Command Palette
Search for a command to run...
DOPD: Dual On-policy Distillation
DOPD: Dual On-policy Distillation
Abstract
On-policy distillation (OPD) offers superior capacity transfer by supervising student-sampled trajectories with dense token-level signals. To furnish high-quality supervision sources and thereby elevate the performance frontier of distillation, an intuitive direction is to infuse privileged information to either teacher or student itself. However, this additional input induces a potential failure mode we dub privilege illusion: a pattern that conflates the transferable capability gap that students are meant to close, and the information asymmetry gap that can only be mimicked but never replicated. This issue is further amplified by the inherent non-uniformity of token-level supervision, where only a small subset of tokens carries pivotal capability-bearing signals. To this end, we propose DOPD, an advantage-aware dual distillation paradigm that dynamically routes token-level supervision between privileged teacher and privileged student policies based on their advantage gap and relative probabilities. Each token receives supervision of different strength, objective, and strategy from either teacher or student itself, which transfers credible capability while simultaneously receiving auxiliary signals, to alleviate privilege illusion. Extensive experiments on both large language model (LLM) and vision-language model (VLM) settings demonstrate that DOPD consistently outperforms Vanilla OPD and other counterparts. Further results on stability, robustness, continual learning, and out-of-distribution tasks validate its superiority.
One-sentence Summary
Researchers from NUS, MMLab, CUHK, and others propose DOPD, an advantage-aware dual on-policy distillation paradigm that dynamically routes token-level supervision between privileged teacher and student policies using their advantage gaps and relative probabilities to mitigate privilege illusion, consistently outperforming baselines on LLM and VLM tasks.
Key Contributions
- Privilege illusion is identified as a failure mode in on-policy distillation where privileged inputs create information asymmetry that the student can mimic but not internalize, causing performance degradation and entropy collapse.
- DOPD, an advantage-aware dual distillation framework, dynamically routes token-level supervision between a privileged teacher and a privileged student policy based on their advantage gap and relative token probabilities, applying strong teacher distillation to capability-bearing tokens and auxiliary self-optimization to others.
- Experiments on large language model and vision-language model settings demonstrate that DOPD consistently outperforms vanilla on-policy distillation and other counterparts, with additional gains in stability, robustness, continual learning, and out-of-distribution tasks.
Introduction
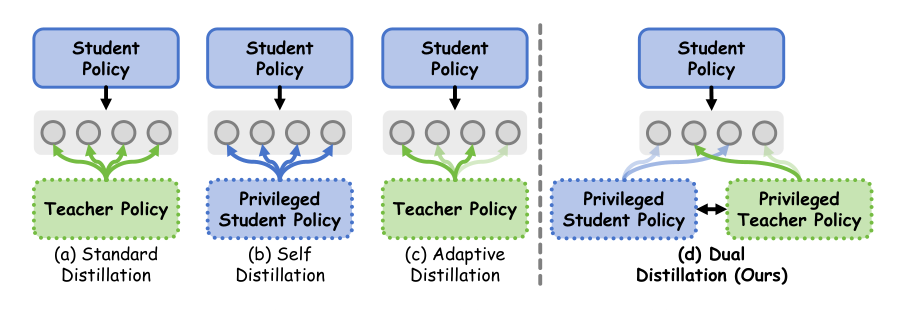
On-policy distillation (OPD) has emerged as an effective post-training approach for transferring capabilities from a teacher model to a student by providing dense, token-level supervision on trajectories sampled from the student’s own policy. This paradigm helps mitigate distribution shift and is applied across large language and vision-language models. However, when the teacher or student gains access to privileged information such as verified reasoning hints or structured visual annotations, the teacher’s apparent performance advantage can arise from information asymmetry rather than genuinely transferable capability, a failure mode the authors term “privilege illusion.” Prior OPD methods uniformly distill all tokens without distinguishing between capability-driven and privilege-driven gains, often causing entropy collapse, reduced exploration, and poor distillation. To address this, the authors propose DOPD, an advantage-aware dual on-policy distillation framework that adaptively routes token-level supervision based on the privilege advantage gap: it applies strong teacher distillation on tokens where the teacher exhibits a credible capability advantage and lighter self-supervision elsewhere, thereby selectively transferring capacity while avoiding privilege illusion.
