Command Palette
Search for a command to run...
扩展嵌入空间在语言模型中的表现优于扩展专家模型
扩展嵌入空间在语言模型中的表现优于扩展专家模型
摘要
尽管混合专家(Mixture-of-Experts, MoE)架构已成为大规模语言模型中实现稀疏性扩展的标准方案,但其正面临收益递减及系统级瓶颈的挑战。在本工作中,我们探索将嵌入(embedding)扩展作为提升稀疏性扩展能力的一个强大且正交的维度。通过全面的分析与实验,我们识别出在特定场景下,嵌入扩展相较于专家扩展能够实现更优的帕累托前沿(Pareto frontier)。我们系统地刻画了决定该方法有效性的关键架构因素——从参数预算分配,到与模型宽度和深度之间的相互作用。此外,通过引入定制化的系统优化技术与推测性解码(speculative decoding),我们成功将这种稀疏性转化为实际的推理加速效果。基于上述洞见,我们提出了 LongCat-Flash-Lite,一个参数量达685亿(68.5B)且激活参数约30亿(3B)的全新模型,该模型从零开始训练。尽管分配了超过300亿参数用于嵌入层,LongCat-Flash-Lite 不仅在参数量相当的 MoE 基线模型中表现更优,还在与同类规模模型的对比中展现出卓越的竞争力,尤其在智能体(agentic)任务与代码生成(coding)领域表现突出。
一句话总结
美团LongCat团队推出LongCat-Flash-Lite,一款拥有685亿参数、激活参数约30亿的稀疏模型,通过嵌入扩展而非专家扩展实现更优的效率与性能,在代理和编程任务中表现卓越,辅以系统优化与推测解码技术。
