Command Palette
Search for a command to run...
ASTRA:智能体轨迹与强化环境的自动化合成
ASTRA:智能体轨迹与强化环境的自动化合成
摘要
大型语言模型(LLMs)在多步骤决策任务中日益被用作工具增强型智能体,然而训练鲁棒的工具使用型智能体仍面临诸多挑战。现有方法通常依赖人工干预,依赖不可验证的模拟环境,仅采用监督微调(SFT)或强化学习(RL)中的一种方式,且在长时程、多轮交互学习中难以保持稳定性。为应对上述问题,我们提出 ASTRA——一种全自动化、端到端的框架,通过可扩展的数据合成与可验证的强化学习,实现工具增强型语言模型智能体的训练。ASTRA 集成两个互补的核心组件:其一,基于工具调用图的静态拓扑结构,构建多样化且具有结构性基础的决策轨迹,从而赋予智能体广泛且具备迁移能力的工具使用能力;其二,一种环境合成框架,能够捕捉人类语义推理中丰富的组合性拓扑特征,将分解后的问答轨迹转化为独立、可执行代码且规则可验证的环境,从而支持确定性的多轮强化学习。基于该方法,我们设计了一种统一的训练范式,将监督微调(SFT)与在线强化学习相结合,并引入轨迹级奖励机制,以平衡任务完成度与交互效率。在多个代理型工具使用基准测试中,ASTRA 训练的模型在相近规模下达到了当前最优性能,其表现接近闭源系统,同时保持了核心推理能力。相关完整流程、环境及训练好的模型已开源,详见:https://github.com/LianjiaTech/astra。
一句话总结
贝壳语言与智能团队提出 ASTRA,这是一个通过可扩展数据合成与可验证强化学习全自动训练工具增强型 LLM 代理的框架,支持稳定多轮学习,在代理基准测试中超越先前方法,同时保留核心推理能力。
