Command Palette
Search for a command to run...
HydraHead: From Head-Level Functional Heterogeneity to Specialized Attention Hybridization
HydraHead: From Head-Level Functional Heterogeneity to Specialized Attention Hybridization
Zhentao Tan Wei Chen Jingyi Shen Yao Liu Xu Shen Yue Wu Jieping Ye
Abstract
The quadratic complexity of attention poses a critical bottleneck for long-context processing, spurring interest in hybrid attention designs. Most open-source hybrid models adopt a layer-wise strategy. Yet, prior work has noted the inherent difficulty of integrating Linear Attention (LA) with Full Attention (FA), suggesting that the design space of attention hybridization remains underexplored. To probe this space, we conduct interpretability analysis and observe that layers exhibit block-wise functional similarity, while individual heads within the same layer display distinct functional specialization despite sharing input features. This head-level heterogeneity suggests that the head dimension provides a natural and principled granularity for fusing heterogeneous attention signals. Building on this insight, we introduce HydraHead, a novel architecture that hybridizes FA and LA along the head axis. HydraHead features two key innovations: (1) an interpretability-driven selection strategy that identifies retrieval-critical heads and preserves FA only for them, and (2) a scale-normalized fusion module that reconciles the distributional gap between FA and LA head outputs. By leveraging a three-stage transfer pipeline with parameter reuse and distillation, we achieve high-performance hybrid models with minimal training overhead. Under a unified training setup, HydraHead outperforms other hybrid designs in long-context tasks while maintaining strong general reasoning. With interpretability-driven head selection, it matches a 3:1 layer-wise hybrid's long-context performance at a 7:1 LA-to-FA ratio. Crucially, trained on only 15B tokens, HydraHead achieves over 69% improvement over the baseline at 512K context length, approaching Qwen3.5, a leading model of comparable size with a native context length of 256K. This highlights the significant scaling potential of head-level hybridization.
One-sentence Summary
HydraHead hybridizes full and linear attention along the head axis by employing an interpretability-driven selection strategy to preserve full attention for retrieval-critical heads and a scale-normalized fusion module to reconcile output distributions, thereby achieving superior long-context performance and strong general reasoning with minimal training overhead while matching a 3:1 layer-wise hybrid at a 7:1 LA-to-FA ratio and delivering over 69% improvement at a 512K context length.
Key Contributions
- This paper introduces HydraHead, a novel Transformer architecture that hybridizes full attention and linear attention along the head dimension to mitigate the quadratic complexity of long-context processing. An interpretability-driven selection strategy identifies retrieval-critical heads to retain full attention, while routing all other heads through linear attention.
- A scale-normalized fusion module reconciles the distributional gap between full and linear attention outputs to ensure stable cross-head representation learning. The architecture is optimized through a three-stage transfer pipeline leveraging parameter reuse and distillation to achieve high performance with minimal training overhead.
- Evaluated under a unified training setup, the model outperforms existing hybrid designs in long-context tasks while maintaining strong general reasoning capabilities. Trained on only 15B tokens, it achieves over a 69% improvement over the baseline at 512K context length and matches the performance of a 3:1 layer-wise hybrid at a 7:1 linear-to-full attention ratio.
Introduction
The transition toward autonomous LLM agents requires extended context windows, yet standard full attention remains computationally prohibitive due to quadratic scaling. While linear attention provides efficient linear scaling, it frequently suffers from expressivity collapse, limiting its ability to perform precise long-range retrieval. Prior hybrid designs have predominantly relied on layer-wise or token-wise mixing, but these approaches struggle with training instability, representation inconsistency, or insufficient efficiency gains. The authors tackle these challenges by introducing HydraHead, a fine-grained architecture that hybridizes attention mechanisms along the head dimension. They leverage mechanistic interpretability to isolate retrieval-critical heads for full attention while assigning linear attention to the remaining heads. To harmonize the divergent output distributions, they develop a scale-normalized fusion module and a parameter-efficient three-stage training pipeline, ultimately achieving state-of-the-art long-context performance with minimal training overhead and robust general reasoning.
