Command Palette
Search for a command to run...
Dataset Compilation | Open-source Inference Datasets From NVIDIA, OpenAI, and Multiple Research Institutions, Covering Mathematics, Panoramic Space, Wiki Question Answering, Research Tasks, Visual Commonsense, etc.

As large models evolve from simply "being able to speak and write" to "being able to reason and think," the importance of data is being redefined.
In the past, massive general-purpose corpora supported the expressive power of language models; today, the real hurdle determining the upper limit of models is gradually shifting to reasoning data with clear structure, rigorous logic, and multi-step deduction processes. Whether it's complex mathematical problems, cross-domain knowledge question answering, or multi-step decision-making and tool invocation capabilities, all rely on the support of high-quality reasoning datasets.
Inference datasets may focus on mathematics and logic, or construct complex reasoning chains through synthesis. They can also be used for multi-task ability assessment, or serve as scientific benchmarks and question-answering system optimization. However, these data resources also exhibit significant fragmentation, often existing in different formats, making them difficult to use uniformly. This causes many developers and researchers to spend a considerable amount of time just "finding data."
therefore,HyperAI has compiled a collection of high-quality inference datasets, covering multi-domain, multi-task inference, synthetic inference training data, scientific research benchmarks, and large-scale question-answering data.It also supports downloading or using datasets online, lowering the barrier to entry for using inference datasets.
More high-quality datasets:
Open-RL Inference Problem Dataset
* Use online:
Open-RL is a multi-domain reasoning problem dataset released by Turing in 2026, containing independent, verifiable, and explicit STEM reasoning problems in physics, mathematics, biology, and chemistry.
Each problem requires multi-step reasoning, involves symbolic operations and/or numerical computation, and has an objectively verifiable final answer. This dataset is suitable for reinforcement learning fine-tuning, reward modeling, outcome-supervised training, and verifiable reasoning benchmarking.
CHIMERA General Inference Synthetic Dataset
* Use online:
CHIMERA is a synthetic reasoning dataset designed specifically for reasoning training, covering a wide range of STEM subjects and providing long chain of thought (CoT) trajectories.
This dataset contains 9,225 questions across 8 subjects (mathematics, computer science, chemistry, physics, literature, history, biology, and phonetics). All examples are generated by a large language model (LLM) and are automatically validated without manual annotation.
Subject distribution:
* Mathematics: 4,452
*Computer Science: 1,303
*Chemistry: 1,102
*Physics: 742
*Literature: 504
*History: 422
*Biology: 383
*Linguistics: 317
Nemotron-Math-v2 Mathematical Inference Dataset
* Use online:
Nemotron-Math-v2 is a mathematical reasoning dataset released by NVIDIA Corporation. It is primarily used to train LLMs to perform structured mathematical reasoning, study the differences between tool-enhanced reasoning and pure language reasoning, and build long-context or multi-track reasoning systems.
This dataset contains approximately 347,000 high-quality mathematical problems and 7 million model-generated inference trajectories. Each problem is solved in six configurations: high/medium/low inference depth and with or without Python TIR, and the answers are validated via a pipeline using an LLM as the arbiter.
OmniSpatial Panoramic Spatial Reasoning Benchmark Dataset
* Use online:
OmniSpatial is a panoramic spatial reasoning benchmark dataset released in 2025 by Tsinghua University in collaboration with the Shanghai Institute for Advanced Study in Space Technology, the Shanghai Artificial Intelligence Laboratory, and other institutions. The related paper is titled "OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models," which aims to fill the gap in the evaluation of spatial understanding of vision-language models.
This dataset contains approximately 1,533 image-question-answering samples, covering four main categories of spatial reasoning tasks: Dynamic Reasoning, Complex Spatial Logic, Spatial Interaction, and Perspective Taking, totaling 50 sub-tasks. The data sources are diverse, including internet images, psychological tests, and driving test questions. The annotations have undergone multiple rounds of review to ensure quality and diversity. Compared to traditional benchmarks, OmniSpatial avoids template-based construction, more closely resembling real-world complex scenarios. It not only tests basic spatial relationships (such as front/back, left/right, and distance) but also emphasizes multi-object interactions, scene changes, and cross-perspective reasoning.
This dataset is suitable for training and evaluating the spatial reasoning capabilities of large multimodal models, especially in applications such as intelligent navigation, augmented/virtual reality, and complex scene understanding. It is a comprehensive and challenging standardized benchmark dataset.
FrontierScience Inference Research Task Evaluation Dataset
* Use online:
FrontierScience is a dataset for evaluating reasoning and scientific research tasks, released by OpenAI in 2025. It aims to systematically assess the capabilities of large models in expert-level scientific reasoning and scientific research sub-tasks.
This dataset employs a design mechanism of "expert creation + two-layer task structure + automatic scoring mechanism," and is divided into two subsets, corresponding to two types of abilities: closed-ended precise reasoning and open-ended scientific research reasoning.
