Command Palette
Search for a command to run...
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
Abstract
Large language model (LLM) agents have achieved strong performance on a wide range of benchmarks, yet most evaluations assume static environments. In contrast, real-world deployment is inherently dynamic, requiring agents to continually align their knowledge, skills, and behavior with changing environments and updated task conditions. To address this gap, we introduce EvoArena, a benchmark suite that models environment changes as sequences of progressive updates across terminal, software, and social domains. We further propose EvoMem, a patch-based memory paradigm that records memory evolution as structured update histories, enabling agents to reason about environmental evolution through changes in their memory. Experiments show that current agents struggle on EvoArena, achieving an average accuracy of 39.6% across evolving terminal, software, and social-preference domains. EvoMem consistently improves performance, yielding an average gain of 1.5% on EvoArena and also improving standard benchmarks such as GAIA and LoCoMo by 6.1% and 4.8%. Beyond individual tasks, EvoMem further improves chain-level accuracy by 3.7% on EvoArena, where success requires completing a consecutive sequence of related evolutionary subtasks. Mechanistic analysis shows that EvoMem improves evidence capture in the memory, indicating better preservation of complete evolving environment states. Our results highlight the importance of modeling evolution in both evaluation and memory for reliable agent deployment.
One-sentence Summary
To address the gap in static evaluations for large language model agents, this work introduces EvoArena, a benchmark suite modeling progressive updates across terminal, software, and social domains, and EvoMem, a patch-based memory paradigm recording memory evolution as structured update histories to enable reasoning about environmental changes, yielding an average accuracy gain of 1.5% on EvoArena and improving GAIA and LoCoMo benchmarks by 6.1% and 4.8% respectively.
Key Contributions
- The paper introduces EvoArena, a benchmark suite that models environment changes as sequences of progressive updates across terminal, software, and social domains. Current agents struggle on this benchmark, achieving an average accuracy of 39.6% across the evolving domains.
- The paper proposes EvoMem, a patch-based memory paradigm that records memory evolution as structured update histories to enable reasoning about environmental changes. This method enhances transparency by making memory evolution inspectable through patch histories that document changes and triggering evidence.
- Results demonstrate that EvoMem yields an average gain of 1.5% on EvoArena and improves standard benchmarks such as GAIA and LoCoMo by 6.1% and 4.8%. Chain-level accuracy also increases by 3.7% on EvoArena for tasks requiring consecutive evolutionary subtasks.
Introduction
Large language model agents demonstrate strong performance on static benchmarks yet struggle in real-world deployments where interfaces, rules, and user preferences change continuously. Existing evaluation methods often rely on fixed environment snapshots, causing agents to fail when they overwrite useful historical context in favor of new information. To address this gap, the authors introduce EvoArena, a benchmark suite that models progressive updates across terminal, software, and social domains. They further propose EvoMem, a patch-based memory paradigm that records structured update histories to help agents reason about environmental changes without losing critical prior evidence.
Dataset
-
Dataset Composition and Sources
- The authors construct EvoArena, a benchmark suite evaluating agents under persistent environment evolution across three distinct regimes.