主要贡献
- ASTRA 引入了一个全自动框架,通过从工具调用图拓扑结构合成多轮轨迹,并将问答轨迹转换为规则可验证、代码可执行的环境,从而训练工具增强型 LLM 代理,消除人工干预并实现确定性强化学习。
- 该方法结合监督微调与在线多轮强化学习,使用轨迹级奖励联合优化任务完成率与交互效率,克服单一训练模式的局限性,提升长时程决策稳定性。
- 在包括 BFCL v3 在内的代理基准测试中评估,ASTRA 训练的模型在相近规模下达到最先进性能,可媲美闭源系统,同时保持核心推理能力,所有流水线与模型均已公开发布。
引言
作者将大型语言模型作为工具增强型代理用于多步决策,这一能力对数据分析和交互系统等现实应用至关重要。先前方法依赖不可验证的模拟环境、碎片化的单步训练,或仅使用监督微调或强化学习——限制了稳定、长时程学习与泛化能力。ASTRA 引入一个全自动框架,通过工具调用图合成多轮、结构化轨迹用于监督训练,并从人类推理轨迹生成代码可执行、规则可验证的环境,以支持确定性多轮强化学习。其统一训练方法结合 SFT 与在线 RL,使用轨迹级奖励,实现最先进性能,同时保留核心推理能力,支持可扩展、可复现的代理开发。
数据集

作者使用精心构建的数据集训练和评估工具使用型 LLM,数据源自异构工具文档与合成用户任务。其结构与处理方式如下:
-
数据集构成与来源
工具文档收集自开源 MCP 注册表(如 Smithery、RapidAPI)、内部规范与公开数据集。这些文档被规范化为统一的 OpenAI 风格工具调用模式,并按服务分组(称为“MCP 服务器”)。仅 1,585 个服务器(涵盖 41 个领域共 19,036 个工具)通过筛选,满足工具数量充足、描述清晰、模式兼容等条件。 -
