Command Palette
Search for a command to run...
IQuest-Coder-V1 技术报告
IQuest-Coder-V1 技术报告
摘要
在本报告中,我们推出了 IQuest-Coder-V1 系列(7B/14B/40B/40B-Loop)——一套全新的代码大语言模型(LLMs)家族。与传统的静态代码表征不同,我们提出了一种基于代码流的多阶段训练范式,通过流水线中不同阶段动态捕捉软件逻辑的演化过程。我们的模型通过一条演进式训练流水线构建而成:首先进行初始预训练,涵盖代码事实、代码仓库及代码补全数据;随后引入一个专门的中段训练阶段,在32K上下文长度下融合推理与智能体轨迹,在128K上下文长度下实现仓库级规模的建模,从而构建深层的逻辑基础;最后通过后训练阶段进一步强化特定编码能力,该阶段分为两条专业化路径:思维路径(基于推理驱动的强化学习)与指令路径(优化于通用辅助任务)。IQuest-Coder-V1 在代码智能的关键维度上均展现出当前领先水平,涵盖智能体式软件工程、竞赛编程以及复杂工具使用等场景。为应对实际部署中的资源约束,IQuest-Coder-V1-Loop 变体引入了一种循环机制,旨在优化模型容量与部署开销之间的权衡,提供一种架构层面增强的高效能-高效率平衡路径。我们相信,IQuest-Coder-V1 系列的发布——包括从预训练基础模型到最终思维模型与指令模型的完整白盒检查点链——将显著推动自主代码智能与真实世界智能体系统的研究进展。
一句话总结
IQuest-Coder-V1 团队推出了 7B/14B/40B/40B-Loop 代码大语言模型系列,采用“代码流多阶段训练范式”进行训练:首先在代码事实和代码库上进行预训练,接着在 32k 和 128k 上下文长度下进行包含推理与代理轨迹的中期训练,最后通过推理驱动的强化学习与指令优化双路径进行后训练,在代理式软件工程、竞赛编程和复杂工具使用方面达到当前最佳性能。
核心贡献
- 我们提出“代码流多阶段训练范式”,通过在代码事实和代码库上预训练、在 32k–128k 上下文长度下进行推理与代理轨迹中期训练、以及通过推理驱动的强化学习与指令微调进行双路径后训练,逐步演化软件逻辑。
- IQuest-Coder-V1 在代理式软件工程、竞赛编程和复杂工具使用等基准测试中达到当前最佳性能,包括通过 40B-Loop-Thinking 模型在 LiveCodeBench v6 上的表现,以及在 40B-Loop-Instruct 变体上评估的其他任务。
- IQuest-Coder-V1-Loop 变体引入循环机制以优化部署时的容量-效率权衡,且从预训练基础模型到最终模型的完整开源训练流程支持可复现性,并推动自主代码智能研究。
引言
作者采用新颖的“代码流多阶段训练范式”构建 IQuest-Coder-V1,这是一系列旨在建模软件逻辑在开发各阶段动态演化的代码大语言模型。以往模型常将代码视为静态,限制了其处理需跨仓库规模上下文和演进逻辑的复杂现实工程任务的能力。为此,作者引入一个进化式训练流程:在 32k 和 128k 上下文窗口下进行专门的中期训练,随后通过双路径后训练——推理驱动的强化学习用于深度分析,指令微调用于通用辅助。其主要贡献包括在代理式软件工程、竞赛编程和工具使用方面达到当前最佳性能,以及使用循环机制优化部署效率而不牺牲能力的 IQuest-Coder-V1-Loop 变体。作者还开源了完整的训练链,以加速自主代码系统研究。
数据集

作者使用多阶段、高度精选的数据集训练 IQuest-Coder,结合网络规模语料库与领域特定代码及推理数据。数据集结构与用途如下:
-
通用语料库(第一阶段):
- 主要来源为 Common Crawl,通过正则表达式过滤和分层去重(精确 + 基于嵌入模型的模糊匹配)清洗。
