Command Palette
Search for a command to run...
daVinci-Agency:高效解锁长周期代理数据
daVinci-Agency:高效解锁长周期代理数据
摘要
尽管大型语言模型(LLMs)在短期任务上表现出色,但将其扩展至长周期代理型工作流仍面临显著挑战。其核心瓶颈在于缺乏能够捕捉真实长依赖结构与跨阶段演化动态的训练数据——现有的数据合成方法要么局限于受模型分布约束的单特征场景,要么带来难以承受的人工标注成本,难以提供可扩展且高质量的监督信号。为此,我们从现实世界软件演化的视角重新构想数据合成方法。关键洞察在于:拉取请求(Pull Request, PR)序列天然蕴含着长周期学习所需的监督信号。它们将复杂目标分解为可验证的提交单元,在迭代过程中保持功能一致性,并通过缺陷修复历史编码出真实的优化模式。基于此,我们提出 daVinci-Agency,该方法通过三个相互关联的机制,系统性地从“PR链”中挖掘结构化监督信号:(1)通过持续提交实现渐进式任务分解;(2)通过统一的功能目标实现长期一致性约束;(3)基于真实的缺陷修复轨迹实现可验证的迭代优化。与将每一步独立处理的合成轨迹不同,daVinci-Agency 依托 PR 驱动的结构,天然保留了因果依赖关系与迭代优化过程,从而有效支撑持久的目标导向行为的教学,并自然契合项目级、全周期任务建模的需求。由此生成的轨迹规模可观——平均达 85,000 个 token 与 116 次工具调用——却展现出惊人的数据效率:仅使用 239 个 daVinci-Agency 样本对 GLM-4.6 进行微调,便在多个基准测试中实现显著提升,尤其在 Toolathlon 上取得 47% 的相对性能增益。除基准性能外,我们的分析进一步证实……
一句话总结
来自SII、上海交大、港理大和GAIR的研究人员提出了daVinci-Agency,这是一种从真实世界PR序列中挖掘长视野监督信号以训练LLM执行代理工作流的新框架,通过保留因果依赖关系,在Toolathon上以极少数据实现47%的性能提升,优于合成方法。