任务构建与增强
对每个服务器,任务通过两种模式合成:- 链式条件生成:生成符合可执行多步工具工作流的任务。
- 仅服务器模式:仅从服务器规范生成任务,以扩大覆盖范围。
增强沿三个维度扩展任务:多样性(改写)、复杂度(添加约束)、角色(用户风格变化),同时保留语言与意图。任务按清晰度、真实性和工具必要性评分——仅满足所有阈值的任务被保留。
-
SFT 数据集
包含 54,885 个多轮对话(总计 580,983 条消息),平均每样本 10.59 条消息、4.42 次工具调用。72.2% 的样本包含 1–5 次工具调用。工具响应与助手回复占主导(41.8% 和 39.3%)。覆盖 6,765 个独特函数,涵盖推理、搜索与计算。 -
RL 数据集
包含 6,596 个双语样本(71.2% 英文,28.8% 中文),涵盖房地产(15.6%)、电商(10.6%)、医疗(8.1%)等领域。平均 4.37 个推理步骤(中位数 4.0),47.8% 为并行多跳场景。28,794 个子问题中 91.3% 需调用工具;平均每样本 3.98 次工具调用。44.2% 的步骤可并行化。 -
处理与元数据
任务通过结构化模板生成,指定领域、知识库与跳数约束(最小/最大)。场景遵循四种逻辑结构:单跳、并行单跳、多跳、并行多跳。所有样本在纳入前均经过质量、真实性和工具依赖性筛选。
方法