- 去污染处理,排除与标准基准重叠的数据。
- 代码片段通过 AST 分析验证语法有效性,支持代码流训练。
- 使用领域特定代理分类器(小型模型训练以模拟大型模型)按信息密度、教育价值和毒性过滤数据,优于 FastText 基线。
- 集成 CodeSimpleQA-Instruct(6600 万样本),注入由 LLM 在约束下生成的事实性、客观问答对,确保时间不变性和单一正确答案。
-
仓库演进数据:
- 构建为三元组:(R_old, P, R_new),其中 R_old 和 R_new 为代码生命周期 40%-80% 百分位(成熟阶段)的状态,P 为两者之间的补丁。
- 确保时间连续性和有意义的代码变更,避免早期不稳定或后期碎片化。
-
代码补全数据(FIM 格式):
- 在文件和仓库级别使用 Fill-In-the-Middle (FIM) 格式构建:||。
- 文件级:通过随机字符或行边界分割单个文档。
- 仓库级:添加同一仓库中语义相似的代码片段作为上下文。
- 基于语法的构建使用 AST 提取表达式、语句和函数级别的片段,保持结构完整性。
- 任务格式包括:<fim_prefix>{pre}|{suf}|{mid}|{im_end}|>(文件)和 <repo_name>{repo} <|file_sep|>{path1} {content1} <|file_sep|>{path2} {content2} <|file_SEP|>{path3} ... {pre}|{suf} <fim_middle|>{mid}|{im_end}|>(仓库)。
-
中期训练(第二阶段):
- 使用相同核心数据类别:推理问答(数学、编码、逻辑)、代理轨迹、代码提交和 FIM 数据。
- 推理问答教授结构化分解与一致性;代理轨迹通过行动-观察-修订循环(含日志、错误、测试反馈)模拟闭环智能。
- 第二阶段 1 在 32K 上下文训练;第二阶段 2 扩展至 128K,支持仓库规模推理。
-
评估基准:
- CrossCodeEval(Python、Java、TypeScript、C#)测试跨文件补全。
- Aider 的 Polyglot 基准(C++、Go、Java、JavaScript、Python、Rust)在 225 个最难的 Exercism 问题上评估多语言编辑。
所有数据均经过严格质量过滤与结构验证,以支持可扩展、高保真度的代码建模。
方法
作者采用结构化多阶段训练流程——称为“代码流流程”——系统性地演化 IQuest-Coder-V1 系列的逻辑与代理能力。该框架分为三个主要阶段:预训练与退火、中期训练、双路径后训练,每个阶段旨在逐步专业化模型同时保留通用智能。流程始于预训练与退火阶段:模型首先在第一阶段接触通用与代码特定数据的混合,随后进入仅针对高质量精选代码语料库的退火阶段。这通过强化真实代码库中固有的语法与语义模式,为复杂推理任务奠定基础。请参考框架图了解此初始阶段的流程。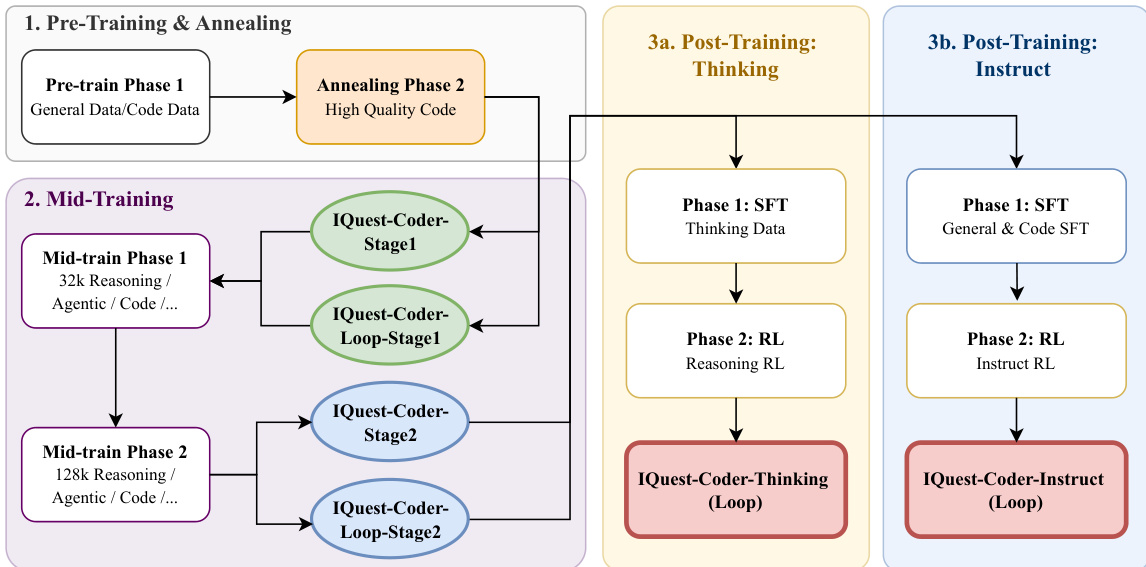 中期训练引入两个顺序阶段,逐步扩展上下文长度与任务复杂度。在中期训练第一阶段,模型在 32k 上下文数据上训练,涵盖推理、代理和代码任务,生成中间检查点如 IQuest-Coder-Stage1 和 LoopCoder-Base-Stage1。此阶段对建立长视野推理基础至关重要。中期训练第二阶段将上下文扩展至 128k,同时保持相似数据分布,生成 IQuest-Coder-Stage2 和 LoopCoder-Base-Stage2,作为后训练的基础。作者强调,在退火后、后训练前注入 32k 推理轨迹可稳定分布偏移下的性能,该发现通过消融研究得到验证。后训练分为两条不同路径:思考路径与指令路径。