主要贡献
- 我们证明,嵌入扩展(特别是通过N-gram嵌入)在特定场景下可超越专家扩展,通过高效扩展参数容量而不引入MoE架构的路由开销,实现更优的帕累托前沿。
- 我们系统分析了影响嵌入扩展效能的架构因素——包括参数预算、词汇表大小、初始化方式及其与模型宽度和深度的交互——并确定N-gram嵌入在各种配置下是最稳健的策略。
- 通过集成推测解码及定制系统优化(如N-gram缓存与同步内核),我们将嵌入稀疏性转化为可测量的推理加速,验证了LongCat-Flash-Lite(685亿参数,激活参数约30亿)优于MoE基线模型,并在代理和编程任务中表现突出。
引言
作者采用嵌入扩展作为MoE的替代方案,用于扩展大语言模型的稀疏参数,以解决专家扩展带来的收益递减和系统瓶颈问题。先前研究较少探索嵌入扩展与专家扩展在效率上的对比、宽度/深度/词汇表大小等架构选择如何影响其性能,以及如何优化嵌入扩展后的推理效率。本文的主要贡献是一个系统性框架,识别嵌入扩展优于专家扩展的场景,刻画关键架构权衡,并引入系统级优化(包括推测解码与定制内核),将稀疏嵌入优势转化为实际推理加速。我们通过LongCat-Flash-Lite(685亿参数,其中嵌入层占300亿+参数)验证了该框架,该模型优于MoE基线,并在代理与编程任务中可与更大模型竞争。
方法
