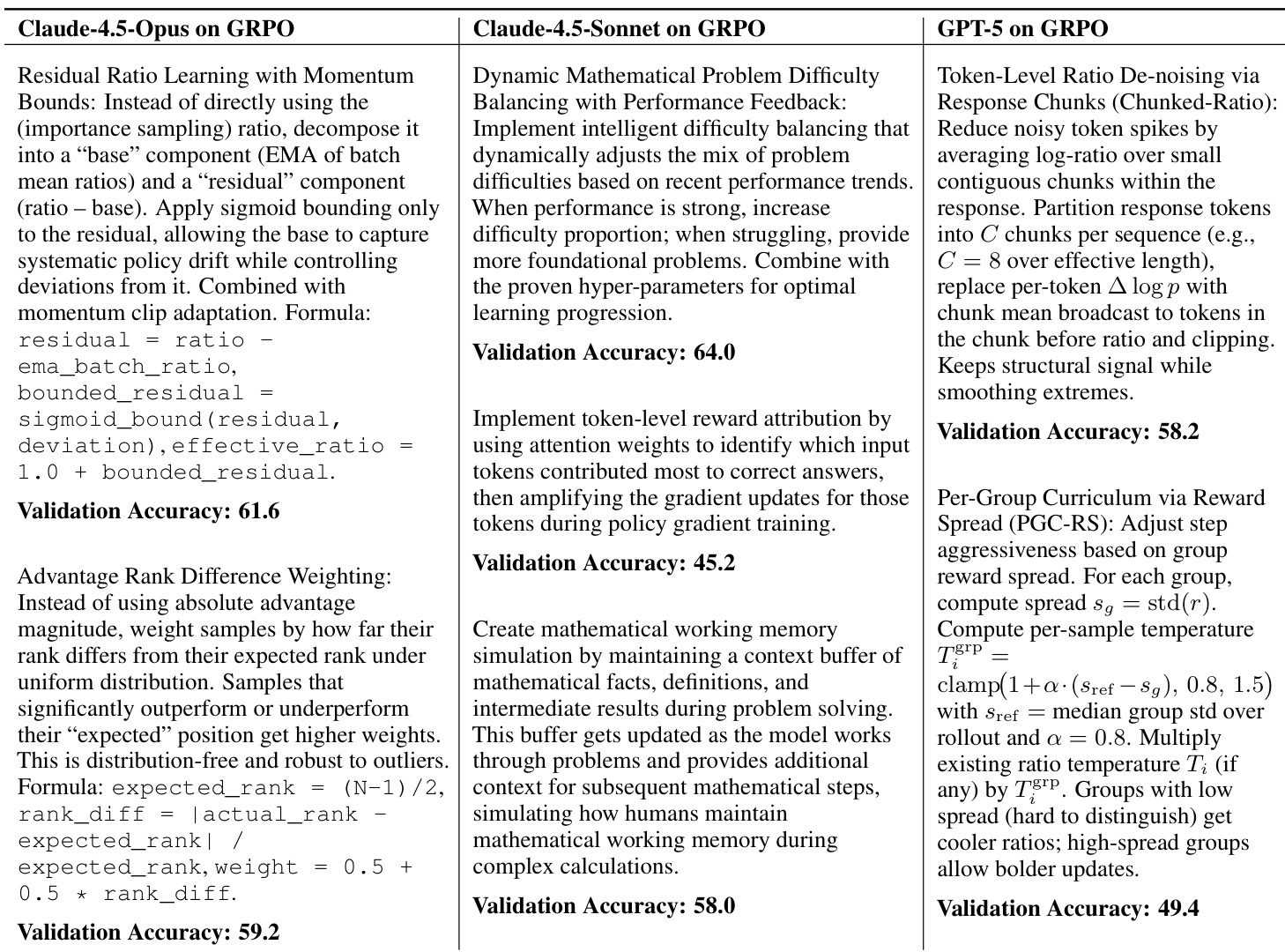
Command Palette
Search for a command to run...
