Command Palette
Search for a command to run...
自蒸馏实现持续学习
自蒸馏实现持续学习
Idan Shenfeld Mehul Damani Jonas Hübotter Pulkit Agrawal
摘要
持续学习使模型能够在不损害已有能力的前提下不断习得新技能与知识,仍是基础模型面临的一项根本性挑战。尽管基于策略的强化学习能够缓解遗忘问题,但其依赖显式的奖励函数,而这类函数在实际中往往难以获得。另一种主要方法是通过专家示范进行学习,目前该方法主要依赖于监督微调(SFT),而SFT本质上属于非策略学习。为此,我们提出自蒸馏微调(Self-Distillation Fine-Tuning, SDFT),一种可直接从示范中实现策略内学习的简单方法。SDFT通过利用示范条件化的模型作为自身教师,借助上下文学习机制生成策略内的训练信号,从而在保留原有能力的同时有效习得新技能。在各类技能学习与知识获取任务中,SDFT始终优于SFT,在提升新任务准确率的同时显著缓解了灾难性遗忘。在顺序学习实验中,SDFT使单一模型能够随时间持续积累多种技能而不会出现性能退化,从而确立了基于策略蒸馏的持续学习路径在示范学习中的可行性与实用性。
一句话总结
来自 MIT、Improbable AI 实验室和苏黎世联邦理工学院的 Idan Shenfeld 等人提出了 SDFT,这是一种利用自生成的上下文信号进行策略内蒸馏的方法,可减少遗忘,在持续技能与知识获取任务中优于 SFT,且无性能退化。
主要贡献
- SDFT 通过利用上下文学习将模型转变为以专家示例为条件的自身教师,实现无需显式奖励函数的策略内更新,从而应对从演示中持续学习的挑战。
- 该方法训练学生模型去匹配以演示为条件的教师版本输出分布,通过最小化反向 KL 散度生成与策略对齐的训练信号,在获取新技能的同时保留先前能力。
- 在技能学习和知识获取任务中评估,SDFT 在新任务准确率上优于监督微调,并显著减少灾难性遗忘;序列实验显示其能稳定积累多技能且无性能退化。
引言
作者利用自蒸馏,直接从专家演示中实现策略内持续学习——在该场景下,传统监督微调因灾难性遗忘和离策略漂移而失败。先前方法要么需要手工设计奖励函数(如强化学习),要么依赖逆强化学习,但后者面临可扩展性差和强结构假设的挑战。他们的主要贡献——自蒸馏微调(SDFT)——重新利用模型的上下文学习能力:将同一模型以演示为条件作为教师,同时训练学生版本基于其自身输出进行更新,生成保留先前能力的同时获取新技能的策略内更新。该方法在序列学习基准上持续优于标准微调,实现稳定、长期的技能积累且无性能退化。
数据集

作者使用一个多领域数据集,包含四个关键子集,每个子集来源和处理方式不同,以支持技能学习与知识获取:
-
科学问答(来自 SciKnowEval 的 Chemistry L-3):
划分为 75% 训练集、5% 验证集和 20% 测试集。专家演示通过查询 GPT-4o 生成,每条提示最多采样 8 个响应并选择与正确最终答案匹配的一个。所有训练样本均获得有效演示。准确率通过多项选择的精确匹配衡量。 -
工具使用(ToolAlpaca):
