Command Palette
Search for a command to run...
World Action Models: A Survey
World Action Models: A Survey
Qiuhong Shen Shihua Zhang Yue Liao Qi Li Zhenxiong Tan Shizun Wang Shuicheng Yan Xinchao Wang
Abstract
World Action Models (WAMs) are embodied predictive-action models that make a forecast of the future available to action. Recent WAMs repurpose large video generation models, and a parallel line relies on language or vision-language backbones without a video-generation core. This rapid expansion has blurred the boundary among broad world models, video generation models, action-grounded video world models, Vision-Language-Action policies, and WAMs. This survey gives the field a common account. It first clarifies these boundaries, then organizes existing works through two complementary views. The first view asks what each method is required to generate, spanning rendered futures, latent futures, and video-generation-free action reasoning. The second view decomposes each method by predictive substrate, backbone, action coupling, and deployment regime. This anatomy supports a unified discussion of interactability, causality, persistence, physical plausibility, and generalization, followed by data, evaluation, and open challenges. Across these axes, a consistent design pattern emerges: WAMs are not simply video generators with action heads, but predictive-action methods whose design choices trade representational richness against compute, memory, latency, and action-label cost. The field is moving toward methods that generate less of the future while preserving what control requires. The survey homepage is available at https://world-action-models.github.io/.
One-sentence Summary
This survey clarifies the boundaries between World Action Models (WAMs) and related systems, categorizes existing approaches by their predictive substrate and action coupling, and identifies a consistent design pattern that trades representational richness against compute, memory, latency, and action-label costs.
Key Contributions
- This survey clarifies the conceptual boundaries between World Action Models, video generation models, vision-language-action policies, and broader world models to establish a common analytical vocabulary.
- It introduces a dual-perspective framework that categorizes existing methods by their generative requirements and systematically decomposes them by predictive substrate, backbone, action coupling, and deployment regime.
- It provides a unified analysis of core control properties including interactivity, causality, persistence, physical plausibility, and generalization, while identifying a consistent design pattern where predictive-action methods trade representational richness against compute, memory, latency, and action-label costs.
Introduction
Embodied AI is shifting from reactive policies to predictive systems that anticipate environmental dynamics before selecting actions. World Action Models (WAMs) enable this transition by coupling future simulation with real-time control, allowing robots to reason about physics, contact, and task consequences in unstructured settings. Prior approaches, however, suffer from fragmented architectures and inconsistent terminology. Reactive Vision-Language-Action models lack explicit environmental modeling, while video-centric world models often prioritize