Command Palette
Search for a command to run...
Vision-DeepResearch:在多模态大语言模型中激励深度研究能力
Vision-DeepResearch:在多模态大语言模型中激励深度研究能力
摘要
多模态大语言模型(MLLMs)在众多视觉任务中已取得显著进展。然而,受限于其内部世界知识的容量,先前的研究通过引入“先推理、后调用工具”的范式,结合视觉与文本搜索引擎,以在需要大量事实信息的任务中实现显著性能提升。然而,这些方法通常在一种过于简化的设定下定义多模态搜索,假设仅需一个完整层级或实体层级的图像查询,辅以少量文本查询,即可获取回答问题所需的关键证据。这种假设在现实场景中难以成立,尤其当面对大量视觉噪声时更为不切实际。此外,这些方法在推理深度和搜索广度上往往受限,难以应对需要从多样化的视觉与文本来源中整合证据的复杂问题。基于上述挑战,我们提出 Vision-DeepResearch,一种全新的多模态深度研究范式。该方法通过多轮次、多实体、多尺度的视觉与文本搜索,有效应对现实世界中噪声严重的搜索引擎,提升检索的鲁棒性。Vision-DeepResearch 支持数十个推理步骤与数百次搜索引擎交互,并通过冷启动监督与强化学习(RL)训练,将深度研究能力内化至 MLLM 中,从而构建出一个强大的端到端多模态深度研究型 MLLM。实验结果表明,该模型显著优于现有的多模态深度研究 MLLM,以及基于强大闭源基础模型(如 GPT-5、Gemini-2.5-Pro 和 Claude-4-Sonnet)构建的各类工作流。相关代码将开源至:https://github.com/Osilly/Vision-DeepResearch。
一句话总结
来自港中文 MMLab、中国科大及合作团队的研究人员提出了 Vision-DeepResearch,这是一种新型多模态范式,通过使用 SFT 和 RL 训练的深度推理 MLLM,支持多轮、多实体、多尺度搜索,在嘈杂的真实世界图像检索任务中以更少参数超越 GPT-5 和 Gemini-2.5-pro。
主要贡献
- Vision-DeepResearch 引入了一种新的多模态深度研究范式,通过多轮、多实体和多尺度的视觉与文本搜索,克服了嘈杂真实世界搜索引擎中命中率低的问题,而先前方法依赖于简单的全图或单实体查询。
- 该框架通过冷启动监督微调和强化学习,将深度研究能力内化到 MLLM 中,支持数十步推理和数百次引擎交互,显著扩展了推理深度和搜索广度,超越现有方法。
