Command Palette
Search for a command to run...
PaperBanana:为AI科学家自动化学术插图
PaperBanana:为AI科学家自动化学术插图
Dawei Zhu Rui Meng Yale Song Xiyu Wei Sujian Li Tomas Pfister Jinsung Yoon
摘要
尽管由语言模型驱动的自主AI科学家取得了迅速进展,但生成符合发表标准的学术插图仍是科研工作流程中的一个耗时瓶颈。为缓解这一负担,我们提出了PaperBanana——一种用于自动生成符合发表标准学术插图的智能体框架。PaperBanana基于最先进的视觉语言模型(VLMs)与图像生成模型,协同多个专业化智能体,实现参考文献检索、内容与风格规划、图像渲染,并通过自我批判机制进行迭代优化。为严格评估该框架,我们构建了PaperBananaBench基准测试集,包含从NeurIPS 2025会议论文中精心筛选的292个方法示意图测试用例,涵盖多样化的研究领域与插图风格。全面的实验结果表明,PaperBanana在忠实性、简洁性、可读性与美学表现等方面均显著优于现有主流基线方法。此外,我们还验证了该方法在生成高质量统计图表方面的有效扩展能力。总体而言,PaperBanana为实现学术插图的自动化生成铺平了道路。
一句话总结
北京大学与谷歌云AI研究院的研究人员提出了PAPERBANANA,这是一种代理式框架,通过协调专门的视觉语言模型(VLM)驱动代理,自动完成出版级学术插图的检索、规划、风格化与迭代优化,在方法图和统计图的保真度、简洁性、可读性和美观性方面显著优于基线方法。
主要贡献
- PAPERBANANA引入了一种代理式框架,通过协调专门代理(负责参考检索、内容规划、图像渲染与自我批判式优化),利用最先进的VLM和图像生成器,自动化生成出版级学术插图。
- 该框架在PAPERBANANA BENCH上进行了评估,这是一个包含292个NeurIPS 2025方法图测试案例的新基准,使用VLM作为评判者,从保真度、简洁性、可读性和美观性四个维度与人类参考图进行评分。