photorealism over action-relevant cues, creating excessive compute and latency that disrupt closed-loop control. The authors leverage this context to deliver a comprehensive survey that formalizes the WAM definition and organizes the rapidly expanding literature through two complementary frameworks. They introduce a philosophy-level taxonomy based on generation targets alongside a component-level anatomy tracking predictive substrates, backbones, action coupling, and deployment regimes. This unified structure enables systematic method comparison, clarifies critical embodiment requirements like physical plausibility and causality, and identifies key open challenges in balancing predictive fidelity with control efficiency.
Dataset
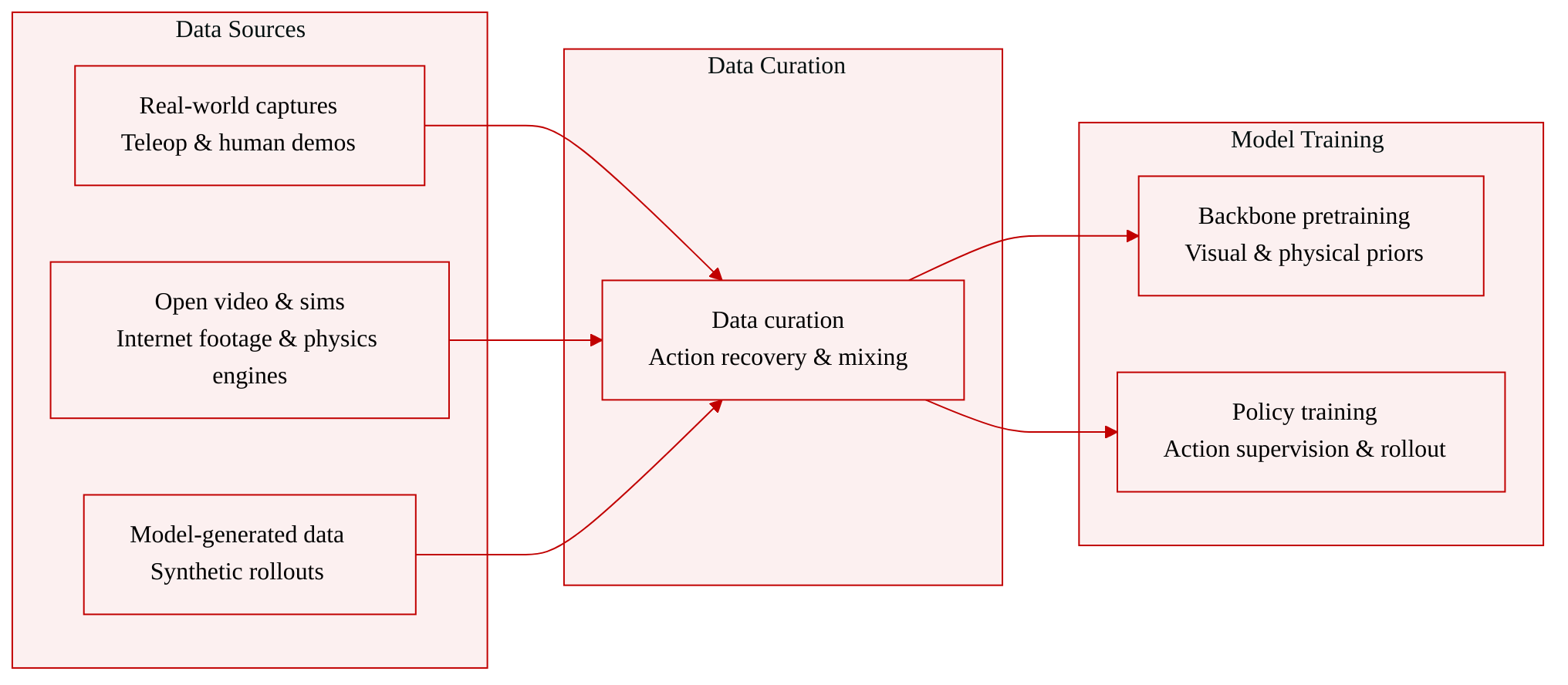
• Dataset Composition and Sources: The authors organize the training corpus into five primary categories based on the trade-off between scale, action-label quality, and embodiment alignment. These categories encompass robot teleoperation recordings, portable human demonstrations, internet-scale egocentric and instructional videos, physics-based and digital-twin simulations, and synthetic data generated by the models themselves.
• Subset Details: Robot teleoperation datasets like Open X-Embodiment and RoboNet deliver exact action commands with high label fidelity but require significant operator and robot time. Portable human demonstrations from platforms such as EgoVerse and EgoDex increase collection throughput through wearable or phone-based capture, though they introduce an embodiment gap. Internet video collections including Ego4D, EPIC-KITCHENS, and EgoScale provide massive visual variation and manipulation patterns but lack explicit action channels. Simulation environments like ManiSkill, LIBERO, and RoboCasa offer precise labels and controlled curricula at low marginal cost, though they present a sim-to-real gap. Synthetic trajectories produced by diffusion models or video generators bridge the gap between simulation and real-world data, inheriting both visual realism and generator failure modes.
• Training Usage and Mixture Strategy: The authors blend these sources to balance visual priors, trusted action labels, data scale, and controllable coverage. Internet video is primarily used to pretrain a video backbone or to train inverse-dynamics and latent-action models that recover control proxies. Teleoperation data supplies the ground-truth action supervision, while simulated and synthetic rollouts fill data gaps that are costly to collect physically. The paper notes that optimal mixture ratios for specific deployment regimes remain an unresolved research question, and access constraints limit independent verification for several large-scale sources.
• Processing and Evaluation Pipeline: The provided text does not specify explicit cropping strategies or detailed metadata construction pipelines. Processing primarily focuses on action recovery techniques, such as retargeting human demonstrations across robot embodiments, extracting pseudo-actions from unlabeled video, and training final policies directly on neural rollouts. The authors evaluate the resulting models using a two-stage protocol that pairs lightweight visual fidelity metrics with selective closed-loop success tests under explicit compute, memory, and latency constraints.