思考路径首先在包含显式推理轨迹的数据集上进行监督微调(SFT),随后通过优化推理保真度的强化学习(RL)训练,生成 LoopCoder-Thinking,该模型在软件工程与竞赛编程等长视野任务中表现出自主错误恢复能力。指令路径则在通用与代码指令跟随数据上进行 SFT,随后通过优化指令遵循的 RL 训练,生成 LoopCoder-Instruct。两条路径均采用 LoopCoder 架构,该架构使用循环 Transformer 设计,包含两个固定迭代:第一轮处理输入嵌入并使用位置偏移的隐藏状态,第二轮计算全局注意力(关注第一轮所有键值对)与局部因果注意力(仅关注第二轮中前序标记)的门控混合。该架构允许对复杂代码段进行迭代精炼,无需标记偏移机制。训练基础设施通过融合门控注意力内核减少内存带宽,通过上下文并行支持超长上下文训练,通过确定性重计算实现静默错误检测。数据构建以模型为中心,依赖前沿 LLM 在自动验证下生成训练样本,包括基于执行的客观领域验证和多智能体辩论的主观领域验证。监督微调采用激进序列打包、带扩展低速率阶段的余弦退火、以及按难度排序数据的三阶段课程,确保稳定收敛。强化学习采用 GRPO 算法与 clip-Higher 策略,基于测试用例通过率训练且无 KL 惩罚,并通过 SWE-RL 框架进一步增强,该框架将软件工程建模为交互式 RL 环境,以工具操作为动作,以测试套件通过率和效率正则化为奖励。作者还通过将语言比例 p=(p1,ldots,pK) 引入损失函数,形式化多语言代码缩放定律:mathcalL(N,D;p)=AcdotN−alphaN(p)+BcdotDgamma−alphaD(p)+Linfty(p) 其中 alphaN(p)=sumkpkalphaNk,alphaD(p)=sumkpkalphaDk,和 Linfty(p)=sumppLinftyk 为语言特定参数的比例加权平均。有效数据项捕捉跨语言迁移:Dx=Dallleft(1+gammasumLieqLjpLipLjauijight) 其中 auij 为从经验协同增益导出的迁移系数。在最优多语言分配下,最终拟合的缩放定律为:mathcalL∗(N,D)=A∗cdotN−alphaN∗+B∗cdotD−alphaD∗+Linfty∗ 其中 alphaD∗=0.6859,alphaN∗=0.2186,和 Linfty∗=0.2025。该公式支持高效分配多语言代码数据,以最大化生成与翻译任务的性能。
中期训练引入两个顺序阶段,逐步扩展上下文长度与任务复杂度。在中期训练第一阶段,模型在 32k 上下文数据上训练,涵盖推理、代理和代码任务,生成中间检查点如 IQuest-Coder-Stage1 和 LoopCoder-Base-Stage1。此阶段对建立长视野推理基础至关重要。中期训练第二阶段将上下文扩展至 128k,同时保持相似数据分布,生成 IQuest-Coder-Stage2 和 LoopCoder-Base-Stage2,作为后训练的基础。作者强调,在退火后、后训练前注入 32k 推理轨迹可稳定分布偏移下的性能,该发现通过消融研究得到验证。后训练分为两条不同路径:思考路径与指令路径。思考路径首先在包含显式推理轨迹的数据集上进行监督微调(SFT),随后通过优化推理保真度的强化学习(RL)训练,生成 LoopCoder-Thinking,该模型在软件工程与竞赛编程等长视野任务中表现出自主错误恢复能力。指令路径则在通用与代码指令跟随数据上进行 SFT,随后通过优化指令遵循的 RL 训练,生成 LoopCoder-Instruct。两条路径均采用 LoopCoder 架构,该架构使用循环 Transformer 设计,包含两个固定迭代:第一轮处理输入嵌入并使用位置偏移的隐藏状态,第二轮计算全局注意力(关注第一轮所有键值对)与局部因果注意力(仅关注第二轮中前序标记)的门控混合。