主要贡献
- daVinci-Agency通过从真实GitHub Pull Request序列中挖掘结构化监督信号,解决长视野训练数据稀缺问题。这些序列天然编码任务分解、功能一致性与迭代优化,反映真实的软件演进过程。
- 该方法构建平均包含85k token与116次工具调用的多PR轨迹,实现数据高效训练——仅用239个样本微调GLM-4.6,即可在Toolathon上获得47%的相对提升,优于使用66k合成样本训练的模型。
- 除基准性能提升外,该方法揭示模型内部化了长视野行为,并发现针对扩展规划的特定缩放规律,确立基于PR演进的训练范式为可扩展的、持久目标导向代理教学方案。
引言
作者利用真实GitHub Pull Request(PR)序列,解决面向代理的LLM缺乏高质量长视野训练数据的问题。现有方法要么依赖缺乏跨阶段依赖的合成轨迹,要么依赖昂贵的人工标注;而PR链天然编码迭代优化、功能一致性与可验证反馈——这对教授持久目标导向行为至关重要。他们的贡献daVinci-Agency从链式PR中挖掘结构化监督信号,训练代理进行任务分解、长期一致性与优化,仅用239个样本即在Toolathon上获得47%提升——展示出卓越的数据效率,并揭示了扩展规划任务的可扩展训练规律。
数据集

作者选用九个精心挑选的GitHub仓库作为daVinci-Agency数据集的基础,以反映真实世界中的长视野软件开发。选择标准包括:
- 规模与成熟度:拥有超过7,000个有效PR的仓库,确保丰富的PR间依赖关系。
- 社区互动性:高频率代码审查,以捕捉自然语言推理信号。
- 语言多样性:涵盖Python、Java、C、Rust和Go,覆盖多样技术栈。
每个仓库通过GitHub API元数据构建PR链,使用提交与评审引用建立依赖拓扑(如PR #21引用PR #15),保留非连续的真实世界迭代模式。
对于每个PR链中的PR,作者使用LLM生成子查询,描述问题与推理链,但故意省略实现细节——迫使代理在执行过程中导航并定位代码。每个查询均附加整个PR链的全局概览,以提供宏观上下文。
