Command Palette
Search for a command to run...
Green-VLA:面向通用机器人的分阶段视觉-语言-动作模型
Green-VLA:面向通用机器人的分阶段视觉-语言-动作模型
摘要
我们提出Green-VLA,这是一种分阶段的视觉-语言-动作(Vision-Language-Action, VLA)框架,专为在Green人形机器人上实现真实世界部署而设计,同时保持在多种不同机器人本体(embodiment)间的泛化能力。Green-VLA采用五阶段课程学习范式:(L0)基础视觉语言模型(VLMs),(L1)多模态定位,(R0)多本体预训练,(R1)本体特定适应,以及(R2)基于强化学习(Reinforcement Learning, RL)的策略对齐。我们结合了一个可扩展的数据处理流水线(包含3000小时演示数据),并引入时间对齐与质量过滤机制,同时采用统一的、具备本体感知能力的动作接口,使单一策略能够控制人形机器人、移动操作机器人以及固定基座机械臂等多种平台。在推理阶段,VLA控制器进一步增强了任务进展预测、分布外检测(out-of-distribution detection)以及基于联合预测的引导机制,显著提升了系统安全性与目标选择的精确性。在Simpler BRIDGE WidowX和CALVIN ABC-D仿真环境中的实验,以及真实机器人上的评估结果表明,通过RL对齐显著提升了任务成功率、鲁棒性以及长时程任务的执行效率,展现出强大的泛化性能与实际应用潜力。
一句话总结
Sber Robotics Center 的 Green-VLA 提出了一种分阶段的视觉-语言-动作框架,通过语义动作对齐、DATAQA 过滤和强化学习优化,统一异构机器人数据,实现对人形机器人和机械臂的零样本泛化,同时通过任务进度预测和联合引导模块提升长时任务成功率。
主要贡献
- Green-VLA 引入了一种以数据质量驱动的流水线,结合 DATAQA 过滤器和时序对齐,处理 3,000 小时异构机器人演示数据,确保在不同机器人形态和控制类型下稳定、高保真训练。
- 提出五阶段训练课程(L0–R2),逐步弥合网络规模视觉-语言模型与具身强化学习对齐之间的鸿沟,使单一策略无需架构修改即可控制人形机器人、移动机械臂和固定基座机械臂。