使用 Tang 等人(2023)的原始训练-测试划分。专家演示已预包含。评估使用正则表达式匹配真实 API 调用,允许参数顺序灵活。 -
医学(HuatuoGPT-o1 子集):
仅在约 20,000 条英文问题的 SFT 集上训练。评估时随机抽取 1,000 个可验证的临床问题。响应由 GPT-5-mini 自动评估,提示聚焦于医学准确性和完整性,输出“CORRECT”或“INCORRECT”。 -
知识获取(合成 2025 灾难维基问答):
基于虚构 2025 年自然灾害的维基风格文章构建。GPT-5 使用自定义提示为每篇文章生成 100 个多事实问题;手动去除重复项。评估使用 GPT-5-mini 与三级评分标准(“CORRECT”、“PARTIALLY_CORRECT”、“INCORRECT”)评估事实准确性和完整性。
所有数据集均在自蒸馏微调框架(SDFT)中使用。模型在训练期间使用学生和教师上下文提示生成响应,计算词元级对数概率,并通过梯度下降与教师 EMA 更新参数。可选使用重要性采样对齐推理与训练引擎。未提及除基于提示评估外的裁剪或元数据构建。
方法
作者利用自蒸馏框架微调大型语言模型,其中单个模型通过利用其上下文学习能力同时充当教师与学生。核心架构如框架图所示,包含两种模式:学生模式和教师模式,两者均基于相同语言模型参数 θ。学生模式处理查询 x 生成响应 y∼πθ(⋅∣x),而教师模式将相同模型以查询 x 和演示 c 为条件,生成条件策略 π(⋅∣x,c)。演示通过简单提示结构纳入,鼓励模型推断示例背后的意图而非逐字复制。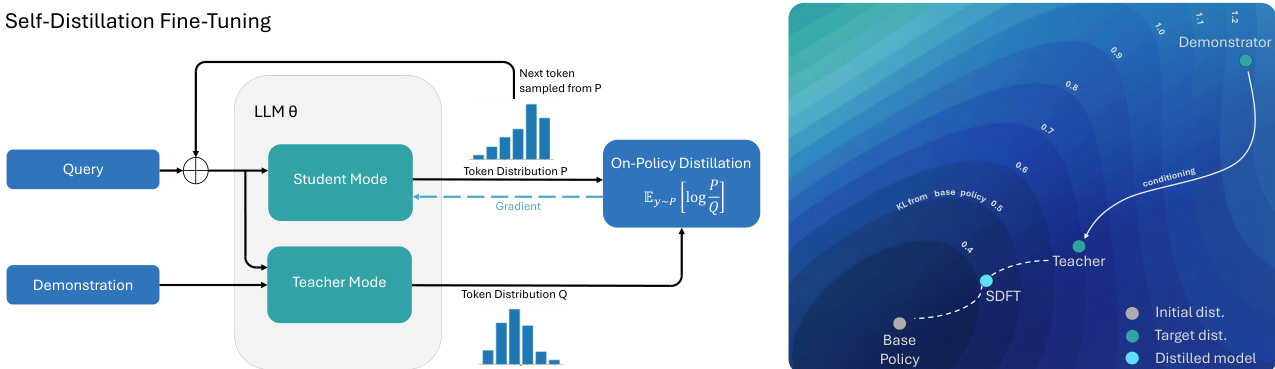
训练目标是最小化学生与教师输出分布之间的反向 Kullback-Leibler(KL)散度,定义为 L(θ)=DKL(πθ(⋅∣x)∥π(⋅∣x,c))。该目标在词元级别计算,利用模型的自回归特性。该损失相对于学生参数 θ 的梯度通过将序列级 KL 分解为词元级项之和推导得出,得到梯度估计器 ∇θL(θ)=Ey∼πθ[∑t∑yt∈Vlogπ(yt∣y<t,x,c)πθ(yt∣y<t,x)∇θlogπθ(yt∣y<t,x)]。该公式实现策略内学习,学生根据其当前行为更新,确保稳定性与连续性。
一个关键设计选择是教师模型的参数化。虽然教师始终以演示 c 为条件,但其权重可有多种定义方式。作者使用学生参数的指数移动平均(EMA)作为教师,提供稳定平滑的教师策略,避免突变。该选择对保持学习过程的策略内性质和防止灾难性遗忘至关重要。框架图突出了信息流,其中学生的词元分布 P 用于计算策略内蒸馏步骤的梯度,更新学生模型参数 θ。
该方法也可解释为逆强化学习(IRL)算法。自蒸馏目标在数学上等价于最大化由演示条件教师与当前学生策略间对数概率差导出的隐式奖励函数。该奖励函数 rt(yt∣y<t,x,c)=logπk(yt∣y<t,x)π(yt∣y<t,x,c) 在词元级别定义,捕捉演示带来的行为即时改进。在该奖励下的策略梯度被证明等价于反向 KL 散度的梯度,表明该方法本质上是一种从自身上下文学习能力中学习的策略内 RL 算法。右侧图示策略空间,可视化该过程:基础策略更新至以演示为条件的教师策略,同时保持接近初始策略以保留通用能力。
