Command Palette
Search for a command to run...
AOrchestra:面向智能体编排的子智能体自动生成
AOrchestra:面向智能体编排的子智能体自动生成
摘要
语言代理(language agents)在任务自动化方面展现出巨大潜力。随着对日益复杂、长周期任务自动化需求的提升,多轮任务求解中“子代理作为工具”的范式应运而生。然而,现有设计普遍缺乏对子代理的动态抽象机制,限制了系统的适应能力。为此,本文提出一种统一且与框架无关的代理抽象方法,将任意代理建模为一个四元组:指令(Instruction)、上下文(Context)、工具(Tools)与模型(Model)。该四元组构成能力的组合式“配方”,使系统能够按需动态生成针对特定任务的专用执行器。基于这一抽象,我们构建了名为 AOrchestra 的智能体系统。其中,核心编排器(orchestrator)在每一步动态实例化该四元组:它筛选与任务相关的上下文,选择合适的工具与模型,并通过实时自动创建代理的方式委派执行。该设计显著降低了人工工程成本,同时保持了对多种代理的即插即用兼容性,具备完全的框架无关性。此外,系统支持可控的性能-成本权衡,使整体表现趋近于帕累托最优(Pareto-efficient)。在三个具有挑战性的基准测试(GAIA、SWE-Bench、Terminal-Bench)中,AOrchestra 搭配 Gemini-3-Flash 模型时,相较最强基线实现了 16.28% 的相对性能提升。相关代码已开源,地址为:https://github.com/FoundationAgents/AOrchestra
一句话总结
来自多个机构的研究人员提出了 AORCHESTRA,这是一种框架无关的系统,使用动态代理元组(指令、上下文、工具、模型)自动生成专门的执行器,减少人工干预,并实现帕累托最优的性能-成本权衡,在 GAIA、SWE-Bench 和 Terminal-Bench 上比基线模型高出 16.28%。
主要贡献
- AORCHESTRA 引入了一种统一的、框架无关的代理抽象,表示为四元组 〈Instruction, Context, Tools, Model〉,支持按需动态创建针对每个子任务需求量身定制的专用子代理。
- 系统的核心编排器在每一步自动实例化该元组,通过整理上下文、选择工具和模型并生成执行器,减少人工工程工作量,并支持多样代理的即插即用集成。
