Command Palette
Search for a command to run...
POPE:通过特权在策略探索学习在难题上进行推理
POPE:通过特权在策略探索学习在难题上进行推理
Yuxiao Qu Amrith Setlur Virginia Smith Ruslan Salakhutdinov Aviral Kumar
摘要
强化学习(RL)已显著提升了大型语言模型(LLMs)的推理能力,然而当前最先进的方法在许多训练问题上仍难以有效学习。在困难问题上,基于策略的强化学习(on-policy RL)几乎从未探索到任何一条正确的轨迹,导致获得零奖励,从而无法提供推动改进的学习信号。我们发现,经典强化学习中用于缓解探索困境的自然解决方案——例如熵奖励(entropy bonus)、放宽重要性比率的裁剪范围,或直接优化 pass@k 目标——均无法解决该问题,且往往在未提升可解性的情况下加剧优化过程的不稳定性。一种自然的替代方案是利用较简单问题上的知识迁移。然而,我们证明,在强化学习训练过程中混合简单与复杂问题会适得其反,原因在于“射线干扰”(ray interference)现象:优化过程会过度聚焦于已可解决的问题,反而主动抑制了对更难问题的进展。为应对这一挑战,我们提出特权在策略探索(Privileged On-Policy Exploration, POPE),该方法将人类或其他“预言者”(oracle)的解决方案作为特权信息,引导在困难问题上的探索,而非像传统方法那样将预言者解作为训练目标(例如离策略RL方法或从监督微调(SFT)结果进行热启动)。POPE通过在困难问题前添加预言者解的前缀,使强化学习在引导式轨迹中能够获得非零奖励。关键在于,这种引导行为所生成的策略能够通过指令遵循与推理能力之间的协同作用,有效迁移回原始的无引导问题。实证结果表明,POPE显著扩展了可解决的问题范围,并在具有挑战性的推理基准测试中大幅提升了模型性能。
一句话总结
卡内基梅隆大学的研究人员提出了 POPE 方法,该方法利用部分“神谕”解法前缀引导策略梯度强化学习(on-policy RL)在困难推理任务中的探索,使模型能够通过指令遵循和回溯行为从无引导任务中学习,同时不破坏优化稳定性,也无需将“神谕”数据作为训练目标。
主要贡献
- POPE 通过使用“神谕”解法前缀引导探索,解决了标准策略梯度强化学习在困难推理问题上失效的问题,使模型能在不直接以“神谕”数据为训练目标的情况下,采样到非零奖励的轨迹。
- 与熵奖励或混合易/难任务训练不同——前者会破坏优化稳定性,后者会导致“射线干扰”——POPE 利用指令遵循机制引导模型走向可解路径,在保持训练稳定的同时提升探索效率。
- 在 DAPO-MATH-17K 等基准测试中评估表明,POPE 显著扩大了可解问题的范围,并通过从引导式问题求解向无引导式求解的迁移能力,提升了整体性能。
引言
