Command Palette
Search for a command to run...
MAI-Thinking-1: Building a Hill-Climbing Machine
MAI-Thinking-1: Building a Hill-Climbing Machine
Abstract
Progress in AI is driven not by a single model, but by the ability to continually improve upon the current state of models. Achieving this requires treating model development as a system-level optimization problem, for which the solution is building a hill-climbing machine for rapid improvement. Our process includes a scaling-focused framework for pre-training modeling decisions, as well as a robust reinforcement learning recipe and infrastructure that sustains long, log-linear performance improvement. The first model developed using our process is MAI-Thinking-1, a 35B active / 1T total parameter MoE that stands among the strongest models of similar size on STEM reasoning and coding tasks (e.g., 52.8% on SWE-Bench Pro, 97.0% on AIME 2025, and 87.7% on LiveCodeBench v6). MAI-Thinking-1 is trained from-scratch, exclusively on clean, enterprise-grade data, without distillation from third-party models. In this technical report, we offer a deep dive into the development of MAI-Thinking-1. By sharing our technical details and learnings we hope to cultivate a transparent and science-driven approach to further development in AI.
One-sentence Summary
MAI-Thinking-1 is a 35B active and 1T total parameter MoE model trained from scratch on clean enterprise-grade data without distillation from third-party models, utilizing a hill-climbing machine framework for system-level optimization that combines scaling-focused pre-training with robust reinforcement learning to sustain log-linear performance improvements on STEM and coding tasks, achieving 52.8% on SWE-Bench Pro, 97.0% on AIME 2025, and 87.7% on LiveCodeBench v6.
Key Contributions
- The paper introduces a hill-climbing machine framework that optimizes every component of the pipeline from data and infrastructure to reinforcement learning recipes and evaluation. This system treats model development as a system-level optimization problem to sustain log-linear performance improvements.
- MAI-Thinking-1 is the first model produced by this process, utilizing a 35B active / 1T total parameter MoE architecture trained from scratch on clean enterprise-grade data. Benchmarks indicate the model stands among the strongest in its weight class, achieving 52.8% on SWE-Bench Pro, 97.0% on AIME 2025, and 87.7% on LiveCodeBench v6.
- Internal safety benchmarks are developed to ground progress while helpfulness and safety training are incorporated into reinforcement learning climbs to balance compliance with user requests. Continuous red-teaming is employed throughout development to surface and remediate vulnerabilities before release.
Introduction
Advancing artificial intelligence requires system-level optimization rather than relying on isolated model breakthroughs. Prior approaches frequently depend on distillation from third-party models, which limits steerability and prevents sustained log-linear performance improvements. The authors leverage a hill-climbing machine framework to transform model development into an empirical optimization loop focused on data, infrastructure, and reinforcement learning. They introduce MAI-Thinking-1, a 35B active parameter mixture-of-experts model trained from scratch on clean enterprise-grade data. This approach avoids distillation shortcuts and achieves competitive performance on complex STEM reasoning and software engineering tasks.
Dataset
-
Dataset Composition and Sources
- The authors compile a high-quality, diverse set of pre-training data from publicly available and licensed human-generated sources.
- Major sources include web HTML, web PDFs, books, journals, and public GitHub code.
- The team explicitly avoids using language-model-generated synthetic data for pre-training and removes AI-generated content from collected sources.
- Data collection respects robots.txt protocols and excludes sources violating safety policies or appearing on the USTR Notorious Markets list.
- Common machine learning repositories like huggingface.co are excluded from web data to prevent contamination.
-
Key Details for Each Subset
- Web HTML: A proprietary crawl processes approximately 1.2 trillion pages, reduced to 794 billion after policy filtering and 423 billion after exact deduplication. The final corpus contains 73.4 billion English and 116.5 billion non-English documents. Common Crawl data adds another 24.2 billion pages.
