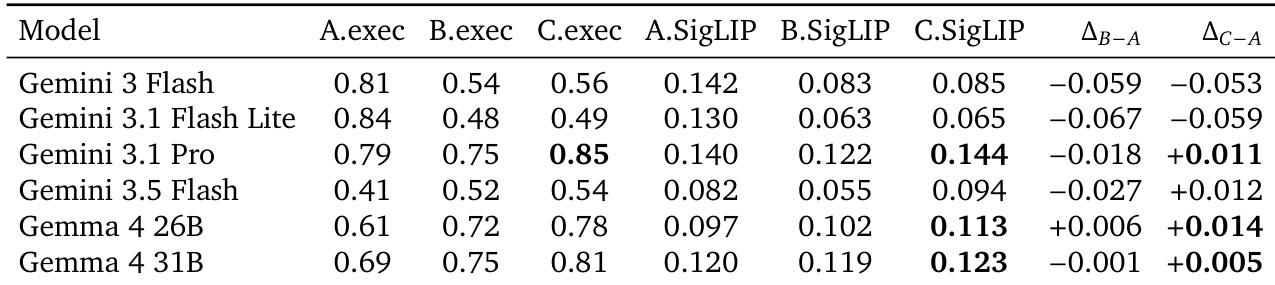
The authors evaluate whether frontier LLMs and VLMs can replicate human judgments in a 3D modeling arena using either rendered images or raw code. Results show that image-based judging achieves substantial agreement with human voters, significantly outperforming code-based judging which yields only fair-to-moderate correlation. Among the models tested, Gemini 3.1 Pro performs best as an image judge, while Gemini 3.1 Pro and Gemini 3 Flash tie for the top spot in code judging. Image-based judging achieves substantially higher accuracy and correlation with human preferences compared to code-based judging. Gemini 3.1 Pro leads image judging performance but exhibits lower coverage due to its frequent use of tie and both bad verdicts. Image judges perform consistently better on image-track prompts than text-track prompts, likely due to the additional visual anchor provided by reference views.
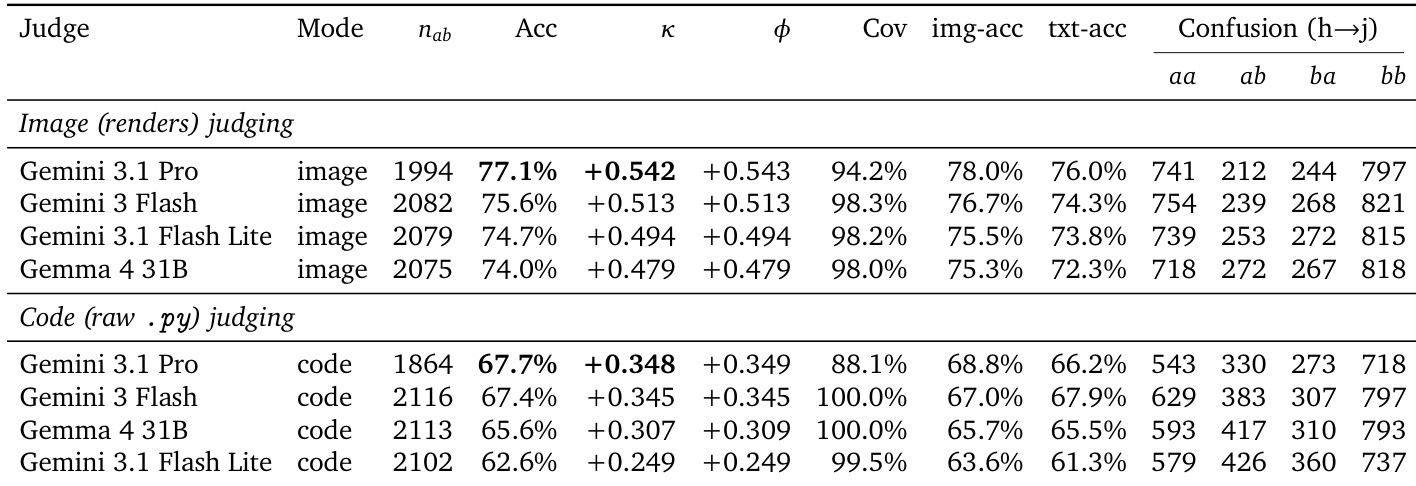
The the the table presents a pairwise win-rate matrix from a public human-vote arena, comparing 3D models generated by different frontier vision-language models. The models are sorted by their overall Elo rating, revealing a clear hierarchy in generative capability. Top-ranked models consistently defeat lower-ranked models across the majority of direct matchups, while models at the bottom of the leaderboard lose most of their pairwise comparisons. The highest-ranked model achieves dominant win rates, defeating nearly all other models