- 实验表明,PAPERBANANA在简洁性上最高优于基线37.2%,整体性能提升17.0%,并能有效扩展至统计图,展示了其在自动化科学可视化方面的广泛应用潜力。
引言
作者利用视觉语言模型与图像生成技术的进展,解决当前学术插图制作仍高度依赖人工的瓶颈问题,尽管自主AI科学家研究已有进展。先前方法要么依赖代码工具(如TikZ),其表达能力难以满足现代设计需求;要么使用通用图像生成器,难以满足学术标准。PAPERBANANA引入一种代理式框架,协调专门代理完成参考检索、内容与风格规划、图像渲染与自我批判,从而生成高保真度的方法图与统计图。同时引入PAPERBANANA BENCH——一个包含292个案例的NeurIPS 2025基准,并在保真度、简洁性、可读性和美观性上全面优于基线方法。
数据集
-
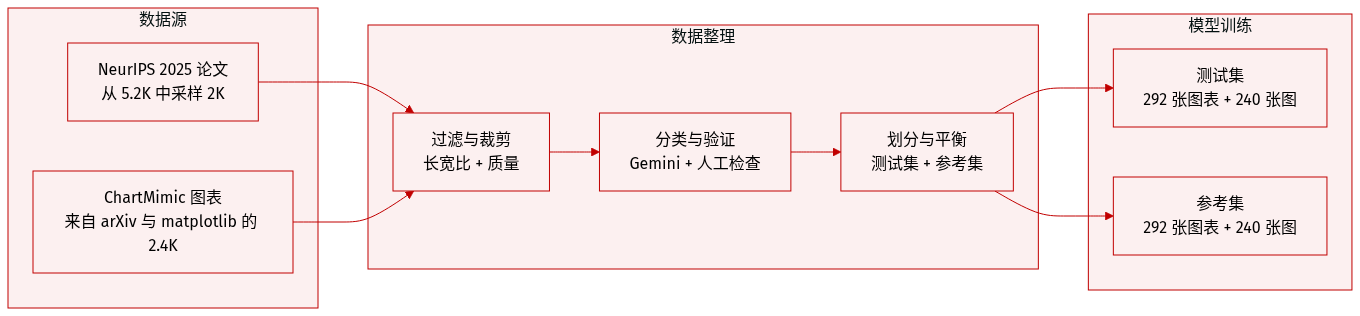
作者使用PAPERBANANABENCH(基于NeurIPS 2025方法图构建的基准)评估自动化图表生成。该基准涵盖现代AI论文中多样且美学复杂的图表。
-
对于方法图:
- 从5,275篇NeurIPS 2025论文中随机抽取2,000篇,通过MinerU提取方法文本、图表与说明。
- 筛选包含方法图的1,359篇论文,再根据宽高比1.5–2.5进一步限制为610篇,以匹配布局规范与模型支持。
- 每个样本为三元组(S, I, C):方法文本、图表图像、说明。
- 使用Gemini-3-Pro将图表分为四类(代理与推理、视觉与感知、生成与学习、科学与应用),并经人工验证准确性与视觉质量。
- 人工筛选后保留584个高质量样本,平均分为测试集与参考集(各292个)。
-
对于统计图:
- 重用ChartMimic的“直接模仿”子集(2,400张来自arXiv与matplotlib的图表),通过Gemini-3-Pro提取原始数据与视觉意图。
- 排除随机生成或几何构造数据,按宽高比1.0–2.5筛选至914张。
- 将22个原始类别合并为7类常见类型:柱状图、折线图、树状图与饼图、散点图、热力图、雷达图、其他。