Dataset
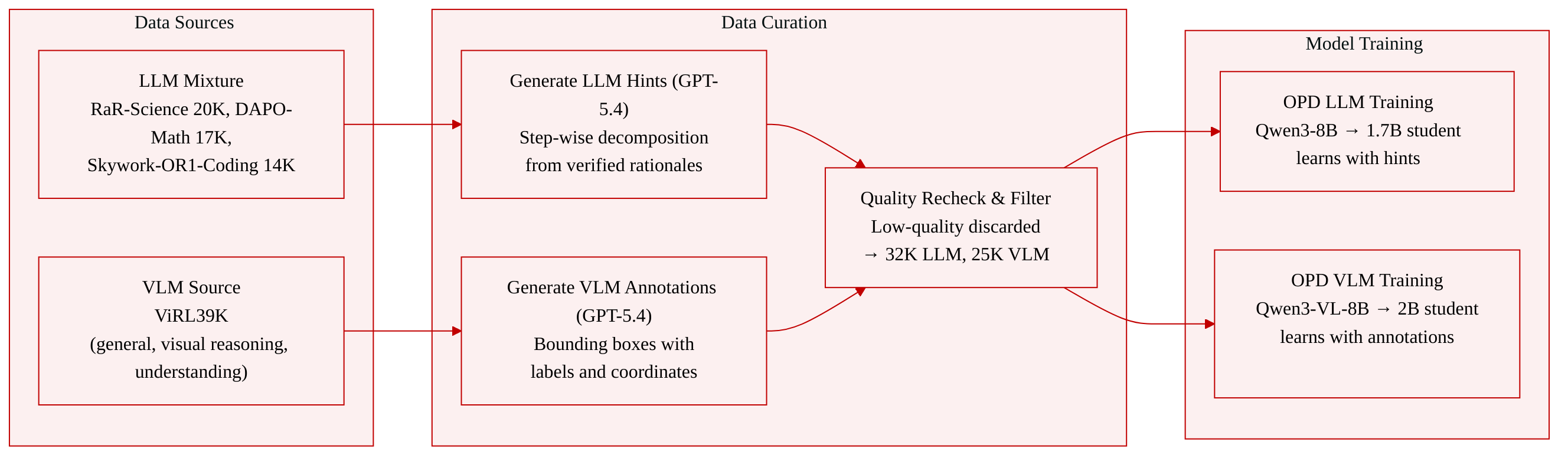
The authors construct two distinct training sets for Language Model (LLM) and Vision-Language Model (VLM) scenarios, each derived from existing public resources and then enriched with privileged information.
Dataset composition and sources
- LLM training set: a mixture of three source datasets covering general, reasoning, and coding tasks:
- RaR-Science-20K (general)
- DAPO-Math-17K (reasoning)
- Skywork-OR1-Coding-14K (coding)
- VLM training set: based on the ViRL39K dataset, which spans general, visual reasoning, and visual understanding tasks.
Processing and metadata construction
- For each sample, privileged input is generated using GPT-5.4 (2026-03-05).
- LLM privileged information: step-wise decomposition hints derived from verified rationales; no direct execution trace or final answer is included.
- VLM privileged information: structured visual annotations consisting of query-related bounding boxes, each with an object label and quadruple coordinates providing explicit visual context.
- A second pass with GPT-5.4 rechecks the generated privileged content; low-quality samples are discarded.
Final dataset statistics
- After filtering, the final LLM training set contains 32K high-quality examples.
- The final VLM training set contains 25K high-quality examples.
How the data is used
- The datasets are used to train non‑thinking student policies in an OPD (Output‑privileged Distillation) framework. The LLM data trains student models derived from teacher‑student pairs such as Qwen3‑8B → Qwen3‑1.7B, while the VLM data trains student models like Qwen3‑VL‑8B → Qwen3‑VL‑2B.
- Both sets are fed directly as training data; no explicit training/validation split or mixture ratios are provided beyond the combined sizes. The privileged information is used as additional input during training to guide the student, with the teacher’s rationales or visual annotations serving as privileged knowledge.