该架构允许对复杂代码段进行迭代精炼,无需标记偏移机制。训练基础设施通过融合门控注意力内核减少内存带宽,通过上下文并行支持超长上下文训练,通过确定性重计算实现静默错误检测。数据构建以模型为中心,依赖前沿 LLM 在自动验证下生成训练样本,包括基于执行的客观领域验证和多智能体辩论的主观领域验证。监督微调采用激进序列打包、带扩展低速率阶段的余弦退火、以及按难度排序数据的三阶段课程,确保稳定收敛。强化学习采用 GRPO 算法与 clip-Higher 策略,基于测试用例通过率训练且无 KL 惩罚,并通过 SWE-RL 框架进一步增强,该框架将软件工程建模为交互式 RL 环境,以工具操作为动作,以测试套件通过率和效率正则化为奖励。作者还通过将语言比例 p=(p1,ldots,pK) 引入损失函数,形式化多语言代码缩放定律:mathcalL(N,D;p)=AcdotN−alphaN(p)+BcdotDgamma−alphaD(p)+Linfty(p) 其中 alphaN(p)=sumkpkalphaNk,alphaD(p)=sumkpkalphaDk,和 Linfty(p)=sumppLinftyk 为语言特定参数的比例加权平均。有效数据项捕捉跨语言迁移:Dx=Dallleft(1+gammasumLieqLjpLipLjauijight) 其中 auij 为从经验协同增益导出的迁移系数。在最优多语言分配下,最终拟合的缩放定律为:mathcalL∗(N,D)=A∗cdotN−alphaN∗+B∗cdotD−alphaD∗+Linfty∗ 其中 alphaD∗=0.6859,alphaN∗=0.2186,和 Linfty∗=0.2025。该公式支持高效分配多语言代码数据,以最大化生成与翻译任务的性能。
实验
我们的模型在代码生成、推理、效率和代理任务上与包括 Claude、GPT、Gemini、Qwen 和 StarCoder2 在内的广泛当前最佳基线模型对比评估。在 EvalPlus、BigCodeBench、FullStackBench 和 LiveCodeBench 上代码生成表现强劲;在 CRUXEval 上正向与逆向推理表现优异;在 Mercury 上运行效率得分具有竞争力,在 Spider 和 BIRD 上 Text-to-SQL 表现良好。在代理场景中,其在 SWE-bench Verified 上获得 76.2 分,在 Terminal-Bench 和 Mind2Web、BFCL 等通用工具使用基准上表现稳健,同时在 Tulu 3 基准上保持高安全合规性,对有害提示表现出平衡的拒绝行为。
作者评估了六种编程语言的代码生成性能,报告了与基线模型相比的得分和相对变化。结果显示大多数语言对表现持续提升,Java 和 TypeScript 提升显著,而部分情况下 Python 和 C# 略有下降。Java 到 JavaScript 提升 12.62%,Python 到 C# 和 Python 到 Rust 分别下降 1.69% 和 2.72%,TypeScript 到 JavaScript 和 Go 到 Rust 分别提升 4.69% 和 2.86%。

作者评估了多个代码生成模型在 Python、Java、TypeScript 和 C# 上的表现,报告精确匹配与编辑相似度得分。IQuest-Coder-V1-40B 在平均编辑相似度上表现最佳,在精确匹配上也表现强劲,优于大多数 20B+ 模型。结果表明其在功能正确性与结构相似性上跨编程语言均具竞争力。IQuest-Coder-V1-40B 在 20B+ 模型中平均编辑相似度最高(85.7),在 Java 上精确匹配最佳(57.9),在 Python(49.0)和 C#(63.4)上表现强劲。StarCoder2-7B 表现最差,平均精确匹配最低(8.3),编辑相似度最低(70.8)。

