Command Palette
Search for a command to run...
短窗口注意力实现长期记忆化
短窗口注意力实现长期记忆化
Loïc Cabannes Maximilian Beck Gergely Szilvasy Matthijs Douze Maria Lomeli Jade Copet Pierre-Emmanuel Mazaré Gabriel Synnaeve Hervé Jégou
摘要
近期研究表明,将滑动窗口softmax注意力层与线性循环神经网络(RNN)层相结合的混合架构,在性能上优于单独使用任一架构。然而,窗口长度的影响以及softmax注意力机制与线性RNN层之间的相互作用仍缺乏深入研究。在本工作中,我们提出了SWAX,一种由滑动窗口注意力机制与xLSTM线性RNN层构成的混合架构。一个反直觉的发现是:更大的滑动窗口并未提升模型在长上下文任务中的表现。事实上,较短的窗口注意力机制促使模型更有效地训练xLSTM的长期记忆能力,因为它减少了对softmax注意力机制在长距离上下文检索中的依赖。然而,过小的滑动窗口会对短上下文任务产生不利影响,而适度增大窗口尺寸本可提供有益的信息。为此,我们采用随机变化滑动窗口大小的方式训练SWAX,迫使模型同时利用更长的上下文窗口和xLSTM的记忆能力。实验结果表明,采用随机窗口大小训练的SWAX在短上下文和长上下文任务上均显著优于传统的固定窗口注意力机制。
一句话总结
来自 Meta FAIR、ENS 巴黎萨克雷大学和约翰内斯·开普勒大学的研究人员提出了 SWAX,一种结合滑动窗口注意力与 xLSTM 层的混合架构,揭示了较短窗口反而通过迫使模型依赖 xLSTM 的记忆机制而提升长上下文召回能力,并提出随机窗口训练策略以平衡短上下文与长上下文性能。
主要贡献
- SWAX 引入了一种混合架构,结合滑动窗口 softmax 注意力与 xLSTM 线性 RNN 层,揭示较短的注意力窗口意外地通过迫使模型更依赖 xLSTM 的持久记忆而提升长上下文检索能力。