Method
The authors identify acritical issue in existing On-Policy Distillation (OPD) termed "privilege illusion," where incorporating privileged information creates an ostensible performance advantage driven by information asymmetry rather than genuine capability enhancement. When privileged inputs are granted to only the teacher or the student, early training shows modest gains, but the resulting information asymmetry leads to late-stage performance degradation and entropy collapse. Even when both policies access privileged information, uniform distillation fails to help the student internalize core competencies, causing it to merely adapt passively to the privileged cues.
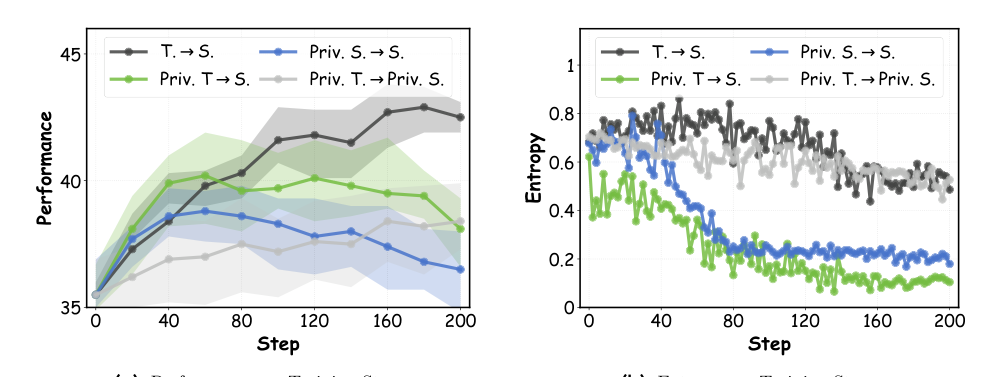
To disentangle capability gaps from information gaps, the authors introduce the privilege advantage gap. When both teacher policy ΠT and student policy ΠS have access to privileged inputs p, the relative advantage between them serves as a proxy for the privilege-conditioned prediction gap. For a given input x and current token yn, the privilege advantage gap A is defined as the absolute difference in their log-probabilities: A=∣logΠT(yn∣x,p,y<n)−logΠS(yn∣x,p,y<n)∣ This metric captures the prediction discrepancy stemming from the performance gap under identical privileged conditions. Empirical analysis shows that ablating tokens with a high advantage gap incurs substantial performance degradation, confirming that these tokens contain the most critical transferable knowledge.
Building on this, the authors propose Dual On-policy Distillation (DOPD). They first evaluate three divergence-based objectives: forward KL divergence, which promotes comprehensive imitation; reverse KL divergence, which encourages mode-seeking behavior; and Jensen-Shannon (JS) divergence, which provides a balanced optimization signal. The standard OPD objective minimizes the token-level divergence between the teacher and student policies over trajectories sampled from the student.
To address the privilege illusion, DOPD employs an advantage-aware dual distillation strategy that dynamically selects the supervision source and distillation form based on the token-level privilege advantage gap An, along with the token-level probabilities qS and qT. After discarding outliers and normalizing within a batch, tokens are partitioned into four regimes:
- Low Advantage, High Probability (qS & qT): Both policies make consistent, confident predictions. The bottleneck is the absence of privileged information rather than a capability gap. The authors apply a light teacher distillation objective using Top-K reverse KL to conservatively absorb useful knowledge.
- Low Advantage, Low Probability (qS & qT): Both policies assign low probability, indicating the token lies beyond their reliable competence region. To avoid noisy supervision, they use the privileged student as a weak self-regularizing anchor via Top-K reverse KL with a smaller coefficient, preventing policy drift.