Experiment
The evaluation is conducted on the Qwen3-1.7B backbone across long-context retrieval and general reasoning benchmarks to compare the proposed HydraHead architecture against layer-wise, token-wise, and alternative head-wise baselines. Architecture comparisons validate that head-wise hybridization inherently balances long-context extrapolation and complex reasoning better than coarse-grained alternatives. Structural and fusion ablations confirm that interpretability-guided head selection, combined with proper feature normalization and static scaling modulation, ensures training stability and maximizes branch synergy. Finally, training optimization and scaling experiments demonstrate the method's robust generalization and consistent superiority over existing hybrid designs.
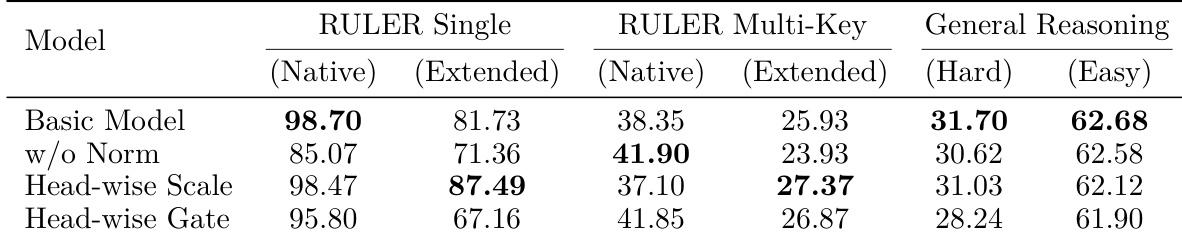
The authors evaluate feature fusion strategies for combining full and linear attention heads, highlighting the critical role of normalization in aligning heterogeneous feature distributions. Direct concatenation without normalization leads to substantial performance degradation across retrieval and reasoning benchmarks. Static head-wise scaling consistently outperforms dynamic gating, particularly in long-context extrapolation, establishing it as the superior fusion mechanism. Direct concatenation without normalization severely degrades retrieval accuracy and general reasoning capabilities. Static head-wise scaling provides more stable representations for long-context tasks compared to dynamic gating mechanisms. Dynamic gating offers localized benefits only within training-length regimes but fails to maintain advantages during length extrapolation.
The authors structure the training of their hybrid model into three progressive stages to optimize convergence and handle varying sequence lengths. They adjust hyperparameters such as batch size and learning rate schedules to stabilize the optimization dynamics between the different attention mechanisms. This configuration allows the model to effectively transfer knowledge while accommodating long-context dependencies in the final phase. The training pipeline utilizes a cosine learning rate scheduler for the initial phases to ensure stable convergence before switching to a constant rate. Context length is significantly increased in the final stage to refine the model's ability to handle extended sequences. The second training stage consumes the largest portion of the total token budget, emphasizing the importance of intermediate knowledge transfer.

The authors evaluate HydraHead against standard full attention models and other hybrid architectures to assess long-context retrieval capabilities. Results indicate that while full attention models excel at shorter sequences, they struggle significantly as context length increases. In contrast, the proposed hybrid method maintains high accuracy across extended lengths, effectively balancing extrapolation with multi-key retrieval performance. HydraHead sustains high retrieval accuracy at extended context lengths where other hybrid models degrade significantly. The hybrid approach balances long-context extrapolation with robust performance on multi-key retrieval tasks. Standard full attention models struggle with performance at the longest context lengths compared to the proposed hybrid architecture.