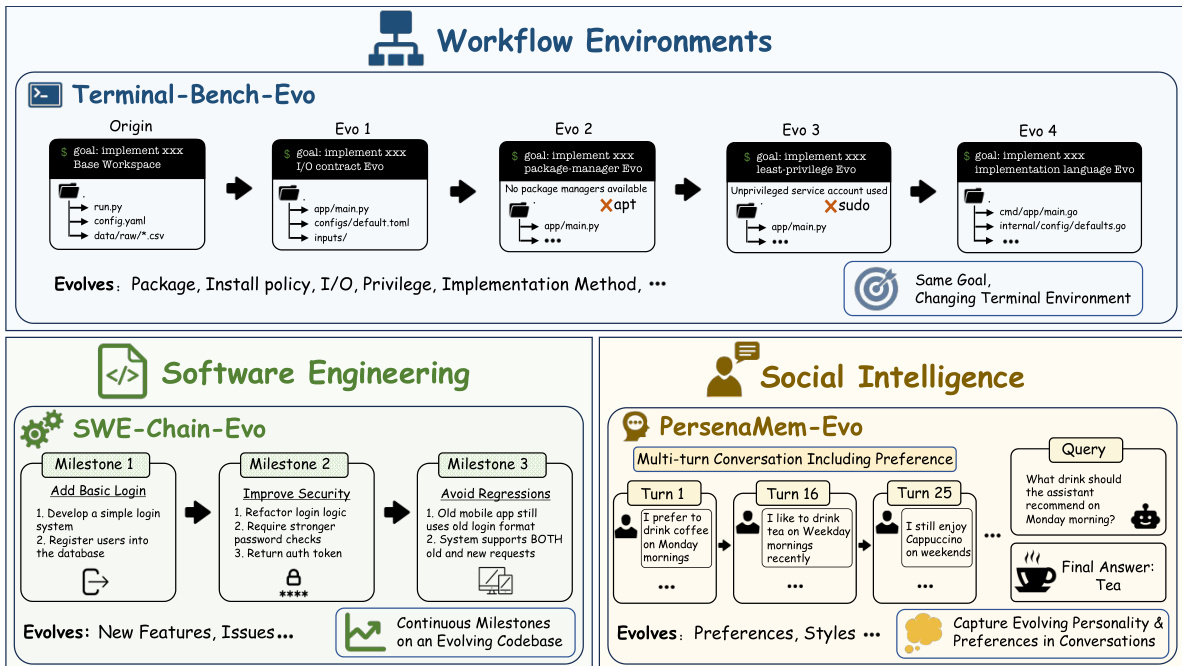
- Terminal-Bench-Evo extends 89 original Terminal-Bench tasks into executable workflow chains where the objective remains stable while execution conditions change.
- SWE-Chain-Evo utilizes 50 evolution chains derived from 12 active GitHub repositories with reproducible dependencies.
- PersonaMem-Evo builds on PersonaMem-v2 and PersonaHub to create 10 persona-level conversations focused on implicit behavioral evidence.
-
Key Details for Each Subset
- Terminal-Bench-Evo: Contains 441 total task instances across 89 chains with a mean length of 4.96 versions. Updates cover I/O protocols, CLI interfaces, dependencies, and workspace organization.
- SWE-Chain-Evo: Features 493 chain-step instances where milestones modify an average of 2.72 files. Each milestone includes Fail-to-Pass and Pass-to-Pass tests to validate functionality and regression.
- PersonaMem-Evo: Includes 505 preference-inference questions paired with long interaction histories averaging 174.7K tokens per persona. Questions test single-pattern transfer, conflict resolution, and temporal trajectory prediction.
-
Data Usage and Processing
- The data serves as an evaluation testbed rather than a training set, measuring Step Accuracy for individual tasks and Chain Accuracy for the full evolution sequence.
- Terminal Processing: A five-stage pipeline generates inherited versions where environment changes persist across releases, ensuring later versions build on earlier realized states.
- Software Processing: Repository states progress via oracle reference updates to prevent compounding agent errors during evaluation, isolating adaptation from execution failures.
- Persona Processing: Dual-blind filtering removes questions solvable by persona profiles alone or without context to ensure reliance on conversational memory.
-
Metadata and Construction
- Metadata records chain position, update types, changed components, and source preference evidence for diagnostic analysis of agent failures.
- Evolution chains are assembled chronologically to test adaptation to new versions while preserving valid prior behavior.
- Quality control steps include oracle validation for executability and consistency checks to ensure instruction, environment, and tests agree.
Method
The authors address a critical limitation in existing agent memory systems, which typically maintain only a single latest memory state. While effective for static environments, this design fails when knowledge is version-dependent. In evolving workflows, a rule updated for a new release may overwrite an earlier rule that remains valid for older releases or specific organizational contexts. To solve this, the authors introduce EvoMem, a framework that augments base memory systems with an explicit trace of memory evolution. Refer to the workflow environments diagram below to see the diverse settings where this evolution occurs.
EvoMem operates through two primary components: patch recording and patch-augmented retrieval. Refer to the framework diagram below for a visual overview of the system architecture.