- 采样480张图(每类80张,热力图/雷达图各40张),对困难案例过采样;平均分为测试集与参考集。
-
预处理包括:
- 裁剪与宽高比调整,以匹配生成模型能力。
- 元数据构建:每张图包含视觉意图、原始数据(针对统计图)、结构化上下文(方法文本或说明)。
- 人工校验确保文本、分类与视觉质量正确。
-
模型仅用这些数据集进行评估,不在PAPERBANANABENCH或统计图测试集上训练。参考集支持推理阶段的检索增强上下文学习。
方法
作者利用PAPERBANANA——一种基于参考的代理式框架——通过分解任务为结构化多代理流水线,自动化生成学术插图。核心目标是将源上下文 S 与交流意图 C 映射为高保真视觉输出 I,可选地由参考示例集 E={En}n=1N 指导,其中每个 En=(Sn,Cn,In)。该公式支持零样本生成(E=∅)与少样本适应,重点聚焦需将技术逻辑精确转化为视觉结构的方法图。
框架包含两个主要阶段:线性规划阶段与迭代优化循环。如下图所示,线性规划阶段协调生成详细且风格化的文本描述,迭代优化循环则通过多次生成与批判循环将该描述转化为最终插图。
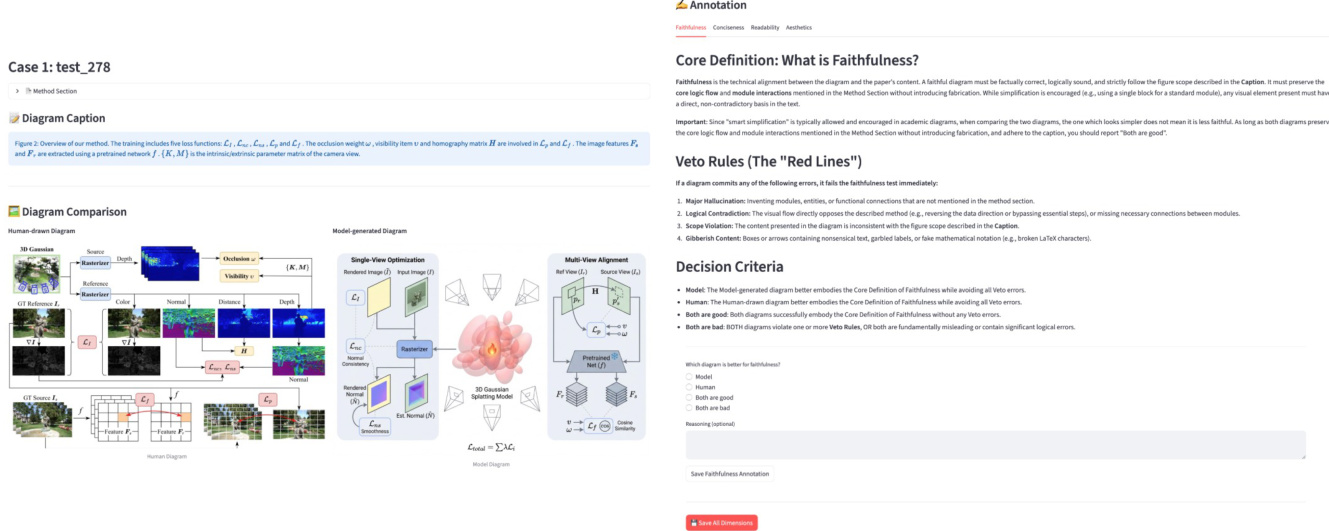
在线性规划阶段,检索代理首先从固定参考集 R 中识别 N 个相关示例 E,通过视觉语言模型(VLM)对候选元数据 (Si,Ci) 进行生成式检索。选择优先考虑视觉结构而非主题相似性,匹配研究领域与图表类型,为下游代理提供具体基础。规划代理随后通过检索示例进行上下文学习,将源上下文 S 与意图 C 转化为目标插图的全面结构蓝图 P。风格代理通过应用自动生成的美学指南 G(封装顶级会议论文中衍生的颜色、形状、排版与布局设计原则),将该描述优化为风格化版本 P∗。
迭代优化循环始于可视化代理,其使用图像生成模型将优化描述 P∗ 渲染为初始图像 I0。在后续每轮迭代 t 中,批判代理依据原始源上下文 (S,C) 与当前描述 Pt 评估生成图像 It,识别事实错误、视觉伪影或结构模糊,并生成修正描述 Pt+1 供可视化代理重新生成。该闭环过程迭代 T=3 轮,最终输出为 I=IT。批判代理同时保持与原始输入的事实验证链接,确保优化过程中语义保真。
