Command Palette
Search for a command to run...
PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
Abstract
LLM agents increasingly operate in large tool ecosystems, where real-world tasks require discovering relevant tools, inferring implicit sub-goals, and adapting to dynamic environments over long horizons. However, existing benchmarks rarely evaluate planning under retrieval-limited tool visibility. To address this gap, we introduce PlanBench-XL, an interactive benchmark of 327 retail tasks over 1,665 tools that tests whether agents can iteratively retrieve usable tools, invoke them to uncover intermediate evidence for subsequent calls toward the final goal. PlanBench-XL further features an optional blocking mechanism that simulates real-world unpredictability through missing, failing, or distracting tool functions, forcing agents to detect disrupted paths and adapt at runtime. Experiments on ten leading LLMs show that massive-tool planning remains challenging: while GPT-5.4 achieves 51.90% accuracy in block-free settings, it collapses to 11.36% under the most severe blocking condition. Further analysis shows that agents are especially vulnerable when failures lack explicit error signals or when recovery requires longer alternative tool-use paths. These results establish PlanBench-XL as a testbed for diagnosing agentic planning failures and highlight the need for robust adaptive planning in long-horizon tasks with large, imperfect tool environments.
One-sentence Summary
PlanBench-XL evaluates long-horizon planning for LLM tool-use agents across 327 retail tasks and 1,665 tools by introducing an optional blocking mechanism that simulates real-world unpredictability through missing, failing, or distracting functions, revealing that GPT-5.4's accuracy drops from 51.90% in block-free settings to 11.36% under severe blocking and underscoring agent vulnerability to silent failures and complex recovery paths.
Key Contributions
- This paper introduces PlanBench-XL, a scalable benchmark framework that automatically generates 327 grounded retail tasks across 1,665 tools to evaluate iterative tool retrieval and intermediate evidence discovery. The framework addresses retrieval-limited tool visibility by providing an automated pipeline for constructing multi-step tool-use trajectories.
- A dynamic interaction environment simulates real-world unpredictability through an optional blocking mechanism that injects missing, failing, or distracting tool functions during execution. This design forces agents to detect disrupted paths and adapt their planning strategies in real time.
- Comprehensive evaluations of ten frontier language models demonstrate that massive-tool planning remains challenging, with top models experiencing accuracy drops from 51.90% to 11.36% under severe blocking conditions. Further analysis reveals that current agents struggle particularly when failures lack explicit error signals or require extended alternative tool-use paths for recovery.
Introduction
Large language model agents increasingly rely on external tools to solve complex, long-horizon tasks in real-world environments like enterprise systems and web platforms. Because context windows restrict full tool visibility, agents must iteratively retrieve and invoke tools to uncover intermediate information, making adaptive planning essential for practical deployment. Prior benchmarks, however, typically assume fixed and fully visible toolsets with clean descriptions and explicit goals, largely ignoring the retrieval noise, missing or failing functions, and dynamic path disruptions that define actual tool ecosystems. To bridge this gap, the authors introduce PlanBench-XL, an interactive benchmark featuring 327 multi-step retail tasks across 1,665 tools that forces agents to navigate partial visibility and recover from simulated tool failures. By evaluating ten leading models, they demonstrate that current agents struggle significantly with massive-tool planning under unreliable conditions, establishing a new testbed for developing robust, adaptive agentic systems.