- 在高自由度 Green 人形机器人及其他平台评估中,Green-VLA 在长时任务中达到最先进性能,强化学习对齐(R2)通过关节预测引导显著提升成功率、鲁棒性和精确物体定位能力。
引言
作者利用一种称为 Green-VLA 的分阶段视觉-语言-动作(VLA)框架,弥合可扩展基础模型与现实机器人部署之间的差距。尽管先前的 VLA 模型受益于大规模数据集和统一架构,但其面临异构、噪声数据以及依赖行为克隆的问题——行为克隆无法优化长时任务成功率或跨机器人形态泛化。Green-VLA 通过引入五阶段训练课程,逐步建立语义基础、统一跨平台动作空间,并通过强化学习优化策略,克服了这些问题。它还集成了 DATAQA 数据质量过滤流水线和关节预测模块以实现精确目标定位,使模型能够零样本泛化至新机器人——包括高自由度 Green 人形机器人——同时提升鲁棒性、成功率和任务效率。
数据集
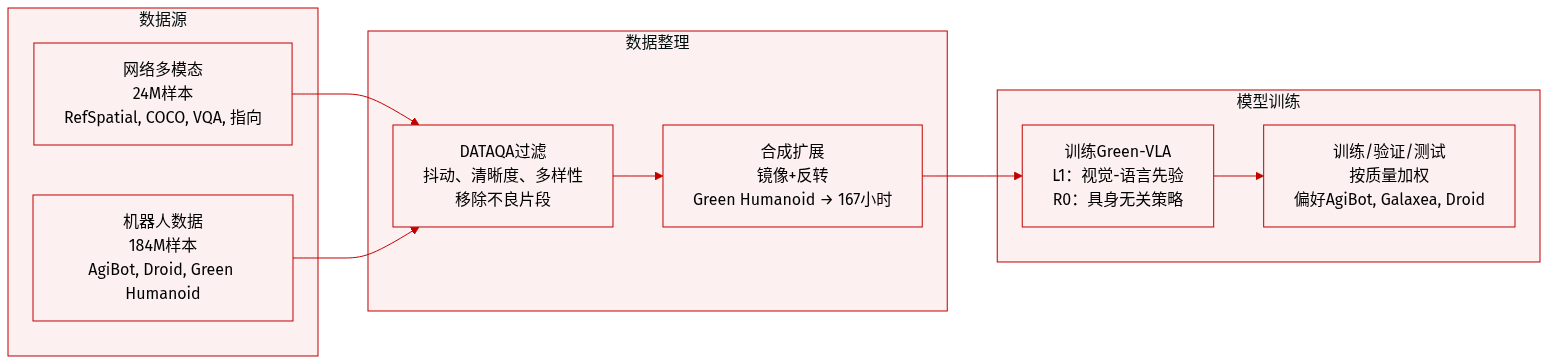
作者为 Green-VLA 使用两阶段训练流水线,结合网络规模多模态数据(L1)和大规模机器人数据(R0),总计超过 2 亿样本和 3,000+ 小时机器人轨迹。以下是数据集的组成、处理和使用方式:
-
数据集组成与来源:
- L1(2400 万样本):来自 10+ 个来源的网络多模态数据,包括 RefSpatial、AgibotWorld、RoboPoint、ShareRobot、Robo2VLM、PixMo-Points、MS COCO、A-OKVQA、OpenSpaces 和 Sun RGB-D。任务涵盖视觉问答、指向、描述、空间推理和像素级轨迹预测。
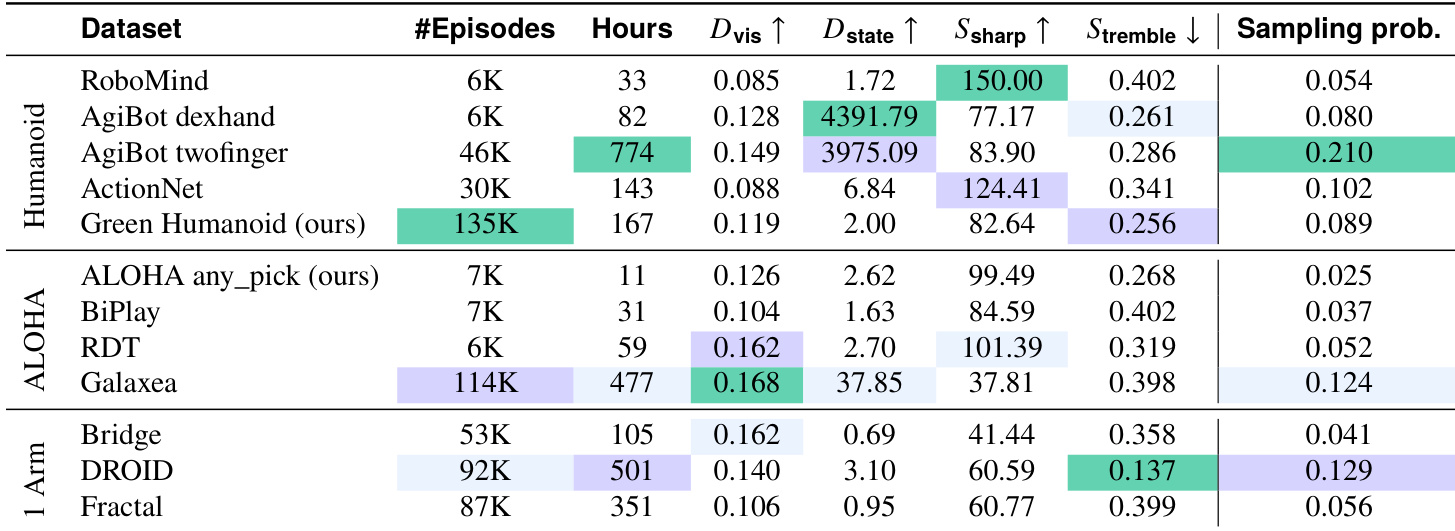
- R0(1.84 亿样本):来自 12+ 个开源和 2 个内部收集的数据集,包括 AgiBotWorld、Droid、Galaxea、Action_net、Fractal、Robomind、RDT、Bridge、BiPlay、Green Humanoid 和 ALOHA any_pick。覆盖人形机器人和机械臂平台,包含多样技能和环境。
