Command Palette
Search for a command to run...
在野外学习潜在动作世界模型
在野外学习潜在动作世界模型
Quentin Garrido Tushar Nagarajan Basile Terver Nicolas Ballas Yann LeCun Michael Rabbat
摘要
能够在真实世界中进行推理与规划的智能体,需要具备预测自身行为后果的能力。尽管世界模型具备这种能力,但它们通常依赖于带有动作标签的数据,而这类标签在大规模数据上获取往往十分困难。这一挑战促使研究者探索从视频中仅学习潜在动作空间的隐式动作模型。本文致力于在真实场景视频(in-the-wild videos)上构建潜在动作世界模型,拓展了以往主要聚焦于简单机器人仿真、视频游戏或操作数据的研究范畴。尽管这一设定使我们能够捕捉更丰富的动作模式,但也带来了由视频多样性引发的新挑战,例如环境噪声干扰,以及不同视频之间缺乏统一的具身性(common embodiment)。为应对部分挑战,本文探讨了动作应具备的若干性质,分析了相关网络架构设计的选择及其评估方法。我们发现,连续但受约束的潜在动作空间能够有效捕捉真实场景视频中动作的复杂性,而传统的向量量化(vector quantization)方法则难以胜任这一任务。例如,我们观察到由智能体(如人类进入房间)引起的环境变化,能够在不同视频之间实现跨视频迁移,这凸显了所学动作对真实场景视频特性的适应能力。在缺乏统一具身性的前提下,我们主要学习到的潜在动作呈现出相对于摄像头的空间局部化特性。尽管如此,我们仍成功训练了一个控制器,能够将已知动作映射为潜在动作,从而将潜在动作作为通用接口,使我们的世界模型在规划任务上的表现与基于动作条件的基线方法相当。本研究的分析与实验为将潜在动作模型扩展至真实世界奠定了重要基础,推动了该方向向现实应用的迈进。
一句话总结
Meta FAIR、Inria 和 NYU 的作者提出了一种仅在真实世界视频上训练的潜在动作世界模型,证明了连续且受约束的潜在动作——而非离散的向量量化——能有效捕捉复杂且可迁移的动作,适用于多样化的现实场景。通过在无共同具身的情况下学习相对于相机、空间局部化的动作,该模型实现了通用动作接口,即使在未标注数据上训练,其规划性能仍可媲美带动作标签的基线模型。
主要贡献