Dataset
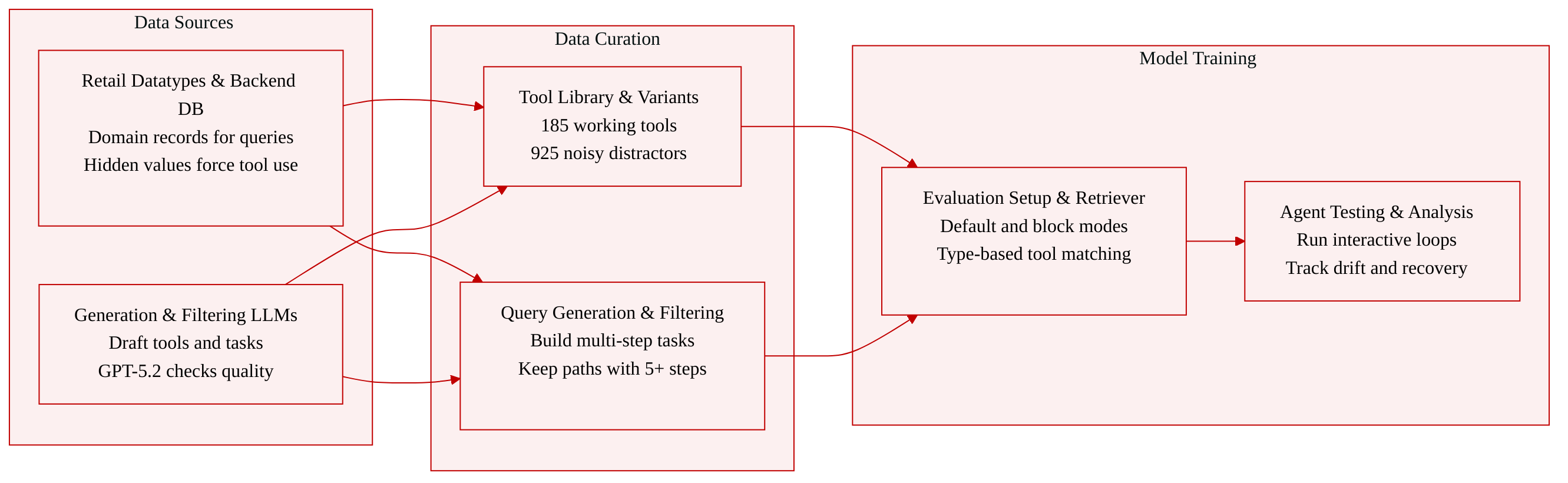
Dataset Composition and Sources
- The authors introduce PlanBench-XL, a synthetically generated benchmark focused on the retail domain to evaluate long-horizon planning and tool exploration in massive tool-use environments.
- The dataset is constructed using a scalable pipeline driven by generation and filtering language models, with GPT-5.2 employed for filtering tasks to ensure quality control.
- The environment relies on a self-defined set of domain-specific datatypes that represent distinct retail information, serving as the foundation for tool schemas and backend records.
Key Details for Each Subset
- Executable Tools: The tool library contains 185 tools derived from combinatorial pairs of input and output datatypes. Input schemas range from 1 to 5 datatypes, while output schemas contain exactly 1 datatype.
- Noisy Tools: The authors augment the library with 925 noisy tools, creating five variants per executable tool to simulate realistic retrieval imperfections. These variants cover categories including deprecated, condition-limited, stale, unreliable, and non-authoritative behaviors.
- Queries: Tasks are generated by specifying initial and target datatype sets, computing valid tool sequences, and verbalizing the tasks with concrete entities instantiated from the backend database.
- Filtering Rules: Tools are filtered to enforce deterministic dependencies, ensure information access requires actual tool execution, maintain domain realism, and guarantee non-trivial information gain. Queries are retained only when the shortest solution path requires at least five distinct tool calls and all declared inputs are necessary for the solution.
Data Usage and Processing
- Evaluation Modes: The benchmark supports a default mode with retrieval noise and a block mode that disrupts useful paths to assess agent recovery and re-planning capabilities.
- Backend Construction: A backend database is instantiated with non-trivial values to force tool invocation, as outputs cannot be inferred from common sense or the query text alone.
- Ground Truth: Process-level ground truth is derived via a backward search algorithm to identify inclusion-minimal tool sets and legal execution orders that transform initial datatypes into target datatypes.
- Retrieval Strategy: Tools are exposed through a custom retriever that supports bi-directional exploration, matching queries to tools based on datatype structures rather than surface-level text descriptions.
Metadata and Additional Processing
- Internal Metadata: The dataset includes metadata tracking input and output datatypes for dependency validation, progress-call annotation, and evaluation diagnostics.
- Agent-Schema: The information provided to models consists of function names, descriptions, parameters, and strictness constraints, with datatype annotations hidden as internal metadata to prevent direct graph recovery.
- Naming Convention: Tool names follow an alias-based template with optional version suffixes to mimic real-world inconsistencies and discourage simple name matching.
- Failure Annotations: Trajectories are annotated to categorize failures into no traction, irrecoverable drift, weak recovery, and format errors based on whether tool calls produce useful intermediate evidence.