-
关键子集详情:
- 网络数据(L1):训练时按任务平衡加权样本。RefSpatial 和 PixMo-Points 将空间点映射到 PaliGemma 令牌。MS COCO 仅限物体检测;Sun RGB-D 仅使用 2D 注释。
- 机器人数据(R0):AgiBotWorld_twofinger(774 小时)和 Droid(512 小时)规模最大。Green Humanoid(48 小时真实数据)通过镜像(翻转相机/关节、左右交换)和时间反转(仅适用于可逆任务如抓取/放置)扩展至 167 小时。ALOHA any_pick 增加 11.2 小时专注于抓取/放置任务。
-
数据处理与过滤:
- 所有机器人数据均进行时间归一化,以对齐不同来源的物理进度。
- DATAQA 流水线使用四个指标过滤片段:抖动(运动平滑度)、多样性(视觉/状态空间)、锐度(基于拉普拉斯算子的图像清晰度)和状态方差。
- 额外过滤:移除缺少相机/帧、极端时长、低运动活跃度或无效夹爪模式(如“开-关-开”用于抓取-放置)的片段。
- 视觉多样性通过 DINOv3 特征方差随时间测量;状态多样性通过状态协方差的 Frobenius 范数测量。
-
训练使用:
- L1 训练通用视觉-语言先验;R0 训练具身无关策略。
- 混合比例按数据集质量指标加权(表 1)。AgiBot twofinger 和 Galaxea 因规模和视觉多样性获得最高权重。Droid 在单臂数据集中因平滑度和任务多样性领先。
- 所有轨迹均存储 RGB、本体感知和语言指令。增强的镜像/反转片段加入 R0 混合。
-
裁剪与元数据:
- 未提及显式裁剪;处理侧重于时间对齐、状态归一化和空间令牌映射。
- 元数据包括任务文本、相机视图、关节/笛卡尔状态以及每片段的过滤质量评分。
方法
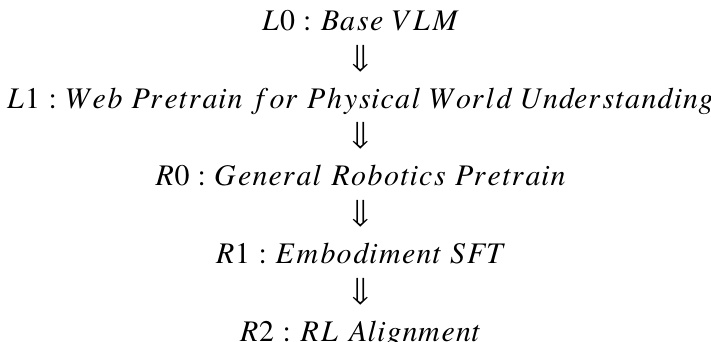
作者利用分阶段训练流水线和统一的基于 Transformer 的架构构建 Green-VLA,这是一种能够实现多具身控制和现实部署的视觉-语言-动作模型。整体框架围绕五个顺序训练阶段——L0 至 R2——每个阶段旨在解决泛化、具身适应和长时鲁棒性的不同瓶颈。如下图所示,流水线从基础视觉-语言模型(L0)开始,经过网络规模多模态预训练(L1)和通用机器人预训练(R0),然后进行具身特定微调(R1),最后通过强化学习对齐(R2)弥补最后一英里性能差距。
