Command Palette
Search for a command to run...
视觉-DeepResearch基准:重新思考多模态大语言模型中的视觉与文本搜索
视觉-DeepResearch基准:重新思考多模态大语言模型中的视觉与文本搜索
摘要
多模态大语言模型(MLLMs)在视觉问答(VQA)任务上取得了显著进展,并已支持基于搜索引擎的视觉-深度研究(Vision-DeepResearch)系统,用于复杂视觉-文本事实检索。然而,评估这类系统在视觉与文本搜索方面的能力仍面临挑战,现有基准测试存在两大主要局限性。首先,现有基准并非以视觉搜索为核心:一些本应依赖视觉搜索才能回答的问题,往往可通过问题文本中的交叉文本线索获得答案,或仅凭当前MLLM所具备的先验世界知识即可推断得出。其次,评估场景过于理想化:在图像搜索方面,所需信息通常可通过与完整图像进行近乎精确的匹配即可获取;而在文本搜索方面,任务设计则过于直接,缺乏足够的挑战性。为解决上述问题,我们构建了视觉-深度研究基准测试(Vision-DeepResearch Benchmark,简称VDR-Bench),包含2,000个视觉问答实例。所有问题均通过严谨的多阶段数据筛选流程与专家严格评审生成,旨在真实还原视觉-深度研究系统在现实世界条件下的行为表现。此外,针对当前MLLM在视觉检索能力上的不足,我们提出一种简单但有效的多轮裁剪搜索(multi-round cropped-search)工作流。实验表明,该策略在真实视觉检索场景中能显著提升模型性能。总体而言,本研究为未来多模态深度研究系统的设计提供了切实可行的指导。相关代码将开源发布于:https://github.com/Osilly/Vision-DeepResearch。