- 本工作解决了从真实世界视频中学习潜在动作世界模型的挑战,其中动作标签缺失,视频内容在具身、环境和代理行为方面具有高度多样性,远超机器人仿真或视频游戏等受控场景。
- 作者证明,连续且受约束的潜在动作——而非通过向量量化实现的离散表示——更能捕捉真实世界视频中丰富、多样且可迁移的动作,包括由外部代理(如人类进入场景)引起的变化。
- 在大规模真实世界数据集上的实验表明,学习到的潜在动作可相对于相机进行空间定位,并可用于训练控制器,将已知动作映射到潜在动作,从而实现与动作条件基线相当的规划性能。
引言
作者致力于解决使智能体在真实环境中推理与规划的问题,通过学习能够预测动作后果的世界模型。尽管传统世界模型依赖于标注的动作数据——这类数据在大规模下往往不可用——潜在动作模型(LAMs)旨在直接从无标签视频中推断动作表示。以往工作主要集中在视频游戏或机器人操作等受控场景,其中动作定义明确且具身一致,限制了泛化能力。相比之下,本工作针对更复杂、更丰富的现实世界视频领域,涵盖多样化的代理、不可预测的事件,且无共享具身。关键贡献在于证明:连续且受约束的潜在动作——而非离散量化——能有效从此类视频中捕捉丰富且可迁移的动作语义,包括由外部代理(如人进入场景)引起的变化。尽管缺乏共同具身,学习到的潜在动作仍相对于相机实现空间局部化,作者进一步证明,通过训练控制器将已知动作映射到潜在动作,这些动作可作为通用规划接口,实现与动作条件基线相当的性能。这推动了将世界模型扩展至真实、非结构化视频数据的可行性。
方法
作者采用潜在动作世界模型框架,通过建模世界状态在历史观测和潜在动作变量共同条件下的演化,来预测未来视频帧。核心架构如框架图所示,包括一个帧因果编码器 fθ,将视频帧转化为表示 st;一个世界模型 pψ,根据历史序列 s0:t 和潜在动作 zt 预测下一帧 st+1;以及一个逆动力学模型 gϕ,从一对连续帧 st 和 st+1 中推断潜在动作 zt。世界模型 pψ 通过最小化预测误差 L=∥st+1−pψ(s0:t,zt)∥1 进行训练,其中 zt 由逆动力学模型获得。这种联合训练过程使模型能够学习一个捕捉未来预测关键信息的潜在动作空间。
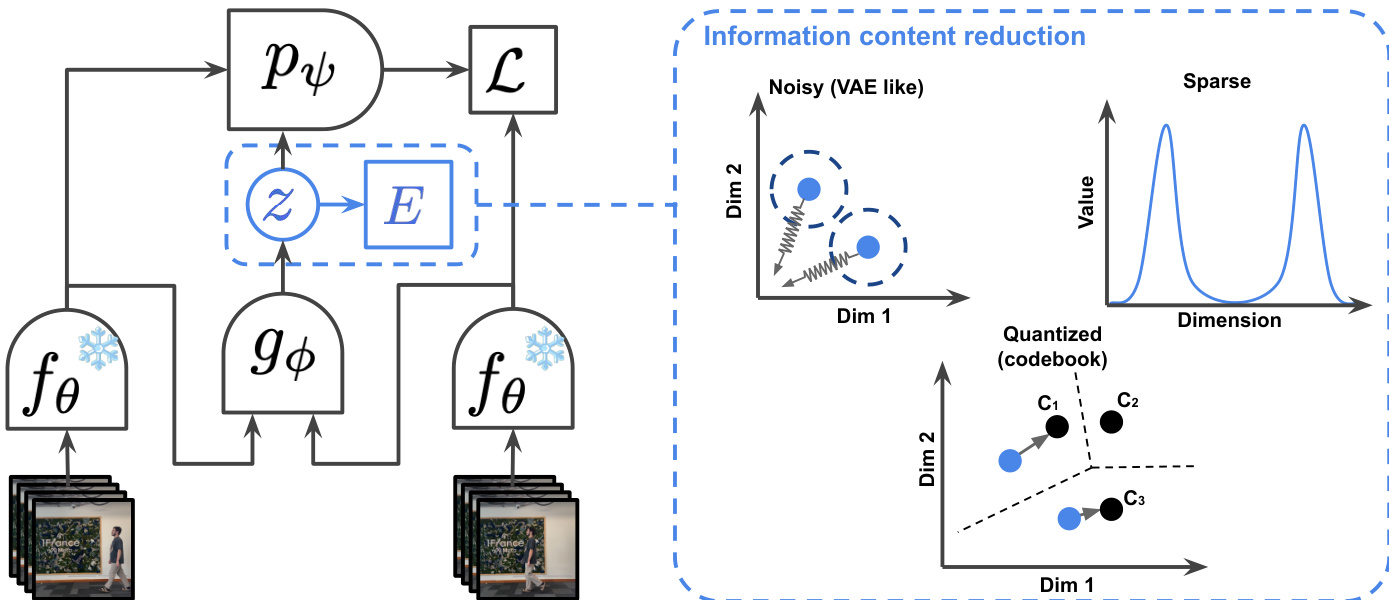