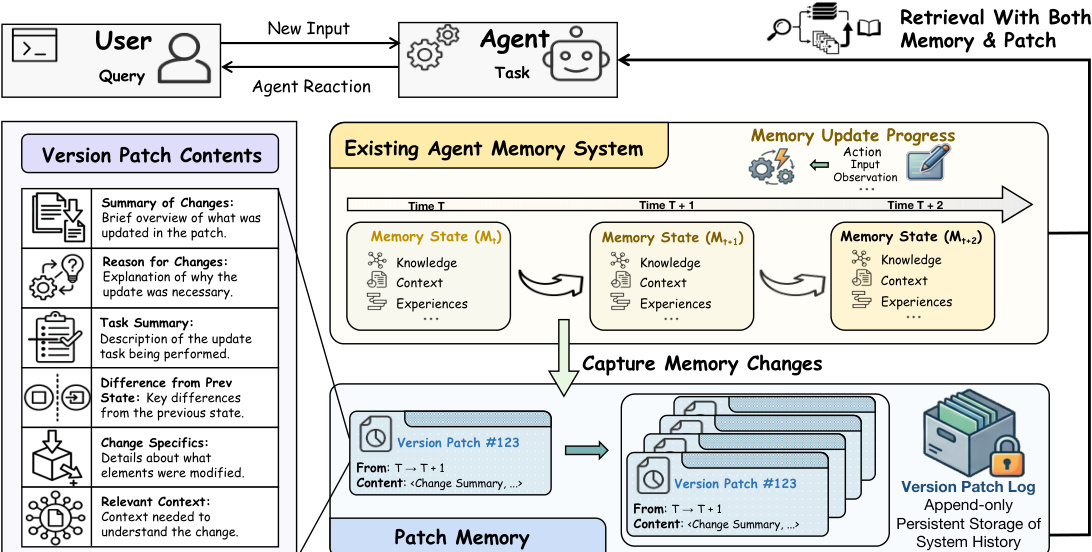 First, patch recording stores meaningful non-additive memory updates. This includes details on what changed, why it changed, and which evidence triggered the update. Second, patch-augmented retrieval retrieves relevant historical patches alongside the latest memory when a query depends on overwritten states or version-specific behavior. This design keeps the base memory system intact while making memory updates inspectable and reusable for downstream reasoning.
First, patch recording stores meaningful non-additive memory updates. This includes details on what changed, why it changed, and which evidence triggered the update. Second, patch-augmented retrieval retrieves relevant historical patches alongside the latest memory when a query depends on overwritten states or version-specific behavior. This design keeps the base memory system intact while making memory updates inspectable and reusable for downstream reasoning.
The goal of patch recording is to preserve behaviorally meaningful transitions. Let xt denote the input observation at time t, and let Mt−1 be the memory maintained by the base agent before observing xt. The base memory updater produces a new memory state:
Mt=U(Mt−1,xt)where U is an agent-specific update function. EvoMem monitors the transition from Mt−1 to Mt and captures memory changes that would otherwise be discarded. The system computes the difference:
Δt=Diff(Mt−1,Mt)EvoMem creates a patch only for non-additive updates, such as revisions or overwrites. For each non-additive update, the system writes a patch to an append-only patch history:
pt=(τt,Ct−,Ct+,rt,zt,et)Here, τt denotes temporal metadata, Ct− and Ct+ denote memory content before and after the update, rt records the rationale, zt provides a semantic summary, and et stores supporting evidence. The resulting patch history is P1:t={p1,…,pt}.
Patch-augmented retrieval exposes version-relevant evidence only when it helps resolve a query. Given a query q, EvoMem first retrieves evidence from the latest memory:
cmem=Rmem(q,MT)EvoMem then retrieves relevant patches from the history:
Pq=Rpatch(q,P1:T)The final context combines both sources:
c(q)=Concat(cmem,Pq)This allows the agent to ground decisions in both the current memory and the evolution trace behind it.