一句话总结
来自深圳环区研究院及合作机构的研究人员提出了 Vision-DeepResearch,该基准重新思考了面向多模态大语言模型的视觉-文本搜索任务,引入了能更好捕捉现实世界检索挑战的新型评估指标,超越了以往静态数据集的局限。
主要贡献
- 我们识别出当前多模态搜索基准的关键局限,包括依赖纯文本线索和理想化的整图检索,无法反映真实世界的视觉搜索挑战。
- 我们引入 VDR-Bench,一个由 2,000 个实例组成的基准,通过多阶段策展流程构建,要求真实的视觉搜索与多跳推理,并经人工验证以消除捷径解法。
- 我们提出一种多轮裁剪搜索工作流,通过迭代定位实体提升视觉检索准确率,实验验证其在现实场景中显著提升性能。
引言
作者利用多模态大语言模型的进展,应对日益增长的深度现实世界视觉-文本研究系统需求——结合图像理解、网络搜索和多跳推理。现有基准存在不足,因允许模型通过文本捷径绕过真实视觉搜索,或依赖理想化、近乎完美的图像匹配,无法反映真实视觉检索的噪声与迭代特性。为此,他们引入 VDR-Bench,一个通过人工验证流程构建的 2,000 实例基准,强制视觉优先推理和跨模态证据收集。他们还提出一种多轮裁剪搜索工作流,通过迭代优化视觉查询提升性能,为构建更鲁棒的多模态智能体提供实用路径。
数据集

