Command Palette
Search for a command to run...
各归其位:文本到图像模型空间智能的基准测试
各归其位:文本到图像模型空间智能的基准测试
Zengbin Wang Xuecai Hu Yong Wang Feng Xiong Man Zhang Xiangxiang Chu
摘要
文本到图像(Text-to-Image, T2I)模型在生成高保真图像方面取得了显著进展,但在处理复杂空间关系方面仍存在明显不足,例如空间感知、空间推理或物体间交互等关键能力。当前主流评估基准普遍忽视这些方面,主要原因在于其提示(prompt)设计通常过短或信息密度较低。为此,本文提出一项全新的基准——SpatialGenEval,旨在系统性地评估T2I模型的空间智能,涵盖两个核心方面:(1)SpatialGenEval包含25个真实场景下的1,230个长文本、高信息密度的提示。每个提示融合了10个空间子领域(如物体位置、布局、遮挡、因果关系等),并配套10组多选题问答对,全面覆盖从基础空间定位到复杂推理的多个维度。我们对21个当前最先进的T2I模型进行了广泛评估,结果表明,高阶空间推理能力仍是制约模型性能的主要瓶颈。(2)为进一步验证高信息密度提示设计的实用价值,我们构建了SpatialT2I数据集。该数据集包含15,400对文本-图像样本,通过对原始提示进行重写以确保图像一致性,同时保持原有的信息密度。在当前主流基础模型(如Stable Diffusion-XL、Uniworld-V1、OmniGen2)上进行微调后,模型在空间关系建模方面均取得一致性的性能提升(分别提升+4.2%、+5.7%、+4.4%),并呈现出更符合现实的空间逻辑效果。这一成果凸显了以数据为中心的范式在提升T2I模型空间智能方面的巨大潜力。
一句话总结
来自AMAP、阿里巴巴集团和北京邮电大学的研究人员提出了SpatialGenEval——一个包含1,230个密集提示的基准,用于评估T2I模型的空间推理能力;同时提出SpatialT2I——一个训练数据集,通过信息丰富的提示重设计,可使Stable Diffusion-XL等模型的性能提升高达5.7%。
主要贡献
- 我们引入了SpatialGenEval,这是一个新基准,包含25个现实场景中的1,230个长而信息密集的提示,每个场景整合了10个空间子领域,并配以10道多选题,系统评估T2I模型的空间感知、推理和交互能力。
- 我们对23个最先进模型的评估揭示了高阶空间推理中普遍存在且显著的瓶颈,表明当前T2I系统在基本对象生成上表现出色,但在复杂空间关系处理上仍存在困难。