为确保潜在动作 zt 仅包含预测所需的信息,避免编码冗余噪声或整个未来状态,作者采用三种不同的信息内容压缩机制。第一种是稀疏性,通过约束潜在动作具有低 L1 范数实现。这通过一个结合方差-协方差-均值(VCM)正则化与能量函数 E(z) 的正则化项 L(Z) 实现,以促进稀疏性并防止平凡解。第二种机制是噪声添加,使潜在动作遵循先验分布(如 N(0,1)),类似于变分自编码器(VAE)。这通过 KL 散度项实现,鼓励潜在动作分布与先验一致。第三种方法是离散化,使用向量量化将连续潜在动作映射到有限的离散码本条目,有效限制潜在空间的信息容量。框架图展示了这三种正则化策略在“信息内容压缩”模块中的体现。
世界模型 pψ 实现为带有 RoPE 位置嵌入的 Vision Transformer(ViT-L),并通过 AdaLN-zero 对潜在动作 zt 进行条件化,实现逐帧适配。潜在动作 zt 默认为 128 维连续向量。模型采用教师强制(teacher forcing)进行训练,即在训练过程中使用真实下一帧作为下一次预测的输入。训练过程同时优化预测损失 L 和所选潜在动作正则化项。作者还训练了一个帧因果视频解码器,用于生成模型预测的可视化结果,用于定性评估和感知指标计算。
学习到的潜在动作空间可作为可解释的规划接口。作者训练了一个轻量级控制器模块,可为 MLP 或基于交叉注意力的适配器,将现实世界动作(及可选的历史表示)映射到学习到的潜在动作。该控制器通过 L2 损失进行训练,以预测逆动力学模型产生的潜在动作。训练完成后,控制器可用于生成规划任务的动作序列。该过程包括从当前状态和目标中推断潜在动作,再利用世界模型预测后续状态。控制器训练过程如图所示,展示了控制器如何学习将已知动作映射到潜在动作空间,而历史表示有助于根据当前相机视角消除动作效果的歧义。
实验
- 在真实世界视频中对潜在动作信息内容进行调控实验,表明稀疏且带噪声的连续潜在动作比离散或量化表示更能适应复杂多样的动作。
- 证明潜在动作编码了相对于相机的空间局部变换,无需共享具身,从而实现物体间(如人到球)及跨视频的运动有效迁移。
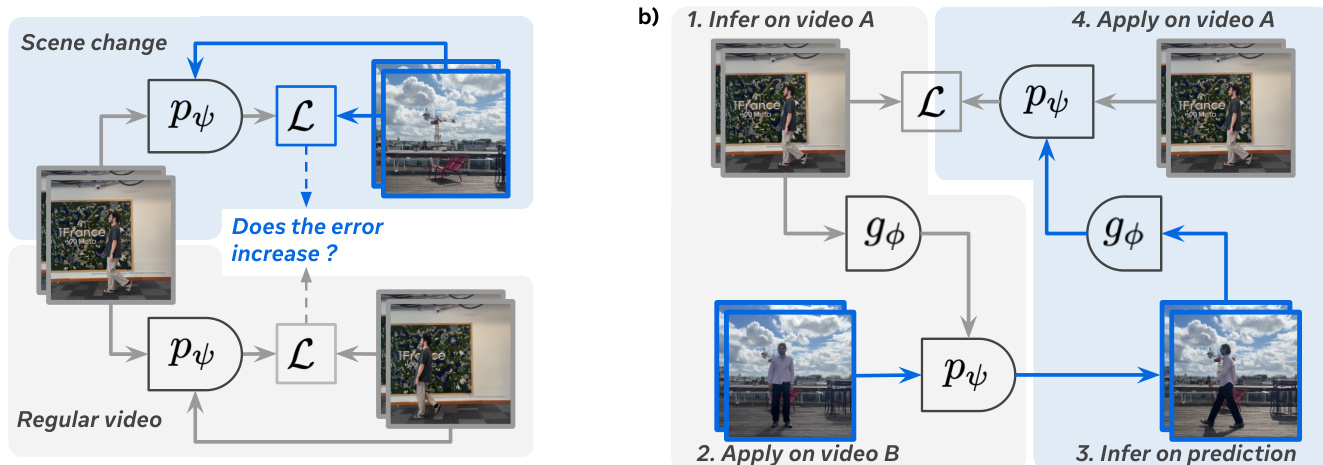
- 验证潜在动作未泄露未来帧信息,因在人工场景切换下预测误差超过两倍,确认其捕捉的是有意义且非作弊的表示。
- 在 Kinetics 和 RECON 数据集上,潜在动作在跨视频迁移中表现出高循环一致性,预测误差增加极小,表明其具有鲁棒性与可复用性。