作者采用一种新颖的N-gram嵌入架构,在保持计算与内存效率的同时高效扩展模型参数。该框架集成基础嵌入表与扩展的n-gram嵌入分支,实现无需词汇表的token序列表示。基础嵌入分支使用标准嵌入表 E0 将单个token映射为嵌入向量。并行地,N-gram嵌入分支处理最大阶数为 N 的token序列,使用哈希函数将n-gram映射到子表。对于每个token ti,增强嵌入 ei 由基础嵌入与2至 N 阶n-gram嵌入贡献的加权平均计算得出。每个n-gram嵌入进一步分解为 K 个子表,每个子表 En,k 维度降低,并通过线性投影矩阵 Wn,k 投影回完整嵌入空间。此设计确保总参数量与 N 和 K 无关,同时增强模型表达能力并减少哈希冲突。
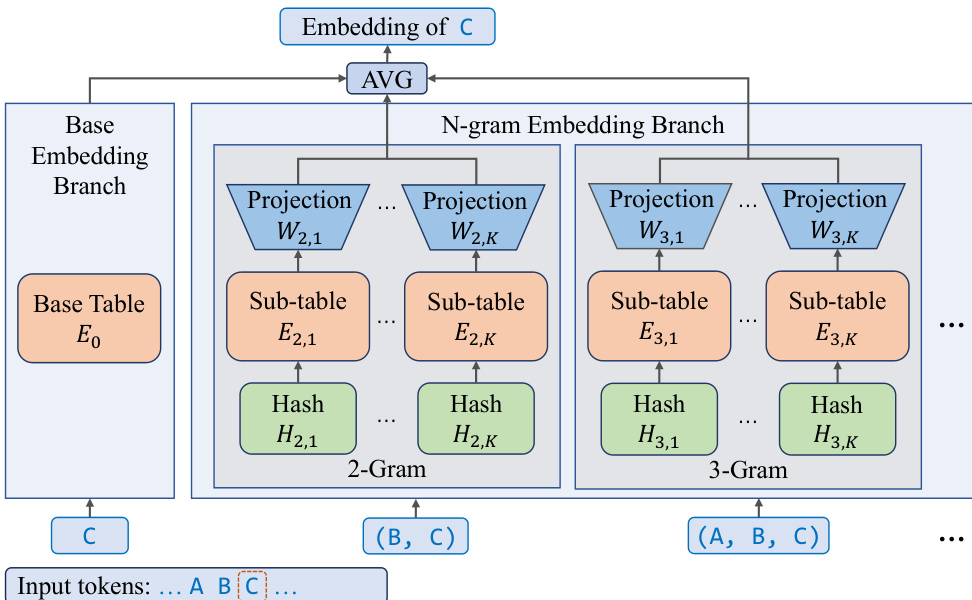
N-gram嵌入机制将参数从MoE层重分配至嵌入空间,减少推理期间激活参数数量。这种架构转变在内存I/O受限的解码场景中尤为有益,允许在不增加MoE层计算负载的前提下使用更大的有效批大小。嵌入层尺寸增加不会影响延迟,因为嵌入查找量随输入token数而非总参数量线性增长。为最大化硬件利用率,模型采用推测解码,有效扩大有效批大小,将参数稀疏性的理论优势转化为实际推理加速。
为应对N-gram嵌入引入的额外开销,作者提出N-gram缓存,一种受KV缓存启发的专用缓存机制。该缓存直接在设备上管理N-gram ID,使用定制CUDA内核实现与推理优化技术的低开销同步。在推测解码场景中,草稿模型层数更少、延迟更低,作者提出两项互补优化:为草稿模型使用常规嵌入层以跳过昂贵的n-gram查找,以及在草稿阶段缓存n-gram嵌入以消除验证阶段的冗余计算。这些优化共同降低延迟并提升推测推理场景的吞吐量。