- 在 GAIA、SWE-Bench 和 Terminal-Bench 上使用 Gemini-3-Flash 进行评估,AORCHESTRA 相比最强基线实现了 16.28% 的相对提升,证明其在复杂、长视野任务中性能优越,同时支持可控的性能-成本权衡。
引言
作者利用一种动态的、框架无关的代理抽象——定义为四元组(指令、上下文、工具、模型)——以支持按需创建针对复杂、长视野任务的专用子代理。以往系统要么将子代理视为静态角色(需要大量工程且缺乏适应性),要么视为孤立的上下文线程(忽略能力专业化),限制了在开放环境中的性能。AORCHESTRA 的编排器在每一步自动实例化该元组,选择工具、模型和上下文以生成定制执行器,减少人工干预,同时支持成本-性能权衡。在 GAIA、SWE-Bench 和 Terminal-Bench 上评估时,与 Gemini-3-Flash 配合使用可实现比基线高 16.28% 的相对提升,并支持基于学习的优化以获得更高效率。
数据集
-
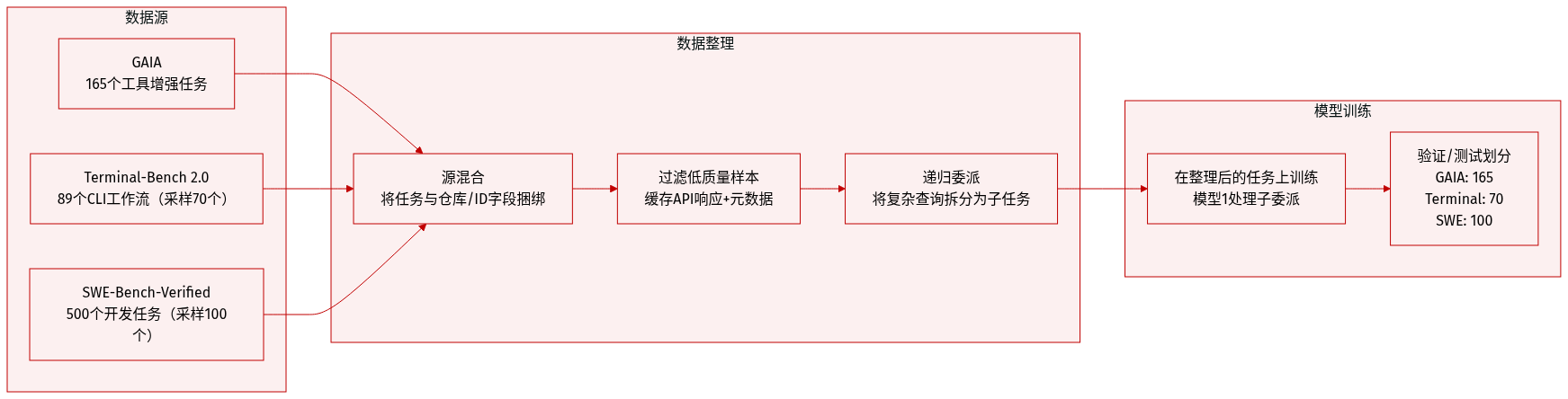
作者使用三个基准数据集进行评估:GAIA、Terminal-Bench 2.0 和 SWE-Bench-Verified。GAIA 包含 165 个测试工具增强多步推理的任务;Terminal-Bench 2.0 包含 89 个真实世界命令行工作流(其中 70 个用于成本采样);SWE-Bench-Verified 包含 500 个软件工程任务(其中 100 个采样),所有任务均通过测试执行和人工筛选验证。
-
每个任务均结构化为包含仓库和实例 ID 字段的指令模板。代理系统将复杂查询——例如识别 2015 年大都会展览的生肖人物——分解为带有详细指令、上下文和模型分配的委派子任务。
-
模型采用递归委派策略:初始尝试识别展览和藏品编号;后续尝试细化对象识别和手部可见性检查;最终决策将发现综合为单一答案(例如,“11”只可见的手)。
-
第三方 API(网络搜索、沙盒环境)仅通过受控工具接口访问。响应与元数据(URL、时间戳、查询)一起缓存,以确保可复现性和一致评估。
方法
作者利用一种统一的、以编排器为中心的架构 AORCHESTRA 解决复杂、长视野的代理任务。其核心创新在于将子代理视为动态可创建的执行器,由四元组接口 (I,C,T,M) 参数化,其中 I 为任务指令,C 为整理后的上下文,T 为工具集,M 为底层模型。该抽象将工作记忆(指令和上下文)与能力(工具和模型)解耦,支持每个子任务按需专业化。