- Web PDFs: The team collects roughly 10 billion documents, filtering down to 620 million for processing. This yields 1.8 trillion English tokens and 1.85 trillion multilingual tokens.
- Books and Journals: Acquired through commercial agreements, these are processed for OCR artifacts and deduplicated before annotation for topic and quality.
- GitHub Code: The corpus totals 7.4 trillion tokens organized into files (1.26T), commits (4.5T), and pull requests (1.19T).
- RL and SFT Data: The STEM Mix dataset contains over 5 million samples, while competitive coding includes 160,000 problems. Software Engineering environments are built from 102 million public pull requests, resulting in 265,617 verified environments.
-
Training Usage and Mixture Ratios
- Pre-training: The final mixture targets a 30 trillion token run. Coding data comprises the bulk at 16.4 trillion tokens with just over 2 epochs on average.
- Math and STEM: Approximately 300 billion math tokens are sampled 5.28 times on average, the highest repetition rate of any source family.
- Web and PDF: These sources are seen less than once on average (0.55x and 0.53x respectively), meaning the full corpus is not exhausted.
- Multilingual: This corpus is aggressively downsampled, with 8.1 trillion unique tokens available but only 0.5 trillion consumed (0.06x).
- Mid-training: The mixture is biased towards STEM, math, and code to build reasoning foundations, assigning 35% to STEM/math, 55% to code, and 10% to background sources.
-
Processing and Metadata Construction
- Extraction: The authors use source-specific structured parsers for HTML/XML, hand-crafted extractors for consistent domains, and LLM-based processing for targeted extraction without adding synthetic content. Wikipedia data is trained on raw markup to preserve infoboxes.
- Deduplication: A multi-stage pipeline removes exact duplicates via hashing, applies MinHash LSH fuzzy deduplication with an 80% similarity threshold, and uses semantic deduplication via embeddings. Cross-dataset deduplication retains instances only in the highest-ranked dataset.
- Filtering: Data undergoes policy compliance checks, AI-content detection, and quality binning using attribute models for educational value and reasoning content.