Method
The authors propose a unified framework for World Action Models that fundamentally link predicted future observations to action production. Unlike standard Vision-Language-Action models that directly map current context to actions, or traditional world models that predict future states without necessarily guiding control, a World Action Model ensures the predicted future observation actively shapes, scores, or trains the action path. The core contract is formalized as a conditional joint distribution over a window of future predictions and future actions, conditioned on observation history, past actions, and task instructions, expressed as pΘ(st+1:t+H,at:t+H−1∣c). This formulation establishes the operational boundary, where any predicted future must directly contribute to producing, scoring, verifying, or training the subsequent action. As shown in the figure below:

To navigate the diverse implementations across the field, the authors categorize existing models into three mutually exclusive design philosophies based on where the future predictor meets the action module during inference. Refer to the framework diagram:
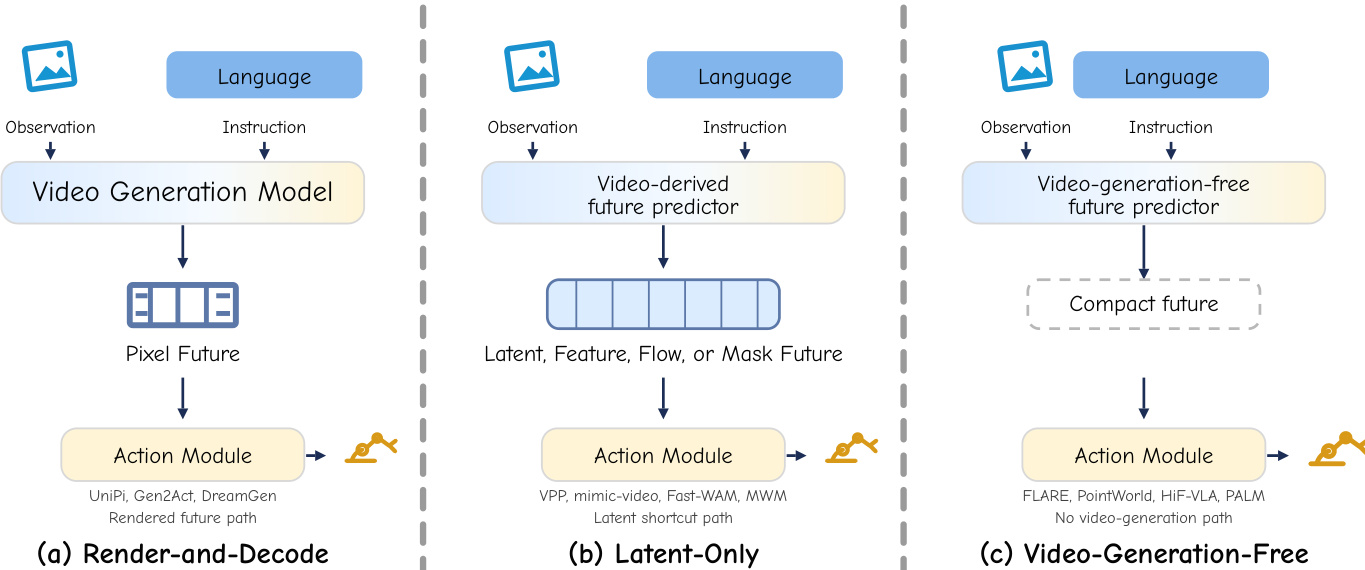 The first philosophy runs a video-generation backbone all the way to pixel output before decoding the action. This preserves full visual priors but incurs high latency. The second philosophy retains the video-derived dynamic prior but intercepts the inference path at intermediate latents, denoising features, or structured fields like flow or masks, bypassing pixel decoding to reduce computational cost. The third philosophy removes the video-generation backbone entirely. Instead, it leverages predictive supervision in compact representational spaces such as large language model or vision-language model embedding spaces, joint-embedding-predictive encoders, or non-video diffusion backbones, attaching lightweight action experts to these compact futures.
The first philosophy runs a video-generation backbone all the way to pixel output before decoding the action. This preserves full visual priors but incurs high latency. The second philosophy retains the video-derived dynamic prior but intercepts the inference path at intermediate latents, denoising features, or structured fields like flow or masks, bypassing pixel decoding to reduce computational cost. The third philosophy removes the video-generation backbone entirely. Instead, it leverages predictive supervision in compact representational spaces such as large language model or vision-language model embedding spaces, joint-embedding-predictive encoders, or non-video diffusion backbones, attaching lightweight action experts to these compact futures.