作者在代理式编码与通用工具使用任务上评估其模型,与开源和闭源 API 模型对比。结果显示该模型在 Terminal-Bench、SWE-Verified、Mind2Web 和 BFCL V3 上表现具有竞争力,尤其在 SWE-Verified 上以 76.2 分表现突出。相对于同等规模的开源模型表现强劲,接近部分闭源系统。IQuest-Coder-V1-40B-Loop-Instruct 在 SWE-Verified 上得分为 76.2,优于大多数开源模型。在 Terminal-Bench 上得分为 52.5,在 Mind2Web 上得分为 64.3,显示广泛的代理能力。在 BFCL V3 上得分为 73.9,表明其在多步工具使用推理上表现强劲。

作者使用 Bird 和 Spider 基准评估多个代码导向语言模型的 Text-to-SQL 任务。结果显示 IQuest-Coder-V1-40B-Instruct 在 Bird 上得分为 70.5,在 Spider 上得分为 92.2,优于大多数开源模型,与多个闭源系统持平或超越。表格突出了不同模型规模与架构的性能差异,闭源 API 模型通常在执行准确性上表现强劲。IQuest-Coder-V1-40B-Instruct 在开源模型中以 92.2 的 Spider 准确率领先,闭源 API 模型如 Gemini-3-Flash-preview 在 Spider 上得分为 87.2,Qwen3-Coder-480B-A35B-Instruct 在 Spider 上得分为 81.2,尽管其 Bird 得分较低。

作者在 CruxEval 和 LiveCodeBench 基准上评估多个代码导向语言模型,按参数规模与架构分组。结果显示 IQuest-Coder-V1 变体,特别是 40B Loop-Thinking 模型,在 Output-COT 和 LiveCodeBench V6 上表现最佳,优于许多更大或闭源模型。闭源 API 模型如 Gemini-3 和 Claude-Opus-4.5 仍具竞争力,但未在所有指标上持续超越最佳开源模型。IQuest-Coder-V1-40B-Loop-Thinking 在 Output-COT 上以 99.4 分领先,在 LiveCodeBench V6 上得分为 81.1。闭源 API 模型如 Gemini-3-Flash-preview 在 CruxEval 上得分高,但在 LiveCodeBench V6 上落后。Qwen3-235B-A22B-Thinking-2507 在 CruxEval Output-COT 上表现强劲(89.5),但 LiveCodeBench 得分较低。

作者评估 IQuest-Coder-V1-40B 在跨语言代码生成、代理式编码、Text-to-SQL 和代码推理基准上的表现,显示在 Java 和 TypeScript 翻译上持续提升,同时注意到 Python 和 C# 略有下降。该模型在平均编辑相似度(85.7)和 Java(57.9)、C#(63.4)、Python(49.0)的精确匹配得分上表现最佳,优于大多数 20B+ 模型,并在代理任务中表现优异:SWE-Verified 得分为 76.2,Terminal-Bench 得分为 52.5,BFCL V3 得分为 73.9。在 Text-to-SQL 上,其在开源模型中以 Spider 92.2 和 Bird 70.5 领先,其 Loop-Thinking 变体在 Output-COT(99.4)和 LiveCodeBench V6(81.1)上表现最佳,与多个闭源系统相当或超越。