在架构层面,Green-VLA 采用单一 Transformer 主干,将多模态输入——RGB 观测、本体感知状态和自然语言指令——融合为共享令牌序列。该序列通过具身特定控制提示 ce 增强,该提示编码机器人的物理配置(例如,臂数、控制类型、移动性)。模型随后预测固定 64 维统一动作空间 Au 中的动作,其中每个索引对应所有支持具身中语义一致的物理自由度。该设计以掩码行为克隆目标替代异构动作空间的朴素填充:
Luni(θ)=E[me⊙(πθ(xte,ce)−Φe(ate))22],其中 me 是指示具身 e 活动槽位的二进制掩码,Φe 将原生动作映射到统一布局。模型输出随后通过 Φe−1 重定向到目标机器人的原生控制空间,实现跨具身迁移而无语义漂移。
为支持实时推理,架构包含效率优化:SDPA 注意力内核、轻量级预测头和流匹配动作专家中的减少去噪步骤。模型还预测一个任务进度标量 ρ^t∈[0,1],训练以反映归一化完成时间,使下游规划器能够在长时执行期间动态调整子目标。
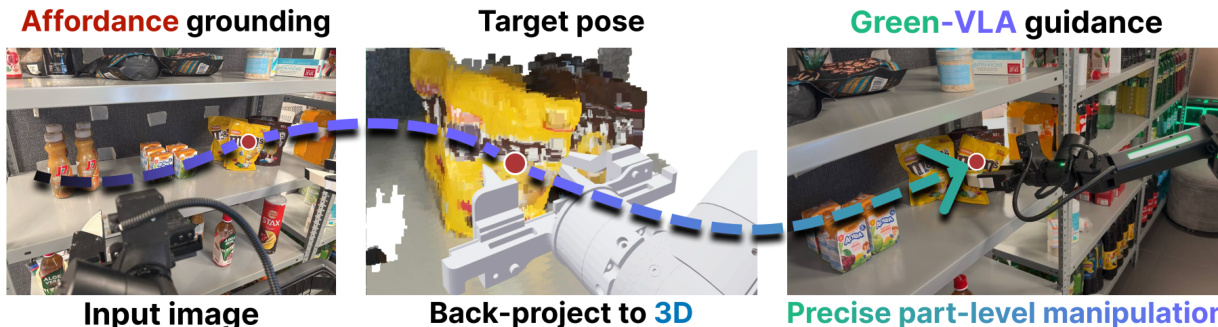
关键创新是集成基于 GigaVision 的高层任务规划器,其独立运行且训练期间保持冻结。该规划器将用户指令解析为原子子任务(例如,“用[左]手拾取[物品]”),并通过结构化提示引导 Green-VLA。执行期间,Green-VLA 通过任务结束概率信号任务完成;若超过阈值,规划器查询反馈模块以验证成功或触发重规划。参见框架图以了解完整推理循环,包括引导和安全模块。

为处理语言中指定的新物体,Green-VLA 集成联合预测模块(JPM),从指令和视觉观测中推断机器人工作空间中的 3D 目标点 p∗。该点首先通过视觉-语言模型预测 2D 可操作位置,然后使用相机内参和姿态提升至 3D:
[p⋆1]=Tcw[d(u,v)K−1[u,v,1]⊤1].所得点用于通过逆运动学计算可行关节配置 q∗,然后通过伪逆引导(PiGDM)引导流匹配策略,使速度场偏向到达目标的轨迹。