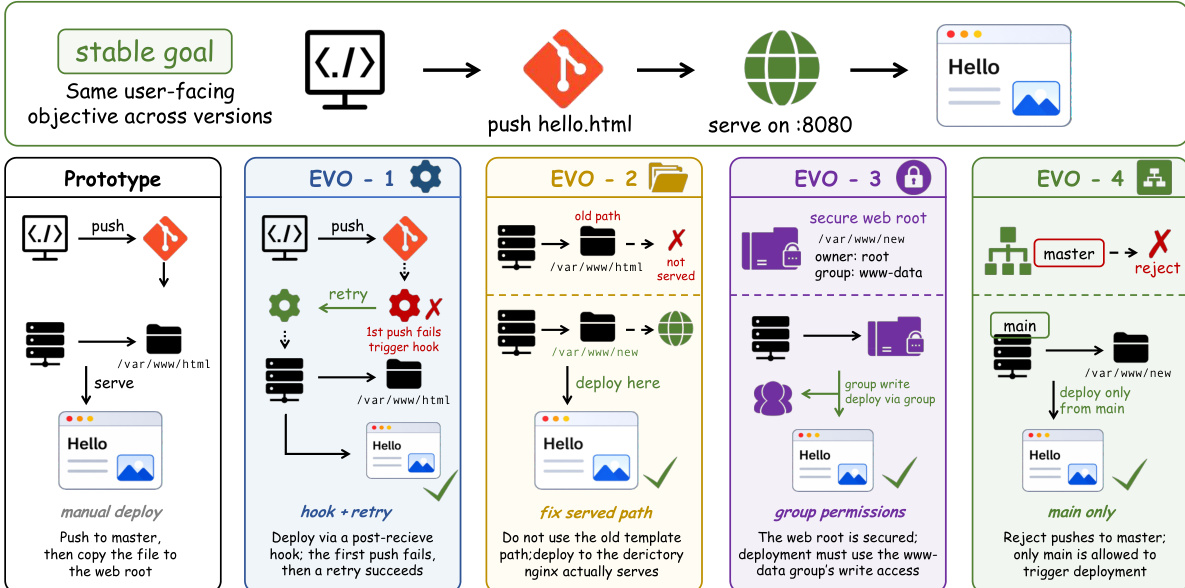
The framework is instantiated across various agent types. For terminal and software engineering agents, the environment evolves through specific milestones. As shown in the figure below, deployment workflows can evolve through stages such as hook and retry mechanisms, path fixes, and permission changes.
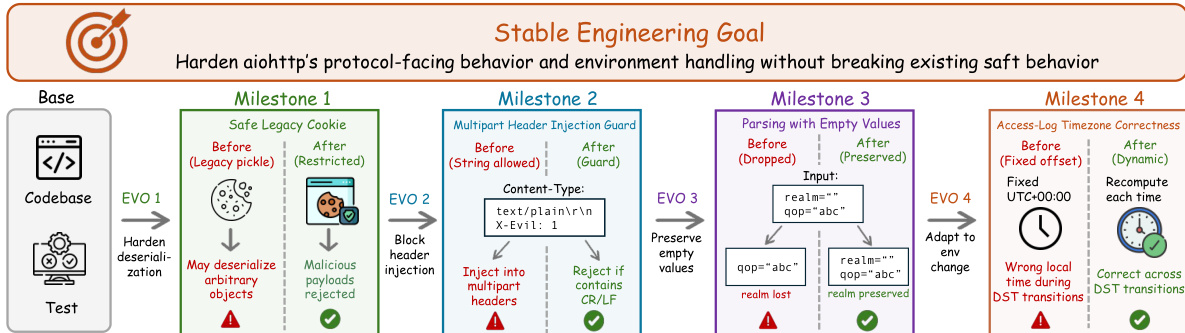
 Similarly, software engineering tasks involve continuous milestones on an evolving codebase. Refer to the engineering goal diagram for examples of hardening protocol behavior across versions.
Similarly, software engineering tasks involve continuous milestones on an evolving codebase. Refer to the engineering goal diagram for examples of hardening protocol behavior across versions.
 For social intelligence agents, the method tracks evolving user preferences over long conversations. As illustrated below, preferences can shift from general statements to specific temporal conditions across multiple turns.