- 在六个基准测试中评估,Vision-DeepResearch 以更小的模型(8B 和 30B-A3B 规模)实现最先进性能,优于开源多模态深度研究 MLLM 以及基于 GPT-5、Gemini-2.5-pro 和 Claude-4-Sonnet 等闭源模型构建的工作流。
引言
作者利用多模态大语言模型(MLLM)解决复杂、事实密集型视觉问答问题,通过赋予其超越单次查询、单尺度检索的深度研究能力。先前方法将视觉搜索视为一次性操作,使用全图或实体级查询,忽略了真实世界中的噪声和搜索引擎的变异性,导致命中率低、推理浅薄。它们还限制训练轨迹长度,使模型无法执行迭代式、多步骤的证据收集。作者的主要贡献是 Vision-DeepResearch,这是一种新范式,综合了长视野、多轮次、涉及多实体和多尺度视觉与文本搜索的轨迹。通过冷启动监督和 RL 训练,他们使 MLLM 能够执行数十步推理和数百次引擎交互,在六个基准测试中达到最先进结果——甚至优于基于 GPT-5 和 Gemini-2.5-Pro 等闭源模型构建的代理工作流。
数据集

-
作者使用从多个开源数据集中精心挑选的真实世界高质量图像,过滤掉小于 224×224 像素的图像。他们应用 MLLM 选择视觉复杂、非平凡的图像,并剔除无需外部证据即可回答或通过图像搜索可精确匹配的图像。
-
从保留的图像中,他们生成“模糊多跳 VQA”实例:首先提示 MLLM 提出实体级边界框,然后在多个尺度上裁剪区域,并通过图像搜索验证实体一致性。生成实体级问题(例如“这只猫叫什么名字?”),然后通过两种技术刻意模糊化:(1)答案链式推理以加深推理深度,(2)通过网页随机游走进行实体替换以模拟多跳知识。这些方法交错使用,以避免模板化或捷径依赖模式。
-
最终合成流水线模拟人类问题设计:提取关键词,检索外部证据,生成多个候选问题,并通过评判 MLLM 选择最佳问题。这产生复杂、真实的 VQA 问题及其答案,用于轨迹合成和 RL 训练。
-
对于监督微调(SFT),作者构建了 30K 高质量多模态深度研究轨迹:16K 来自经验证的事实导向 VQA 问题(增强轨迹),8K 纯文本 QA 轨迹,6K 模糊 VQA 轨迹。全部使用自回归交叉熵损失训练,以教授多轮、多尺度、跨模态推理与规划。
-
对于 RL 训练,他们使用 15K 经验证的 VQA 实例,通过与实时搜索环境交互采样轨迹。奖励由 LLM 作为评判者计算,评估答案正确性和是否符合 ReAct 格式,使用 rllm 框架优化。
-
训练数据使用 Ms-Swift 进行 SFT,rllm 进行 RL,应用于 Qwen3-VL-30B 和 Qwen3-VL-8B 模型。流水线强调视觉裁剪、外部搜索和长视野推理行为,评估涵盖六个基准,包括 VDR-Bench、FVQA 和 BC-VL。