Building on these philosophies, the authors decompose any World Action Model into four separable but interacting design axes. As illustrated in the figure below:
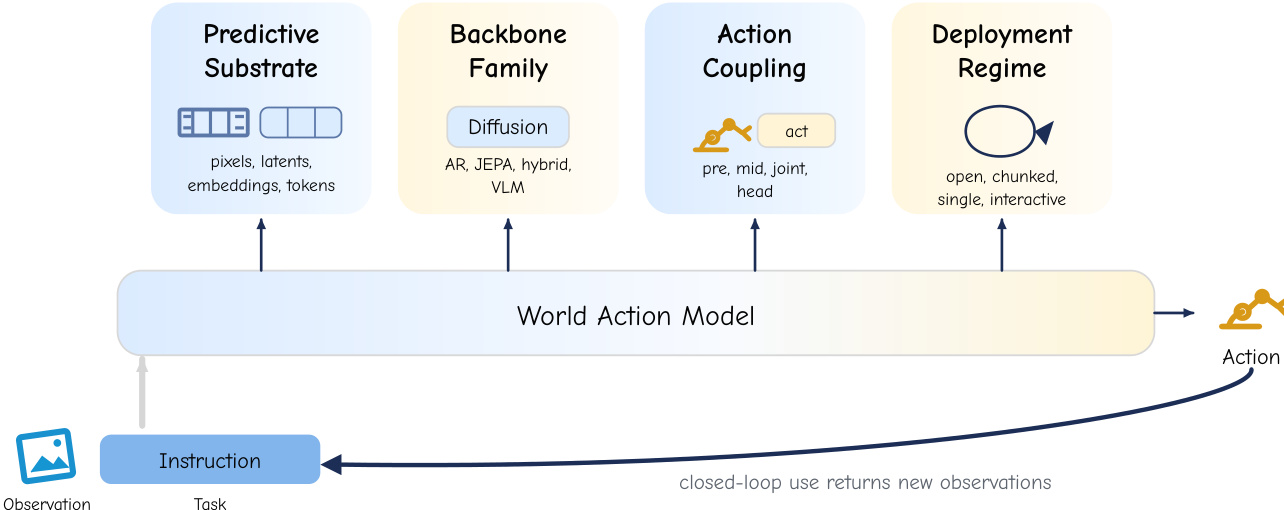 The first axis is the predictive substrate, which defines the representational space of the future variable. The second axis is the architectural backbone, which determines how the prediction is produced, including iterative-denoising networks, autoregressive decoders, joint-embedding predictors, hybrid architectures, or large language and vision-language models. The third axis is the action coupling, which specifies the factorization of the joint distribution and dictates how actions enter or leave the prediction loop. The fourth axis is the deployment regime, which governs the invocation cadence and horizon length relative to the control loop, ranging from open-loop rollout to chunked closed-loop control, single-step execution, and interactive simulator operation.
The first axis is the predictive substrate, which defines the representational space of the future variable. The second axis is the architectural backbone, which determines how the prediction is produced, including iterative-denoising networks, autoregressive decoders, joint-embedding predictors, hybrid architectures, or large language and vision-language models. The third axis is the action coupling, which specifies the factorization of the joint distribution and dictates how actions enter or leave the prediction loop. The fourth axis is the deployment regime, which governs the invocation cadence and horizon length relative to the control loop, ranging from open-loop rollout to chunked closed-loop control, single-step execution, and interactive simulator operation.