为安全和稳定,Green-VLA 包含一个在线 OOD 检测器,建模为在训练机器人状态上拟合的高斯混合模型。如果预测轨迹导致低密度状态 s(即 ptrain(s)<τood),模型通过梯度修正动作,将状态推向更高密度:
s←s+α∇ptrain(s),α=0.2.该修正机制如推理图所示,确保策略在长时任务中保持在训练分布内。
通过调度数据集采样课程,Green-VLA 实现跨多样具身的训练稳定性。并非从一开始就按目标权重 wi 采样数据集,Green-VLA 使用幂律调度:
Wi(t)=∑jwjαtwiαt,αt∈[0,1],α0=0,αT=1,从均匀采样开始,逐渐收敛到目标分布。这防止大型数据集早期主导,允许模型先学习共享结构,再专业化。
为标准化异构演示,Green-VLA 使用光流幅度作为运动速度代理进行时间对齐。轨迹通过单调三次样条重采样以标准化每步运动,确保跨数据集一致动力学。此外,训练期间引入速度条件调制:为每个样本抽取标量 v∼p(v),并将目标轨迹扭曲至不同时间分辨率。模型隐藏状态通过以下方式调制:
h~t=RMSNorm(ht),h^t=γ(v)h~t+β(v),其中 γ(v) 和 β(v) 是学习函数。这使 Green-VLA 能在多个时间“缩放级别”运行,支持精细操作和粗粒度长时运动。
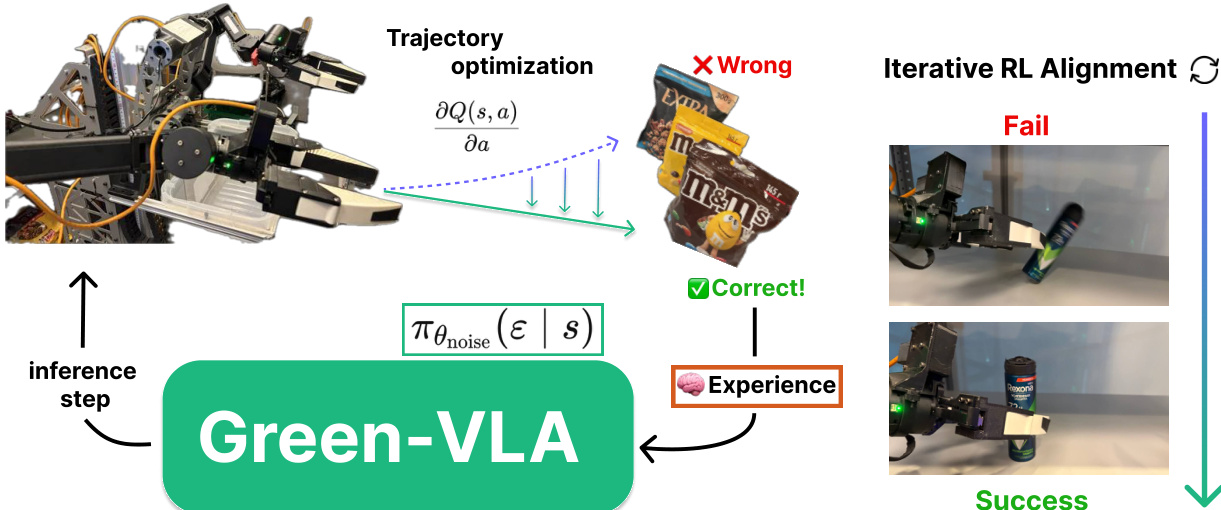
最终 R2 阶段采用两种强化学习微调策略,保持基础模型权重不变。第一种,轨迹优化与原生微调,使用隐式 Q 学习训练单独评论家,并使用其梯度 ∇aQ(s,a) 迭代优化动作:
a←a+η∥∇aQ(s,a)∥∇aQ(s,a),其中 η 是超参数。优化轨迹在环境中验证后加入训练集。第二种方法,源分布优化,训练小型演员网络以采样噪声向量,输入流匹配模型后产生更高回报。该方法实现在线强化学习而不直接修改基础策略参数。
实验
- Green-VLA 在 R0 预训练后展现出强大的任务跟随和跨具身泛化能力,尽管使用显著更少的训练数据,仍优于先前模型,验证了统一动作表示和质量对齐数据集的价值。
- 在 R1 微调中,Green-VLA 有效适应新环境如 CALVIN 和电商货架,即使无先前暴露,仍显示稳健的组合泛化和改进的精细指令跟随性能,尤其在 JPM 引导下实现 SKU 级精度。