作者使用 VDR-Bench,一个包含 2,000 个多跳视觉问答(VQA)实例、覆盖 10 个不同视觉领域的基准,用于评估深度研究与实体级检索性能。以下是数据集的构建与使用方式:
-
来源与构成:
- 图像来自多个公开数据集,经 Qwen3-VL-235B-A22B-Instruct 预筛选分辨率和视觉丰富度,仅保留含多个实体和真实场景的图像。
- 每个样本围绕人工裁剪的显著区域(如物体、标志、地标)构建,作为网络级图像搜索的视觉查询。
- 最终样本结合视觉证据、检索到的实体及基于外部知识图谱的多跳推理链。
-
关键子集细节:
- 步骤 0:多领域图像预筛选剔除低分辨率图像;Qwen3-VL-235B-A22B-Instruct 选择高质量、实体丰富的场景。
- 步骤 1:人工标注者裁剪显著区域;每个裁剪区域触发网络视觉搜索以检索候选图像。
- 步骤 2:从搜索结果标题/说明中提取候选实体(人物、品牌、地点)。Qwen3-VL-235B-A22B-Instruct 过滤不一致匹配,再经人工验证确保实体无法通过整图搜索轻易找到。
- 步骤 3:Gemini-2.5-Pro 生成与已验证实体关联的种子 VQA 对。人工审核确保问题需视觉锚定且答案唯一明确。
- 步骤 4:知识图谱随机游走将问题扩展为多跳推理任务(如“出现在图中的公司总部位于哪个城市?”)。
- 步骤 5:自动可解性检查确认答案可从记录的视觉搜索 + KG 路径推导;人工标注者移除仅依赖文本捷径或推理模糊的问题。
-
模型使用与训练设置:
- VDR-Bench 仅用于评估,未提及训练集划分。
- 问题设计强制代理检索并推理视觉实体,而非依赖先验知识。