方法
作者利用高度自动化的数据流水线构建长视野多模态深度研究轨迹,使他们的 Vision-DeepResearch 代理能够在嘈杂的网络环境中执行复杂的视觉-语言推理。该流水线将视觉搜索与基于文本的推理相结合,通过图像描述衔接,分为两个主要阶段:视觉证据收集和基于文本的深度研究扩展。
如下图所示,流程始于输入图像和问题。模型首先生成推理步骤,并通过多实体、多尺度裁剪定位相关区域,生成一组边界框 Sb={Ib1,…,Ibn}。每个裁剪触发视觉动作 At=Tool-Call(Sbt),提交至视觉搜索工具流水线。流水线返回观察结果 Otv,累积为视觉证据 Vtv={O1,…,Otv}。该序列包括三个顺序工具:视觉搜索(检索 URL)、网站访问(获取 Markdown 内容)和网站摘要(提取相关文本并过滤噪声)。
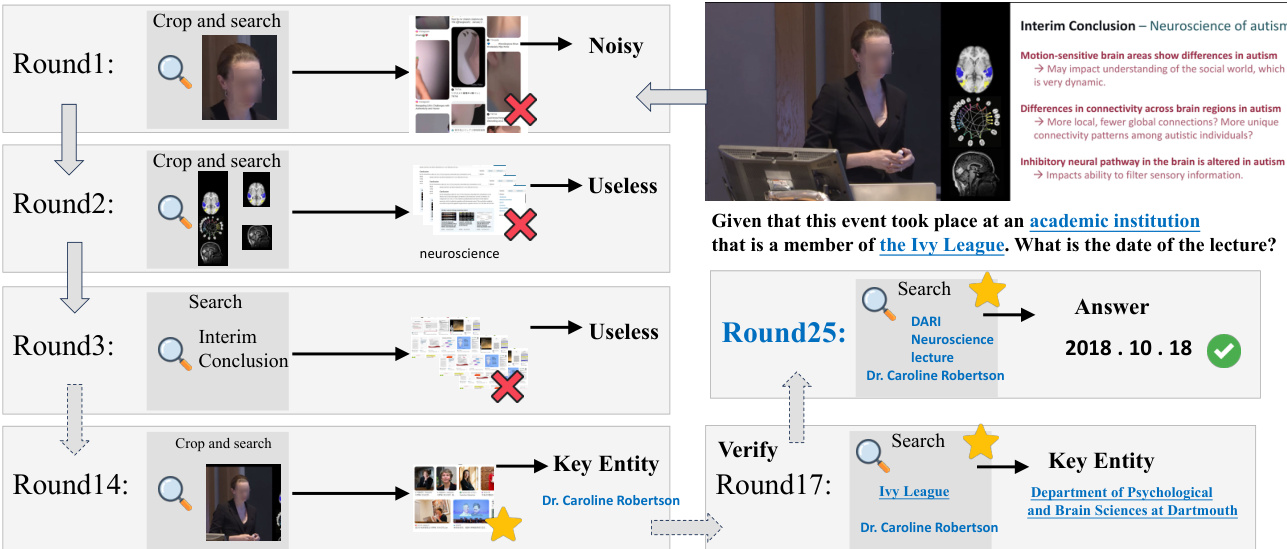
为控制搜索深度,外部评判模型评估累积证据 Vtv 是否足以支持下游推理,输出二元命中信号 htv=Judge(I,q,Vtv,atrue)∈{0,1}。若 htv=0,流水线继续;若 htv=1,视觉阶段在步骤 Tv 终止。所得视觉轨迹记为 Cvision={I,q,pv,R1,A1,O1,…,pv,RTv,ATv,OTv}。
然后,作者通过将原始图像 I 替换为详细文本描述 D,同时保留推理、动作和观察,将此视觉轨迹桥接至文本。此桥接上下文输入基于文本的深度研究基础 LLM,其使用工具(如网络搜索、网站访问与摘要、Python 代码执行)扩展轨迹。文本轨迹记为 Ctext={D,q,R1,A1,O1,…,RTv,ATv,OTv,pt,RTv+1,ATv+1,OTv+1,…,RTv+Tt,ATv+Tt,aoutput},其中 Tt 为文本步骤数,aoutput 为最终答案。
完整多模态轨迹 Cmultimodal 合并两个阶段,并进行拒绝采样:LLM 验证 aoutput 是否匹配真实答案 atrue,仅保留一致轨迹用于训练。作者还纳入直接从原始问题生成的纯文本轨迹。
训练时,作者结合监督微调(SFT)与强化学习(RL)。RL 阶段采用基于 rLLM 框架构建的高吞吐异步展开架构,支持并发工具调用,吞吐量比同步方法高 10 倍以上。训练使用组相对策略优化(GRPO)和留一法技巧,应用于 15K 高质量 VQA 实例。模型与真实在线搜索环境交互,采样长视野轨迹,限制为最多 50 轮、每轮 64K 上下文令牌和 4K 响应令牌。