实验
- 在科学问答、工具使用和医学任务中,SDFT 在新任务准确率上优于 SFT 和 DFT,同时保留先前能力,实现帕累托最优权衡。
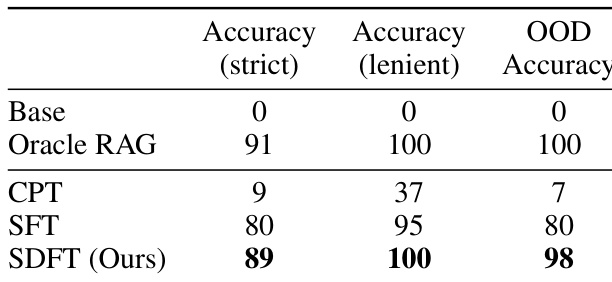
- 在知识获取中,SDFT 在 2025 灾难事实任务上达到 89% 严格准确率(SFT 为 80%),且分布外准确率接近完美,超越 CPT 并匹配 Oracle RAG。
- SDFT 缓解灾难性遗忘:在多任务持续学习中,它实现稳定技能积累,而 SFT 导致严重干扰和性能振荡。
- 模型扩展增强 SDFT:Qwen2.5-14B 在科学问答上比 SFT 提升 7 分,确认其依赖强大的上下文学习能力。
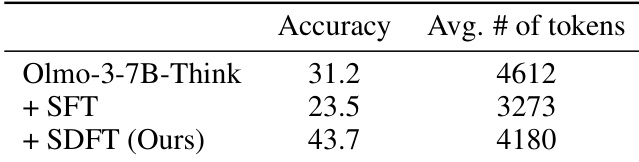
- 在仅含答案的医疗数据的 Olmo-3-7B-Think 上,SDFT 将准确率提升至 43.7%(SFT 为 23.5%),且未压缩推理深度。
- 策略内蒸馏至关重要:从相同教师进行的离线蒸馏表现逊于 SDFT,证明收益源于策略内学习,而非仅教师质量。
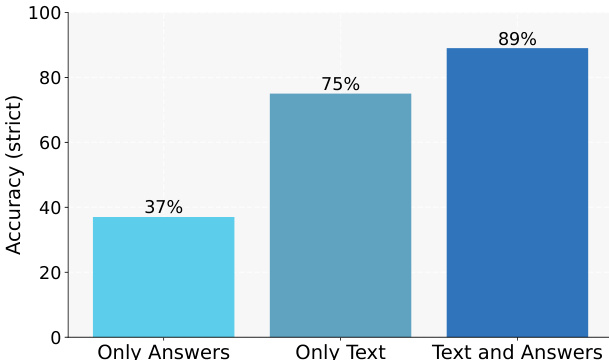
- 教师上下文重要:以文章文本和答案为条件时准确率达 89%,仅文本条件为 75%。
- EMA 教师确保稳定训练:优于冻结基线和不稳定自教师变体。
- SDFT 比 SFT 增加 2.5 倍 FLOPs 和 4 倍墙钟时间,但与 Re-invocation 等多阶段基线相比可能降低总成本。
结果表明,SDFT 在知识获取设置中所有指标上均达到最高准确率,优于 CPT 和 SFT。该方法达到 89% 严格准确率和 100% 宽松准确率,同时实现 98% 分布外准确率,证明有效整合新事实知识。
作者使用 SDFT 在工具使用任务上训练模型,同时评估其对先前能力的影响。结果表明,SDFT 在新任务上达到最高准确率(70.6),并在先前任务(包括 HellaSwag、HumanEval 和 TruthfulQA)中保持最佳性能,优于 SFT 和 DFT 基线。这表明 SDFT 有效提升任务性能且无显著灾难性遗忘。

作者评估教师上下文对知识整合的影响,显示以源文本和答案为条件的教师显著提高严格准确率,相比仅使用文本或仅使用答案。结果表明完整演示上下文对有效知识迁移至关重要,文本加答案条件达到 89% 准确率,远优于仅文本条件(75%)和仅答案条件(37%)。
作者使用 Qwen2.5 7B-Instruct 模型比较 SFT、CPT 和 SDFT,其中 SDFT 使用指数移动平均(EMA)教师和策略内学习。SDFT 通过利用演示条件教师信号和策略内蒸馏,优于 SFT 和 CPT,减少灾难性遗忘并提升分布内和分布外准确率。
作者使用演示条件教师策略训练推理模型,无需显式推理数据,在仅含答案监督的医疗任务上比较标准 SFT 与他们的 SDFT 方法。结果表明,SDFT 将准确率从 31.2% 提升至 43.7%,同时保持推理深度,而 SFT 降低性能和响应长度。