作者采用双轨方法合成工具增强型代理训练数据:一轨用于监督微调(SFT)通过轨迹生成,另一轨用于强化学习(RL)通过可验证环境构建。每轨由不同的架构组件与验证机制支撑,确保真实性、多样性与可执行性。
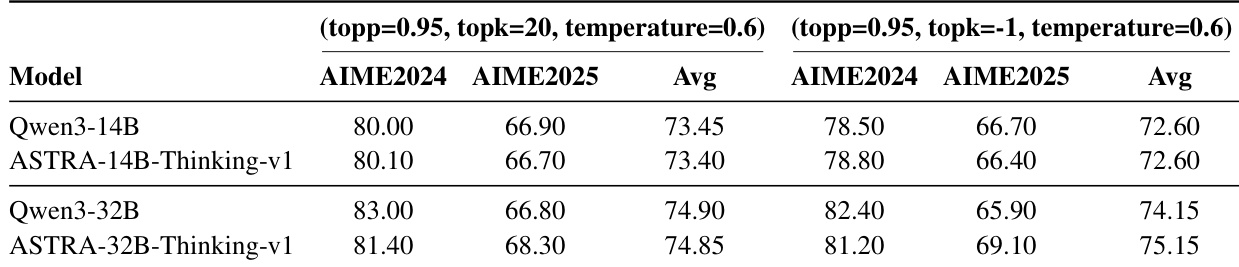
对于 SFT,流程始于工具文档收集与规范化,随后进行工具链合成与验证。如框架图所示,流程分为五个顺序阶段。第一阶段从原始工具规范中过滤合格文档,提取函数名与参数模式。第二阶段从合成工具链构建有向转移图,节点代表工具,边表示合法的连续调用。候选链通过图上长度受限的随机游走采样,边权重由先前合成频率决定。第三阶段使用 LLM 生成与这些链配对的任务条件查询,演化出合理用户意图并验证其连贯性。第四阶段使用 Qwen-Agent 执行多轮交互,整合真实 MCP 服务器与状态模拟器(用于仅文档工具)。模拟器注入 20% 故障率以模拟现实不可靠性。最后,第五阶段应用多维奖励模型,从七个维度评估轨迹质量:查询理解、规划、工具响应上下文理解、工具响应上下文条件规划、工具调用状态、工具简洁性、最终答案质量。这些分数平均为单一标量奖励,用于生成 SFT 信号。
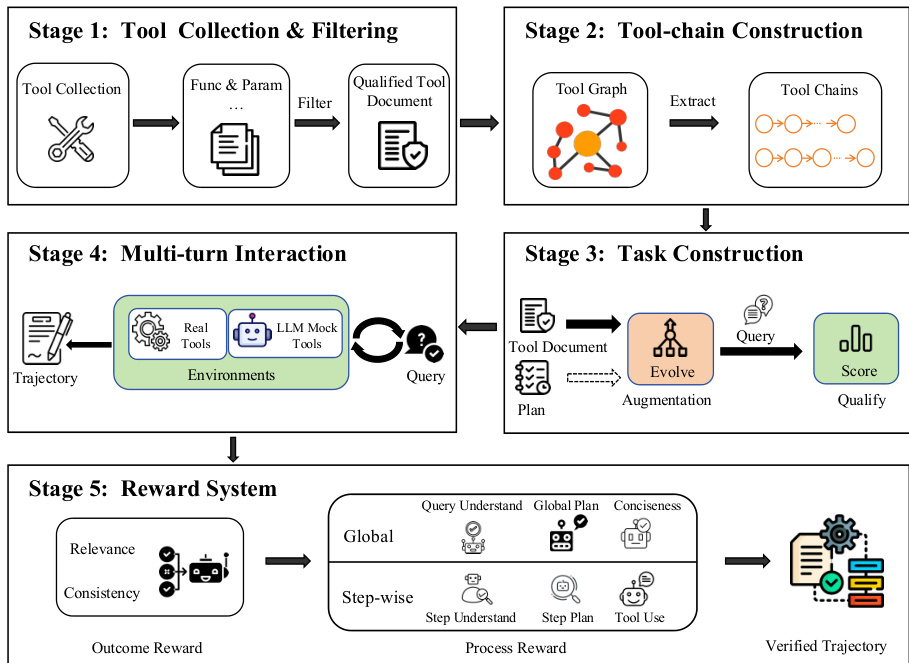
对于 RL,作者采用基于问答的环境合成框架,将多轮工具使用建模为在潜在语义拓扑上的导航。如下图所示,流程包含四个阶段:问答实例合成、质量验证、环境合成、子环境合并。第一阶段,系统生成主问题 q0 及其答案 a0,以及一组中间子问题 S={(qi,ai)}i=1m,形成依赖图 G,使得 a0=Φ({ai},G)。合成以知识源 K 和跳数预算 H 为条件,可在问题条件或无条件模式下运行。