- Decontamination: Public evaluation benchmarks are removed using a universal 20-gram fuzzy deduplication with an 80% similarity threshold.
- Packaging: Examples are greedily packed into fixed-length sequences. For pull requests, prefix compression is applied to fit within a token budget, and sequences exceeding 256K tokens are discarded.
- Safety and PII: The entire corpus is processed using PII-risk and safety filtering before training.
Method
Model Architecture and Design
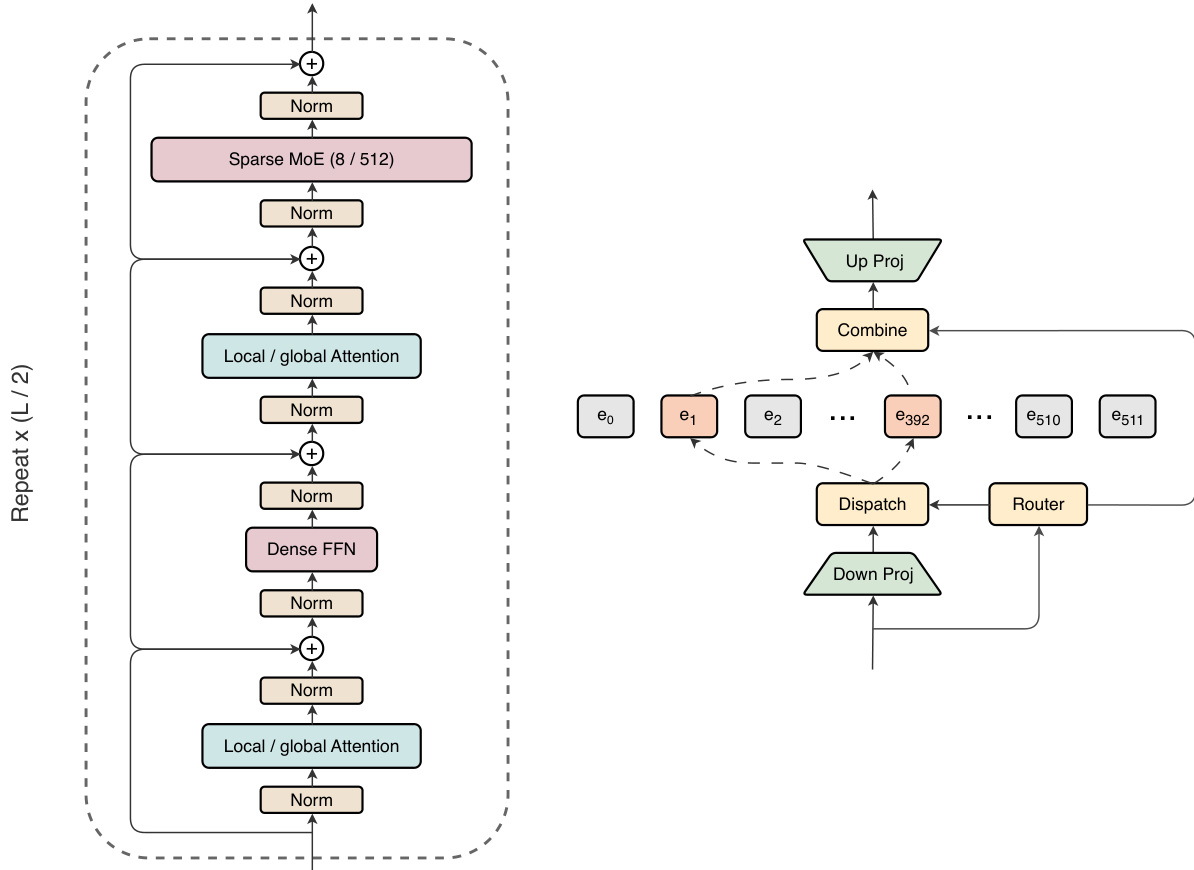
The base model for MAI-Thinking-1, known as MAI-Base-1, is a 35B-active and 1T-total sparse Mixture of Experts (MoE) model. The architecture is designed to leverage scale efficiently on the underlying GPU infrastructure. It employs a decoder-only Transformer structure with periodic local and global attention layers and alternating dense and MoE feed-forward blocks. In each layer, RMSNorm is applied at both the input and output immediately before the residual addition.
The model utilizes a periodic attention design that pairs five local attention layers with one global attention layer. This significantly reduces the computational cost of attention during training and the KV cache size during inference. For the feed-forward layer, the architecture alternates between MoE layers and dense feed-forward networks (FFN). This paradigm of pairing a high-sparsity layer with a zero-sparsity layer scales comparably to balanced sparsity allocation while being more efficient in wall-clock time. The MoE layer adopts the LatentMoE design, where a shared down-projection is applied before the all-to-all dispatch. Routing decisions are based on the original representation, and each compressed representation is routed to 8 out of the 512 experts with softmax gating.
Refer to the framework diagram for the overall layout of the Transformer body, which interleaves high-sparsity MoE layers with small dense FFNs, and global attention with local attention. The diagram also details the MoE layer, showing how 8 of 512 experts are activated per token in a compressed latent space.