对于统计图生成,框架调整可视化与批判代理以优先数值精度。可视化代理不直接生成图像,而是将描述 Pt 转换为可执行的Python Matplotlib代码,渲染为图表 It。批判代理评估图表并生成修正描述 Pt+1 以纠正错误,保持 T=3 轮优化协议。这种基于代码的方法确保与底层数据严格对齐,同时保留迭代质量控制机制。
实验
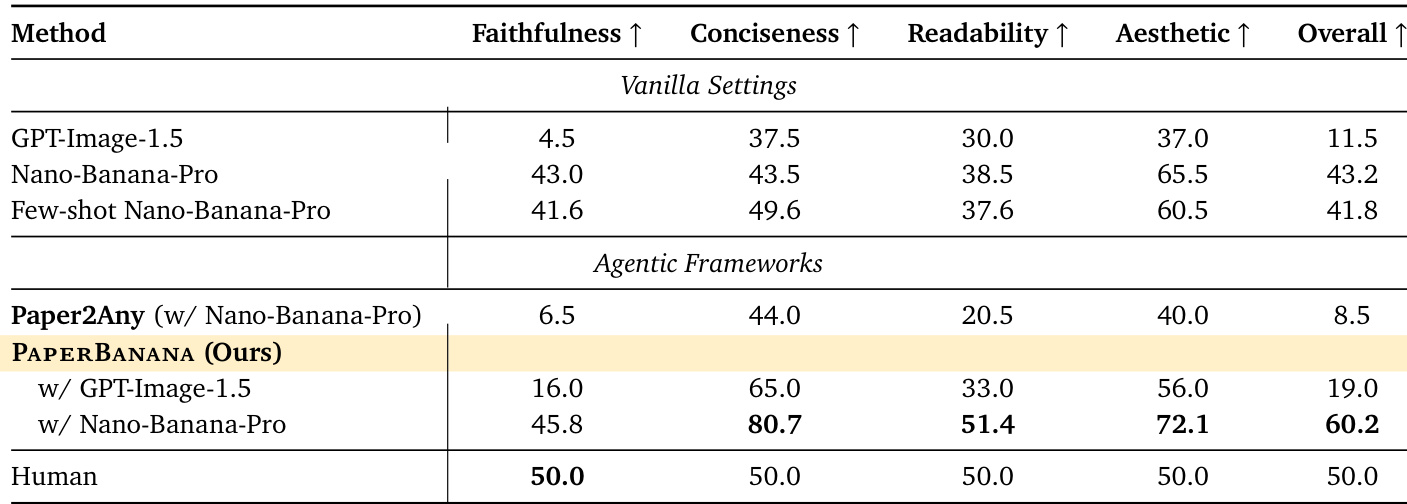
- 使用VLM作为评判者评估方法图与统计图,将模型输出与人工绘制参考图在保真度、简洁性、可读性与美观性上对比,采用分层评分,优先内容保真与清晰度。
- 通过强模型间一致性与人类对齐验证VLM评判者(Gemini-3-Pro)的可靠性,确认其可作为人类评估的可靠代理。
- 证明PAPERBANANA优于基线方法(包括原始提示、少样本提示与Paper2Any),尤其提升保真度、简洁性与可读性,人工盲测确认其在72.7%案例中更优。
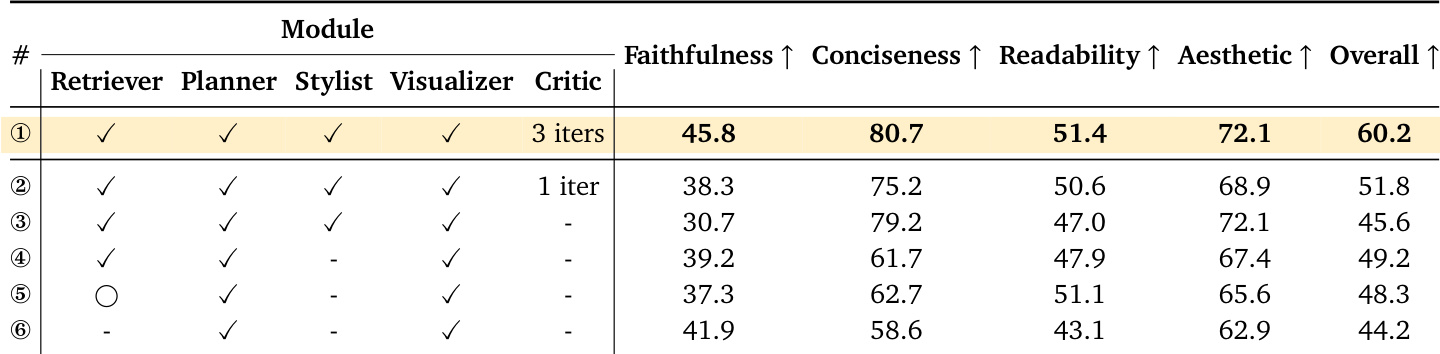
- 消融研究表明,检索代理提升简洁性与美观性,批判代理可恢复风格优化中损失的保真度,突显代理协作迭代的价值。
- 证明自动生成的美学指南可增强人工绘制图表,56.2%的优化输出在美观性上优于原图。
- 对比统计图的代码生成与图像生成方法,发现图像模型在呈现效果上更优但内容保真度较弱,建议混合方法以获得最优结果。
- 识别PAPERBANANA的主要失败模式为连接错误,源于基础模型局限且批判代理难以可靠捕捉。
作者通过消融实验评估代理系统各组件对图表质量的贡献。结果表明,包含批判代理并运行多轮迭代显著提升整体性能,尤其在保真度与简洁性上;移除检索代理或限制迭代次数会降低关键指标。完整管道(含所有模块与迭代优化)在所有维度上均取得最高分。
作者使用分层VLM评估比较图表生成方法,优先保真度与可读性而非简洁性与美观性。结果表明,其代理框架PAPERBANANA显著优于原始与少样本基线,通过平衡技术准确性与视觉清晰度获得最高总分。尽管取得进展,人工绘制图表仍为基准,尤其在保真度方面,凸显自动化图表生成的剩余挑战。