第二阶段从四个维度验证每个分解实例:依赖一致性(确保每个子问题依赖逻辑必要)、子问题原子性(验证不可再分)、顺序合理性(检查执行顺序有效性)、任务完整性(确认足以解决 q0)。整体质量评分 QS(τ) 为这四个二元指标的平均值。第三阶段为每个非叶节点子任务合成可执行子环境,生成工具规范、增强其复杂度、实现经沙盒验证的 Python 工具代码。第四阶段通过识别同质子问题并扩展其底层数据结构以支持多参数变体,合并功能等价的子环境,同时保持正确性。
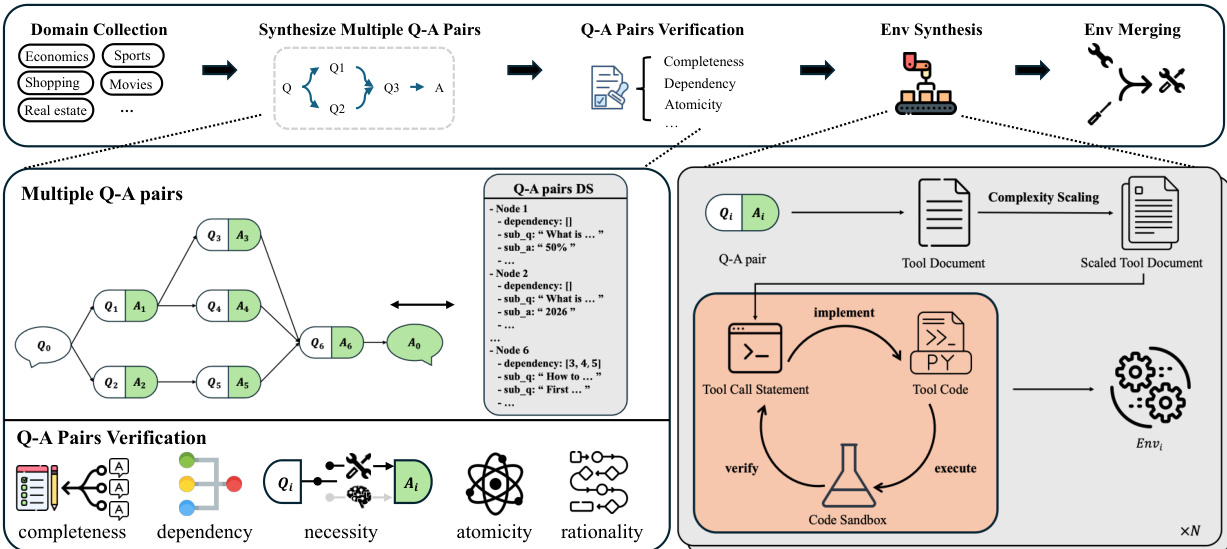
RL 训练基础设施实现在线、多轮代理范式。每一步,策略模型生成工具调用语句,在代码沙盒中与其对应工具实现一同执行。沙盒返回工具输出,作为观察反馈以条件化后续决策。当达到最大轮次、序列长度或模型停止调用工具时,交互终止。所得轨迹通过修改的 GRPO 目标进行策略优化,省略 KL 与熵项以提升稳定性。为缓解退化奖励方差导致的训练不稳定,作者引入自适应批量填充:维护一个有效 rollout 缓冲区(具有非零奖励方差),每优化步骤选择前 n 个有效样本,确保密集梯度信号。奖励函数采用 F1 风格,定义为子任务召回率 r=n^/n 与工具使用精确率 p=n^/(c+ϵ) 的调和平均,其中 n^ 为解决的子任务数,c 为总工具调用数。该设计激励任务完成与交互效率。
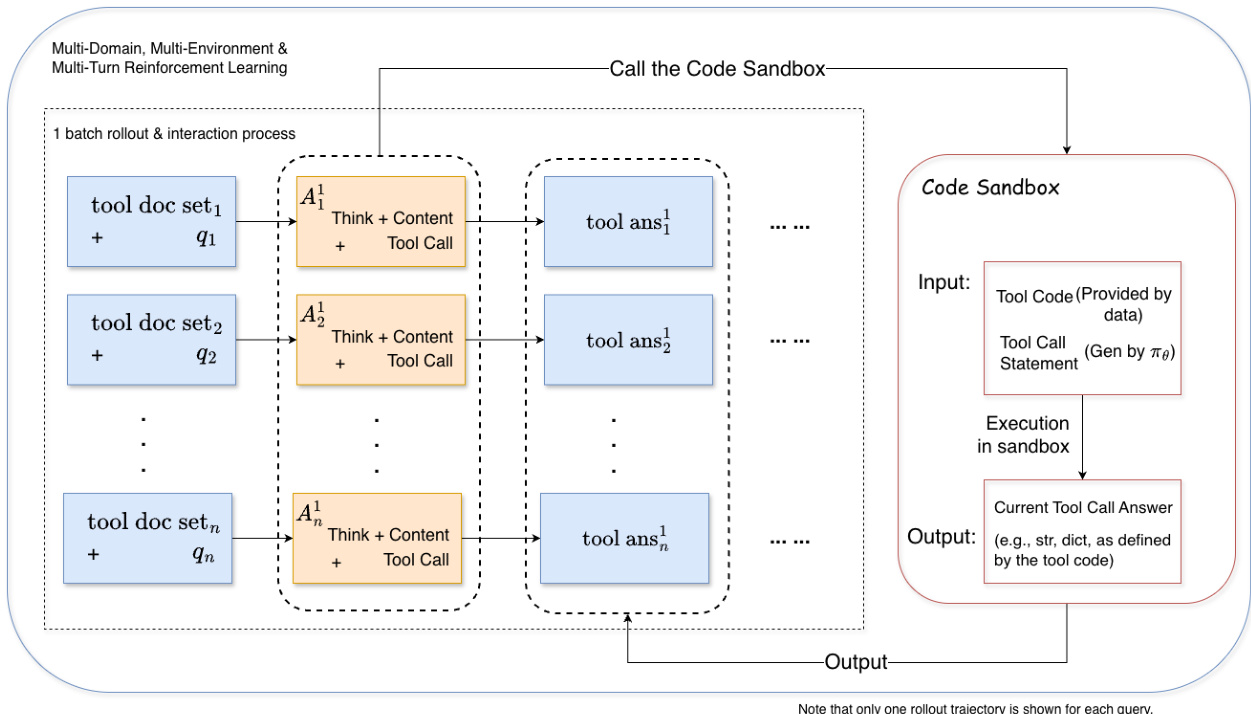
为增强鲁棒性,作者为每个训练实例增强任务无关工具,从工具文档嵌入的余弦相似度衍生的三个语义相似度带(高、中、低)中采样。这鼓励模型区分相关工具而非过拟合最小集合。训练在严格在线环境中进行,批大小 256,学习率固定为 2×10−6,支持长上下文(25,600 token 提示,49,152 token 响应),以适应多轮交互。