Experiment
The PlanBench-XL benchmark evaluates frontier and open-source LLMs on long-horizon adaptive planning within massive tool ecosystems, using baseline assessments, retrieval-time blocking, enforced exploration, and path-length variations to validate core capabilities, robustness to corrupted tools, adaptive recovery potential, and complexity tolerance. Results indicate that while broad exploration and precise execution strongly drive success, current models consistently struggle to adapt when tools are silently corrupted or recovery paths lengthen, with additional test-time compute yielding only marginal gains. Qualitative analysis reveals that performance bottlenecks primarily stem from trajectory drift and flawed tool-selection rather than retrieval limitations, underscoring the need for agents to reliably detect unreliable feedback and dynamically re-plan under partial observability.
The evaluation reveals a pronounced performance divide between frontier models and smaller open-source variants, with larger architectures consistently demonstrating superior task completion and execution precision. While broader exploration of available tool datatypes generally correlates with higher success rates, excessive retrieval activity does not guarantee effective progress, as some models waste interaction turns on uninformative searches. Furthermore, maintaining basic tool-use reliability remains essential, as models that successfully minimize invalid calls and filter out untrusted inputs achieve significantly higher overall accuracy. Larger model variants consistently outperform their smaller counterparts in both task completion accuracy and execution quality. Excessive retrieval turns and high search-to-call ratios do not necessarily translate into successful task completion or efficient exploration. Minimizing structurally invalid tool calls and rejecting untrusted inputs are strongly associated with higher overall task success rates.
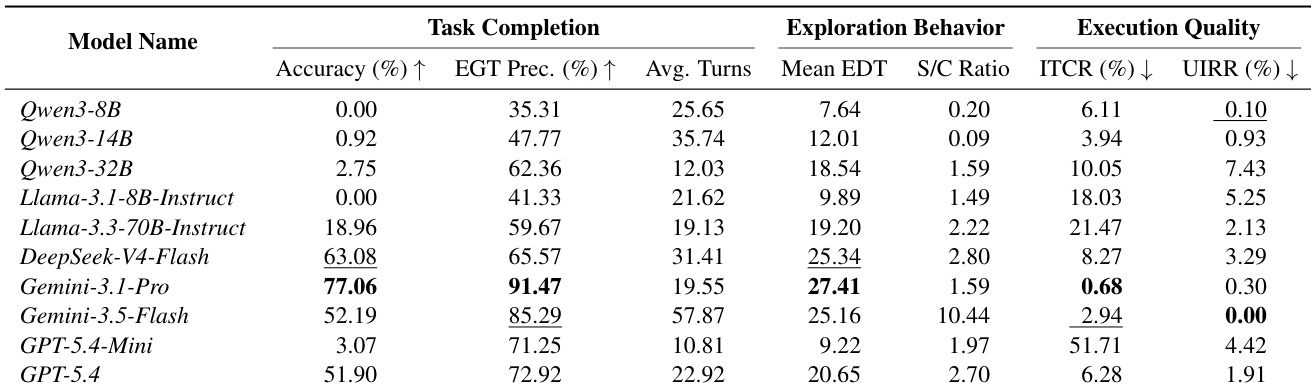
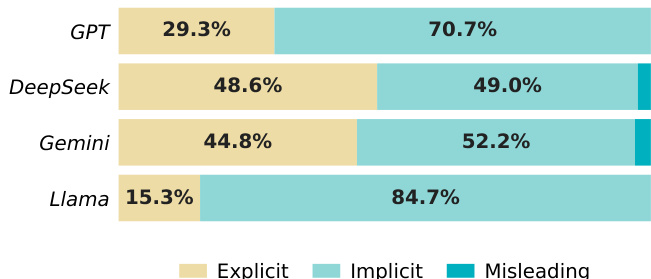
The analysis of block alternative invocation reveals that models predominantly interact with explicit and implicit failures, while largely avoiding semantically misleading tools. Architectural differences lead to varying failure preferences, with some models heavily favoring silent failures and others showing a more even split between explicit and implicit error types. This distribution underscores the significant challenge agents face in handling subtle, executable-looking failures compared to obvious semantic mismatches. Models consistently avoid semantically misleading tools, demonstrating effective initial tool filtering. Llama and GPT exhibit a strong tendency to invoke implicit failures over explicit ones. DeepSeek and Gemini display a more balanced reliance on both explicit and implicit failure types.