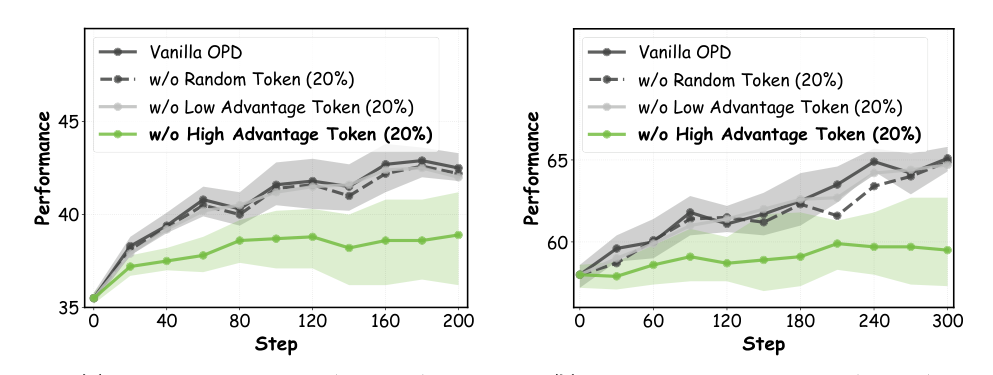
- High Advantage, High Teacher Probability (qT): The teacher exhibits a clear, confident advantage. These tokens contain critical transferable knowledge. The authors perform full-vocabulary teacher distillation using JS divergence to balance support coverage and mode concentration.
- High Advantage, High Student Probability (qS): The student is more confident than the teacher. Strongly constraining the student might suppress valid exploration. They adopt a light privileged-student distillation objective with Top-K reverse KL to softly encourage consistency without over-regularization.
The total DOPD objective combines these four token-wise losses through indicator masks, ensuring that strong full-vocabulary teacher supervision is applied only when the teacher demonstrates a credible capability advantage, thereby mitigating the entanglement between capability transfer and privileged-information imitation.
Experiment
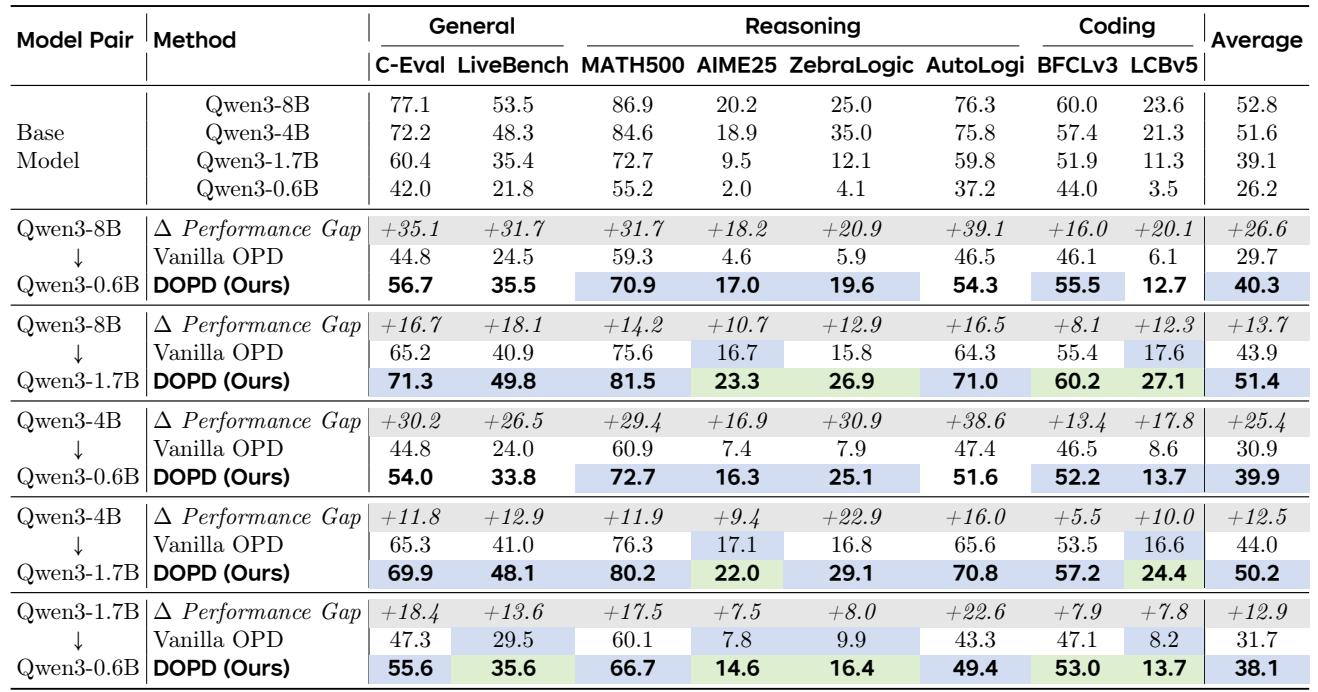
The experiments evaluate the proposed DOPD framework using Qwen3 (8B→1.7B) and Qwen3-VL (8B→2B) teacher-student pairs, with step-wise hints or structured visual annotations serving as privileged information. Across diverse LLM and VLM benchmarks, DOPD consistently outperforms standard, self-, and adaptive distillation baselines, recovering up to 89.8% of the teacher-student gap and occasionally surpassing the teacher on reasoning and coding tasks. The method shows strong generalization across model scales, stable training, and effective continual learning, while ablations reveal that capability-oriented hints and token-level adaptive distillation are critical to these gains.