For social intelligence agents, the method tracks evolving user preferences over long conversations. As illustrated below, preferences can shift from general statements to specific temporal conditions across multiple turns.
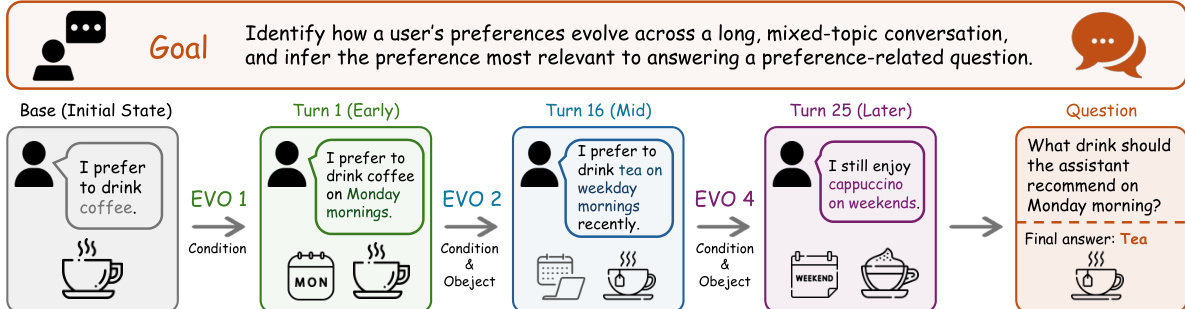 This separation turns memory from a single mutable store into a versioned evolution trace, allowing agents to retain access to prior states, rationales, and evidence for version-aware reasoning.
This separation turns memory from a single mutable store into a versioned evolution trace, allowing agents to retain access to prior states, rationales, and evidence for version-aware reasoning.
Experiment
The evaluation assesses EvoMem across evolving benchmarks like EvoArena and standard tasks to determine agent robustness under environment changes. Results demonstrate that EvoMem significantly enhances chain-level consistency by enabling agents to operationalize retrieved transition information and preserve historical constraints during software or preference evolution. Qualitative analysis confirms that the system is particularly effective when tasks require tracking dispersed temporal evidence or avoiding regressions in dependent sequences, indicating that preserving update history as retrievable evidence is crucial for maintaining reliability as task conditions change over time.
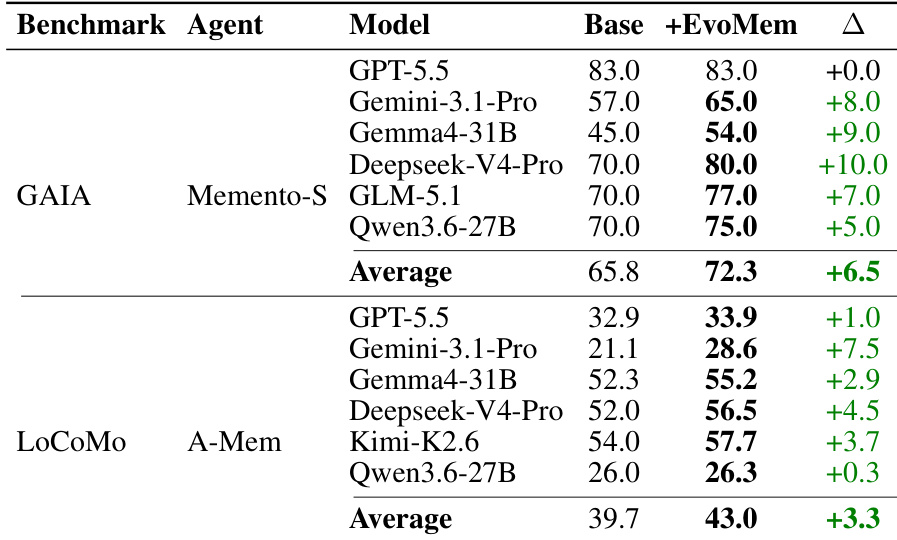
The authors evaluate the EvoMem method on standard agent benchmarks using multiple backbone models and specialized agents. The results demonstrate that adding EvoMem consistently improves task performance across all tested models compared to the baseline configuration. Both benchmarks show a positive shift in average scores, indicating that EvoMem effectively enhances agent robustness in these standard settings. EvoMem consistently yields positive performance gains across all tested models for the GAIA benchmark. The LoCoMo benchmark also shows uniform improvements when EvoMem is integrated with the base agent. Average scores increase for both benchmarks, confirming the general effectiveness of the memory augmentation.