- 与直觉相反,在混合模型中增大滑动窗口尺寸会降低长上下文性能,因为它削弱了 RNN 发展稳健长期记忆的压力,尽管有助于短上下文任务。
- 使用随机变化窗口尺寸(如 128/2048)训练 SWAX 可弥合短上下文与长上下文性能差距,在 RULER Needle-In-A-Haystack 和困惑度等基准测试中显著优于固定窗口基线。
引言
作者利用结合滑动窗口注意力与线性 RNN(特别是 xLSTM)的混合架构,解决大语言模型中内存效率与长上下文召回之间的权衡。虽然 softmax 注意力在长序列上提供强召回能力,但其无界的内存与计算成本使其在极长输入下不切实际;线性 RNN 每 token 成本恒定,但召回能力较弱。先前混合设计假设更长滑动窗口可提升性能,但作者证明相反:短窗口通过迫使模型更依赖 RNN 记忆,反而提升长上下文保留能力。其核心贡献是 SWAX——一种采用随机变化窗口尺寸训练的模型,通过动态平衡注意力与循环记忆使用,在短上下文与长上下文任务中同时提升性能。
数据集

- 作者使用两个代码生成基准:HumanEval+(HumanEval 的扩展)和 MBPP,二者均用于评估 AI 模型的功能正确性与 Python 任务表现。
- 对于常识与通用推理,他们在八个基准上进行评估:HellaSWAG、ARC、PIQA、SIQA、Winogrande、NaturalQuestions、RACE 和 TQA —— 全部采用问答或选择题形式,以测试自然语言理解与推理能力。
- 这些基准不用于训练,仅作为训练后评估模型性能的工具。
- 本节未提供数据集构成、过滤或预处理细节;重点严格限定于下游评估。
- 未提及裁剪、元数据构建或混合比例 —— 数据以标准基准形式用于训练后评估。
方法
作者采用结合滑动窗口注意力(SWA)与线性循环神经网络(RNN)组件的混合架构,以解决基于 Transformer 的系统在长上下文建模中的计算与内存挑战。该框架在滑动窗口注意力层与通过 xLSTM 实现的线性注意力层之间交替。选择 xLSTM 组件因其在语言任务中的表现及高效的 Triton 内核支持,矩阵记忆单元(mLSTM)因实证效果优于标量变体(sLSTM)而被优先采用。该设计实现了局部保真度与长程记忆保留之间的平衡:SWA 层在固定窗口内提供高保真局部推理,而线性注意力层则维持压缩的、无界记忆状态以支持长上下文召回。