参考框架图,其展示了编排器的迭代过程。系统从用户任务开始,由编排代理将其分解为子任务。在每一步 t,编排器从其受限动作空间 AAORCHESTRA={Delegate(Φt),Finish(y)} 中采样动作 at。若动作为 Delegate,编排器实例化一个具有指定四元组 Φt=(It,Ct,Tt,Mt) 的动态子代理。该子代理使用模型 Mt 执行子任务,受限于工具集 Tt,且仅以 (It,Ct) 为条件。完成后,它返回结构化观察 ot——通常包括结果摘要、产物和错误日志——并通过状态转移函数 δ(st,at,ot) 整合到下一系统状态 st+1 中。该过程重复,直至编排器选择 Finish,输出最终答案 y。
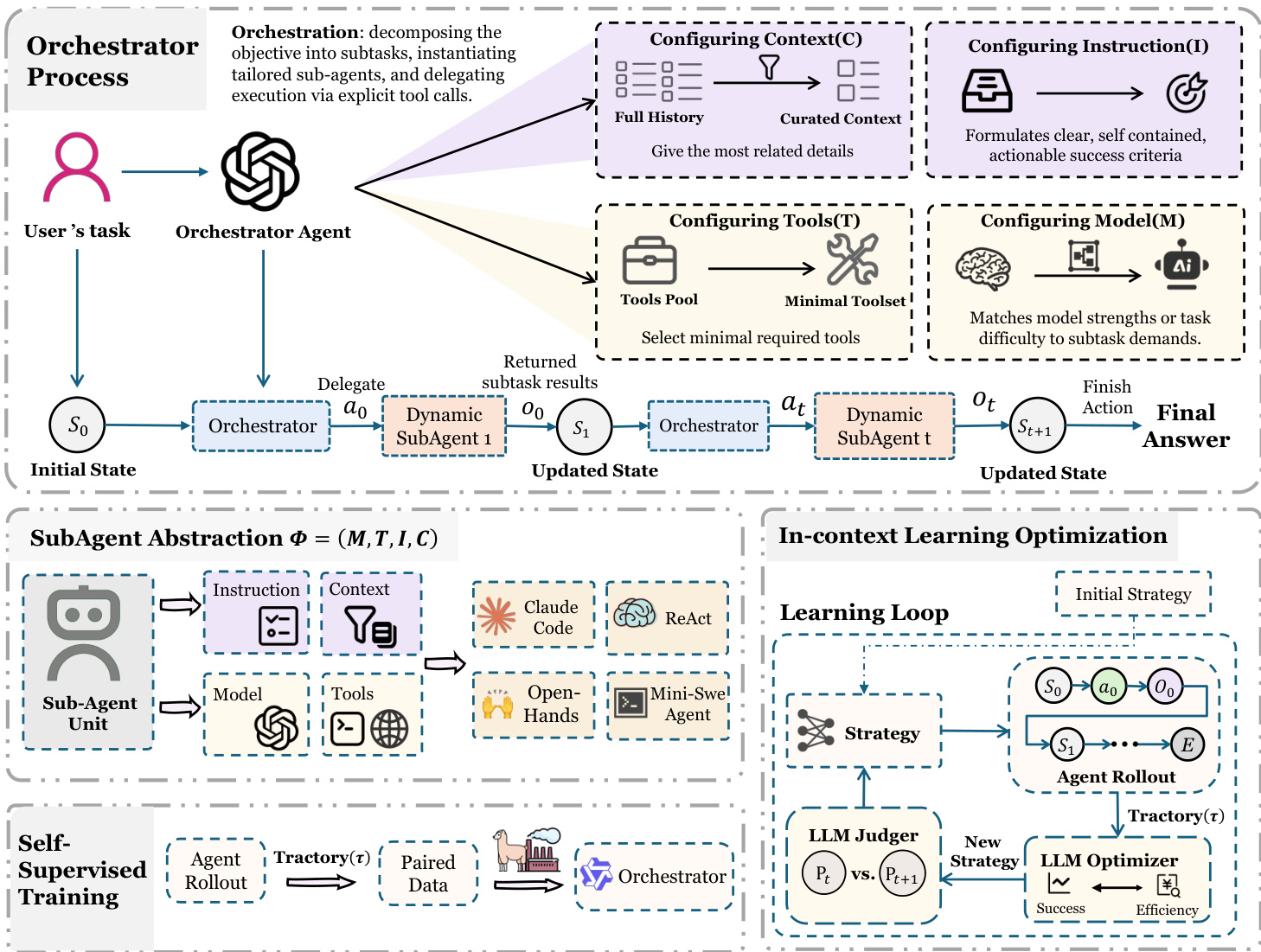
编排器的设计明确区分编排与执行:它从不直接执行环境动作,而是将所有执行委托给动态实例化的子代理。这使每个子任务在上下文、工具和模型选择上实现细粒度控制。例如,编排器可通过过滤完整历史来整理上下文,仅提供最相关的细节;通过从工具池中选择最小必要子集来配置工具;并根据子任务需求匹配模型能力——如为简单任务选择更便宜的模型,或为复杂推理选择更强的模型。
该框架还支持两种互补的学习范式以改进编排器策略 πθ(at∣st)。首先,监督微调(SFT)从专家轨迹中提炼知识,以改进任务编排——增强子任务分解和 (It,Ct,Tt) 的合成。其次,迭代上下文内学习无需更新模型权重即可优化成本感知编排。此处,编排器的指令 Imain 被视为可学习对象。在展开轨迹 τk 后,优化器分析性能和成本指标,提出提示编辑 ΔI,更新指令为 Ik+1main=OPTIMIZE(Ikmain,τk,Perf(τk),Cost(τk))。该循环旨在发现性能与成本之间的帕累托最优权衡,例如为非关键子任务选择更便宜的模型。
子代理抽象与实现无关,允许从简单的 ReAct 循环到小型 SWE 代理等多样内部设计,同时保持与编排器的一致接口。这种灵活性结合显式能力控制和可学习编排,使 AORCHESTRA 能在无需训练的情况下实现强大性能,并适应各基准测试中的成本-性能权衡。
实验
- AORCHESTRA 在 GAIA、Terminal-Bench 2.0 和 SWE-Bench-Verified 上持续优于基线系统,在 pass@1 和 pass@3 指标上取得显著提升,尤其当使用 Gemini-3-Flash 作为编排器时。