Olympiad dataset
Originally designed by medal winners and national team coaches of the International Physics, Chemistry and Biology Olympiads, the questions are of a difficulty level comparable to top international competitions such as IPhO, IChO and IBO; focusing on short-answer reasoning tasks, the model is required to output a single numerical value, an algebraic expression or a biological term that can be fuzzily matched, in order to ensure the verifiability of the results and the stability of the automatic evaluation.
Research Dataset
Written by doctoral students, postdoctoral fellows, and professors, the questions simulate sub-problems that may be encountered in real scientific research, covering the three major fields of physics, chemistry, and biology. Each question is accompanied by a fine-grained 10-point scoring system to evaluate the model's performance in several key aspects, beyond just the correctness of the answer, including the completion of modeling assumptions, reasoning paths, and intermediate conclusions.
HotpotQA Question Answering Dataset
* Use online:
The HotpotQA dataset is a large-scale question-and-answer dataset collected from English Wikipedia, containing 113,000 crowdsourced questions. To answer these questions, you need to refer to the introductory paragraphs of two Wikipedia articles.
Each question contains two gold paragraphs and a list of sentences from some of the paragraphs, which provide supporting facts deemed necessary to answer the question. This dataset has the following characteristics:
The question requires searching and reasoning through multiple supporting documents to answer;
* The problems are diverse and not limited by any pre-existing knowledge base or knowledge model;
This dataset provides sentence-level supporting facts needed for reasoning, enabling QA systems to reason and interpret predictions under strong supervision;
This dataset presents a novel fact comparison problem to test the ability of a QA system to extract relevant facts and make necessary comparisons.
VCR Visual Common Sense Reasoning Dataset
* Use online:
VCR stands for Visual Commonsense Reasoning, which is a large-scale dataset for visual common sense reasoning. The dataset asks challenging questions about images, and the machine needs to complete two subtasks: answer the questions correctly and provide reasons to justify its answers.
The VCR dataset contains a large number of questions, 212K for training, 26K for validation, and 25K for testing. The answers and reasons come from more than 110K non-repeated movie scenes.

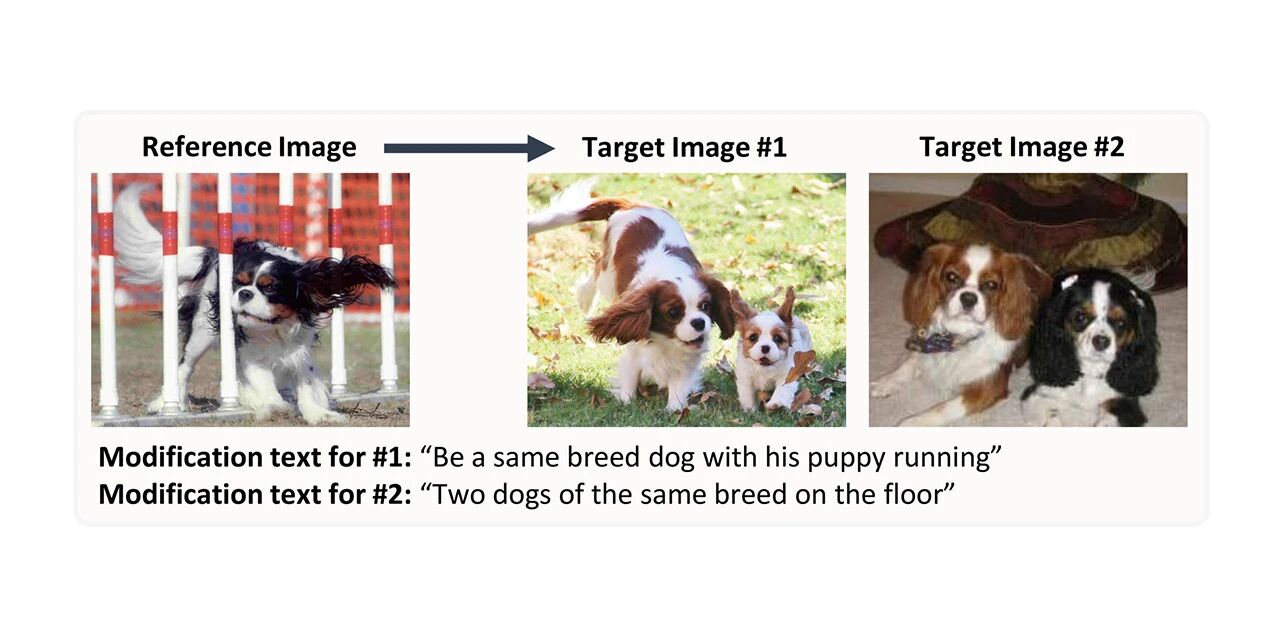
CIRR Image Synthesis Retrieval Dataset
* Use online:
CIRR stands for Compose Image Retrieval on Real-life images, and contains more than 36,000 pairs of crowdsourced, open-domain images and manually generated modified text. The dataset aims to promote future research on subtle reasoning about visual linguistic concepts and iterative retrieval with dialogues, and addresses the shortcomings of existing datasets by placing more emphasis on distinguishing open-domain visually similar images.