面向执行基础的自动化AI研究
面向执行基础的自动化AI研究
Chenglei Si Zitong Yang Yejin Choi Emmanuel Candès Diyi Yang Tatsunori Hashimoto
摘要
自动化人工智能研究具有加速科学发现的巨大潜力。然而,当前的大规模语言模型(LLMs)常常生成看似合理但实际上无效的研究构想。执行层面的约束或许有助于提升质量,但目前尚不明确自动化执行是否可行,也未验证LLMs能否从执行反馈中学习。为探究上述问题,我们首先构建了一个自动化执行系统,用于实现研究构想,并启动大规模并行GPU实验以验证其有效性。随后,我们将两个真实的科研问题——LLM的预训练与后训练——转化为可执行环境,实证表明,我们的自动化执行系统能够成功实现从前沿LLMs中采样得到的大量研究构想。我们进一步分析了两种从执行反馈中学习的方法:进化搜索与强化学习。基于执行引导的进化搜索展现出极高的样本效率:在后训练任务中,它仅用十个搜索周期便找到了一种显著优于GRPO基线(69.4% vs 48.0%)的方法;在预训练任务中,也找到了一种优于nanoGPT基线(19.7分钟 vs 35.9分钟)的训练方案。相比之下,基于执行奖励的强化学习则面临模式崩溃问题:虽然能提升构想模型的平均奖励,但无法提升其上限性能,原因在于模型趋向于收敛到简单、同质的方案。我们对已执行的构想及其训练动态进行了深入分析,旨在为未来实现以执行为根基的自动化AI研究提供重要参考与指导。
一句话总结
斯坦福大学的司成磊、杨子彤及其同事提出了一种用于AI研究的自动化执行器,通过GPU实验测试LLM生成的想法,利用进化搜索在LLM预训练和后训练中高效超越基线方法,同时揭示了强化学习的局限性及前沿模型的早期饱和现象。
主要贡献
- 我们引入了一种可扩展的自动化执行器,用于实现并评估LLM为开放性问题(如LLM预训练和后训练)生成的研究思路,在Claude-4.5-Opus等前沿模型上实现超过90%的执行成功率。
- 执行引导的进化搜索被证明样本效率高,在十轮迭代内发现显著优于基线的后训练和预训练方案(69.4% vs 48.0% 和 19.7 vs 35.9分钟),但多数模型的扩展趋势仍受限。
- 从执行奖励中进行强化学习可提升平均想法质量,但易出现模式崩溃,收敛到简单、低多样性想法,未能提升科学发现所需的关键上限性能。
引言
作者利用大型语言模型通过生成、实现和评估研究想法的执行反馈闭环来自动化AI研究。以往的AutoML和基于LLM的研究代理工作要么在受限搜索空间中运行,要么缺乏从执行结果中学习的机制——限制了其随时间提升想法质量的能力。作者的主要贡献是一种可扩展的自动化执行器,可并行实现和运行数百个LLM生成的想法,用于开放性问题如LLM预训练和后训练,实现超过90%的执行率。他们使用该系统通过进化搜索和强化学习训练想法生成器,发现进化搜索能高效发现高性能想法,而RL则因多样性崩溃而无法提升峰值性能。该工作展示了可行性,并揭示了未来系统需解决的关键局限。
数据集

作者使用两个研究环境训练和评估其自动化想法执行器:
-
预训练环境(nanoGPT)
- 来源:改编自nanoGPT速通(Jordan等,2024),使用124M GPT-2模型在FineWeb语料库(Penedo等,2024)上训练。
- 目标:在8块H100 GPU上固定25分钟墙钟预算内优化验证损失(或其倒数,1/loss)。
- 修改:
- 代理奖励(1/loss)取代原始训练时间作为优化目标。
- 评估超参数冻结;推理限制为单token预测,防止基于注意力的奖励操纵。
- 最终验证使用锁定的推理函数,确保与原始排行榜上人类方案的公平比较。
-
后训练环境(GRPO)
- 来源:基准GRPO算法(Shao等,2024)在MATH数据集(Hendrycks等,2021)上微调Qwen2.5-Math-1.5B(Yang等,2024)。
- 目标:在固定墙钟时间内最大化MATH验证准确率。
- 防护措施:验证代码隔离在单独文件中;执行器无法访问或修改它,防止奖励操纵。