- 我们构建了包含15,400个图文对的SpatialT2I数据集,其提示经过重写以保持信息密度;实验证明,在该数据集上对Stable Diffusion-XL、Uniworld-V1和OmniGen2等基础模型进行微调,可使空间准确性和真实感提升4.2%–5.7%。
引言
作者利用文本到图像模型日益增强的能力,解决一个关键缺陷:它们难以处理复杂的空间关系,如物体定位、遮挡和因果交互。当前基准主要关注短提示和基本对象-属性匹配,未能评估高阶空间推理,导致模型评估存在盲区。为此,作者提出SpatialGenEval——一个包含1,230个长且信息密集提示的基准,覆盖25个现实场景,每个提示配以10道多选题,覆盖10个空间子领域。他们对23个模型的评估揭示了空间推理的普遍瓶颈。除评估外,作者还构建了SpatialT2I——一个包含15,400个图文对的微调数据集,可使Stable Diffusion-XL和OmniGen2等模型的性能提升高达5.7%,证明以数据为中心的训练可直接提升空间智能。
数据集

作者使用精心构建的数据集流水线评估并增强文本到图像(T2I)模型的空间智能。以下是详细说明:
-
数据集构成与来源
核心基准SpatialGenEval由25个现实场景构成,涵盖5个类别:户外(32.5%)、自然(28.5%)、室内(16.3%)、人物(12.2%)和设计(10.6%)。这些场景选择注重多样性和现实相关性,涵盖从机场到水下景观的环境。 -
关键子集细节
- 提示生成:使用Gemini 2.5 Pro生成1,230个高质量、信息密集的提示(平均60词),每个提示嵌入全部10个空间子领域。人类专家对其进行润色,确保流畅性、逻辑性和词汇简洁性(例如,将“ vermilion”替换为“亮红色”)。
- 问答生成:为每个提示自动生成10道多选题(每题对应一个空间子领域),每题含3个干扰项。人工标注者确保无答案泄露(例如,将“叶子呈圆形排列的布局是什么?”修改为“图中叶子的布局是什么?”),并为不确定情况添加“无”选项。
- SpatialT2I(SFT数据集):由14个顶级T2I模型生成的15,400个图文对构成。提示通过GPT-4o重写以更好地匹配生成图像。“设计”场景(130个提示)因图像质量较低被排除。
-
模型训练与数据使用
SpatialT2I用于微调UniWorld-V1、OmniGen2和Stable Diffusion-XL。作者通过消融实验测试数据质量:三个子集(Unipic-v2、Bagel、Qwen-Image)的性能提升与其原始得分成正比。扩展实验表明,加入更高质量的子集可提升模型的空间推理能力。 -
处理与元数据