- 编排器与子代理之间的上下文共享至关重要:整理后的任务相关上下文比无上下文或完整上下文继承更能提升性能,减少噪声并保持执行保真度。
- 编排是一种可学习的技能:微调较小模型(Qwen3-8B)进行任务委派可提升性能,上下文内学习可实现成本感知的模型路由,提高准确性和效率。
- 即插即用子代理展示框架鲁棒性:AORCHESTRA 在更换子代理后端时仍保持强性能,确认其模块化设计和实现独立性。
- 系统展现强大的长视野推理和错误恢复能力:它通过迭代细化假设、传播中间发现并根据子代理反馈调整,成功解决复杂、多尝试任务。
作者通过比较无上下文、完整上下文及其提出的方法,在其代理框架中评估上下文共享策略。结果表明,显式整理并传递相关上下文给子代理显著提升了所有难度级别的性能,获得最高平均分。该设计避免了遗漏关键线索或引入无关历史噪声的缺陷。
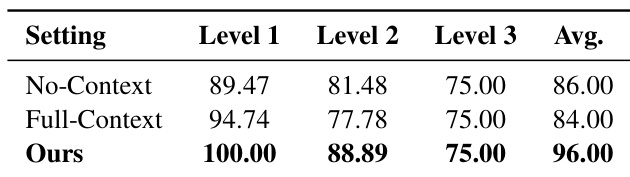
作者使用分层代理框架,其中主编排器将任务委派给专用子代理,在多个基准测试中实现比基线系统更高的准确性。结果表明,显式整理并传递上下文给子代理可提升性能,且对编排器进行微调或上下文内学习可进一步提高准确性和成本效率。系统还表现出鲁棒性,即使使用较小模型或不同子代理后端仍保持强性能。
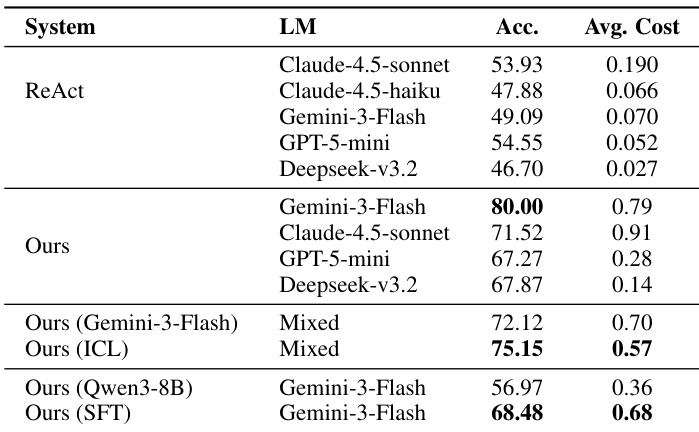
作者使用动态委派任务至专用子代理的编排器框架,在各难度级别上实现比独立基线更高的整体准确性。结果表明,结合编排器与不同子代理风格可提升性能,尤其在中等难度任务上,同时在简单任务上保持强结果。该框架在子代理选择上表现出灵活性,ReAct 风格子代理获得最佳整体准确性。
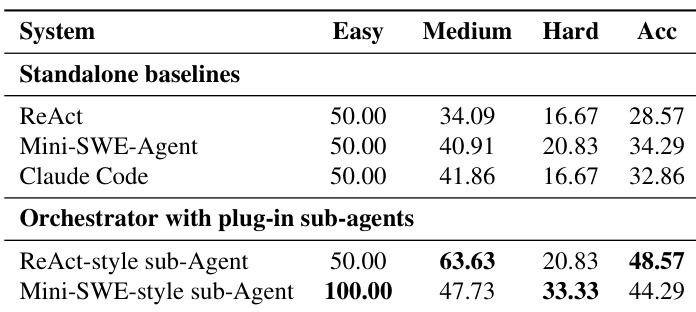
作者使用 AORCHESTRA——一种多代理编排框架——在三个多样化基准测试(GAIA、Terminal-Bench 2.0 和 SWE-Bench-Verified)上优于基线系统。结果表明,在 pass@1 和 pass@3 指标上持续提升,其中 Terminal-Bench 2.0 和 GAIA 上提升最大,表明其在任务类型和模型后端上具有强泛化能力。系统设计——支持上下文感知的子代理委派、可学习编排和即插即用执行——促成了其稳健性能和成本效率。