如下图所示,混合架构以 1:1 比例交错 SWA 与 xLSTM 层,形成交替组件序列。这种层间混合使模型既能受益于滑动窗口注意力的效率,又能利用线性注意力的无界记忆容量。滑动窗口尺寸在实验中变化,评估配置包括 128、256、512、1024 和 2048 个 token,以评估窗口长度对性能的影响。此外,引入随机训练程序,每个训练批次的窗口尺寸从 128 或 2048 中等概率随机采样。该策略旨在减少训练期间对 SWA 层的过度依赖,从而通过鼓励线性注意力层在推理中更有效贡献,增强模型对更长序列的外推能力。
实验
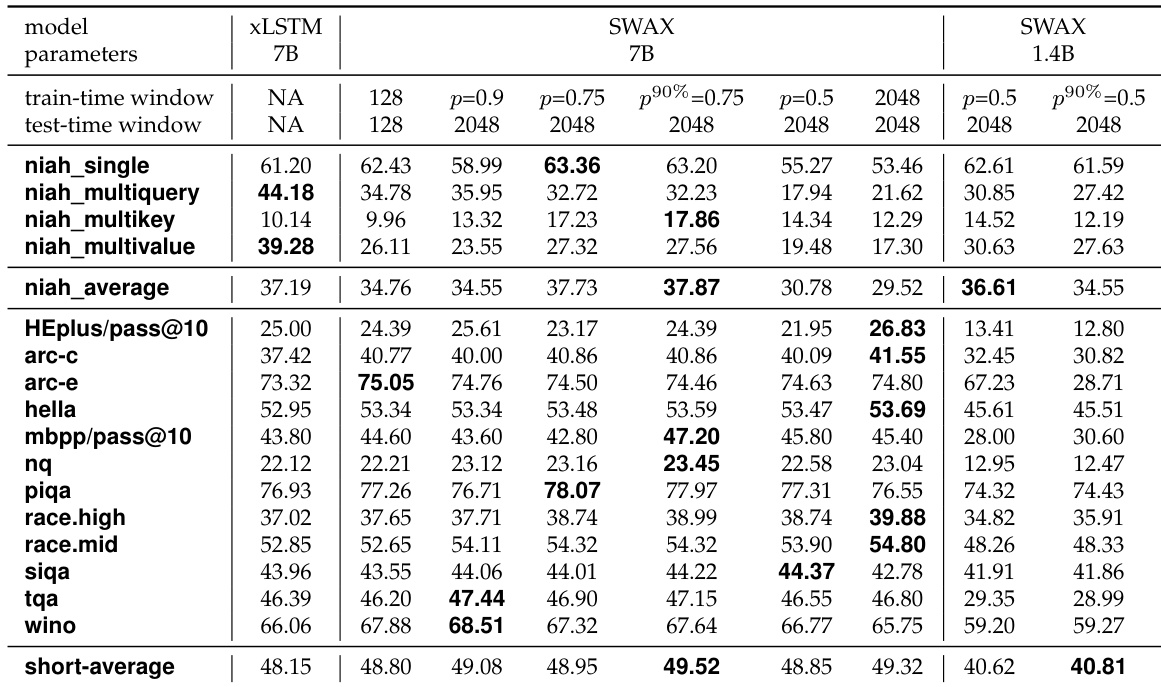
- 在 RULER NIAH 和短上下文基准上评估混合 SWA-LA 模型(1.4B 和 7B),确认混合模型在长上下文召回中优于纯架构,尽管全局层数更少,原因是 SWA 处理局部依赖,而 LA 专精长程依赖。
- 发现较短 SWA 窗口尺寸(128–512)显著提升长上下文召回(例如,在 131k token 时准确率约 30%,而 2048 窗口模型接近 0%),因为它们迫使 LA 层在训练中学习长程依赖。
- 随机训练(交替 128/2048 窗口,最后 10% 逐步退火)实现两全其美:在短上下文任务上匹配或超越 2048 窗口模型,同时保持强长上下文性能(例如,在 1.4B 上平均 NIAH 准确率比 2048 窗口模型高 16 分)。
- 在 7B 规模及使用 Gated DeltaNet 时验证随机训练的泛化性;同时在 LongBench、Babilong 和 LongBench2 基准上显示性能提升。
- 纯 SWA 模型(2048 窗口)表现与 SWAX-2048 相似,证实 SWAX-2048 的长上下文召回差源于对 SWA 层的过度依赖,而非 LA。