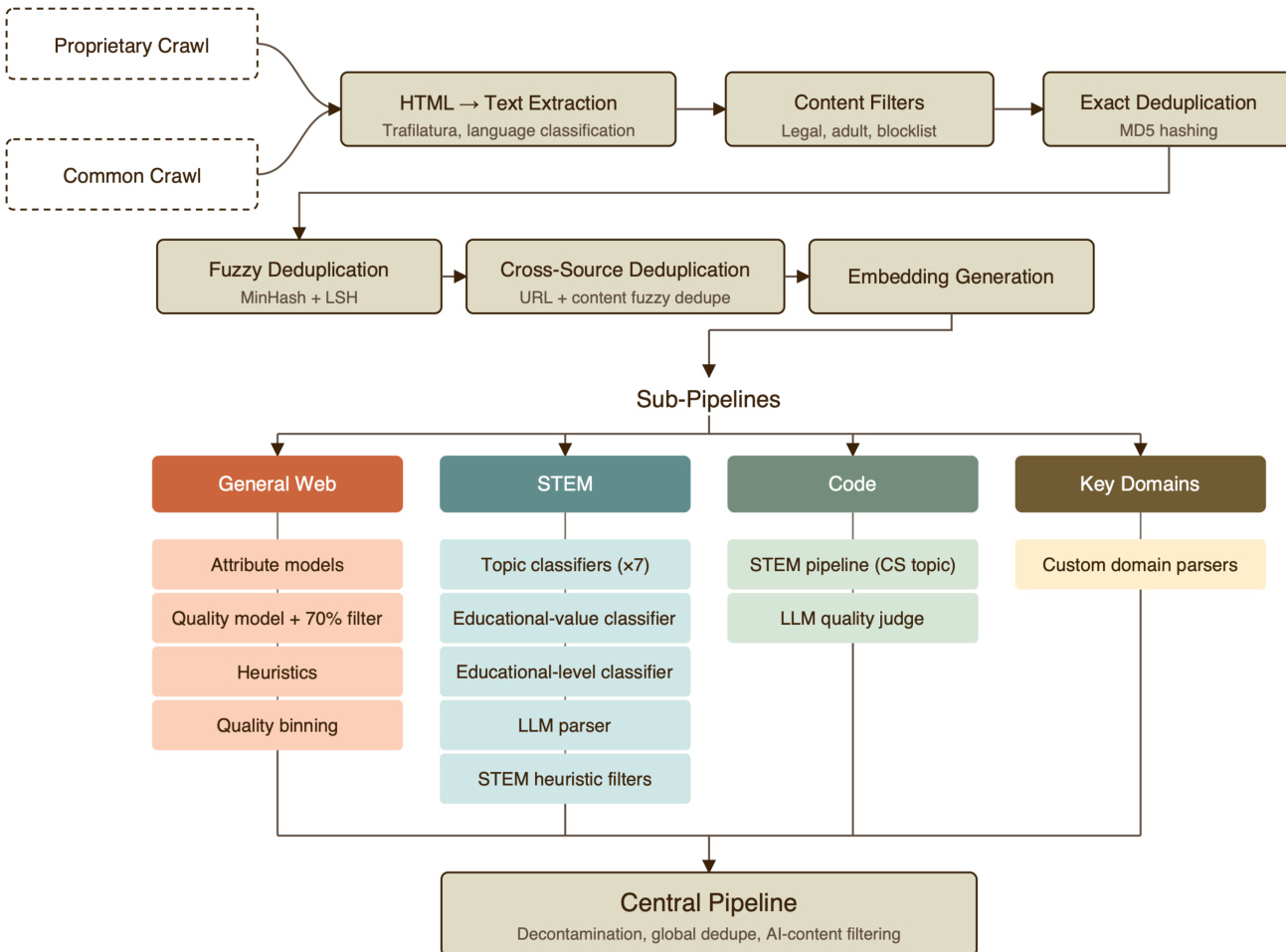
Data Preparation and Corpus Construction
The training corpus was built entirely in-house from both publicly available and acquired data sources, ensuring the model learns from human knowledge rather than imitations of existing AI models. The pipeline begins with data from Proprietary Crawl and Common Crawl sources, which undergo HTML to text extraction and language classification. Content filters are applied to remove legal, adult, and blocklisted material, followed by exact deduplication using MD5 hashing.
Further processing involves fuzzy deduplication using MinHash and LSH, as well as cross-source deduplication. The data is then split into sub-pipelines for General Web, STEM, Code, and Key Domains. Each sub-pipeline employs specific attribute models, quality classifiers, and heuristic filters to ensure high-quality training data. Finally, a central pipeline handles decontamination, global deduplication, and AI-content filtering.