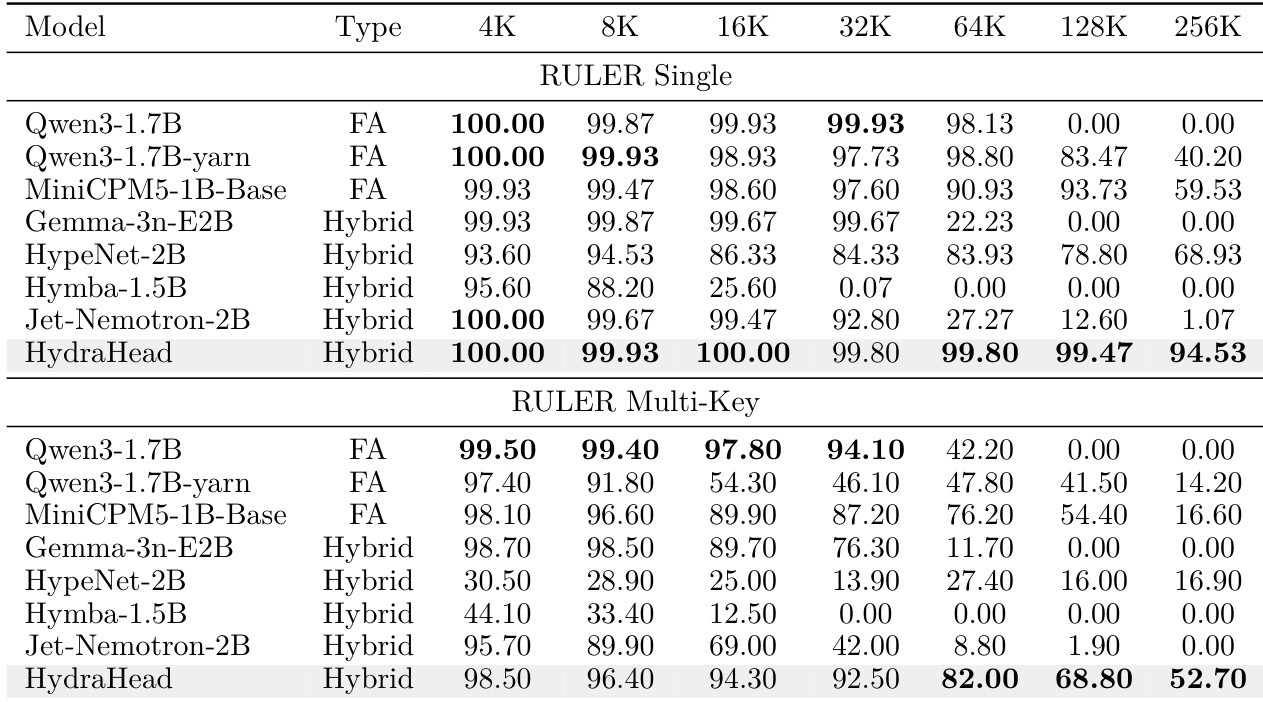
The comparison demonstrates that a head-wise hybrid architecture utilizing interpretability-guided selection at a higher linear attention ratio achieves long-context retrieval performance comparable to a traditional layer-wise hybrid approach. Despite operating with a significantly sparser budget for full attention heads, the proposed method substantially improves general reasoning capabilities across both challenging and standard benchmarks. The head-wise hybrid maintains robust extended context retrieval performance while operating at a much higher efficiency ratio than the layer-wise baseline. Interpretability-guided head allocation yields marked improvements in complex general reasoning tasks compared to uniform layer substitution. The proposed architecture successfully balances computational efficiency with superior performance on challenging reasoning benchmarks without sacrificing long-context capabilities.

The authors optimize the training pipeline across three stages to balance knowledge transfer and long-context adaptation. They scale up data and batch sizes in the initial stages to stabilize optimization, while reserving a final stage with a significantly longer context length for fine-tuning. This configuration yields consistent improvements across evaluation benchmarks, particularly in challenging long-context and reasoning tasks. The training strategy progresses from shorter contexts and decaying learning rates to a final stage focused on extended context lengths with a constant learning rate. Increasing data scale and batch sizes during the early stages enhances knowledge transfer and stabilizes optimization across heterogeneous attention branches. The final training stage employs a significantly larger sequence length to better accommodate long-context dependencies.

The authors evaluate a hybrid attention architecture that integrates full and linear attention heads through a three-stage progressive training pipeline designed to stabilize optimization and accommodate extended sequence lengths. Initial experiments validate feature fusion strategies, demonstrating that proper normalization and static head-wise scaling are essential for maintaining stable representations and outperforming dynamic gating during long-context extrapolation. Comparative evaluations against standard full attention and layer-wise hybrid baselines reveal that the proposed interpretability-guided head-wise approach successfully balances computational efficiency with robust multi-key retrieval while significantly enhancing complex reasoning capabilities. Ultimately, the study establishes that structured hybridization and progressive training effectively resolve the inherent trade-off between long-context scalability and general reasoning performance.