Command Palette
Search for a command to run...
Achieve "voice-over Freedom" With Just 3 Seconds of Audio: Mistral open-source Speech Model Voxtral-4B-TTS-2603; Set a New Benchmark for Data Quality: Sutra 10B Pretraining.

Currently, lightweight speech models often struggle to balance naturalness and deployment efficiency when handling complex multilingual contexts and long-form dubbing. In practical applications, speech agents and content broadcasting not only require extremely high language understanding but also demand that the model run with low latency in a local environment and support seamless switching between multiple languages. These demanding scenarios pose challenges to the parameter scale and engineering capabilities of existing open-source models.
In this context,Mistral has officially released the Voxtral-4B-TTS-2603 model. Voxtral TTS is a multilingual zero-shot text-to-speech model based on a hybrid modeling framework. It encodes speech into semantic and acoustic tokens using the Voxtral Codec. The semantic part is aligned with the text through ASR distillation. During the generation phase, an autoregressive model using only the decoder progressively generates semantic tokens to ensure long-range consistency. Simultaneously, a flow-matching model is introduced to efficiently generate acoustic tokens in a continuous space, balancing generation quality and computational efficiency. This hybrid architecture of "semantic autoregression + acoustic flow matching" effectively integrates the advantages of discrete and continuous modeling, enabling the model to achieve high-quality speech cloning with only about 3 seconds of reference speech and exhibiting good generalization ability in multilingual scenarios.
The HyperAI website now features "Voxtral 4B TTS 2603 Multilingual Speech Generation," so give it a try!
Online use:https://go.hyper.ai/AoY2t
A quick overview of hyper.ai's official website updates from March 30th to April 5th:
* High-quality public datasets: 8
* A selection of high-quality tutorials: 10
* Community article interpretation: 3 articles
* Popular encyclopedia entries: 5
Top conferences with April deadlines: 6
Visit the official website:hyper.ai
Selected public datasets
1. Job Board College Student Job Search Dataset
This dataset is a synthetic dataset of the job-seeking process of recent college graduates, containing 100,000 records. It details students' demographic information (such as major, university ranking, and region), academic performance (such as GPA and internships), and their job-seeking application process (application submission, initial interview, second interview, and job offer). For students who successfully receive offers, target variables such as salary, company size, and role relevance are also included.
Direct use:https://go.hyper.ai/Rj94B
2. Groundsource Global Flood Events Dataset
This dataset is a high-resolution historical flood event dataset automatically constructed from global news data, containing 2.6 million flood records covering more than 150 countries. During data processing, the research team used Gemini Large Language Models (LLMs) to systematically extract structured information such as the time and location of flood events from unstructured news texts, achieving automated construction of large-scale historical disaster events.
Direct use:https://go.hyper.ai/Aj8bq
3. Sutra 10B Pretraining Teaching and Training Dataset
This dataset is a high-quality educational dataset for pre-training large language models. Generated by the Sutra framework, it creates structured educational content and optimizes language model pre-training. It is the largest dataset in the Sutra series and is designed to demonstrate how dense, well-curated datasets can provide optimal pre-training performance for small language models.
Direct use:https://go.hyper.ai/okKgZ
4. zh-meme-sft-8k Chinese Internet Meme Culture Dataset
This dataset is a fine-tuning dataset of Chinese internet meme culture instructions, primarily used to train dialogue models to understand and use trending internet memes. The dataset is constructed from comment interactions on social media platforms such as Douyin, Xiaohongshu, and Bilibili, and has undergone multiple rounds of cleaning and enhancement. Its features include dialogue structures from authentic sources, high-quality retention of trending memes after multiple rounds of cleaning, and standardization using the ChatML format.
Direct use:https://go.hyper.ai/O0asZ
5. Creative Professionals Creative Task Instruction Dataset
This dataset is a large-scale, high-fidelity synthetic task dataset designed for the training, evaluation, and fine-tuning of multimodal AI agents. It contains 1,070,917 agent command operations, covering 36 creative, technical, and engineering software environments. The dataset aims to explore complex software interactions and multi-step reasoning.
Direct use:https://go.hyper.ai/Da6qF
6. Nemotron Personas France (French synthetic person dataset)
This dataset, released in 2026 by NVIDIA in collaboration with Pleias, is a French synthetic character dataset. It contains synthetic character data generated based on real French demographics, geography, and personality traits. The aim is to provide diverse synthetic character data to support model development by reflecting the geographical and demographic distribution of France.
Direct use:https://go.hyper.ai/8CmKo
7. Student Mental Health Dataset (Student Mental Health and Burnout)
This dataset is a large-scale synthetic dataset designed to analyze and predict student burnout levels through academic, psychological, and lifestyle factors. It contains 150,000 student records and mixes numerical and categorical features, making it suitable for machine learning, classification, and data analysis tasks.
Direct use:https://go.hyper.ai/YL24S
8. Historical Pandemic & Epidemic: Global Historical Epidemic Dataset
This dataset is a comprehensive record of major global pandemics throughout history, designed to provide an analytically ready resource. It contains 50 major pandemics from the Antonine Plague of 165 AD to COVID-19 and monkeypox in 2023, covering all eras, regions, and pathogen types.