- 所有提示和问答均由5名专家经过168人时的人机协同流程精修,遵循详细标注规则。
- 问答对由Qwen2.5-VL验证一致性。
- 对于SpatialT2I,提示通过GPT-4o重写以对齐图像内容,在保留空间智能的同时修正错位。
- 元数据包括场景类型、提示、问题、真实答案、图像路径和模型预测——均结构化以确保可复现性。
该流水线结合MLLM自动化与人工策划,确保高质量、空间丰富的数据用于评估和模型训练。
方法
作者采用分层框架定义并评估Spatial-GenEval基准中的空间智能,结构涵盖四大主要领域:空间基础、空间感知、空间推理和空间交互。每个领域进一步分解为具体子维度,逐步评估模型生成和解释空间一致场景的能力。评估流程始于现实场景选择和全部10个空间子领域的整合,如框架图所示。
第一阶段,大型语言模型(LLM)合成一个包含全部10个空间约束的信息密集提示。该提示设计为语义丰富,明确整合所需子领域,如对象属性、空间位置和因果交互。生成的提示随后驱动文本到图像(T2I)模型生成。生成的图像随后与10组对应的多维问答对进行评估,这些问答对旨在探测模型对提示中编码空间关系的理解。评估过程通过将模型输出与真实答案对比以识别差异,进而优化提示以提高空间准确性。
框架包含提示生成的元指令阶段,任务描述规定每个提示必须涉及全部10个空间子领域,且长度约为60词。这确保生成的提示全面覆盖广泛的空间推理任务。输出格式要求提示以有效JSON结构化,每个条目包含场景及其对应的生成提示。这种结构化方法确保一致性,并便于跨不同场景系统评估空间智能。
第二阶段,重点转向基于文本到图像提示生成问答对。此阶段的元指令强调创建10道多选题,每题针对一个空间子领域。问题必须直接源自提示,避免引入无关或虚构信息。此阶段的输出格式同样基于JSON,每个条目包含场景、提示、问题类型和对应答案。这确保评估系统化且与原始提示对齐。
最后,框架包含提示重写的元指令,目标是提升生成提示的空间智能。过程涉及分析输入JSON,包括场景、提示、问题类型和真实答案。任务是解构场景并合成一个重写提示,准确反映场景的最终状态,整合所有感知、推理和交互细节中的确认事实。重写提示必须是单一、清晰的段落,适合下游文本到图像生成。这种迭代优化过程确保提示不仅准确,而且优化用于生成空间一致的图像。
实验
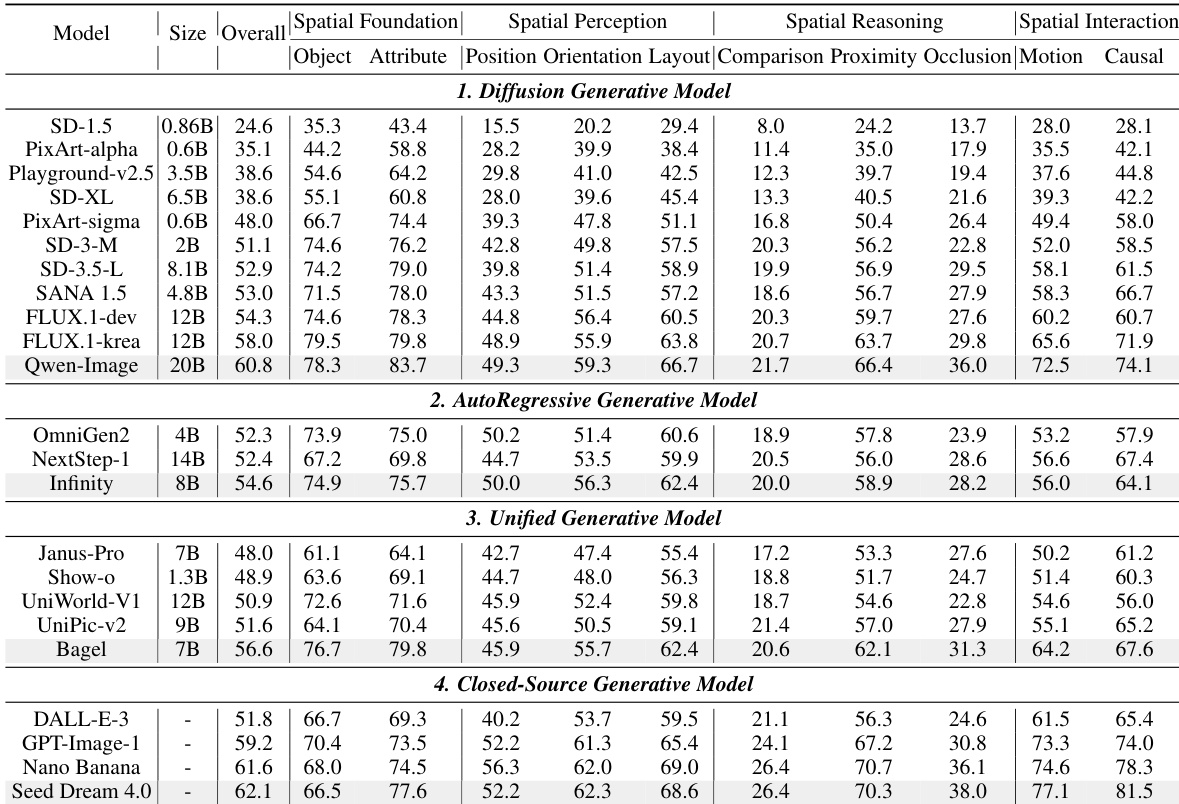
- 在SpatialGenEval上评估了23个文本到图像模型(开源/闭源),使用Qwen2.5-VL-72B作为评判者;表现最佳者:Seed Dream 4.0(62.7%),紧随其后的是开源Qwen-Image(60.6%)。
