Command Palette
Search for a command to run...
TRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
TRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
Hyeongwon Jang Gyouk Chu Changhun Kim Joonhyung Park Hangyul Yoon Eunho Yang
Abstract
Clinical early warning systems built on electronic health records, in which clinical observations are recorded as irregularly sampled medical time series (ISMTS), must deliver both calibrated risk scores for patient triage and interpretable rationales that clinicians can verify. Large Language Models (LLMs) have been explored for this task, yet they collapse graded clinical risk into overconfident binary predictions. This risk polarization undermines both calibration and cross-patient comparability. To address this, we propose TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales. This dialectical formulation mitigates risk polarization, enabling a single LLM to yield continuous risk scores grounded in explicit clinical reasoning. Evaluated on three ISMTS benchmarks, TRIAGE achieves an average AUPRC improvement of 3.3% and reduces calibration error by 81% compared to the competitive baselines. An LLM-as-a-judge assessment further shows that our rationales surpass post-hoc explanations from the baseline by 20% in clinical reasoning quality. The source code is available at https://github.com/HyeongWon-Jang/TRIAGE .
One-sentence Summary
The authors propose TRIAGE, a framework that trains large language models to generate dialectical reasoning over competing clinical outcomes, yielding continuous, calibrated risk scores and interpretable rationales for irregularly sampled medical time series that achieve an average AUPRC improvement of 3.3% and reduce calibration error by 81% across three benchmarks while surpassing baseline post-hoc explanations by 20% in clinical reasoning quality.
Key Contributions
- TRIAGE is a framework that trains large language models to generate dialectical reasoning over competing clinical outcomes for irregularly sampled medical time series. By eliciting outcome-specific rationales instead of forcing a single prediction, the method prevents probability collapse and yields continuous, cross-patient comparable risk scores.
- The approach implements a two-stage training pipeline comprising dialectical reasoning supervision and self-refinement to align implicit probability distributions with patient evidence. This formulation enables the model to weigh coexisting clinical signals of deterioration and stabilization during a single forward pass.
- Evaluated on three irregularly sampled time series benchmarks, the framework achieves an average 3.3% improvement in AUPRC and reduces calibration error by 81% relative to competitive baselines. LLM-as-a-judge evaluations further demonstrate that the generated rationales surpass post-hoc explanations by 20% in clinical reasoning quality.
Introduction
Clinical early warning systems leverage irregularly sampled medical time series from electronic health records to predict adverse events, necessitating both well-calibrated risk scores for patient triage and interpretable rationales that clinicians can verify. Existing solutions fail to deliver these capabilities jointly, as specialized deep learning models remain opaque and post-hoc explainability methods provide only non-linguistic attribution scores rather than high-level clinical reasoning. LLM-based approaches face similar trade-offs, often sacrificing natural language explanations for continuous risk scoring or suffering from risk polarization where elicited reasoning pre-commits to a single outcome, collapsing probability distributions into overconfident binary predictions. The authors propose TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by producing outcome-specific rationales. This method mitigates risk polarization and allows a single model to yield continuous, cross-patient comparable risk scores grounded in explicit clinical reasoning via a two-stage pipeline of dialectical reasoning supervision and self-refinement.
Dataset

Experiment
Evaluated across three irregular medical time series benchmarks for sepsis and mortality prediction, the experiments validate TRIAGE’s predictive accuracy, calibration, and robustness against missing clinical variables. Ablation studies demonstrate that dialectical reasoning and batch-level reinforcement learning significantly outperform traditional single-outcome supervision and sample-level rewards, effectively mitigating risk saturation and improving score reliability. Qualitative assessments further confirm that the model generates clinically grounded, temporally aware rationales that avoid the one-sided biases and hallucinations prevalent in standard LLMs and post-hoc interpretability methods. Overall, the findings establish TRIAGE as a robust, data-efficient framework that successfully bridges high-fidelity clinical reasoning with reliable risk prediction.