最终数据集包含9个仓库,包括numpy/numpy、scipy/scipy、apache/pulsar和astral-sh/ruff,覆盖科学计算、分布式系统与现代工具链。表4列出各仓库总PR数与最终构建的任务查询数。
该数据用于训练代理进行长视野推理,查询作为代理执行的输入。除PR拓扑与查询合成外,未进行裁剪或元数据构造。流程强调状态演进与逐步一致性,而非孤立任务求解。
方法
作者采用分层、长视野的代理-环境交互框架,将自主软件工程建模为基于马尔可夫决策过程的序列决策过程。在每个时间步,代理观察状态,并在内部推理消息与外部工具执行之间交替,形成将代码库从初始状态转换至与给定查询对齐目标状态的轨迹。该范式明确捕捉真实开发工作流中固有的时间与语义依赖,任务极少孤立,而是通过相互依赖的Pull Request链演进。
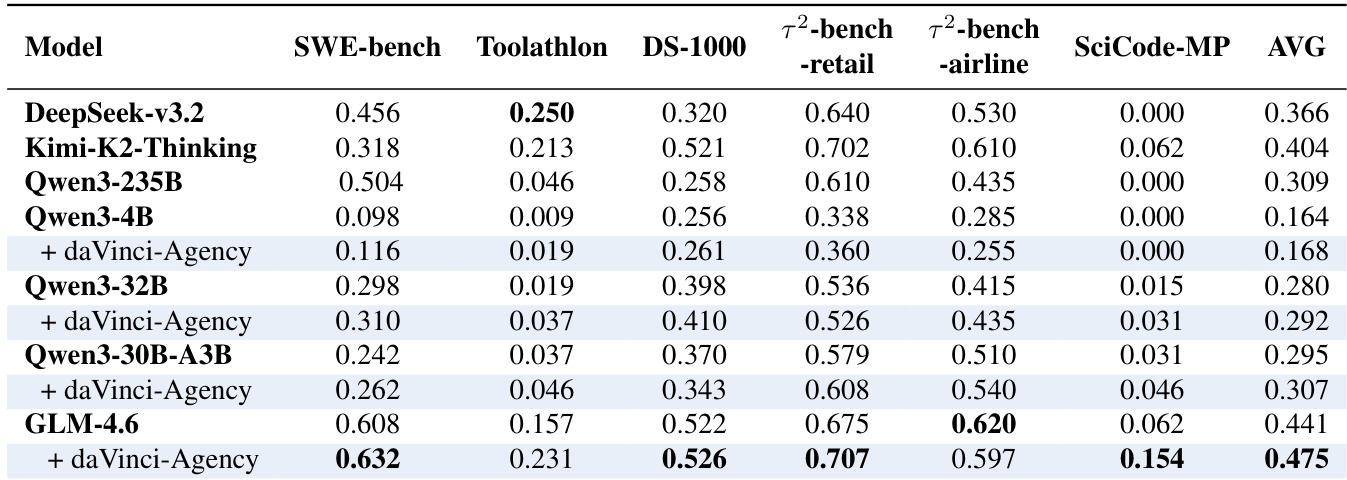
参考框架图说明端到端流程:从PR链构建查询开始,经状态传播环境下的多阶段执行数据收集,最终通过拒绝采样与缩放处理训练数据。环境通过递归将代理前一补丁应用于下一阶段的基提交来强制连续性,形式化为 Sinit(t)=Bt⊕Δτt−1,确保每个后续任务均基于代理自身演进的代码库状态。这种递归依赖迫使代理维持长期一致性并管理各阶段的错误累积。
训练目标是最小化代理策略 πθ 在高保真轨迹上的负对数似然,其中监督信号来自跨阶段演进。轨迹通过语义评估器(GLM-4.6)筛选,该评估器对生成补丁与真实补丁的对齐度打分,仅保留 s≥0.8 的轨迹。严格筛选确保训练数据集 Dtrain 不仅编码任务完成,也编码优化策略与长期一致性,正如软件开发项目演进层级所强调。
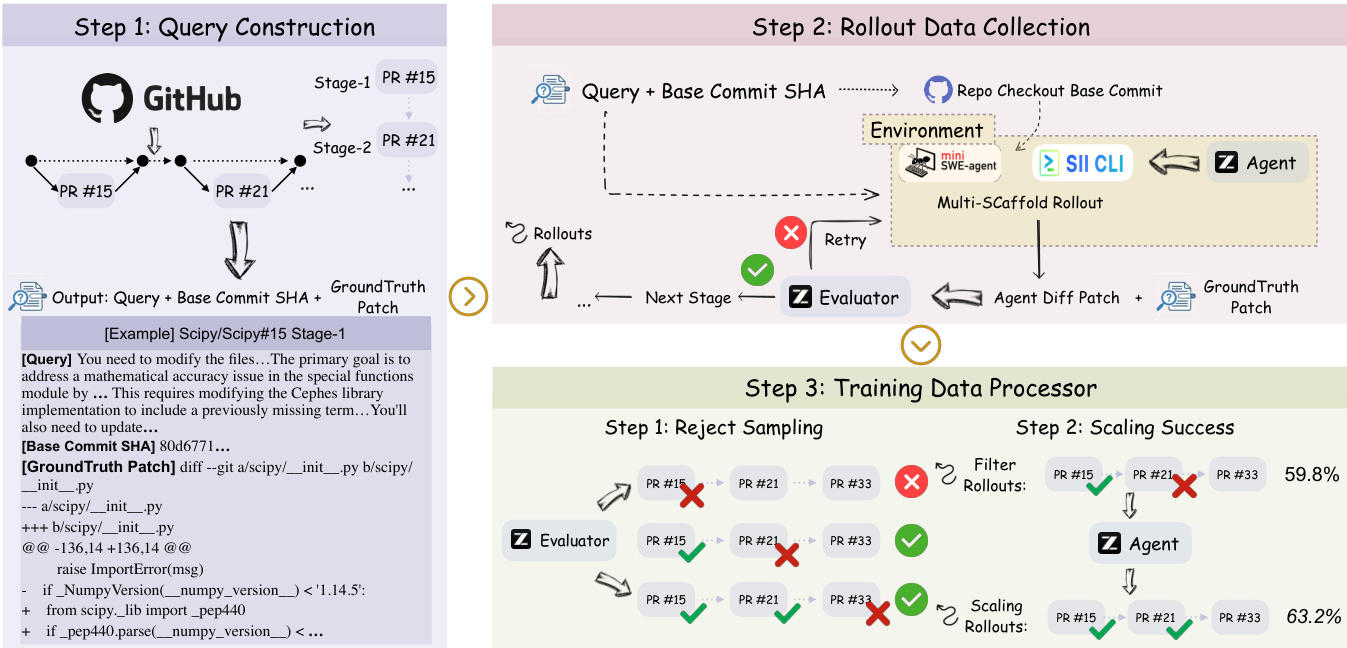
如下图所示,模型运行在三个不同视野层级:函数级(单次工具调用)、功能级(约40次工具调用)与项目演进级(100+次工具调用)。daVinci-Agency针对的项目演进级要求跨多个PR的持续规划、导航与迭代补丁生成,反映真实软件维护的复杂性。代理必须从补丁中抽象关键逻辑,合成结合意图、位置与实现策略的指令,并在各阶段保持状态。