除硬件效率外,作者还探索N-gram嵌入与推测解码的协同效应。N-gram嵌入结构天然编码丰富的局部上下文与token共现信息,可进一步加速推理。两个有前景的方向被识别:基于N-gram嵌入的草稿生成(将N-gram嵌入重用为超快速草稿模型)和早期拒绝(利用N-gram嵌入表示作为语义一致性检查,提前剪枝低概率草稿token)。这些策略为优化端到端延迟提供了路径。
基于Per-Layer Embedding(PLE)方法,作者提出Per-Layer N-gram Embedding(PLNE),在每层以N-gram嵌入输出替代基础嵌入输出。此扩展在MoE框架内实现更灵活、有针对性的参数扩展。带PLNE的FFN输出形式化为 FFN(l)(xi)=Wd(l)(SiLU(Wα(l)xi(l))⊙ei(l)),其中 ei(l) 根据N-gram嵌入公式计算,使用层特定嵌入表与投影矩阵。该设计允许更精细的参数分配控制,并增强模型捕捉局部上下文的能力。
实验
- N-gram嵌入扩展仅在专家数量超过“甜点”后引入时优于专家扩展,高稀疏度下(如13亿激活参数)表现最佳,可在比例高达50时实现比MoE基线更低的损失。
- 将>50%总参数分配给N-gram嵌入会降低性能;最优分配上限约50%,与同期研究中观察到的U型损失曲线一致。
- N-gram嵌入的词汇表大小应避免为基词汇表大小的整数倍,以最小化哈希冲突,对2-gram哈希尤为关键。
- N-gram阶数N=3–5且子表K≥2时性能接近最优;最小设置(N=2, K=1)显著表现不佳。