The authors evaluate the statistical reliability of their benchmark by computing confidence intervals across multiple models and evaluation metrics. The reported uncertainty margins are consistently narrow relative to the observed performance gaps between models, indicating that the primary findings are stable and not driven by random sampling variation. Statistical uncertainty remains minimal across all tested models and metric categories. Narrow confidence margins confirm that observed performance differences reflect genuine capability variations rather than sampling noise. Robustness analysis demonstrates that the benchmark yields consistent outcomes under repeated evaluation conditions.
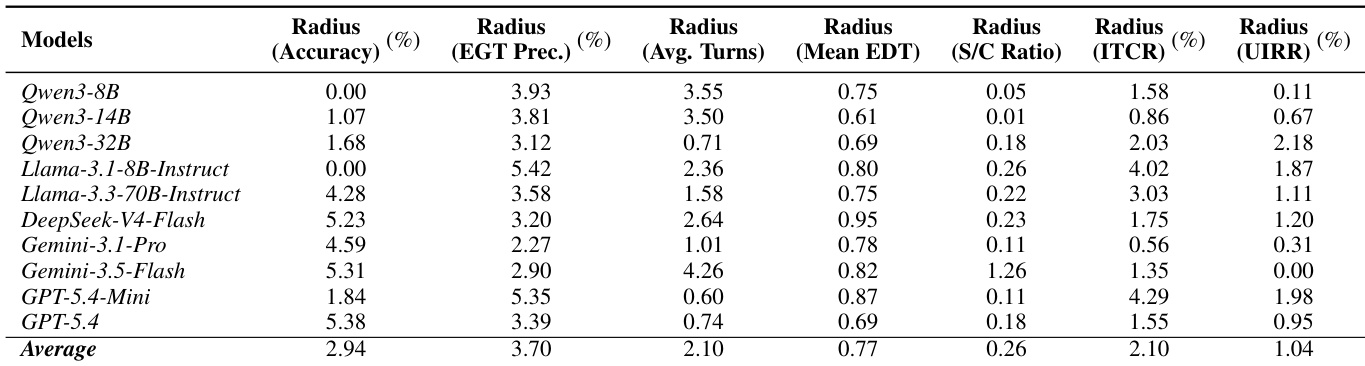
The authors evaluate a smaller open-source model on a single-step tool retrieval task to verify that benchmark results are not primarily limited by retriever coverage. The model demonstrates strong capability in locating and executing the correct tool, closely matching the ideal interaction pattern. High execution precision and an absence of invalid calls indicate that the retrieval system and runtime protocol reliably supply valid tools for straightforward queries. High accuracy and precision indicate reliable task completion and relevant execution. The retrieval system frequently includes ground-truth tools, supporting effective single-step planning. Interaction length closely matches the ideal trajectory, with no structural or procedural call failures.

The authors introduce a comprehensive evaluation framework that simultaneously addresses multiple critical dimensions of tool-use planning, including retrieval, sub-goal reasoning, exploration, and handling unreliable tools. Unlike prior benchmarks that focus on isolated capabilities, this proposed framework integrates all key features to provide a holistic assessment of agent performance in large-scale tool ecosystems. Existing benchmarks typically evaluate only a limited subset of tool-use capabilities, leaving critical areas like bi-directional exploration and unreliable tool handling largely untested. The proposed framework uniquely covers all seven evaluated dimensions, enabling a more complete assessment of agent adaptability and robustness. This comprehensive design highlights a significant gap in current evaluation suites, which often overlook the interplay between long-horizon planning and tool reliability.

The evaluation utilizes a comprehensive framework that holistically assesses multi-dimensional tool-use capabilities, including retrieval, reasoning, exploration, and unreliable tool handling. Experiments validate that larger frontier models consistently outperform smaller variants in execution precision, while demonstrating that excessive search activity hinders efficiency and that minimizing invalid calls and filtering untrusted inputs are critical for success. Analysis of failure modes reveals that agents effectively avoid semantically misleading tools but struggle with subtle implicit failures, with architectural differences heavily influencing error preferences. Additional reliability and retrieval tests confirm that observed performance gaps reflect genuine capability variations rather than sampling noise or system limitations.