作者利用强化学习提升大语言模型在困难问题上的推理能力,但标准策略梯度强化学习在此类任务中通常失败,因为极少能采样到任何正确的轨迹——导致无学习信号。先前的改进方法,如熵奖励、pass@k 优化或混合易/难问题训练,均未奏效:它们要么破坏训练稳定性,要么因“射线干扰”(即优化聚焦于已可解任务)而降低性能。作者的主要贡献是“特权策略梯度探索”(POPE),该方法在强化学习过程中使用人类或“神谕”所写解法的短前缀引导探索——但从未训练模型去模仿这些前缀。这使得模型能在困难问题上采样到成功的轨迹,且所学行为可通过指令遵循和回溯机制迁移到无引导设置中,从而显著扩大可解问题的范围。
数据集
- 作者使用了人类撰写与模型生成的数学问题解法的混合数据,主要来源于两个数据集:Omni-MATH(人类解法)和 DAPO(由 gemini-2.5-pro 生成的解法)。
- Omni-MATH 提供结构化的题目-解法对,包含逐步推理过程,如代数表达式和验证步骤;例如,要求构造满足特定和性质的集合的问题。
- DAPO 提供模型生成的解法,例如“求最小自然数 n,使得 n²−n+11 恰好有四个质因数”,从而支持人类与合成推理的对比。
- 文中未提供任一子集的显式过滤规则或规模指标;重点在于解法结构和正确性,而非数据集规模。
- 数据以原始形式用于评估或说明;文中未提及训练/验证划分、混合比例、裁剪或元数据构建。
- 数据处理极简:解法以原始 LaTeX 和自然语言形式呈现,保留原始格式和逻辑流,便于直接分析或比较。
方法
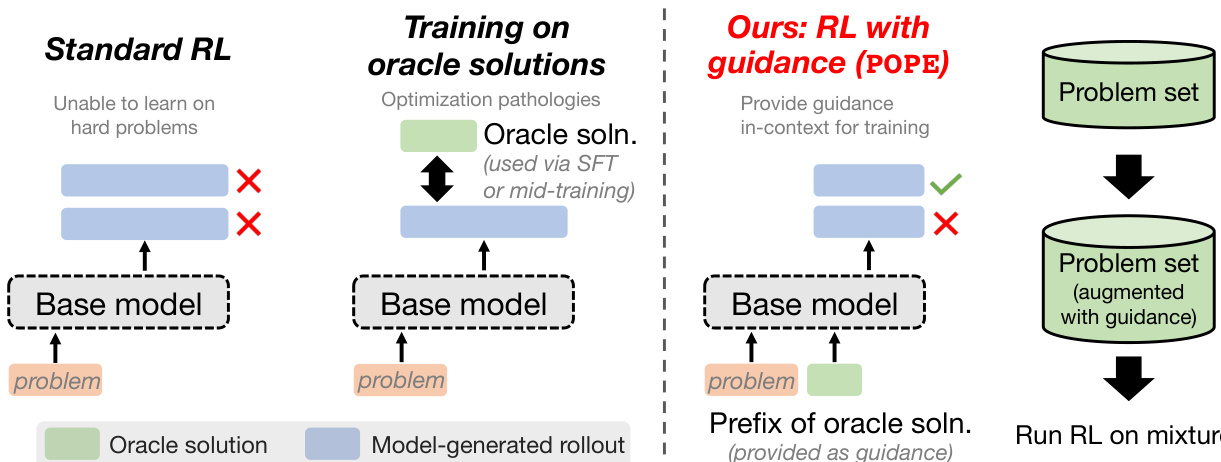
作者提出了一种新颖的探索策略——“特权策略梯度探索”(POPE),以解决标准策略梯度强化学习在困难问题上的根本缺陷:奖励信号消失、训练停滞。与将“神谕”解法直接作为训练目标(易导致记忆化或策略不稳定)不同,POPE 仅将它们作为上下文引导,引导模型自身的策略梯度轨迹进入可获得非零奖励的解空间区域。
核心机制是为每个难题附加一个从人类解法中精心挑选的短前缀,并附带一条系统指令,引导模型在此基础上继续生成。该引导不取代模型自身的生成过程,而是调整策略,使其从更有利的内部状态开始轨迹生成。作者通过评估确定每个问题 x 的最小前缀长度 i∗(x),即能使基础模型至少生成一次成功轨迹的最短前缀。若不存在此类前缀,则使用一小段随机片段(少于完整解法的 1/4)。引导数据集构造如下:
Dhardguided:={concat(x,z0:i∗(x),I)∣x∈Dhard}.训练在无引导难题与其引导版本 1:1 混合的数据上进行,确保模型能从引导式设置泛化到无引导设置。该方法完全保持策略梯度性质:所有轨迹均由当前策略生成,梯度更新不使用任何离策略数据。
参考框架图,图中对比了 POPE 与标准 RL 及直接“神谕”训练。标准 RL 在难题上因所有轨迹均错误导致优势为零而失败;直接通过 SFT 或训练中途注入“神谕”解法会引发优化异常。相比之下,POPE 通过上下文引导提供奖励信号,同时不扭曲策略的生成行为。
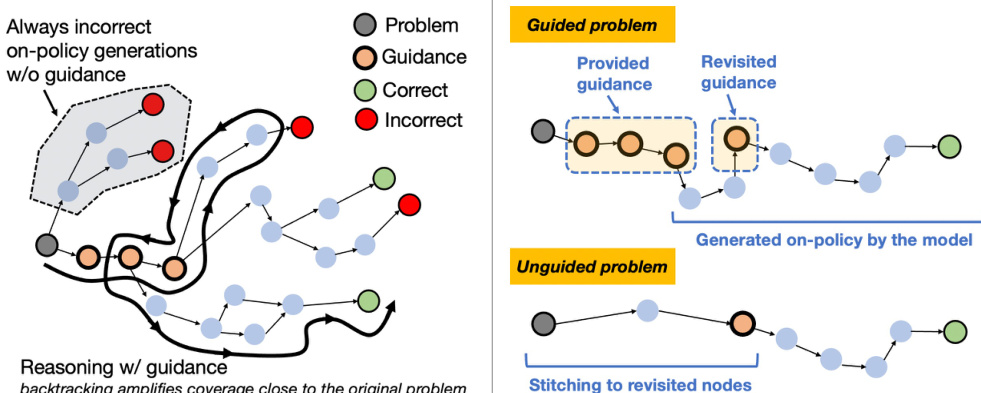