奖励通过 LLM 作为评判者范式确定:若最终答案正确则奖励为 1.0,否则为 0.0。为确保训练稳定性,作者实施多项工程保障:重复文本或级联工具调用失败时中断轨迹、屏蔽异常轨迹不参与梯度更新、使用 BF16 精度训练以避免长上下文数值溢出。
请参阅框架图,了解端到端 Vision-DeepResearch 范式的概览,包括事实 VQA 合成、多轮轨迹生成和长视野 ReAct 风格推理循环的集成。
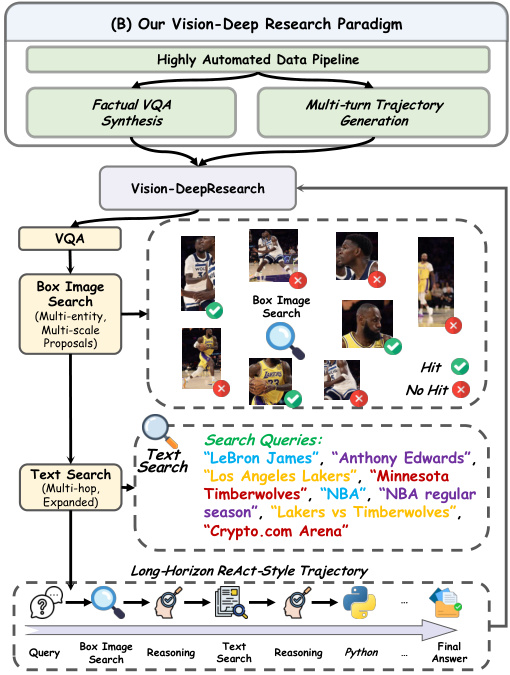
最终训练数据包括多模态轨迹和纯文本深度研究轨迹,使代理能够在不同模态间泛化,并在复杂真实世界网络环境中执行稳健的长视野推理。
实验
- 我们的方法在多模态深度研究任务上超越现有开源模型,并与强大的专有系统媲美,尤其在结合推理与工具使用的代理工作流中表现突出。
- 消融研究证实,多尺度视觉裁剪和文本搜索共同至关重要:裁剪提升对象级定位,文本搜索提供缺失的事实背景,共同实现跨基准的平衡性能。
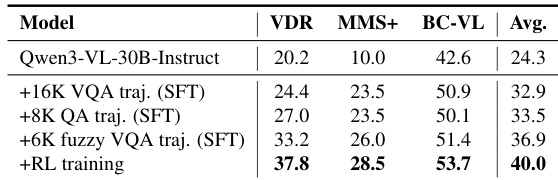
- 数据消融显示,使用工具增强轨迹的监督微调显著提升性能,强化学习进一步优化长视野决策,获得最佳综合结果。
- RL 训练在减少轨迹长度的同时提高奖励,表明工具使用更高效,更大规模的 RL 优化有望带来进一步提升。
- 不使用工具直接作答表现不佳,而 ReAct 风格的代理推理始终带来显著改进,验证了复杂多模态任务中迭代证据收集的必要性。
作者使用结合多尺度视觉裁剪与文本搜索的多模态代理框架,显著提升开放域推理性能。结果表明,其方法在代理工作流下优于专有和开源模型,提升源于更好的长视野工具使用行为和证据定位。消融研究证实,视觉定位和文本检索共同必要,强化学习进一步优化决策,超越监督微调。
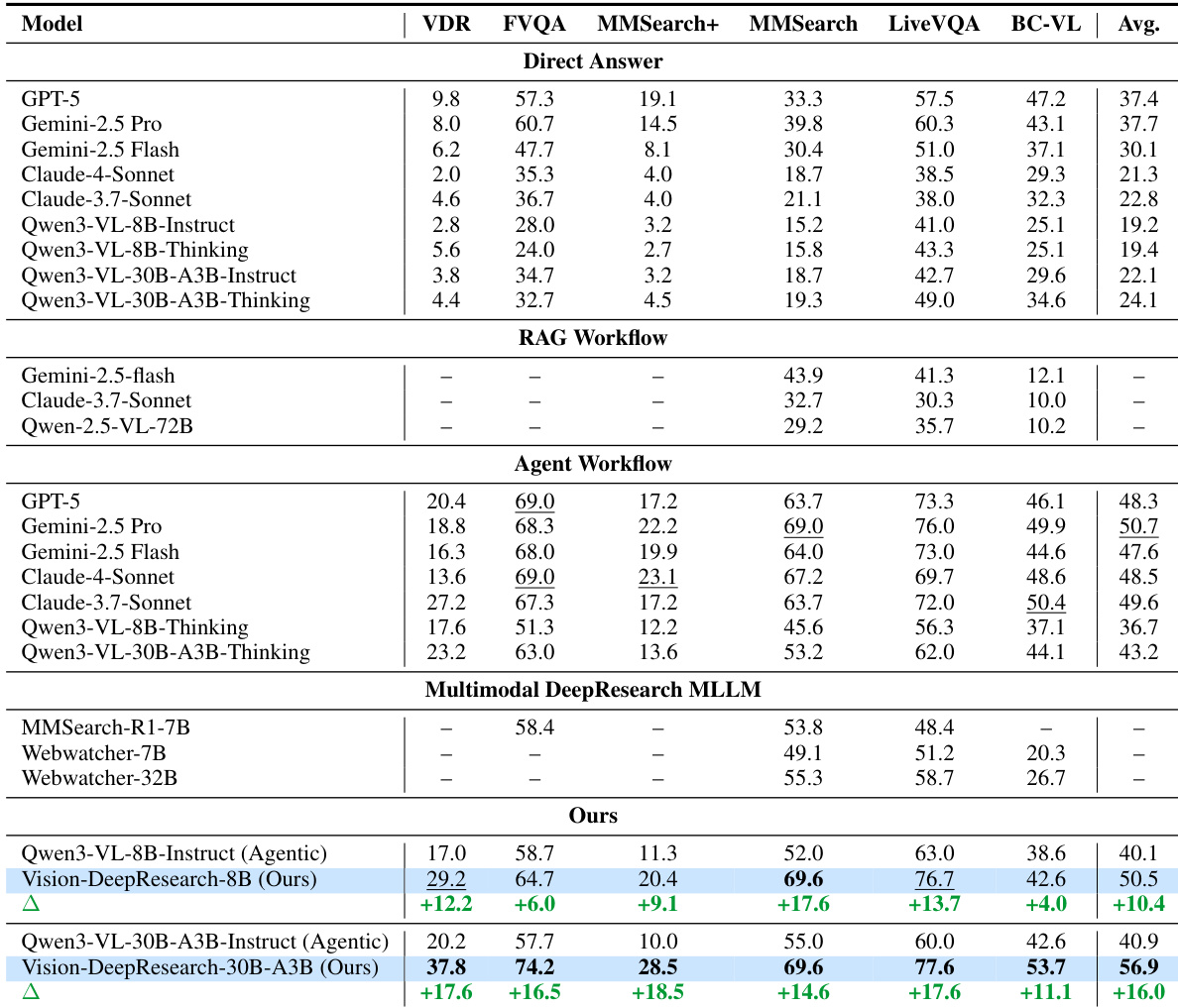
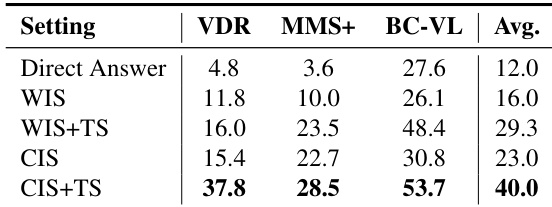
作者评估了多模态推理中的不同检索策略,发现结合多尺度视觉裁剪与文本搜索(CIS+TS)在各基准上表现最强且最均衡。结果表明,仅依赖直接作答或全图搜索会导致效果不佳,而结合局部视觉锚点与文本证据显著提升准确率。这表明有效的多模态推理需要精确的视觉定位和互补的事实检索。
作者结合使用工具增强轨迹的监督微调与强化学习,显著提升多模态推理性能。结果表明,加入经验证和模糊的多跳轨迹可提升准确率,而 RL 进一步优化长视野决策,带来跨基准的最佳综合得分。最终模型显著优于基线版本,证明了迭代工具使用和奖励驱动优化的价值。