-
通用设置
- 两个环境均允许无限制的想法范围——从超参数调优到新架构或训练方法。
- 对想法生成模型可提出的改进类型不加约束。
- 环境设计为开放但可衡量,结合创新空间与明确基准。
方法
系统架构包含两个主要组件:自动化想法执行器和自动化AI研究员,二者在闭环反馈系统中协同工作。自动化想法执行器作为一个高级API,将一批自然语言想法转换为基准性能指标。该组件由三个核心模块组成:实现器、调度器和工作器。实现器部署在具有高I/O能力的CPU机器上,接收一批自然语言想法并生成可执行代码变更。它并行调用代码执行LLM API,同时提供想法和基线代码库以采样多个代码差异文件。为确保可打补丁,模型最多进行两次顺序自我修订,返回第一个成功应用的差异。修补后的代码库作为.zip文件上传至云存储桶。调度器以固定时钟频率周期性从云端下载新代码库。对于未执行的代码库,它评估研究环境的资源需求并准备作业配置。工作器是一个配备GPU的集群,在接收调度器的作业配置后连接可用资源。它运行实验并将结果(包括性能指标和完整元数据:想法内容、代码变更、执行日志)上传至云存储桶(如wandb)。自动化AI研究员(包含想法生成模型)接收实验结果并使用它们通过强化学习或进化搜索更新想法生成器,生成新的自然语言想法以继续循环。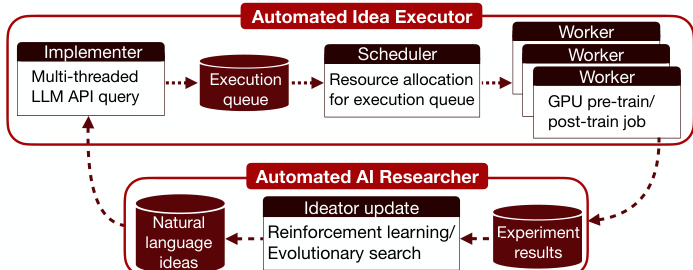
实验
- 构建自动化执行器以实现LLM生成的想法,并通过GPU实验在LLM预训练和后训练任务中验证它们。
- 执行引导的进化搜索发现更优方法:GRPO上准确率达69.4%(对比基线48.0%),nanoGPT上训练时间缩短至19.7分钟(对比基线35.9分钟),均在10轮内达成。
- Claude-4.5-Sonnet和Claude-4.5-Opus实现高执行率(最高达90%),在best-of-50采样中优于基线;GPT-5执行率较低。
- 当使用GPT-5作为执行器时,开源模型如Qwen3-235B仍实现非零完成率并优于基线。
- 在同等预算下,进化搜索优于best-of-N采样,表明跨轮次反馈的有效利用。
- Claude-4.5-Opus显示扩展趋势;Claude-4.5-Sonnet早期饱和但找到最优超参数组合。
- 从执行奖励中进行RL提升平均性能,但导致模式崩溃,收敛到简单想法(如RMSNorm→LayerNorm、EMA),未提升上限性能。
- RL训练缩短思考轨迹长度,与更高执行率相关但想法复杂度降低。
- 模型生成的算法想法类似近期研究论文,表明其支持前沿AI研究的潜力。
- 进化搜索的最优解在GRPO上超越人类专家基准(69.4% vs 68.8%),但在nanoGPT上落后于人类速通(19.7分钟 vs 2.1分钟)。
结果表明,执行引导搜索在后训练任务上实现69.4%的验证准确率,显著优于48.0%的基线,并超越最佳人类专家结果68.8%。在预训练任务上,搜索将训练时间缩短至19.7分钟,优于基线35.9分钟,并接近最佳人类方案2.1分钟。
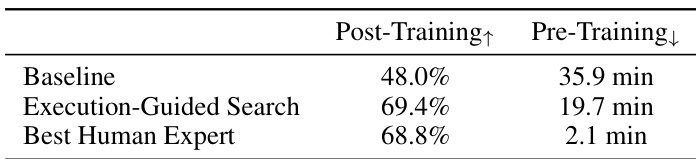
作者使用自动化执行器在两个环境中评估并优化大型语言模型生成的想法:GRPO用于后训练,nanoGPT用于预训练。结果表明,执行引导的进化搜索使模型能发现高性能解决方案,Claude-4.5-Sonnet在GRPO上实现69.4%准确率,Claude-4.5-Opus在nanoGPT上达到3.1407的验证损失,均优于各自基线。
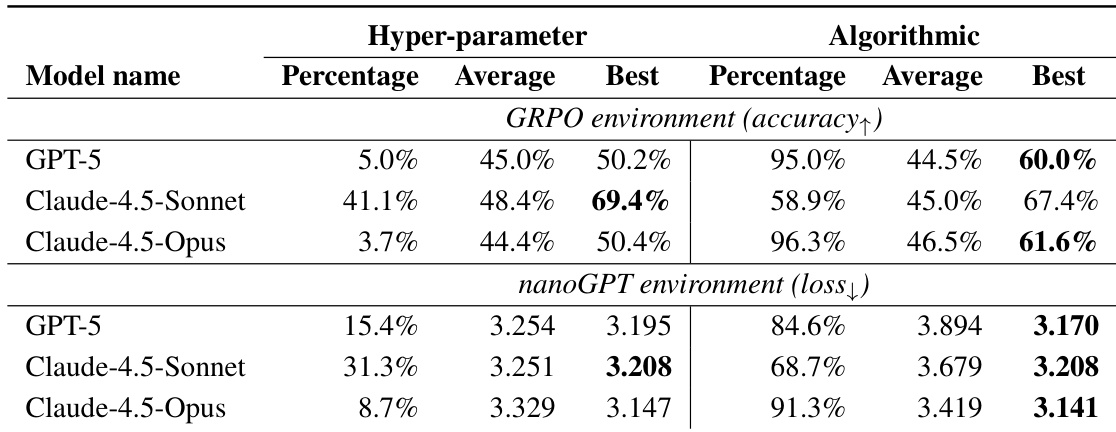
作者使用自动化执行器评估并优化大型语言模型生成的改进LLM训练方法的想法。结果表明,执行引导的进化搜索使Claude-4.5-Opus和Claude-4.5-Sonnet等模型发现显著优于基线方法的方案,其中Claude-4.5-Sonnet在GRPO任务上实现69.4%的验证准确率,Claude-4.5-Opus在nanoGPT任务上将训练时间缩短45%。