POPE 的有效性基于 MDP 中探索的思维模型。难题的特点是奖励稀疏,代理必须从初始状态到达一个子集 Sgood,从该子集中可稳定获得奖励。引导相当于一个“滚入策略”,将模型导向 Sgood,从而使策略梯度强化学习能学习有效的后续行为。一旦这些后续行为被习得,模型即可在无引导情况下从 Sgood 成功,剩余挑战简化为如何从初始问题到达此类状态。
如下图所示,大语言模型中的推理轨迹常包含自我验证与回溯行为,从而扩大了初始问题附近的可达状态范围。当这些行为在引导下发生时,会诱导引导与无引导状态空间的重叠。这种重叠使所学策略能从引导式成功泛化到无引导前缀,实质上将探索问题简化为到达任何邻近状态,而非复现完整引导字符串。
训练过程基于 Pipeline-RL 框架,底层优化器为 GRPO。每个提示下,Actor 工作者最多生成 8 条轨迹,经预处理工作者缓冲处理后,由学习者工作者用于策略更新。RL 损失采用 GRPO 的裁剪代理目标,优势值按批次均值标准化以降低方差。作者默认不包含熵或 KL 正则项,而是专注于引导对探索动态的影响。
作者还探索了 pass@k 优化作为标准奖励最大化的替代方案,动机是优化 pass@1 可能导致“射线干扰”——即过拟合于简单问题而损害难题表现。pass@k 目标最大化至少一条 k 条独立轨迹成功的概率,通过无偏估计器计算:
ρ(n,c,k)=1−(kn)(kn−c),其中 n 为每个提示采样的轨迹数,c 为正确轨迹数。梯度按加权策略梯度计算,权重取决于轨迹是否正确,使模型能从成功与近似成功中学习。
综上,POPE 将稀疏奖励探索转化为两阶段问题:首先,通过引导到达可获得奖励的状态;其次,通过策略梯度强化学习学习如何利用该状态。大语言模型推理轨迹的结构(特别是自我修正与回溯)通过诱导潜在状态空间重叠,实现了从引导到无引导问题的迁移,使 POPE 成为一种可扩展且有效的方法,能在不损害模型生成能力的前提下提升难题表现。
实验
- 词元级探索方法(熵奖励、更高裁剪比)在难题上失效,导致熵爆炸且无实质性可解性提升。
- 训练中混合易/难题会引发“射线干扰”,尽管早期有收益,但会阻碍难题进展。
- 直接优化 pass@k 指标无助于难题探索;它降低奖励信号并减缓收敛。
- POPE 利用引导前缀避免“射线干扰”,即使与易问题混合训练,也能在难题上持续改进。
- POPE 的有效性依赖于引导与无引导推理路径的重叠;限制回溯引导会削弱向无引导设置的迁移能力。
- POPE 优于在“神谕”解法上进行监督微调,后者会崩溃熵并损害难题与基准测试表现。
- POPE 在标准化基准(AIME2025、HMMT2025)上提升下游表现,尤其在更难题目上,同时在异构训练数据中保持鲁棒性。
作者发现,标准强化学习和词元级探索方法因熵爆炸和“射线干扰”无法解决难题,而对“神谕”解法的监督微调因崩溃词元熵而降低性能。相比之下,POPE——一种使用引导前缀的方法——在难题上持续提升可解性,缓解易问题干扰,并在混合训练设置下提升标准化基准表现。