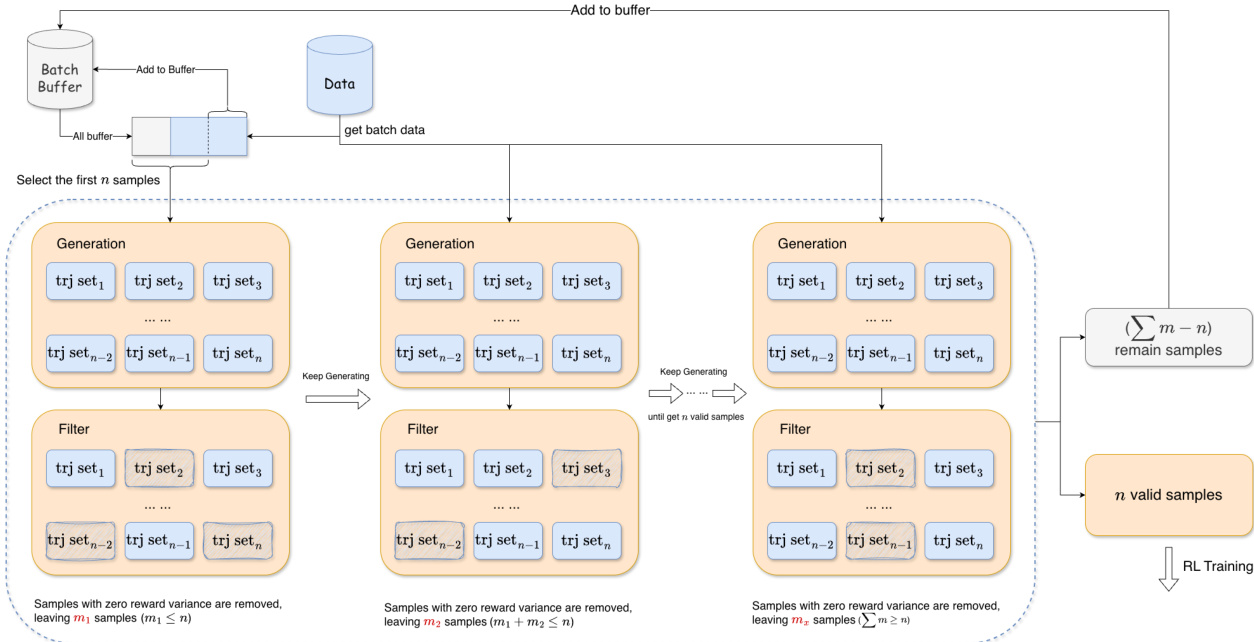
SFT 基础设施在 HuggingFace Transformers 中采用修改的检查点策略,以减少 I/O 与存储开销:模型权重高频保存,而训练状态检查点(优化器、调度器)仅保留最近 1–2 个。这在不损害可扩展性的同时保留细粒度可观测性用于分析。
实验
- 使用上下文并行训练 Qwen3-14B 和 Qwen3-32B,通过 SFT 与 RL 处理长序列;使用带预热的余弦学习率调度。
- 在需要多轮工具使用与用户模拟的代理基准测试(BFCL-MT、τ²-Bench、ACEBench)以及非代理数学基准测试(AIME2024/2025)上评估,以检验核心推理能力。
- 在各模型规模上取得最先进或具竞争力的结果;RL 阶段相比 SFT 与原始模型带来最大性能提升。
- RL 期间混合无关工具通过迫使模型拒绝错误选项提升工具判别能力,平衡相似度覆盖效果最佳。
- F1 风格奖励(平衡召回率与精确率)稳定训练,防止工具过度或不足使用;仅召回或仅精确率奖励导致训练崩溃。
- SFT 改善结构化工具使用与状态跟踪;RL 通过子问答监督支持更广泛探索,支持从次优决策中恢复。
- 输出长度在 SFT 后减少,RL 后适度增加;各阶段交互步骤保持稳定,表明性能提升并非源于长度变化。
- 方法在非代理任务上保持强大推理能力,同时增强代理工具使用能力。