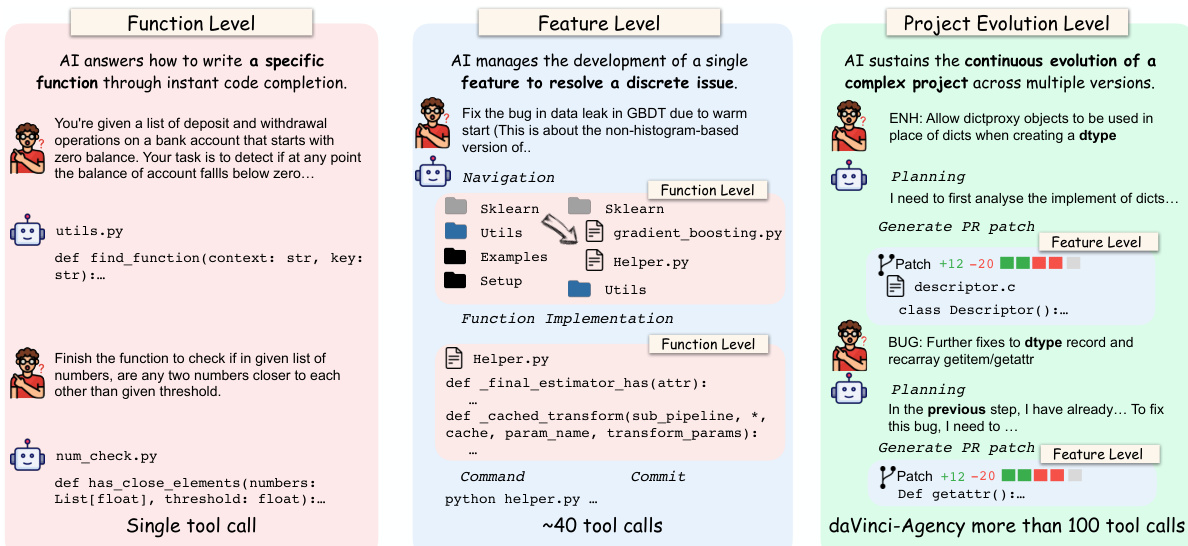
执行过程中,代理部署于多个支架(SII-CLI与mini-swe-agent)以捕捉多样代理行为,记录包含观察、推理消息与工具执行的完整轨迹。评估器提供最多三次迭代的文本反馈,使代理在最终提交前迭代改进补丁。该过程产生紧凑但高质量的数据集,尽管规模小,仍实现卓越的长视野性能,如在比基线数据集大数个数量级的情况下实现148%的性能提升。
代理的推理过程遵循结构化四步分析:识别核心意图、定位概念位置(文件路径与变量)、将关键逻辑抽象为模糊计划、合成指导执行的指令。这确保代理行为不仅反应式,而且与PR链演进上下文战略对齐。生成的轨迹展现测试配置、缺陷检测与长期一致性维护等行为——这些能力使daVinci-Agency区别于常陷入逃避或在长期交互中丢失上下文的基础模型。
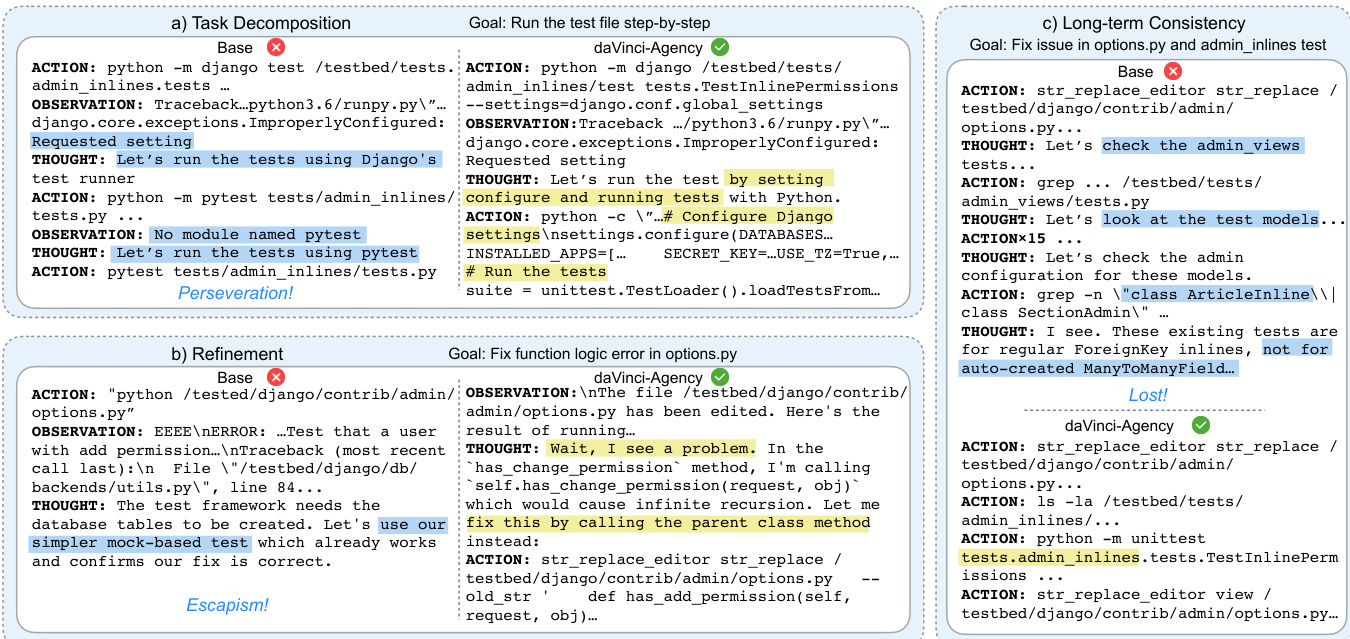
训练数据处理器通过两个阶段进一步提升数据集质量:拒绝采样剔除低保真执行轨迹,缩放成功轨迹以放大高性能轨迹。双阶段过滤确保最终训练集语义准确且行为稳健,使代理能泛化至复杂多阶段软件演进任务。
实验
- daVinci-Agency在长视野代理基准测试中优于主要开源基线,尤其在软件工程、工具使用与跨领域可靠性方面表现突出,尽管数据量更小。
- 消融研究证实,建模真实PR演进——特别是通过语义依赖链——对开发长视野代理能力至关重要;单PR或仅时间序列效果较差。
- 该范式支持自蒸馏:由GLM-4.6自身生成的训练轨迹驱动性能提升,证明高质量数据结构——而非更强教师模型——可解锁潜在代理能力。
- daVinci-Agency在不同模型架构(MoE与稠密)与规模上泛化良好,甚至在Qwen3-8B等较小模型上提升性能。