Refer to the data processing workflow for the complete pipeline from raw crawl to the central pipeline, illustrating the various filtering and domain-specific processing stages.
Reinforcement Learning Climb
Pre-training and mid-training provide the base model with broad predictive competence, but the reinforcement learning (RL) climb optimizes the model for specific behaviors such as reasoning chains, tool use, and safety. The process begins with a mid-trained model and trains three domain-specific specialist models: one for STEM and competitive coding, one for agentic coding and tool use, and one for helpfulness and safety. These specialist models are subsequently consolidated into a single model using supervised finetuning (SFT). A final lightweight RL stage turns this consolidated model into MAI-Thinking-1.
The RL objective is derived from Group Relative Policy Optimization (GRPO) with token-level policy gradient. For a prompt q, the rollout policy samples a group of G responses, and each response receives a scalar reward. The training objective maximizes the expected reward while applying adaptive entropy control to maintain policy stability.
Refer to the RL climb overview for the progression from the mid-trained model to the specialist teachers and finally to the consolidated MAI-Thinking-1 model.

Agentic Training Framework
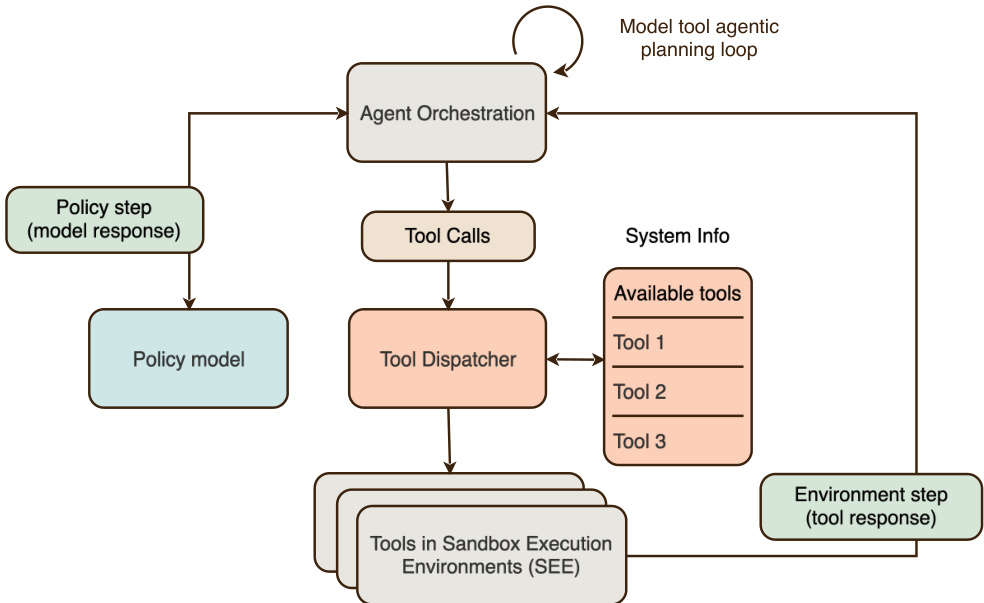
For the agentic climb, the model is trained to solve tasks requiring interaction with an external environment. This involves decomposing user requests, choosing tools or code actions, observing results, and adapting plans across multiple steps. The training signal combines verifiable rewards with AI-feedback rewards for aspects like task interpretation and trajectory quality.
The agentic multi-step RL uses the same core objective as single-step reasoning but extends rollouts to a trajectory of policy steps and environment steps. The orchestration harness follows a ReAct-style loop that parses the model's reasoning, dispatches tool calls to the Sandbox Execution Environment (SEE), and appends returned observations to the context. The loop terminates when the model emits no tool calls or exceeds budget limits.
