HyperAI
Command Palette
Search for a command to run...
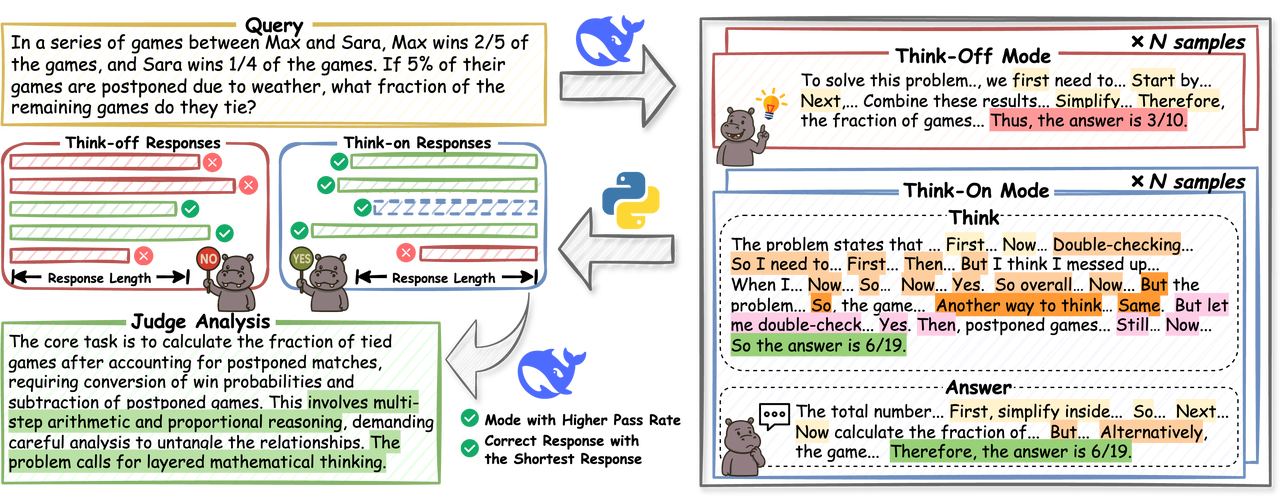
HiPO 混合策略优化框架
HiPO(Hybrid Policy Optimization)是由快手联合南京大学的研究团队于 2025 年 9 月提出的,相关研究成果发表于论文「HiPO: Hybrid Policy Optimization for Dynamic Reasoning in LLMs」。
HiPO 是一个用于自适应推理控制的框架,使 LLMs 能够选择性地决定何时进行详细推理(Think-on)以及何时直接响应(Think-off)。具体而言,HiPO 结合了一个混合数据管道,提供配对的 Think-on 和 Think-off 响应,以及一个混合强化学习奖励系统,该系统在平衡准确性和效率的同时避免过度依赖详细推理。在数学和编程基准测试中的实验表明,HiPO 可以显著减少令牌长度,同时保持或提高准确性。