作者采用两阶段训练方法——监督微调后接强化学习——以增强 Qwen3 模型的工具使用能力,RL 在代理基准测试中带来最大性能提升。结果表明在多轮工具交互与任务完成上持续改进,同时在非代理推理任务上保持强大表现。最终 RL 训练模型优于其基线与 SFT 版本,在匹配参数规模下达到最先进或具竞争力的表现,超越更大规模开源与闭源模型。
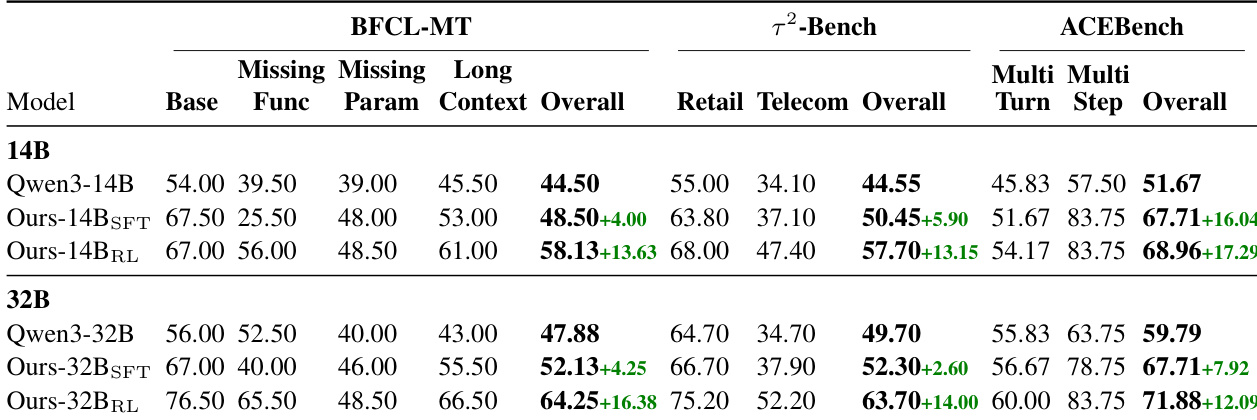
作者观察到,尽管微调阶段未显著改变每子任务平均交互步骤数,但大幅减少每步 token 使用量,RL 阶段输出长度介于原始与 SFT 模型之间。这表明性能提升源于更高效的推理与工具使用模式,而非对话深度变化。RL 训练模型每子任务保持比基线模型更高的 token 效率,表明在不牺牲任务覆盖的前提下提升简洁性。
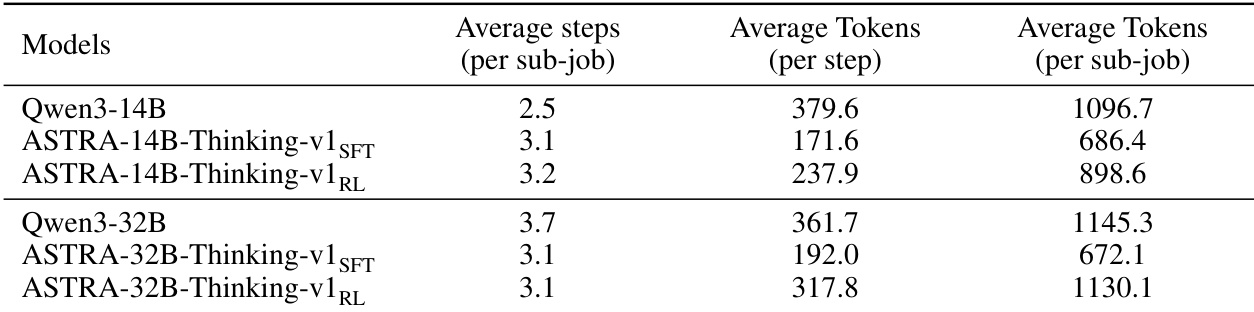
作者采用结合监督微调与强化学习的两阶段训练方法,增强 Qwen3 模型的代理工具使用能力。结果表明,其方法在匹配参数规模下,在多轮工具使用基准测试中达到最先进性能,强化学习带来最大性能提升。该方法同时在非代理推理任务上保持强大表现,表明工具使用优化未损害核心推理能力。
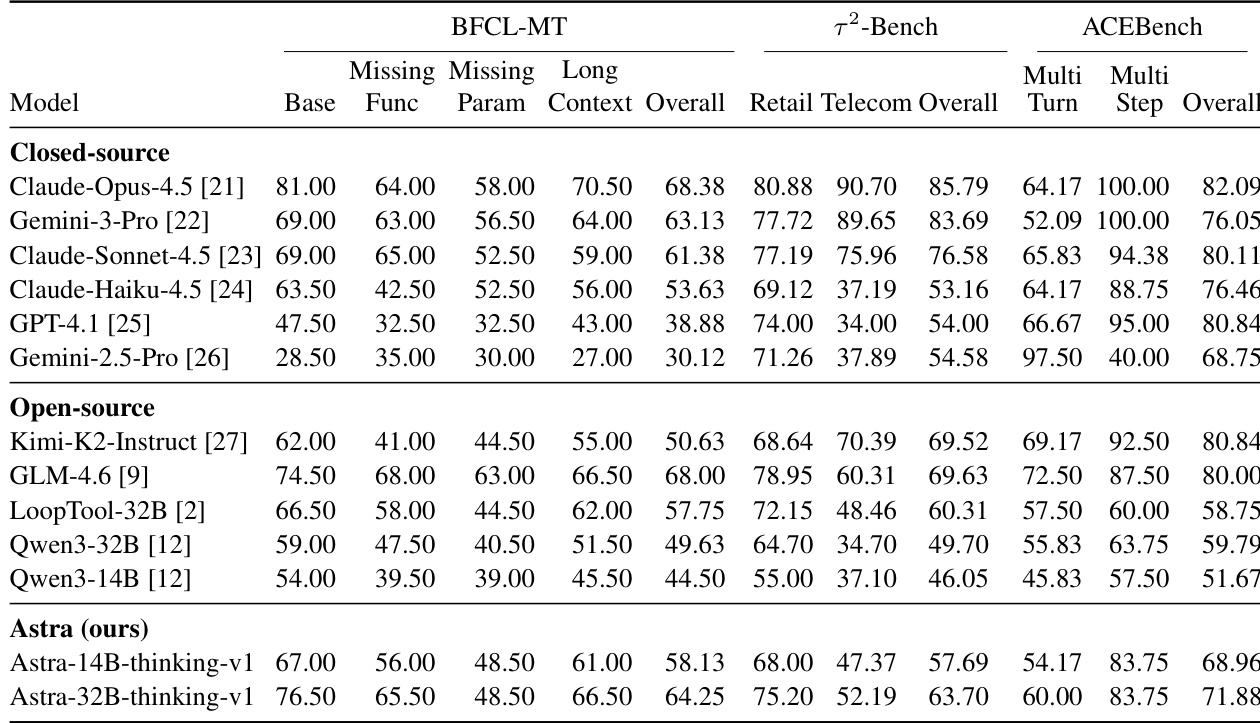
作者在非代理数学推理基准测试 AIME2024 和 AIME2025 上评估其 ASTRA 模型,采用两种解码设置,显示训练后性能保持稳定或略有提升,尽管聚焦代理工具使用但无显著退化。结果表明,32B 版本始终优于 14B 版本,且两个 ASTRA 版本在两种解码配置下均保持具竞争力的分数。