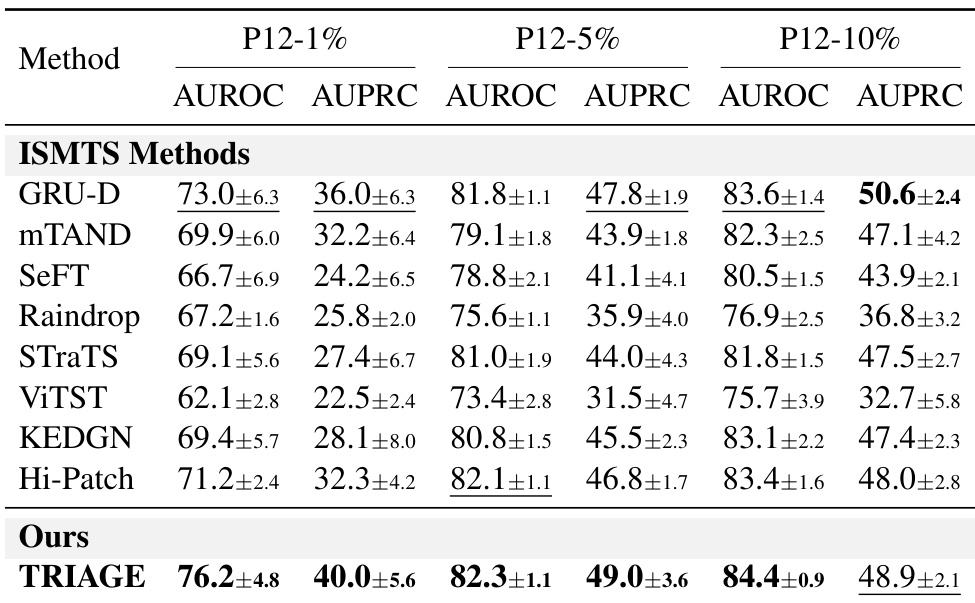
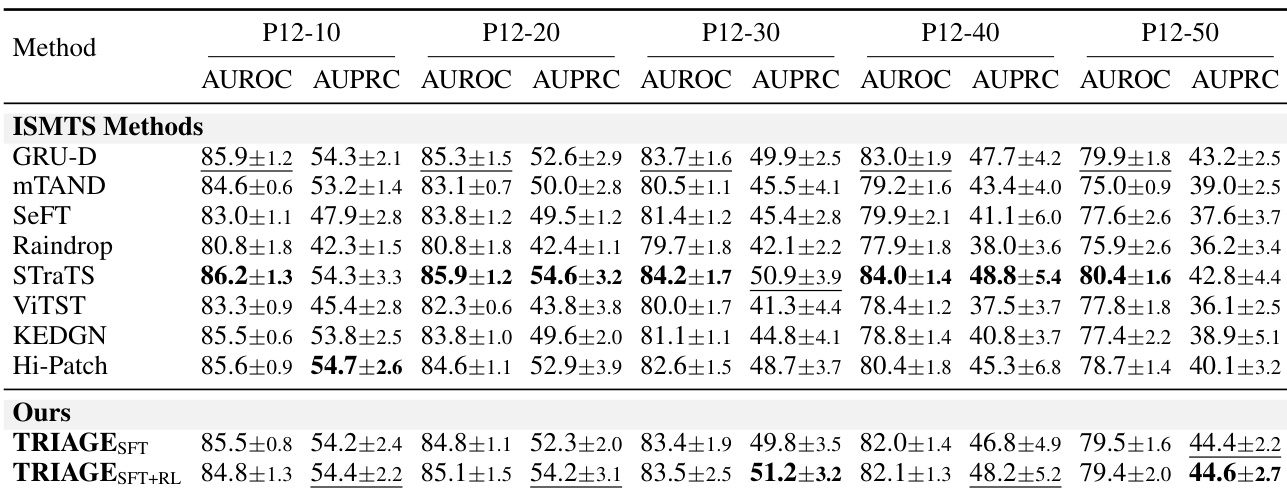
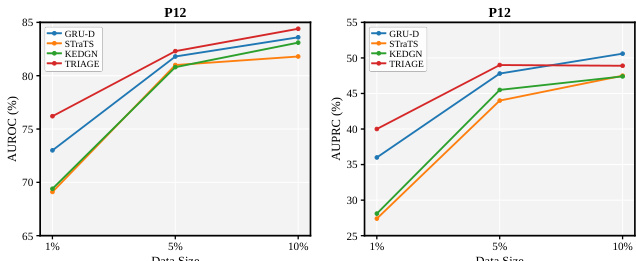
The authors evaluate TRIAGE against established ISMTS baselines on the P12 dataset under varying training data fractions. Results indicate that TRIAGE significantly outperforms existing methods when labeled data is scarce, demonstrating high data efficiency. As data availability increases, TRIAGE remains competitive, achieving top-tier performance across most evaluation criteria. TRIAGE significantly outperforms baselines in low-data regimes, demonstrating high data efficiency. The method consistently achieves the highest AUROC scores across all evaluated data fractions. TRIAGE maintains competitive performance relative to top baselines as training data availability increases.
The authors assess the robustness of their model, TRIAGE, against established baselines by randomly masking input variables during inference. The experiment reveals that TRIAGE preserves its predictive capability more effectively than competing methods as the proportion of missing data increases. The reinforcement learning-tuned variant demonstrates particular strength in maintaining high discrimination metrics under severe data scarcity. TRIAGE demonstrates greater stability than baselines as the percentage of missing variables rises from 10% to 50%. The RL-tuned TRIAGE variant secures the top performance rank for AUPRC at higher missingness levels. While baselines lead at lower removal rates, TRIAGE consistently remains in the top tier of performers across all tested scenarios.