- 嵌入放大(通过缩放因子√D或LayerNorm)通过防止残差分支信号抑制,在所有数据划分上降低训练损失0.02。
- 更宽模型(7.9亿–13亿激活参数)扩展了N-gram嵌入的有效窗口,即使在高参数比例下仍保持优势;更深模型(>20层)削弱其相对增益。
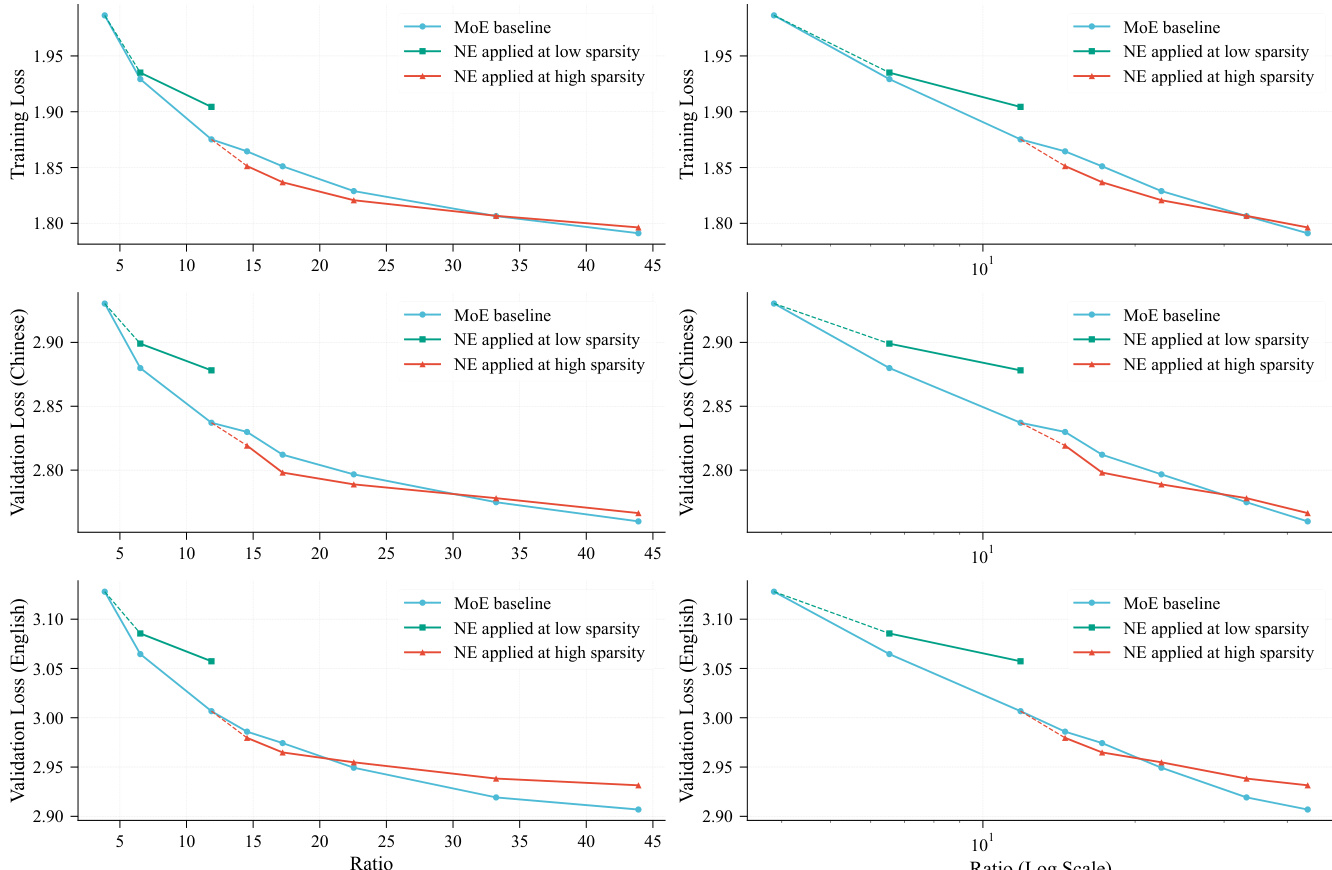
- LongCat-Flash-Lite(增强N-gram嵌入)在MMLU、C-Eval、GSM8K、HumanEval+等基准测试中优于纯MoE基线,验证嵌入扩展的有效性。
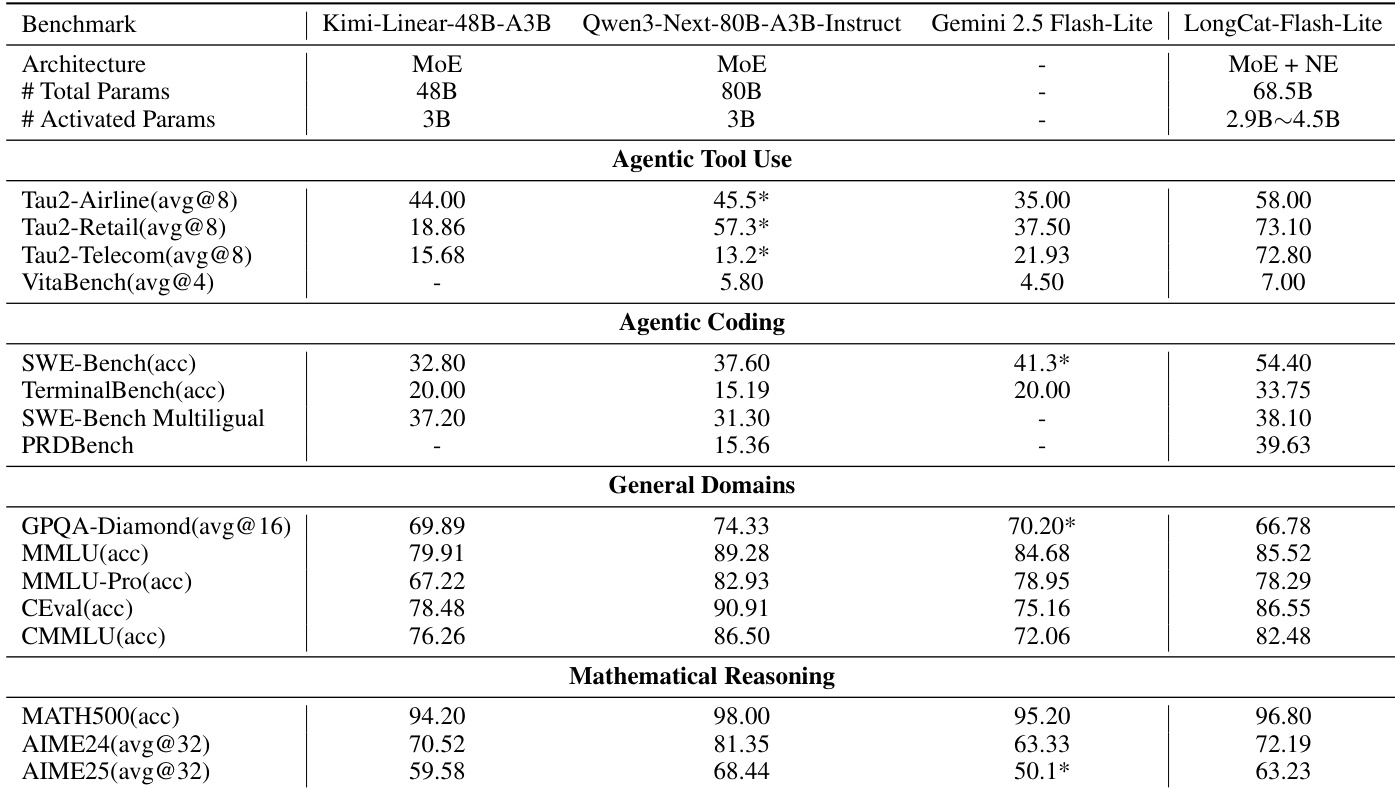
- LongCat-Flash-Lite在代理工具使用(τ²-Bench: 72.8–73.1;VitaBench: 7.00)与编程(SWE-Bench: 54.4;TerminalBench: 33.75)任务中表现优异,超越Qwen3-Next-80B、Gemini 2.5 Flash-Lite及Kimi-Linear-48B-A3B。
- 在数学推理(MATH500: 96.80;AIME24: 72.19)与通用知识(MMLU: 85.52;CEval: 86.55)方面表现强劲,展现参数高效下的广泛能力。
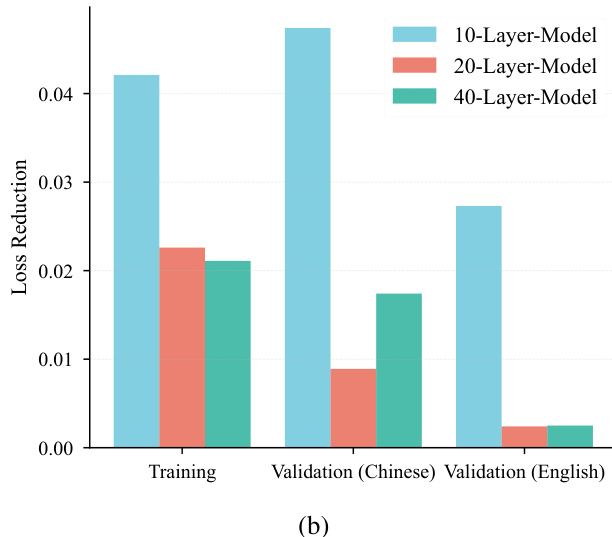
作者使用柱状图比较不同层数(10、20、40层)模型在训练与验证任务中的损失降低情况。结果显示,10层模型在训练与中文验证中损失降低最高,而40层模型在英文验证中表现最佳,表明更深模型可能对某些验证任务更有效。