- R2 强化学习对齐显著提升长时任务一致性和物理可靠性,提高各基准的成功率和平均链长,尤其在涉及可变形或滑动物体的挑战性操作场景中。
- 人形机器人评估确认系统能够执行复杂多步指令,实现精确手部选择、物体消歧和完整上身协调——即使在分布外场景布局下——同时保持桌面清洁和分类工作流效率。
- 在所有阶段和具身中,Green-VLA 通过分阶段训练持续改进,表明结合统一预训练、具身特定调优和强化学习优化可产生稳健、可扩展且具备指令跟随能力的机器人策略。
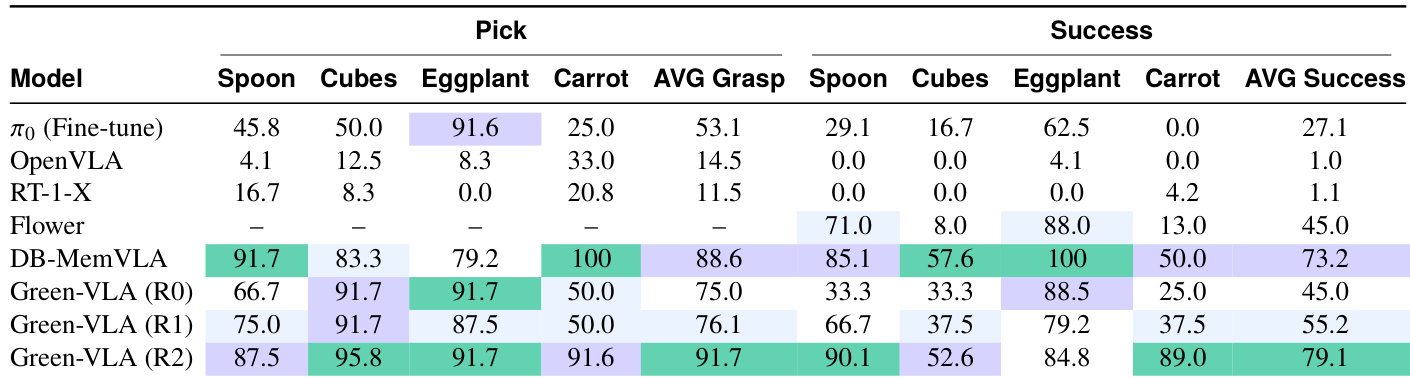
作者在训练阶段 R0、R1 和 R2 上评估 Green-VLA,显示在多样物体上拾取精度和任务成功率的逐步提升。结果表明,R2 强化学习对齐带来最大性能提升,尤其在成功率上优于先前模型,包括微调基线。Green-VLA 在每个阶段持续改进,表明分阶段训练提升操作任务中的精度和鲁棒性。
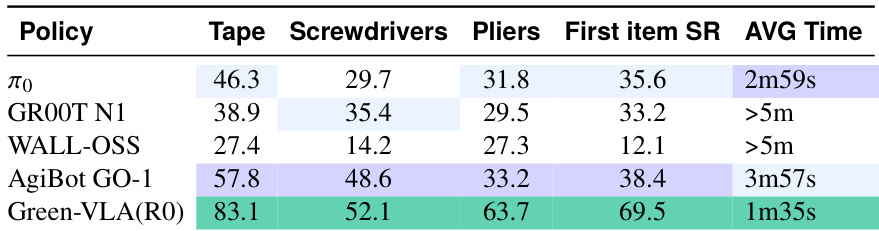
作者在物体拾取和桌面清洁任务上将 Green-VLA 与多个基线模型对比,发现其在多个物体类别上实现更高成功率和更快执行时间。结果表明,即使无具身特定微调,Green-VLA 仍优于先前模型,表明多具身预训练的强大泛化能力。模型的效率和精度提升在单物体和完整任务场景中均一致。
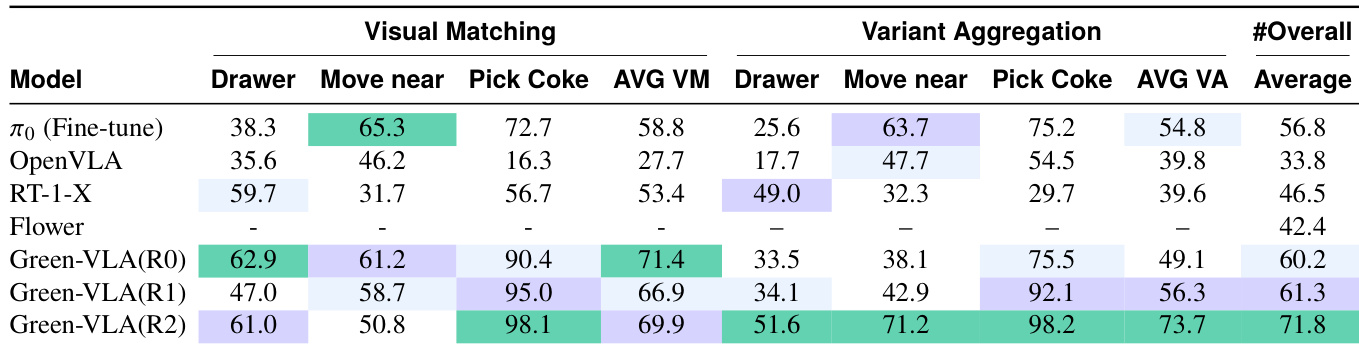
作者在训练阶段 R0、R1 和 R2 上评估 Green-VLA,测量视觉匹配和变体聚合任务性能。结果表明 Green-VLA 在各阶段持续改进,R2 达到最高总分,表明强化学习对齐提升任务精度和鲁棒性。模型优于 π₀ 和 OpenVLA 等基线,尤其在精细物体选择和处理变体条件方面。
作者使用统一多具身数据集训练 Green-VLA,尽管使用显著少于先前系统的数据,仍实现强大的任务跟随和效率。结果表明,其模型在多样机器人平台和任务类型中泛化良好,性能增益通过具身特定微调和强化学习对齐进一步放大。架构中感知与控制的分离使模型即使在分布外条件和复杂多步工作流下仍能稳健执行。