Focusing on the predictive substrate, the authors classify the future representation into four distinct categories. Refer to the figure below:
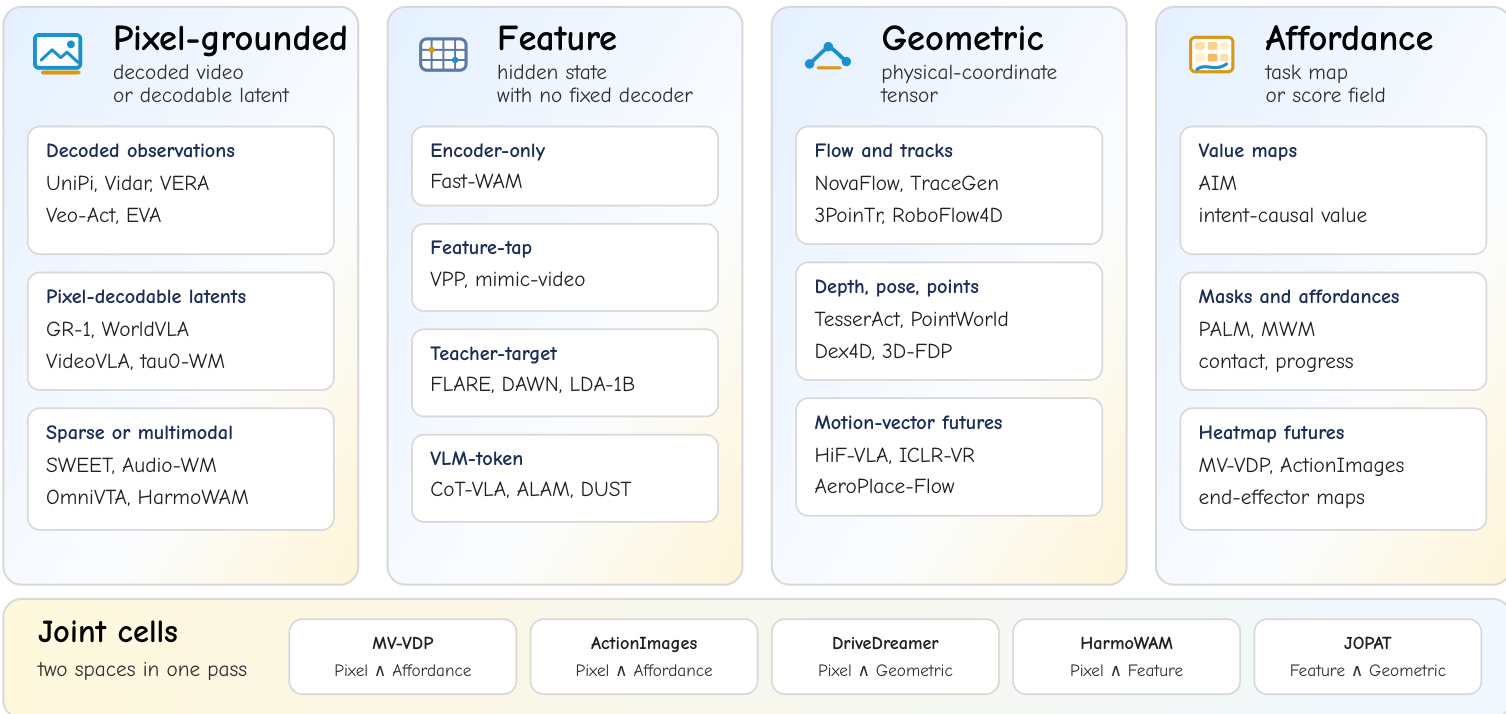 Pixel-grounded substrates expose decoded observations or decoder-bound latents that map back to video, preserving appearance and motion priors. Feature substrates represent learned hidden states, teacher embeddings, or token blocks without a fixed observation decoder, trading direct visual interpretability for compactness and semantic invariance. Geometric substrates expose physical-coordinate tensors such as optical flow, point tracks, depth, pose, or motion vectors, compressing the future toward motion rather than texture. Affordance substrates expose task-relevant label or score maps, including value maps, contact likelihood fields, semantic masks, or end-effector heatmaps, directly aligning the predicted future with control objectives.
Pixel-grounded substrates expose decoded observations or decoder-bound latents that map back to video, preserving appearance and motion priors. Feature substrates represent learned hidden states, teacher embeddings, or token blocks without a fixed observation decoder, trading direct visual interpretability for compactness and semantic invariance. Geometric substrates expose physical-coordinate tensors such as optical flow, point tracks, depth, pose, or motion vectors, compressing the future toward motion rather than texture. Affordance substrates expose task-relevant label or score maps, including value maps, contact likelihood fields, semantic masks, or end-effector heatmaps, directly aligning the predicted future with control objectives.