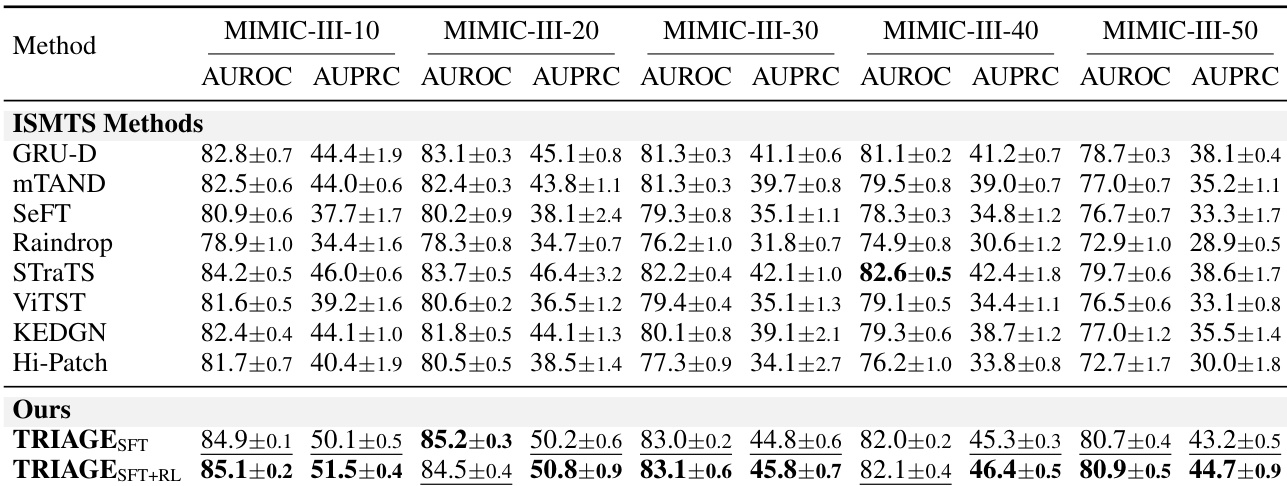
The authors evaluate their proposed TRIAGE model against several ISMTS baselines under varying variable masking ratios on the MIMIC-III dataset. Results demonstrate that both the supervised fine-tuned and reinforcement learning-enhanced versions of TRIAGE consistently achieve superior discrimination performance compared to existing methods across all tested missing data scenarios. The model maintains robust predictive accuracy even as the proportion of masked variables increases, highlighting its resilience to incomplete clinical information. The proposed TRIAGE model, particularly after reinforcement learning, consistently outperforms all ISMTS baselines in both AUROC and AUPRC metrics across all variable masking ratios. TRIAGE demonstrates superior robustness to missing data, maintaining high predictive performance even when up to half of the input variables are removed. The reinforcement learning stage provides a notable performance boost over supervised fine-tuning alone, achieving the best results on nearly all evaluation points.
The authors evaluate model performance across varying training data sizes on the P12 dataset. Results demonstrate that all methods benefit from increased data availability, with performance gains evident as the training set expands. The proposed method consistently achieves the highest discrimination scores across all data fractions, showing the most significant advantage in low-resource settings. The proposed method achieves the highest AUROC and AUPRC scores across all data sizes, with the most significant advantage at the lowest training fraction. Performance for all models improves as the training data size increases. The method maintains a clear lead over baselines even as data availability grows, though the margin narrows slightly at higher data fractions.
The authors analyze the effectiveness of various reasoning structures by comparing zero-shot inference with supervised fine-tuning baselines. The results demonstrate that the proposed TRIAGE_SFT approach delivers the highest performance in discrimination metrics compared to all other tested methods. TRIAGE_SFT achieves superior performance in discrimination metrics relative to zero-shot inference and other supervised baselines. One-sided rationale supervision results in lower predictive accuracy compared to answer-only supervised fine-tuning. Zero-shot inference exhibits the weakest performance among the evaluated reasoning strategies.
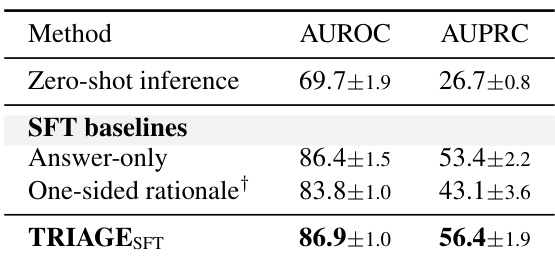
The authors evaluate TRIAGE against established baselines on the P12 and MIMIC-III datasets by testing performance across varying training data fractions, increasing input variable masking ratios, and distinct reasoning strategies. These experiments validate the model's high data efficiency in low-resource settings, its predictive stability under severe missing data conditions, and the effectiveness of reinforcement learning over zero-shot or standard supervised approaches. Overall, TRIAGE demonstrates superior resilience to training scarcity and incomplete clinical information while maintaining consistent top-tier performance across all tested scenarios.