- 空间推理(如比较、遮挡)是核心瓶颈,得分常低于30%,接近随机概率(20%)。
- 文本编码器更强的模型(如基于LLM)优于仅使用CLIP的模型;例如,Qwen-Image(60.6%)> SD-1.5(28.5%)。
- 统一模型(如Bagel,7B,57.0%)与更大的扩散模型(如FLUX.1-krea,12B,58.5%)相比表现具有竞争力,显示架构效率。
- 通过Gemini 2.5 Pro重写提示可提升得分(如OmniGen2在比较任务中+4.5%),尤其对显式空间关系有效,但对遮挡等隐式推理无效。
- 评估稳健:GPT-4o和Qwen2.5-VL-72B产生一致排名;人类对齐研究确认MLLM评估者有效(平衡准确率约80%)。
- SpatialGenEval与其他基准强相关,验证其作为生成能力指标的可靠性。
作者使用多基准比较评估五个流行文本到图像模型在各种空间智能任务上的表现。结果表明,Qwen-Image在提出的SpatialGenEval基准上得分最高(60.60),优于Janus-Pro、SD-3.5-L、Flux.1-dev和Bagel等模型,其排名在多个基准中保持一致。

作者使用综合基准评估23个文本到图像模型的四类任务,结果显示开源模型正缩小与闭源模型的差距,但空间推理仍是显著弱点。结果表明,模型在对象和属性生成等基本空间任务上表现良好,但在复杂推理上挣扎,特别是在比较和遮挡任务中,得分常低于30%,表明在将语义属性绑定到结构场景逻辑上存在核心局限。
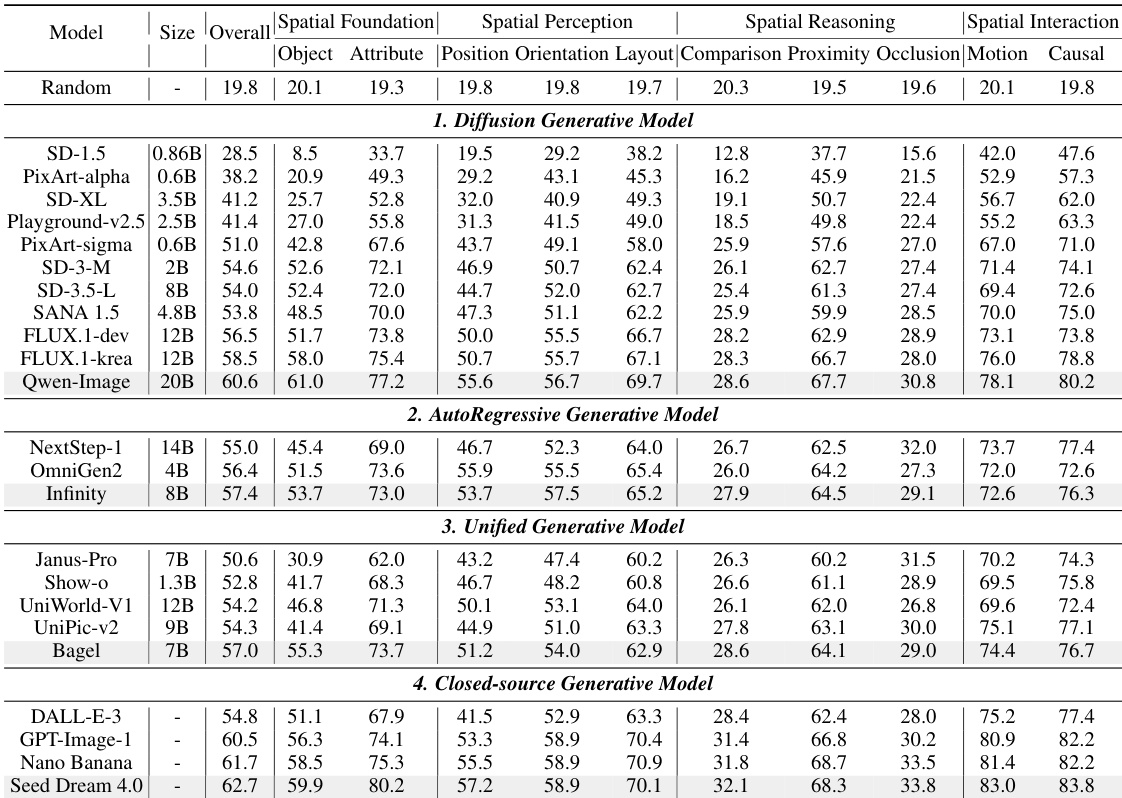
作者使用Qwen-Image评估其在SpatialGenEval基准上的表现,显示其在空间基础和感知任务上表现优异,总体得分高达60.6%,但在空间推理和交互任务上仍挣扎,得分显著较低。结果表明,虽然Qwen-Image在所有子领域上优于随机选择和无图像输入,但其在空间推理(42.4%)和空间交互(79.2%)上的表现表明在复杂空间推理和交互任务上仍存在持续弱点。

作者使用多轮投票机制在SpatialGenEval基准上评估文本到图像模型,评估其在四个空间维度上的表现。结果表明,虽然模型在基本空间基础任务上表现良好,但在比较和遮挡等复杂推理子任务上准确率显著下降,表明在关系理解上存在核心弱点。
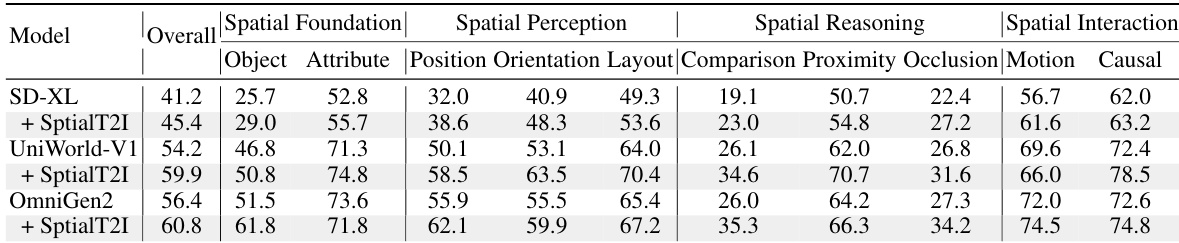
作者使用综合基准评估23个文本到图像模型的四类任务,结果显示开源模型正缩小与闭源模型的差距,但空间推理仍是显著弱点。结果表明,模型在对象和属性生成等基本空间任务上表现良好,但在复杂推理上挣扎,特别是在比较和遮挡任务中,得分常低于30%。