Command Palette
Search for a command to run...
TTCS:用于自演化系统的测试时课程合成
TTCS:用于自演化系统的测试时课程合成
Chengyi Yang Zhishang Xiang Yunbo Tang Zongpei Teng Chengsong Huang Fei Long Yuhan Liu Jinsong Su
摘要
测试时训练(Test-Time Training, TTT)为提升大语言模型(LLMs)的推理能力提供了一条有前景的路径,其核心思想是仅利用测试问题对模型进行自适应调整。然而,现有方法在应对复杂推理任务时面临两大挑战:一是原始测试问题通常过于困难,难以生成高质量的伪标签;二是测试集规模有限,导致持续的在线更新容易引发训练不稳定。为解决上述局限,我们提出TTCS——一种协同演化的测试时训练框架。具体而言,TTCS从同一预训练模型中初始化两个策略:一个问题生成器(question synthesizer)和一个推理求解器(reasoning solver)。这两个策略通过迭代优化不断演化:问题生成器基于测试问题逐步生成更具挑战性的问题变体,构建出与求解器当前能力相匹配的结构化课程;而求解器则通过在原始测试问题与生成的合成问题上采样多个响应,并利用自一致性奖励(self-consistency rewards)进行自我更新。关键在于,求解器的反馈引导生成器产生与其当前能力相契合的问题,而生成的问题变体反过来又增强了求解器在测试时训练过程中的稳定性。实验结果表明,TTCS在具有挑战性的数学推理基准测试中持续提升了模型的推理能力,并在不同大语言模型架构上展现出良好的泛化性,能够有效迁移至通用领域任务。这一成果揭示了一条可扩展的路径,用于动态构建测试时课程,推动模型实现自我演化。我们的代码与实现细节已开源,详见:https://github.com/XMUDeepLIT/TTCS。
一句话总结
来自厦门大学、圣路易斯华盛顿大学和中国人民大学的研究人员提出了 TTCS,这是一种协同演化的测试时训练框架,通过动态生成定制化的问题变体来稳定并增强大语言模型的推理能力,在数学和通用基准测试中通过自洽反馈循环超越了先前方法。
主要贡献
- TTCS 解决了测试时训练在复杂推理任务中的关键局限性,包括不可靠的伪标签和稀疏的可学习样本,这些问题阻碍了在 AIME24 等难题上的有效适应。
- 该框架引入了一对协同演化的策略——一个生成与能力匹配的问题变体的合成器,以及一个通过自洽奖励更新的求解器——通过 GRPO 迭代优化以稳定并引导自我演化。
- 实验表明,TTCS 在多个大语言模型主干上,对具有挑战性的数学基准和通用领域任务均表现出持续提升,验证了其作为测试时动态课程构建的可扩展方法。
引言