The proposed DOPD method substantially closes the performance gap between the student and teacher policies, recovering nearly 90% of the original gap on average. It not only approaches but surpasses the teacher on four challenging benchmarks, especially in reasoning and coding tasks. DOPD consistently achieves the best results across all eight evaluated benchmarks, outperforming strong adaptive distillation baselines by significant margins. DOPD recovers 89.8% of the teacher-student performance gap on average. The method surpasses the teacher policy on four reasoning and coding benchmarks. DOPD outperforms the strongest adaptive distillation baselines (ExOPD, Uni-OPD, EOPD) by more than 4 points on average. Self-distillation baselines provide only modest improvements, highlighting the benefits of advantage-aware dual distillation.
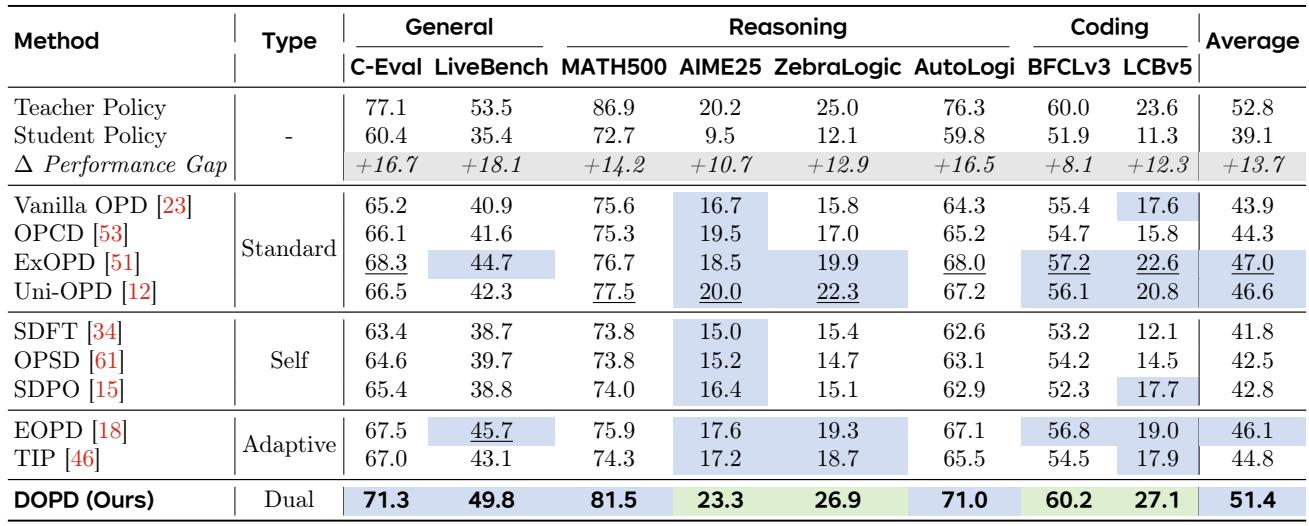
On VLM-based preference distillation, DOPD raises the student policy by 10.1 points, recovering 69.2% of the teacher-student gap. It achieves the highest average score, surpassing Vanilla OPD by 6.0 points and outperforming Uni-OPD, Vision-OPD, and VA-OPD by margins ranging from 2.1 to 4.2 points. Gains are especially large on visual understanding tasks, where the initial student-teacher gap is widest. DOPD delivers a 10.1-point absolute gain over the student policy, reaching 58.4 average score and closing 69.2% of the teacher-student gap. Compared to the strongest VLM-oriented distillation baselines, DOPD provides an average improvement of 2.1 to 6.0 points, with the largest advantage over Vanilla OPD.