- 在机器人操作(DROID)和导航(RECON)任务中,仅使用在自然视频上训练的小型控制器,即实现了与在领域特定、带动作标签数据上训练的模型相当的规划性能。
- 在 DROID 和 RECON 数据集上,潜在动作世界模型的规划性能误差在 0.06–0.05 L1 范围内,与显式动作标签训练的基线模型相当或接近。
- 发现最优性能来自平衡的潜在动作容量:容量过高会降低可迁移性与泛化性,容量过低则限制表达能力。
- 扩展实验表明,更大模型、更长训练时间与更多数据可提升逆动力学模型性能,其中训练时间对下游规划的提升最为显著。
作者在机器人操作任务上评估了不同容量潜在动作模型的规划性能,测量累积位移误差。结果表明,具有高容量潜在动作的模型误差更低,其中 V-JEPA 2 + WM 模型表现最佳,误差为 0.05 米。
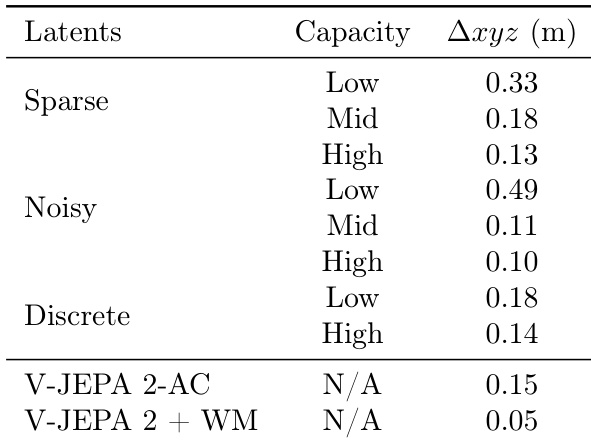
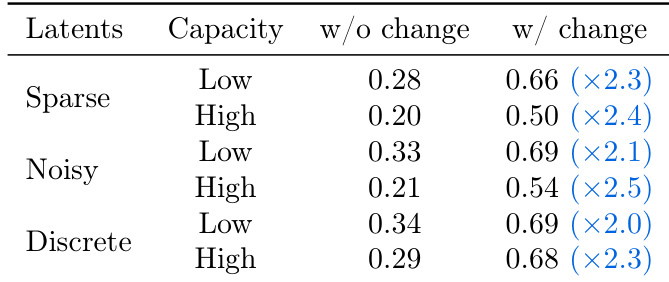
作者评估了不同正则化方法与容量下潜在动作的可迁移性,测量在某视频上推断的动作应用于另一视频时的预测误差增加。结果表明,稀疏且带噪声的潜在动作在高容量下实现更低的预测误差,而离散潜在动作表现更差,尤其在高容量下,表明连续潜在动作在迁移方面更有效。
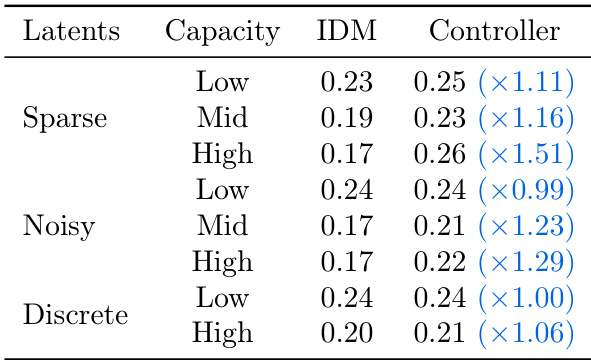
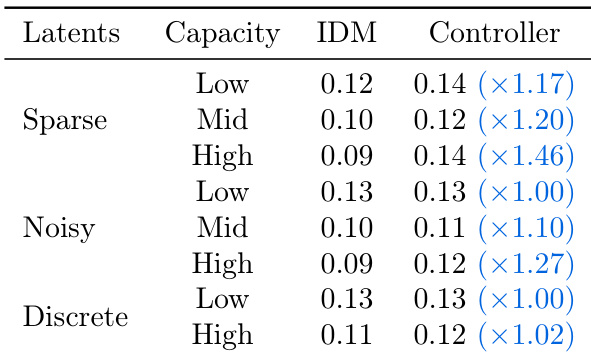
作者比较了不同潜在动作正则化方法及其对预测与控制性能的影响。结果表明,稀疏且带噪声的潜在动作在逆动力学模型(IDM)中实现更低的预测误差,并在控制任务中保持一致性能,而离散潜在动作在两种场景下均表现较差。最佳控制性能由中等容量的稀疏且带噪声潜在动作实现,表明动作复杂性与可识别性之间需取得平衡。
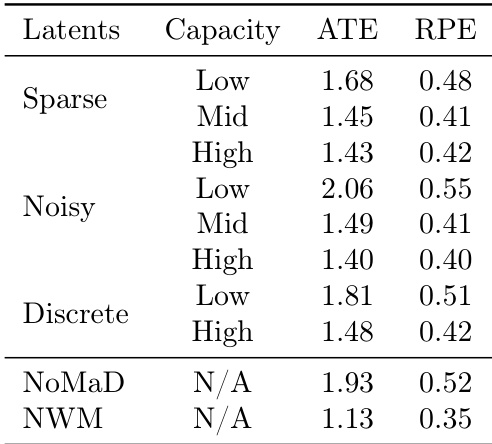
作者使用 ATE 和 RPE 指标评估了不同潜在动作正则化在规划任务中的性能。结果表明,高容量的带噪声潜在动作实现最低的 ATE 和 RPE 值,优于稀疏和离散动作,而 NoMaD 与 NWM 基线表现更差或不适用。
作者比较了不同潜在动作正则化方法,发现稀疏且带噪声的潜在动作在逆动力学模型(IDM)和控制器任务中均比离散方法实现更低的预测误差。尽管更高容量通常提升性能,但最佳结果出现在中等容量,表明动作复杂性与可迁移性之间存在权衡。