The the the table outlines the composition of the software evolution benchmark dataset, categorizing repositories into six distinct domains such as web frameworks and cloud infrastructure. It demonstrates that the evaluation set spans a variety of software engineering contexts, aggregating multiple evolution chains and milestones across these categories. The cloud infrastructure and distributed systems domain contains the highest number of repositories and milestones. Testing frameworks comprise the smallest portion of the benchmark dataset. The dataset aggregates multiple evolution chains across various software domains to test long-horizon memory and robustness.

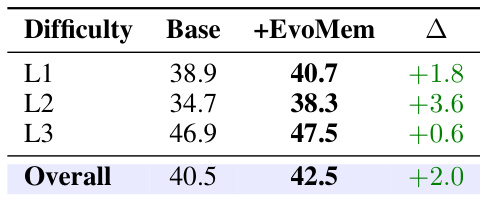
The the the table presents accuracy results for the PersonaMem-Evo benchmark, comparing a baseline agent configuration against one augmented with EvoMem. The results demonstrate that integrating EvoMem consistently enhances performance across all difficulty tiers, leading to a higher aggregate accuracy score. EvoMem provides a consistent performance boost over the baseline across all difficulty levels. The intermediate difficulty level shows the largest relative improvement compared to the baseline. While the hardest difficulty level starts with the highest baseline accuracy, the method still yields a positive gain.
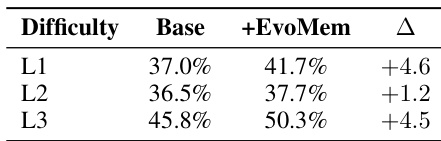
The results present a difficulty-level analysis of the PersonaMem-Evo benchmark using the GPT-5.5 backbone, comparing the baseline agent against the version enhanced with EvoMem. Data indicates that EvoMem consistently improves performance across all difficulty levels, with the most significant gains observed at the lowest and highest difficulty tiers. EvoMem provides consistent accuracy improvements over the baseline across all difficulty levels. The performance gains are notably larger at the easiest and hardest difficulty settings compared to the middle tier. The middle difficulty level exhibits the smallest improvement margin among the three evaluated groups.
The authors analyze how EvoMem affects performance across different reasoning types in evolving preference environments. The data indicates that the method is particularly effective for tasks requiring the arbitration of competing preferences and the synthesis of scattered signals. However, it shows a slight decline in performance for temporal trajectory tasks, suggesting potential difficulties in prioritizing the most recent valid state. The approach delivers the strongest performance improvements for conflict resolution and multi-pattern synthesis tasks. Single-pattern transfer tasks benefit marginally from the inclusion of EvoMem. Temporal trajectory tasks experience a reduction in accuracy compared to the baseline system.
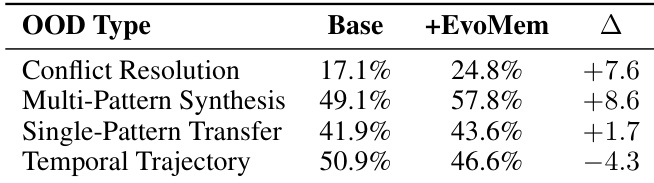
The study evaluates EvoMem on standard benchmarks including GAIA and LoCoMo, alongside specialized software evolution and PersonaMem-Evo datasets covering diverse domains and reasoning types. Experiments demonstrate that the method consistently improves task performance and agent robustness across multiple backbone models and difficulty tiers compared to baseline configurations, with specific analysis revealing strong gains in conflict resolution and multi-pattern synthesis tasks. Although temporal trajectory tasks experience a slight reduction in accuracy, these findings collectively validate EvoMem as a robust memory augmentation technique that enhances agent capabilities in complex, evolving environments.