Refer to the agentic loop diagram for the interaction between Agent Orchestration, Tool Dispatcher, and the Sandbox Execution Environments, highlighting the model tool agentic planning loop.
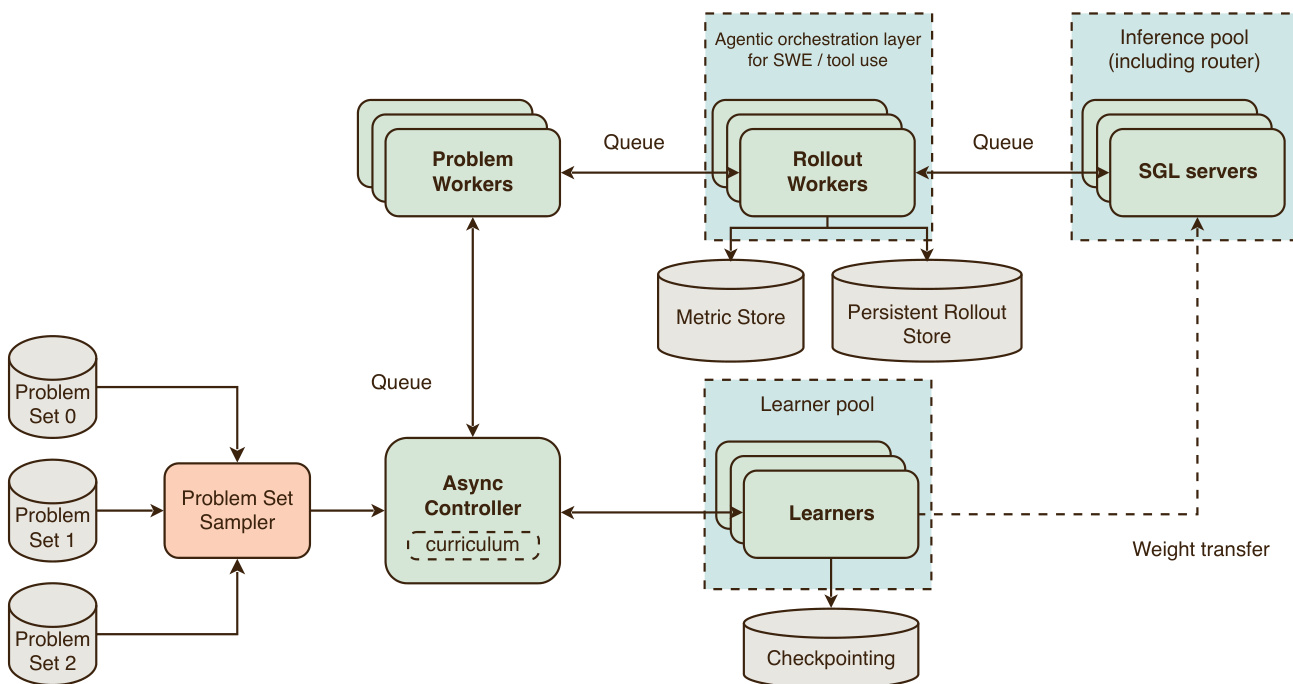
RL Infrastructure and System Design
The reinforcement learning climb relies on Rocket, an in-house framework for large-scale asynchronous distributed reinforcement learning. Rocket uses the YOLO framework for the learner and SGLang for model inference. The system is organized around a single controller, a pool of problem and rollout workers, and the router and inference servers that produce model generations.
The controller loads RL tasks and sends them to problem workers, which generate rollouts and compute normalized advantages. Rollout workers handle the actual generation of model responses and tool interactions. Inference performance is critical, and the system employs optimizations like prefix caching for multi-turn workloads and expert parallelism for long generations. The framework ensures stability through defense-in-depth measures at the replica, router, and job levels.
Refer to the Rocket architecture diagram for the system components and data flow, showing the Controller, Problem Worker, Rollout Worker, and Inference Server interactions.