作者利用测试时训练在无需外部标签的情况下提升大语言模型的推理能力,但现有方法在难题上因伪标签不可靠和测试样本稀疏且过于困难而失效。先前的方法(如 TTRL)依赖多数投票,当模型表现不佳时往往强化错误答案,且缺乏中间训练步骤来弥合能力差距。TTCS 引入了一个协同演化的框架,包含两个策略——一个生成课程对齐问题变体的合成器,以及一个通过自洽奖励更新的求解器——构建动态、能力匹配的训练循环,以稳定学习并提升在具有挑战性的数学和通用推理任务上的表现。
数据集

作者使用一组多样化的基准测试来评估推理与泛化能力,分为三类:
-
竞赛级数学:
- AMC23:美国数学竞赛问题,用于识别数学人才。
- AIME24&25:2024 和 2025 年美国邀请赛数学考试,因其多步推理需求被选中。
-
标准数学基准:
- MATH-500:MATH 数据集的精选 500 题子集,用于高效评估核心数学解题能力。
- Minerva:涵盖多个难度级别的广泛 STEM 问题集。
- OlympiadBench:来自国际竞赛的综合性奥赛级问题集。
-
通用领域基准:
- BBEH:Big Bench Extra Hard,针对语言模型通常表现不佳的任务。
- MMLU-Pro:强调高级语言理解和推理能力的多任务挑战性基准。
- SuperGPQA:为跨复杂领域扩展大语言模型评估而设计的研究生级别问题。
本文未指定这些数据集的训练划分、混合比例或预处理步骤——它们仅用于评估。未描述裁剪、元数据构建或特定数据集处理。
方法
作者采用一种称为测试时课程合成(TTCS)的协同演化测试时训练框架,该框架集成了两个不同但相互依赖的代理:合成器策略和求解器策略。两个代理均从同一预训练语言模型初始化,并通过基于组相对策略优化(GRPO)的闭环优化过程相互迭代精炼。整体架构旨在通过生成能力对齐的合成问题作为课程变体,动态调整求解器以适应测试分布,同时利用其自身输出派生的自监督信号训练求解器实现自我演化。
如框架图所示,合成器负责根据每个测试问题生成合成问题。这通过结构化提示模板实现,强制保留原始推理结构的语义,同时改变表层元素(如对象、场景或约束)。生成的合成问题随后由求解器评估,求解器为每个问题采样多个响应,并基于多数投票计算自洽得分。该得分作为问题相对于求解器当前能力难度的代理。合成器随后通过 GRPO 更新,使用复合奖励函数,该函数结合了能力自适应分量(在自洽得分接近 0.5 时达到峰值,此时学习信号最大化)和相似性惩罚(防止冗余和近似重复生成)。这确保合成器逐步将其输出分布转向求解器能力前沿的问题,在可学习性与新颖性之间取得平衡。
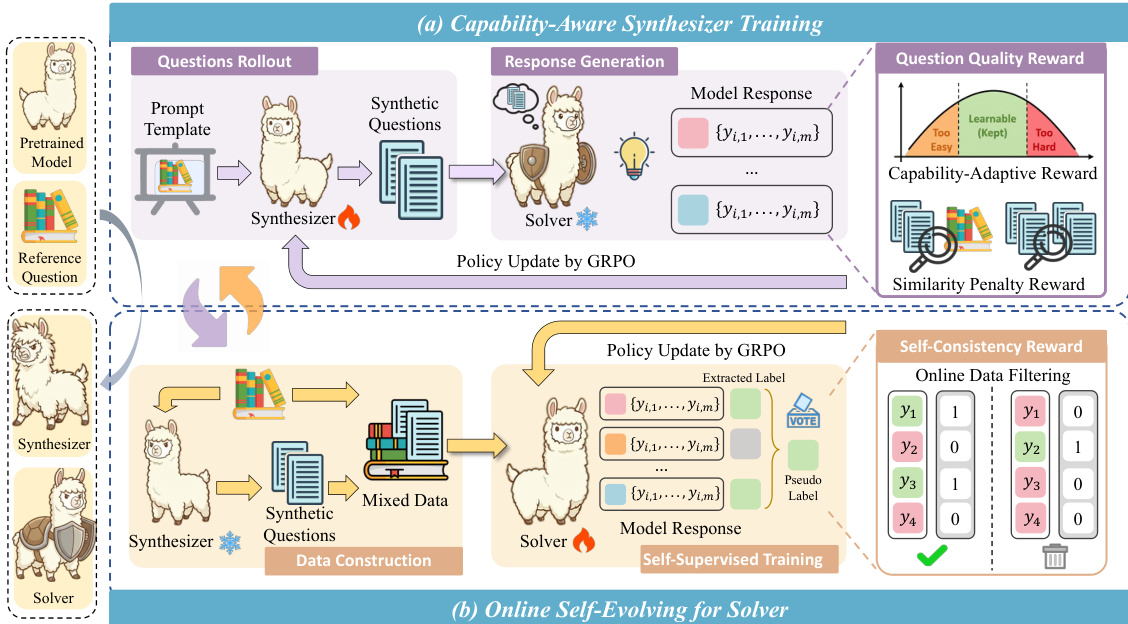