- 基准强调最终答案准确率与实体级检索成功率。
-
处理与元数据:
- 每个样本包含:原始图像、裁剪区域、视觉搜索结果、验证实体名称、知识图谱扩展路径及多跳问题。
- 元数据追踪完整推理轨迹——包括搜索查询、检索实体和 KG 跳数——以支持评估。
- 使用两个指标:
- 答案准确率:使用 Qwen3-VL-30B-A3B-Instruct 作为评判模型,通过标准化提示评估。
- 实体召回率(ER):衡量代理检索实体集是否在语义上匹配黄金实体序列(非字符串匹配),使用 LLM 作为评判者接受有效推理路径与同义词。
实验
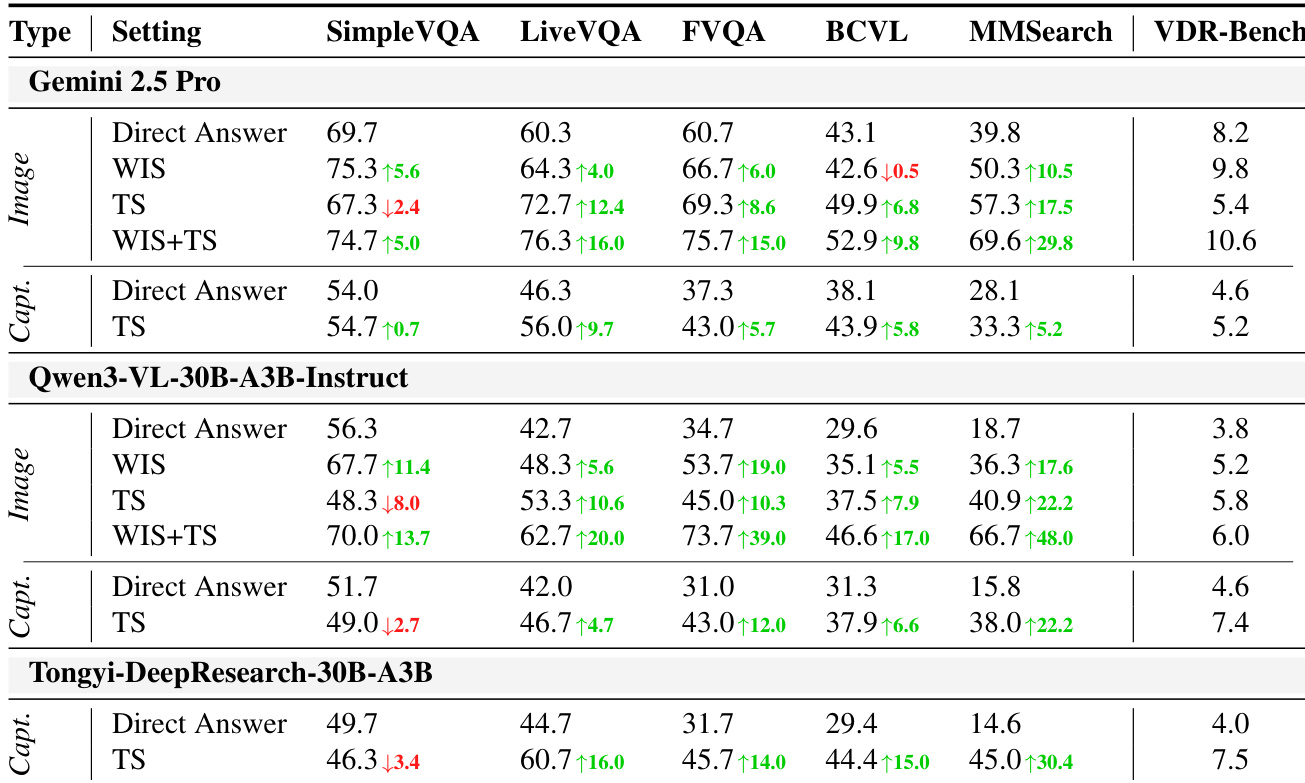
- 现有 Vision-DeepResearch 基准常未能强制视觉搜索为中心的推理,因许多问题仅靠文本搜索或模型先验即可回答,暴露出显著的文本线索泄露。
- 当前评估设置过于理想化,依赖近乎精确的图像匹配,绕过现实挑战如迭代定位、实体细化与跨模态验证。
- 在新 VDR-Bench 上,无搜索工具时模型表现不佳,证实主动视觉与文本检索对准确回答的必要性。
- 配备搜索工具时,先验知识较弱的开源模型优于闭源模型,表明有效工具使用比预训练知识更重要。
- 多轮视觉强制通过促进迭代区域裁剪与跨模态验证提升性能,凸显结构化视觉锚定在复杂推理任务中的价值。
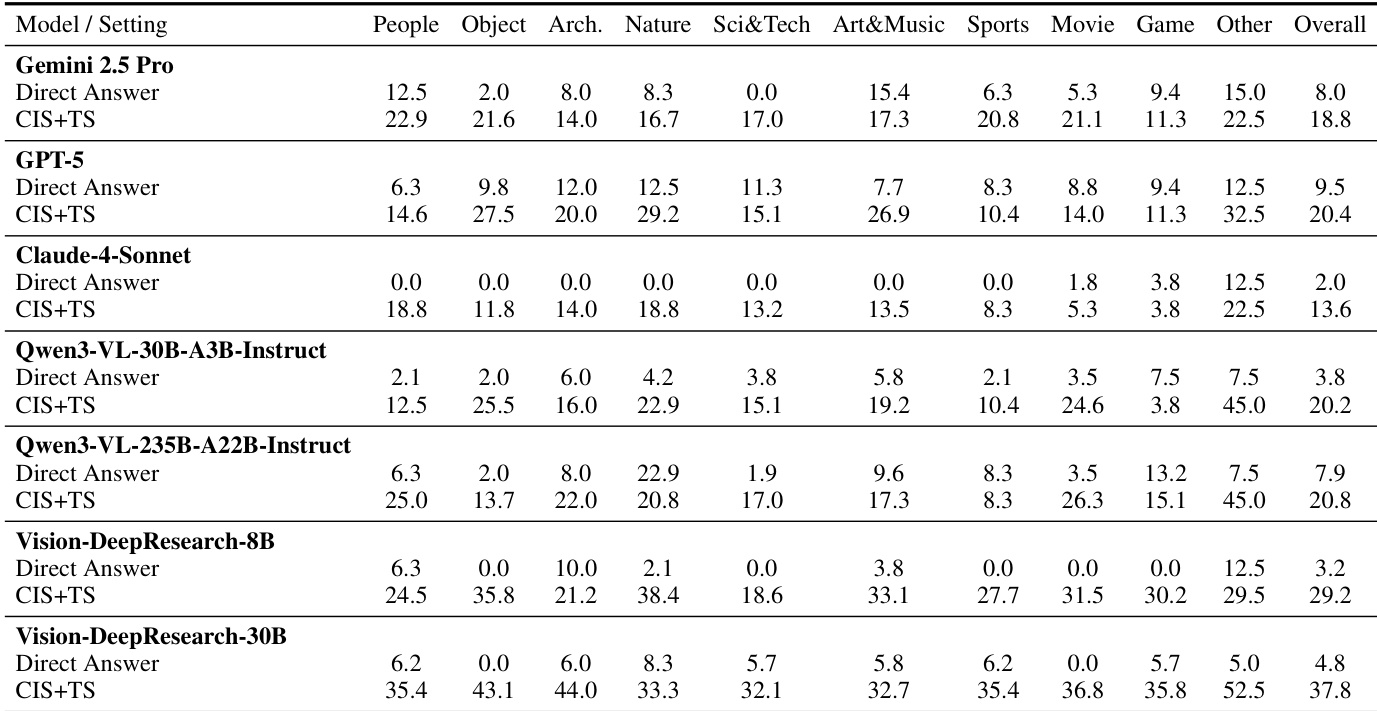
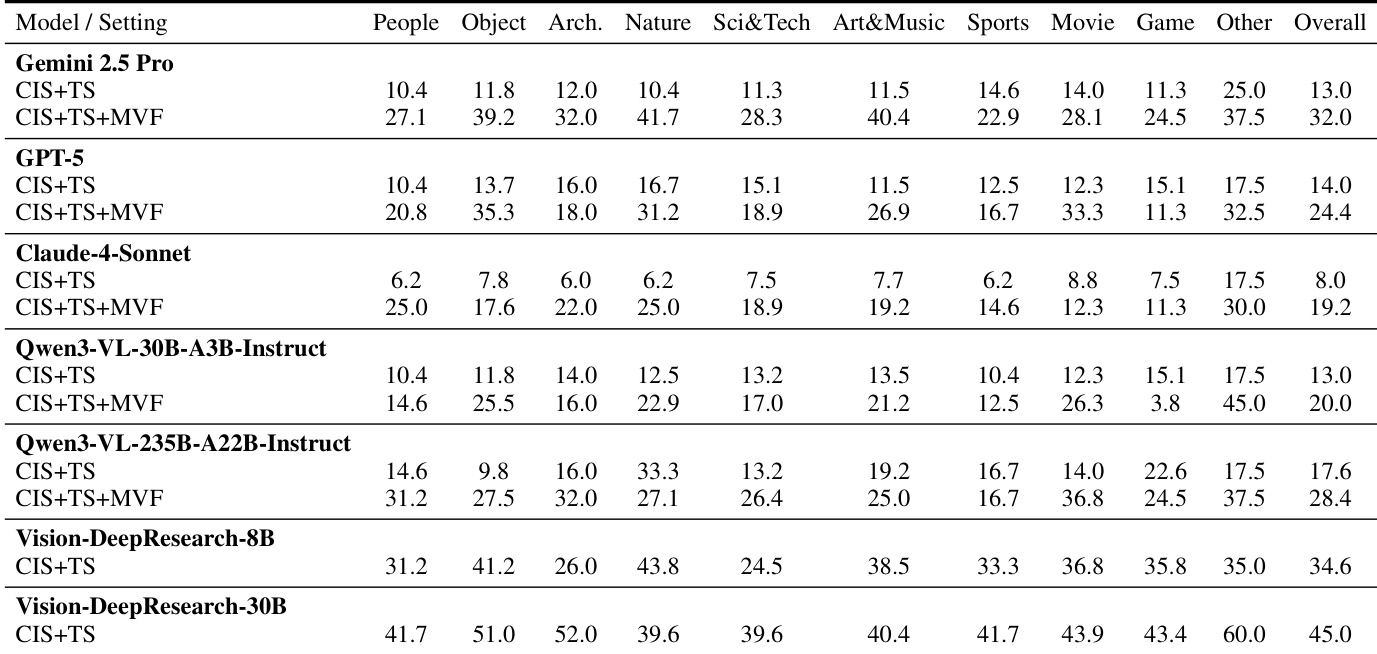