Experiment
The experimental setup employs scaling ladders and efficiency gain metrics to validate architectural and data design choices across varying model sizes. Key findings indicate that data mixture performance rankings are not always invariant to scale, while qualitative analysis of reasoning traces shows that stronger models adopt rigorous verification strategies compared to the guessing behaviors of weaker variants. Ultimately, the final model achieves competitive benchmark performance and human preference scores against contemporaries, supported by robust safety mitigations derived from extensive red teaming and iterative training stability improvements.
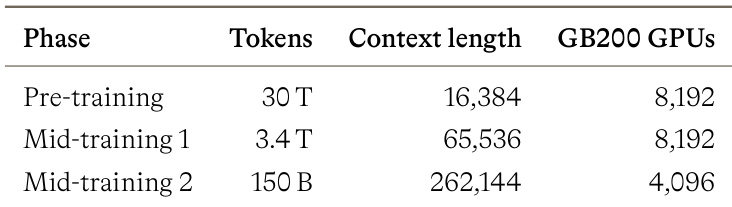
The authors employ a staged training strategy that transitions from a high-volume pre-training phase to specialized mid-training phases focused on long-context capabilities. The initial phase consumes the majority of the token budget and GPU resources to build foundational knowledge at a standard sequence length. Later phases prioritize extending the context window significantly while operating with a reduced token count and fewer computational resources in the final stage. The pre-training phase utilizes the largest token budget and GPU cluster size compared to later stages. Context length increases substantially from the initial phase through to the final mid-training stage. The final training phase operates with a significantly smaller GPU count while targeting the longest context window.
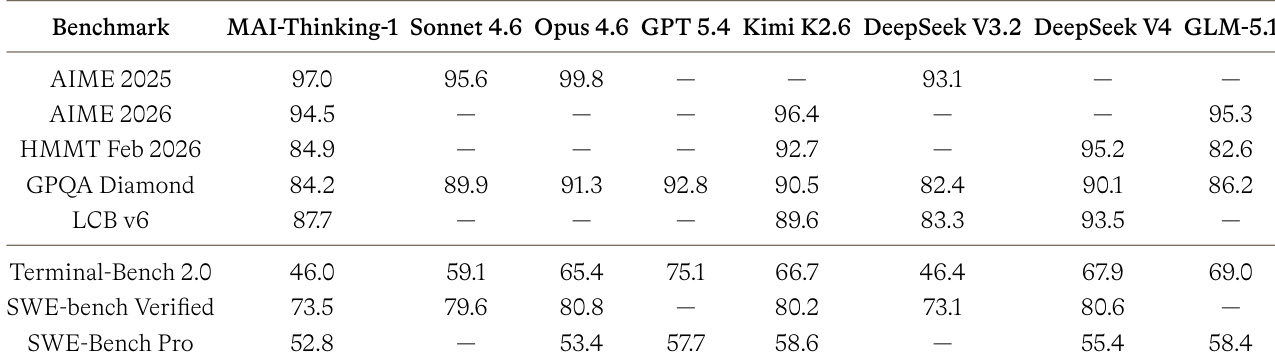
The authors evaluate MAI-Thinking-1 against various frontier models across STEM and agentic coding benchmarks to assess its competitive standing. The results indicate that while the model delivers consistently strong performance across diverse categories, it generally trails behind top-tier contemporaries in most areas without leading the field. MAI-Thinking-1 outperforms Sonnet 4.6 on the AIME 2025 mathematics competition benchmark. The model demonstrates performance on SWE-Bench Pro that is comparable to Opus 4.6. Agentic coding benchmarks such as Terminal-Bench 2.0 show lower performance relative to leading models like Opus 4.6 and GPT 5.4.