同时,求解器在包含原始测试问题和合成器生成的合成变体的混合数据集上进行训练。在每次迭代中,求解器为每个问题采样多个响应,并通过多数投票派生伪标签。每个响应根据与共识的一致性被赋予二元自洽奖励。为确保训练稳定性并防止退化,一种在线过滤机制仅保留自洽得分在 0.5 附近窄带内的问题,有效选择在 GRPO 下提供最大梯度信号的样本。然后,求解器通过 GRPO 使用这些过滤后的自监督奖励进行更新,使其能够逐步掌握日益复杂的变体,同时保持在原始测试分布内。该过程的迭代性质确保合成器的课程适应求解器不断演变的能力,形成无需真实标签即可推动持续改进的反馈循环。
实验
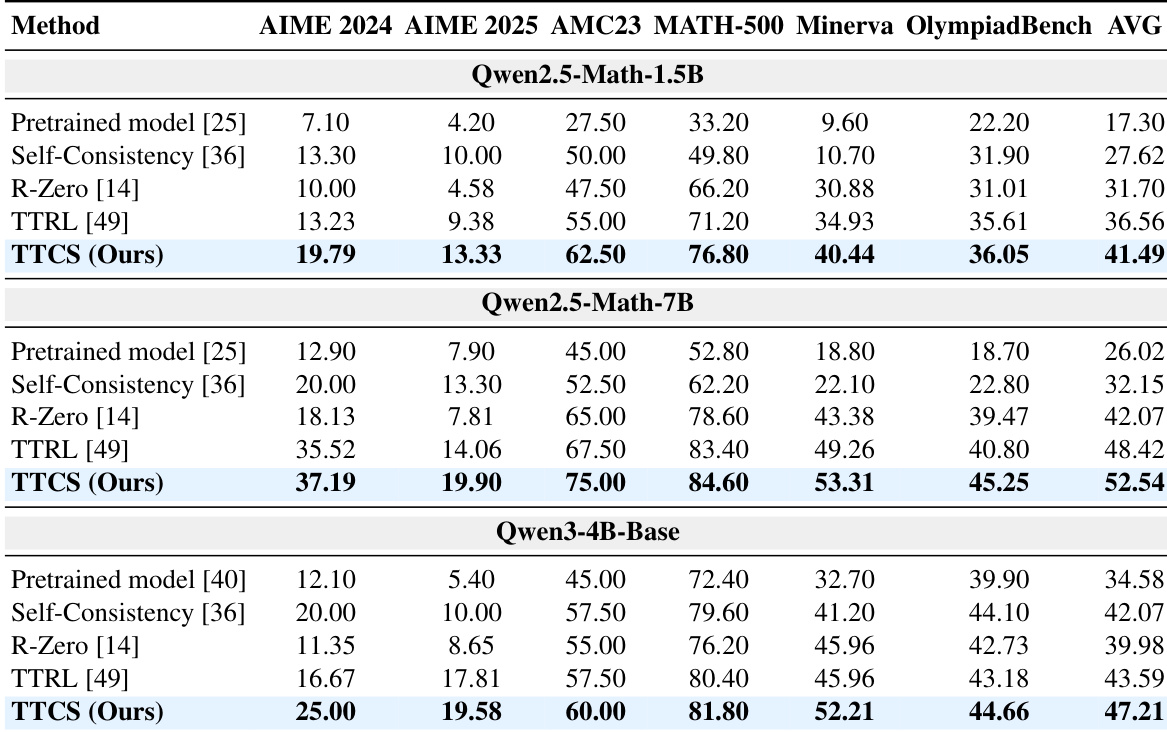
- TTCS 显著提升了数学基准上的推理性能,优于静态模型、自洽方法和测试时训练方法(如 TTRL 和 R-Zero),尤其在 AIME24/25 等挑战性任务上表现突出。
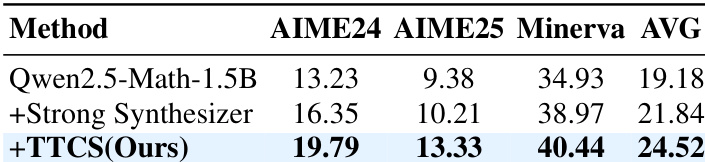
- 该框架的协同演化设计——合成器动态生成课程对齐问题——被证明比使用更强但静态的问题生成器更有效,突显了自适应训练的价值。
- TTCS 在训练域之外泛化良好,提升了通用推理基准(如 MMLU-Pro、SuperGPQA)和未见数学数据集上的性能,表明其获得了可迁移的推理逻辑。
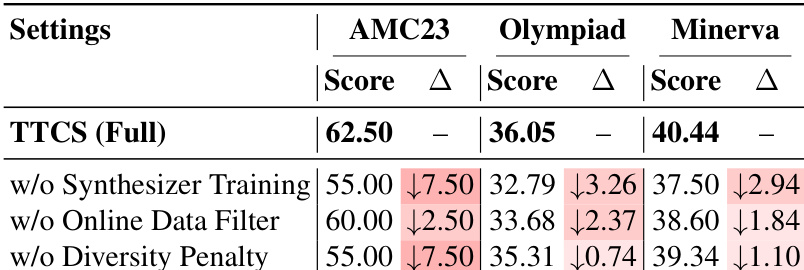
- 消融研究证实,动态合成器训练、在线数据过滤和多样性惩罚对有效自我演化至关重要;移除任何组件都会导致性能下降。
- TTCS 在有限测试数据下仍有效,通过合成课程放大稀疏监督,并在训练迭代中逐步提升问题复杂性和多样性。
作者使用 TTCS 在测试时动态生成课程问题以增强数学推理能力,从而在静态和自洽基线上取得显著性能提升。结果表明,即使从较小模型开始,TTCS 也能通过调整问题难度和多样性以适应求解器不断演变的能力,显著提高 AIME24 和 AIME25 等挑战性基准的准确率。该方法优于更强的静态合成器,证实对于有效的测试时学习,自适应协同演化比原始模型规模更为关键。
作者使用 TTCS 在测试时动态生成和精炼训练问题,使模型能够逐步适应其推理能力。结果表明,移除关键组件(如合成器训练、在线数据过滤或多样性惩罚)在各基准上一致导致性能下降,证实每个元素均对框架有效性有实质贡献。这表明,自适应课程设计和选择性数据整理对于测试时自我演化的持续改进至关重要。
作者使用 TTCS 在测试时动态生成和精炼中间问题,使模型能够逐步超越静态基线提升推理能力。结果表明,在多个模型规模和数学基准上均取得持续且显著的提升,尤其在 AIME 等挑战性任务上,TTCS 优于仅依赖测试集伪标签的方法。该框架的协同演化设计,能实时调整问题难度和多样性,被证明比使用更强但静态的合成器或被动推理时扩展更有效。