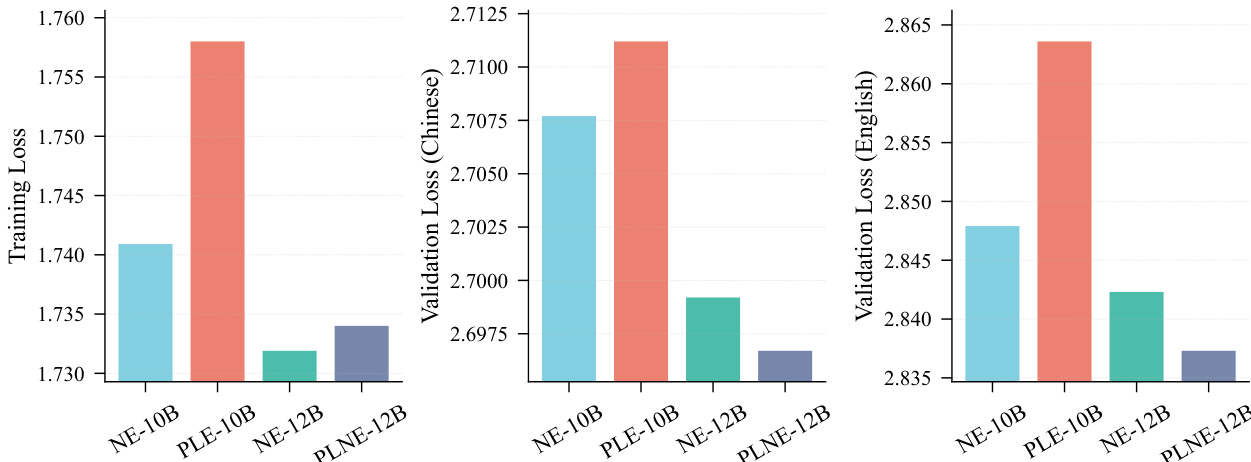
作者比较不同模型变体在训练与验证损失上的表现,显示NE-10B在训练损失上最低,NE-12B在中文与英文验证损失上均最低。结果表明,将模型规模从100亿增至120亿参数可提升验证性能,NE-12B在所有指标上优于PLE-10B与PLNE-12B。
作者比较LongCat-Flash-Lite-Vanilla与LongCat-Flash-Lite模型在多个基准测试中的表现,显示LongCat-Flash-Lite在通用、推理与编程领域多数任务中得分更高。这表明所提出的N-gram嵌入扩展方法优于基线。
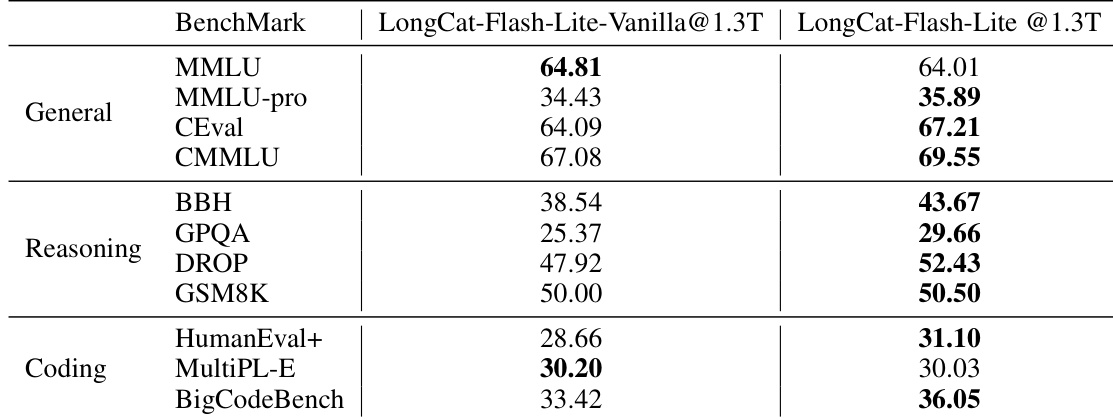
结果表明,N-gram嵌入扩展在高稀疏度下优于专家扩展,但随着参数比例超过某阈值,性能优势逐渐减弱。N-gram嵌入的最佳集成发生在专家数量超过阈值时,其优势在更宽模型中更显著,而更深模型会削弱其相对优势。
作者将采用N-gram嵌入扩展的LongCat-Flash-Lite与多个前沿模型在多能力领域进行对比。结果显示,LongCat-Flash-Lite在代理工具使用与编程任务中表现卓越,超越Qwen3-Next-80B-A3B-Instruct与Gemini 2.5 Flash-Lite等模型,同时在通用知识与数学推理基准中保持竞争力。这表明通过N-gram嵌入扩展总参数可有效增强模型能力,尤其在实际应用场景中。