Finally, the action coupling axis defines the structural decision that transforms a predictive world model into an actionable policy. As shown in the figure below:
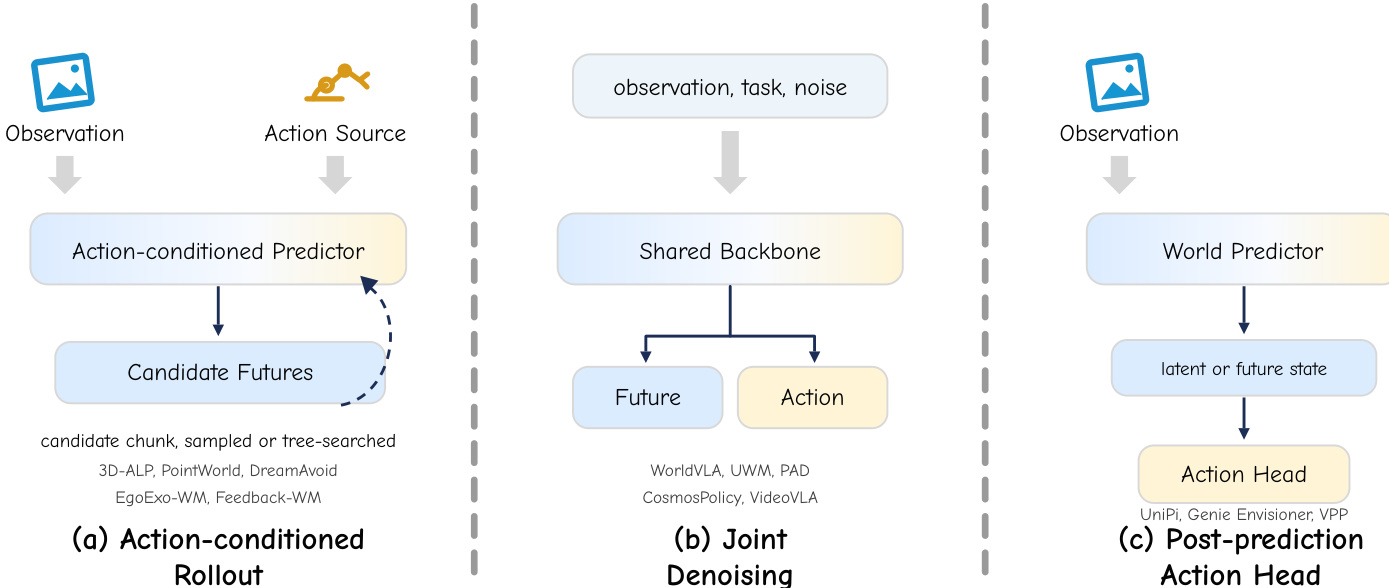 The first arrangement is action-conditioned rollout, where an outer planner or policy supplies candidate actions, and an action-conditioned world model predicts their consequences. This can operate at the chunk level or step-wise. The second arrangement is joint generation, where a single generative process on a shared backbone produces both the substrate and the action chunk simultaneously, enforcing mutual consistency through a coupled loss. The third arrangement is the post-prediction action head, where the substrate generator predicts the future first, and a smaller, separate action expert decodes the control signal from that prediction. This factorization allows pretrained predictors to remain fixed while the action head adapts to specific embodiments or control interfaces.
The first arrangement is action-conditioned rollout, where an outer planner or policy supplies candidate actions, and an action-conditioned world model predicts their consequences. This can operate at the chunk level or step-wise. The second arrangement is joint generation, where a single generative process on a shared backbone produces both the substrate and the action chunk simultaneously, enforcing mutual consistency through a coupled loss. The third arrangement is the post-prediction action head, where the substrate generator predicts the future first, and a smaller, separate action expert decodes the control signal from that prediction. This factorization allows pretrained predictors to remain fixed while the action head adapts to specific embodiments or control interfaces.
Experiment
The first experiment compares chunk-level and step-wise action-conditioned rollout strategies, validating that parallel candidate scoring and continuous mid-trajectory adaptation respectively enable robust counterfactual control in world models. The second experiment assesses current benchmarking protocols, revealing that isolated success metrics or averaged performance scores frequently obscure critical trade-offs and task-specific failure modes. Ultimately, the findings establish that reliable evaluation requires integrated reporting frameworks that jointly quantify accuracy, latency, planning horizon, and computational constraints.
The authors introduce FLARE as a World Action Model characterized by a joint-embedding backbone and a feature-based teacher substrate. The system utilizes a post-prediction head for action coupling and adopts a chunked deployment strategy. This configuration places FLARE within the chunk-level submode family, where actions are processed in parallel blocks rather than step-by-step. FLARE operates on a chunked deployment strategy, aligning with the chunk-level submode family for parallel candidate evaluation. The model employs a joint-embedding backbone and a post-prediction head to couple actions with predictions. The chunked approach allows for the parallel assessment of action candidates but limits reactive control during the prediction window.

The evaluation of FLARE examines its chunked deployment strategy within a parallel candidate assessment framework, validating the architectural integration of a joint-embedding backbone and feature-based teacher substrate. By incorporating a post-prediction head for action coupling, the system successfully transitions action processing from sequential steps to parallel evaluation blocks. This design yields a clear qualitative trade-off, delivering enhanced parallel efficiency while inherently limiting reactive control during active prediction windows.