in head-to-head comparisons and demonstrating superior 3D generation quality. The matrix exhibits a strong transitive ordering, where models higher on the leaderboard consistently beat those below them, creating a distinct pattern of wins and losses across the grid. Smaller or lighter models struggle against frontier-scale backbones, frequently losing pairwise matchups and indicating a significant capability gap in procedural 3D code generation.
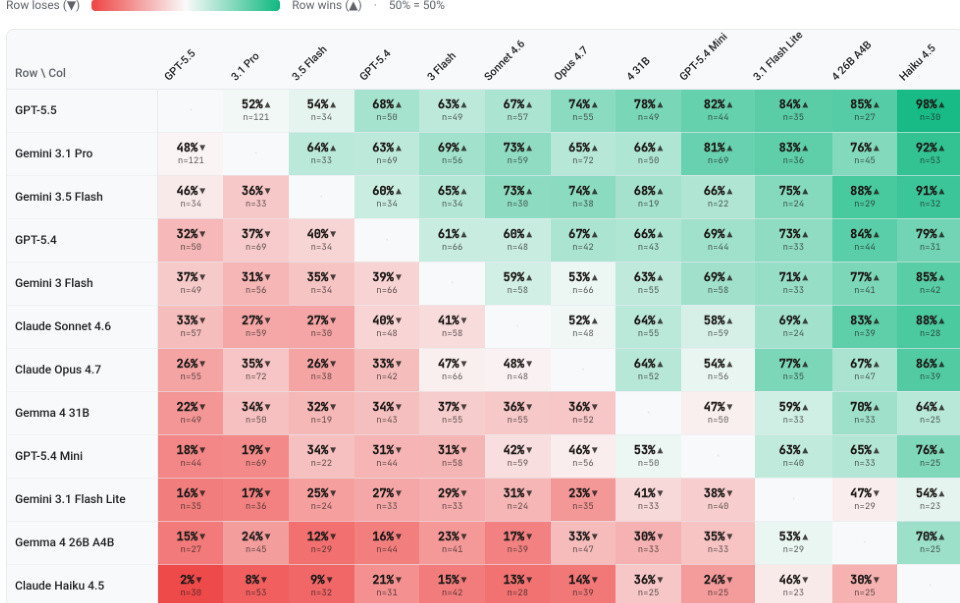
Across several evaluations, the authors probe frontier vision-language models on procedural 3D code generation, studying the effects of input-view count, model scale, and intermediate image synthesis. Increasing the number of input views yields negligible and inconsistent gains in executability or perceptual fidelity, serving mainly to test spatial understanding, while a clear capability gap emerges where large models like GPT-5.5 substantially outperform lighter counterparts in both code validity and geometric accuracy. Inserting a generated image before 3D code generation degrades performance when used alone, especially for smaller models, but pairing the image with the original text prompt recovers and even improves quality for high-capacity backbones. Human preference arenas and automated judging experiments further show that image-based evaluation aligns well with human judgments, whereas code-based assessment lags behind, and that top-ranked models dominate pairwise comparisons in a strongly transitive hierarchy.