作者在受控搜索设置下评估多个视觉语言模型,以分离视觉与文本检索的贡献。结果表明,启用多轮视觉强制在各领域一致提升性能,说明迭代细化与跨模态验证对有效视觉深度研究至关重要。开源模型,特别是较大者,尽管先验知识较弱,仍展现出强大的搜索驱动推理能力,表明工具使用策略比参数化记忆更重要。
作者通过受控实验表明,许多现有视觉基准无需视觉搜索即可有效解决,依赖文本检索或模型先验,削弱了其评估真实视觉推理的有效性。结果表明,性能常因文本搜索提升更显著,而非整图搜索,显示广泛存在的文本线索泄露与对语言知识的过度依赖。相比之下,新 VDR-Bench 要求主动搜索,证明模型规模与搜索工具使用,而非仅先验知识,对视觉深度研究性能至关重要。
作者在受控搜索条件下评估多个视觉语言模型,评估其对视觉与文本证据的依赖。结果表明,当模型同时使用裁剪图像与文本搜索时性能显著提升,多轮视觉强制带来进一步增益,表明有效视觉推理需迭代细化与跨模态验证。值得注意的是,先验知识较弱的模型在启用搜索工具时常优于更强模型,表明对视觉深度研究任务,搜索策略比预训练知识更重要。
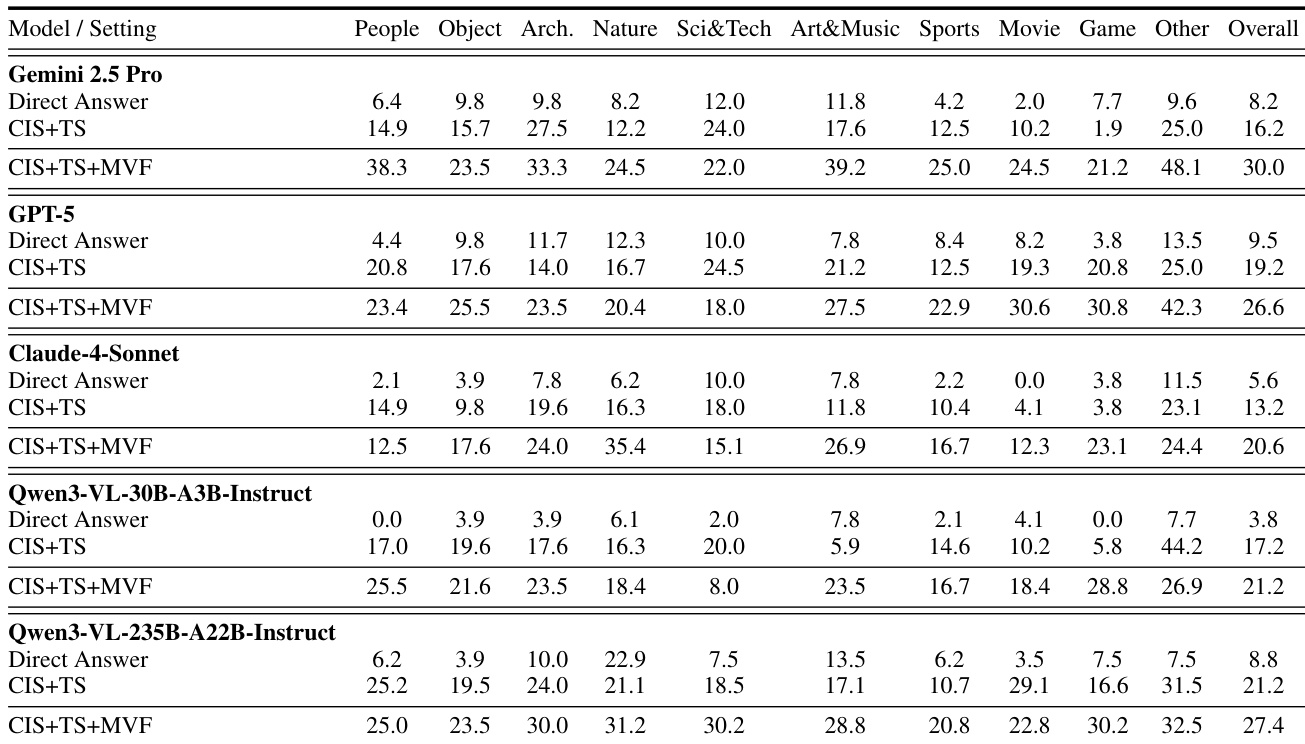
作者在新基准上评估多个视觉语言模型,该基准强制视觉搜索为中心的推理,发现当模型同时使用裁剪图像与文本搜索工具时性能显著提升。结果表明,先验知识较弱的模型在搜索驱动任务中常优于更大的闭源模型,表明有效工具使用比仅靠预训练知识更重要。最高分由主动通过迭代搜索与视觉证据交互的模型获得,凸显设计要求真实视觉锚定而非文本捷径的基准的重要性。