- 在daVinci-Agency上训练的模型展现出新兴元技能:结构化任务分解、自我修正与目标保持,对比基线模型的目标漂移与逃避行为。
- 效率显著提升:减少的token与工具使用表明更高推理密度与更好上下文管理,直接增强长视野性能。
- 通过完成PR链扩展轨迹长度可提升性能,证实更长、语义连贯的序列是代理能力扩展的关键维度。
- 拒绝采样至关重要:过滤低质量轨迹可防止性能崩溃,并通过高保真监督实现有意义的自我改进。
作者使用拒绝采样过滤自生成训练轨迹,结果表明相比使用未过滤数据,该方法显著提升模型在多个基准上的性能。无拒绝采样时,模型平均得分急剧下降,表明低质量监督会削弱推理能力。采用拒绝采样后,模型不仅恢复性能,更超越基线,尤其在SciCode-MP等复杂任务上,证实高保真数据对有效自蒸馏至关重要。

作者使用daVinci-Agency在结构化、基于演进的PR序列上训练模型,在长视野基准测试中取得优异性能,尽管数据集规模更小。结果表明,建模PR间的语义依赖(而非时间顺序或孤立任务)对开发稳健代理行为至关重要。该方法在不同模型架构与规模上持续提升性能,证明高质量、逻辑结构化的数据本身即可解锁高级长视野推理,无需依赖更强教师模型。
作者使用daVinci-Agency微调GLM-4.6,在AgencyBench衡量的长视野代理任务中获得显著性能提升。结果表明,微调模型显著优于其基础版本及其他大规模基线(如DeepSeek-v3.2与Kimi-K2-Thinking)。该提升归因于从真实PR演进中提取的结构化监督,而非依赖更强教师模型或简单数据扩展。

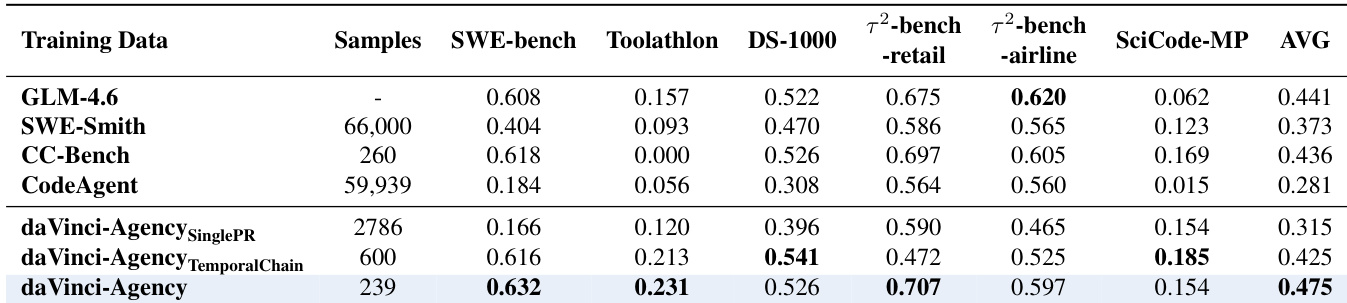
作者使用daVinci-Agency微调多种模型架构,在长视野代理基准测试中展现一致性能提升,GLM-4.6取得最高平均分0.475。结果表明,daVinci-Agency训练不仅提升任务成功率,也提升token与工具效率,表明模型更好内化结构化推理与规划。提升与模型无关,在稠密与MoE架构中均观察到,源于数据集强调真实演进式监督,而非仅序列长度或教师模型质量。