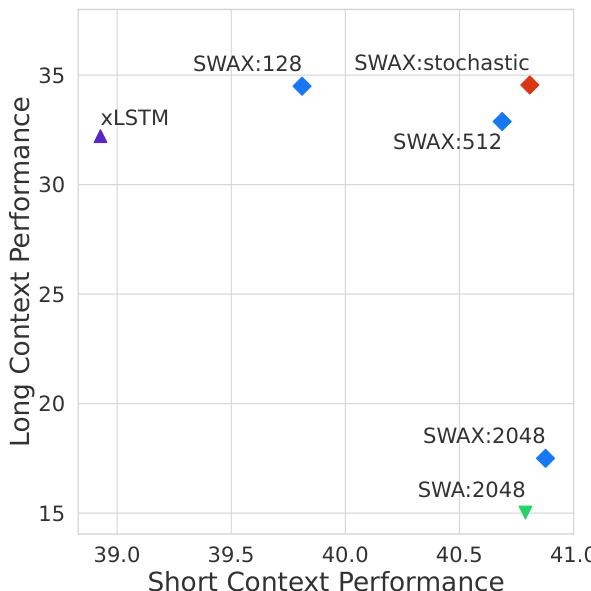
作者评估不同训练窗口尺寸的 SWAX 模型在长上下文基准上的表现,发现采用小窗口(128)的随机训练在多数情况下优于固定大窗口训练(2048)。具体而言,随机方法在 LongBench 和 Babilong 任务上平均准确率高于固定 128 和 2048 窗口模型,表明随机窗口训练提升了短上下文与长上下文性能。
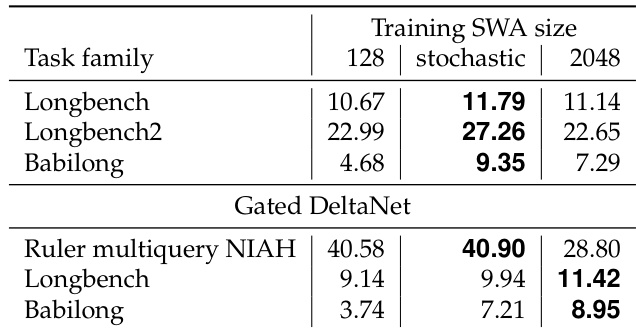
结果显示,SWAX:2048 模型在短上下文任务上准确率高,但在长上下文召回上表现差,在超过 65k token 的序列长度上准确率接近零。相比之下,SWAX:128 模型在长上下文性能上显著更好,在 RULER NIAH 任务上平均比 SWAX:2048 高 16 个准确率点,表明较短窗口尺寸提升了对更长序列的外推能力。
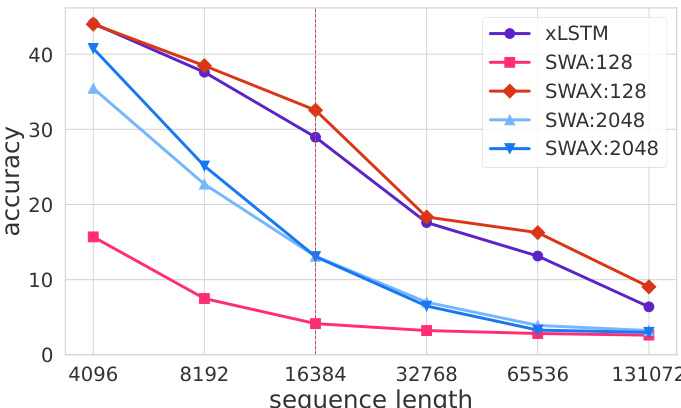
作者使用结合 softmax 滑动窗口注意力(SWA)与线性注意力(xLSTM)的混合架构,研究窗口尺寸对长上下文召回的影响。结果表明,使用固定长窗口(2048 token)训练的模型在长上下文任务上表现差,而使用较短窗口或随机窗口训练的模型召回显著更好,表明训练中对局部注意力的过度依赖阻碍了长上下文泛化。
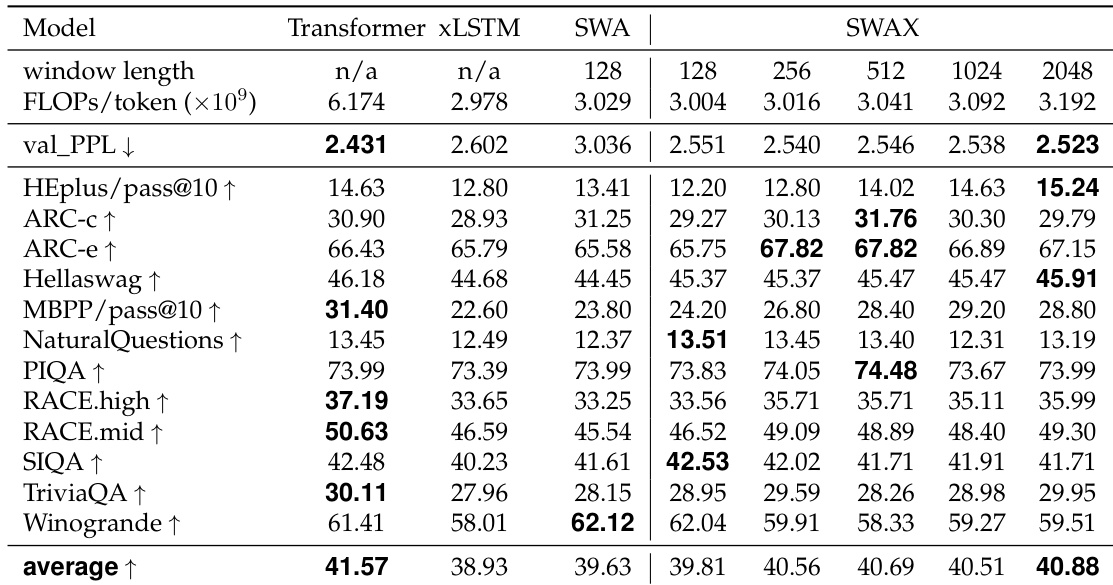
结果表明,随机窗口尺寸训练在保持强长上下文召回的同时提升了短上下文性能。在 1.4B 和 7B 参数规模上,采用随机窗口尺寸训练的模型在短上下文任务上的平均性能高于固定窗口模型,其中 7B 模型优于固定 2048 窗口变体。长上下文性能保持竞争力,随机训练结果与或优于固定短窗口模型。

作者在训练中使用随机窗口尺寸以平衡短上下文推理与长上下文召回性能。结果表明,采用随机窗口尺寸训练的模型在短上下文性能上与固定长窗口训练模型相当或更优,同时保持或提升长上下文召回,在 RULER NIAH 等任务上优于固定长窗口训练模型。