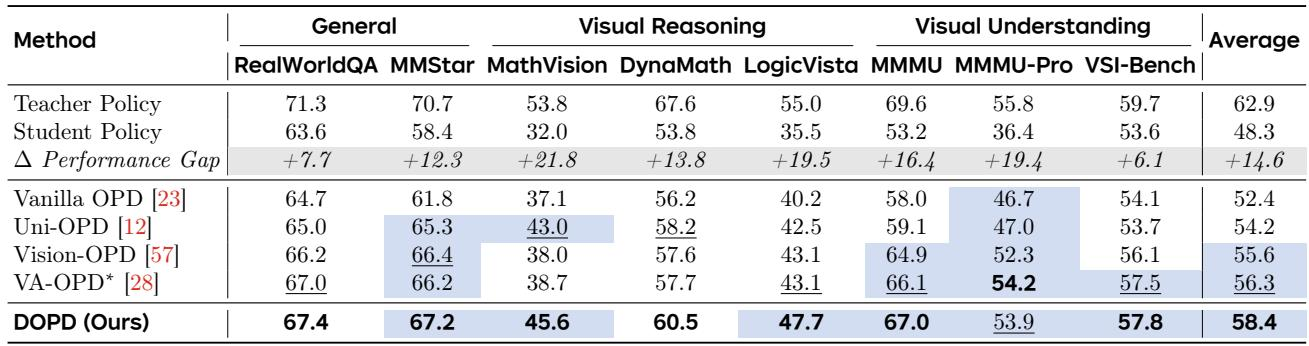
DOPD surpasses Vanilla OPD on every tested teacher-student pair, delivering up to over three times larger average gains and showing particular strength when size mismatches are large. While vanilla distillation struggles as the capacity gap widens, DOPD maintains or increases its improvements, recovering more than half of the teacher-student performance difference in the most extreme mismatch scenario. These results confirm the method's robustness and scalability across diverse model scales. DOPD yields average performance improvements 2–3× larger than Vanilla OPD across five teacher-student configurations. In the largest mismatch (Qwen3-8B → Qwen3-0.6B), DOPD achieves a 14.1-point gain and recovers 53.0% of the teacher-student gap, while Vanilla OPD gains only 3.5 points. Vanilla OPD's gains diminish as the teacher-to-student size ratio increases, whereas DOPD's gains grow or remain stable, indicating better handling of distribution inconsistency.
Using the final answer as privileged information causes the student model to overfit, performing worse than providing no privileged input. Providing step-wise hints without execution traces yields the highest accuracy, substantially surpassing all other privileged forms on both evaluation benchmarks. Final-answer distillation underperforms the no-privilege baseline, with the lowest scores on both C-Eval and LiveBench. Step-wise hints without execution achieve the best results, improving over no privileged input by more than 8 points on C-Eval and 10 points on LiveBench. Summarized hints offer a moderate gain, while step-wise hints that include execution traces are nearly on par with providing no privileged information.

When using VLM-based privileged information, directly supplying the final answer gives only a small improvement over no privileged input, while providing spatially grounded cues such as bounding boxes with object labels delivers substantially larger accuracy gains on both benchmarks. Among all strategies, the combination of a bounding box and an object label emerges as the most effective privileged input. Supplying the final answer as privileged information yields minimal gain over no privileged input, noticeably underperforming all visually grounded alternatives. Bounding box with object label as privileged input achieves the largest improvement, significantly surpassing caption-only and bounding box with caption approaches across both datasets.

The evaluation examines DOPD across text-only and vision-language preference distillation on eight benchmarks, comparing it to strong adaptive baselines and analyzing privileged information strategies. DOPD consistently recovers nearly the full teacher-student performance gap, surpassing the teacher on reasoning and coding tasks, and its gains grow with larger model size mismatches where vanilla distillation fails. Ablations reveal that step-wise reasoning hints without execution traces and spatially grounded visual cues like bounding boxes with object labels substantially outperform final-answer or execution-trace priors.