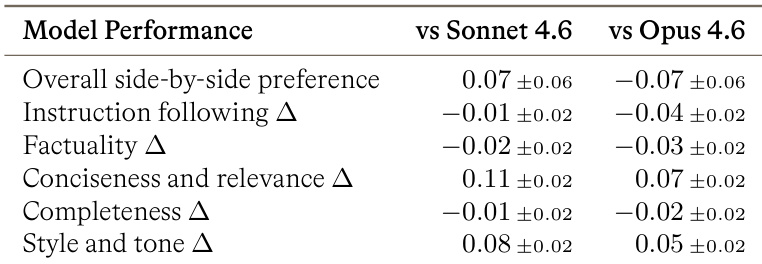
The authors conducted human side-by-side evaluations comparing their model against Sonnet 4.6 and Opus 4.6 across multiple quality dimensions. Results indicate a slight overall preference for their model over Sonnet 4.6, whereas Opus 4.6 received a slight preference over their model. The model demonstrated superior performance in conciseness, relevance, style, and tone compared to both competitors, while showing slight deficits in instruction following, factuality, and completeness. Overall preference is slightly positive against Sonnet 4.6 but negative against Opus 4.6. Conciseness, relevance, style, and tone scores are higher than both competitor models. Instruction following, factuality, and completeness metrics show lower or comparable performance relative to the competitors.
The the the table illustrates a data mixture configuration where STEM and Coding content is heavily weighted for training. General Helpfulness and Safety data comprises a substantial share of the samples but contributes very little to the overall token budget, indicating shorter data sequences relative to STEM content. STEM and Coding data dominates the token volume, receiving the highest allocation. General Helpfulness and Safety samples are common but account for a minimal fraction of total tokens. Agentic Capability data represents a small fraction of the training mixture across both metrics.

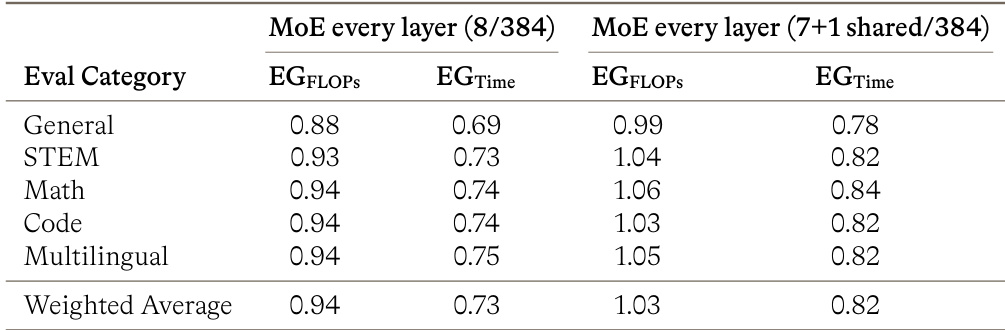
The authors evaluate two MoE-every-layer architectural variants against an interleaved baseline layout to assess efficiency gains across different evaluation categories. While the variant incorporating shared experts shows a slight improvement in FLOPs efficiency, both MoE-every-layer configurations demonstrate lower efficiency in training time compared to the baseline. This indicates that the interleaved layout offers a better overall tradeoff when considering hardware utilization and wall-clock costs. The MoE-every-layer variant with shared experts generally achieves FLOPs efficiency gains above the baseline, unlike the standard variant which remains below or near baseline levels. Both MoE-every-layer configurations demonstrate significantly lower training time efficiency compared to the interleaved baseline layout. The interleaved layout is identified as the preferred architecture due to its superior wall-clock efficiency despite FLOPs trade-offs.
The authors employ a staged training strategy transitioning from high-volume pre-training to specialized long-context phases, utilizing a data mixture heavily dominated by STEM and coding tokens. Comparative benchmarks and human evaluations demonstrate strong performance in style and reasoning but indicate the model generally trails top-tier competitors in instruction following and factuality. Architectural ablation studies further validate that an interleaved layout offers superior wall-clock efficiency compared to MoE-every-layer variants.