Direct use:https://go.hyper.ai/AbhHY
Selected Public Tutorials
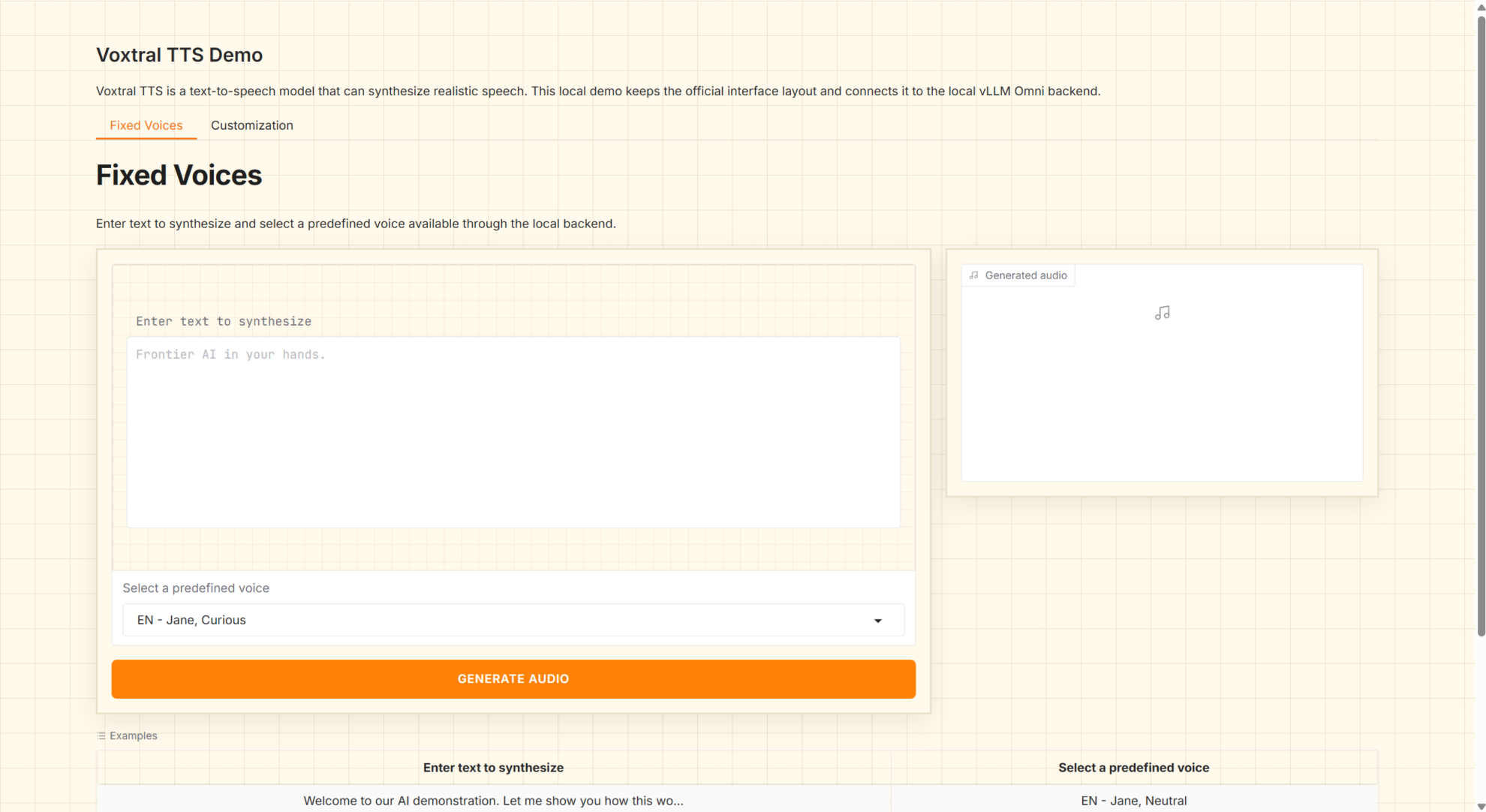
1. Voxtral 4B TTS 2603 Multilingual Speech Generation
Voxtral-4B-TTS-2603 is a 4B-level text-to-speech (TTS) model released by Mistral AI in March 2026. It offers open weights and multilingual speech generation capabilities, supporting the direct synthesis of natural language text into playable audio. This model is designed for scenarios such as voice agents, voice broadcasting, content dubbing, and localized TTS services, and is suitable for local deployment and invocation using standardized service interfaces.
Run online:https://go.hyper.ai/AoY2t
2. LingBot-World: An Open Source World Model
LingBot-World is an open-source world simulator based on video generation. As a top-tier world model, it boasts a high-fidelity environment, long-term memory capabilities, and real-time interactivity. LingBot-World employs an advanced video generation architecture, capable of generating high-quality videos with spatiotemporal consistency based on input images, text prompts, and camera pose signals.
Run online:https://go.hyper.ai/fzF6R
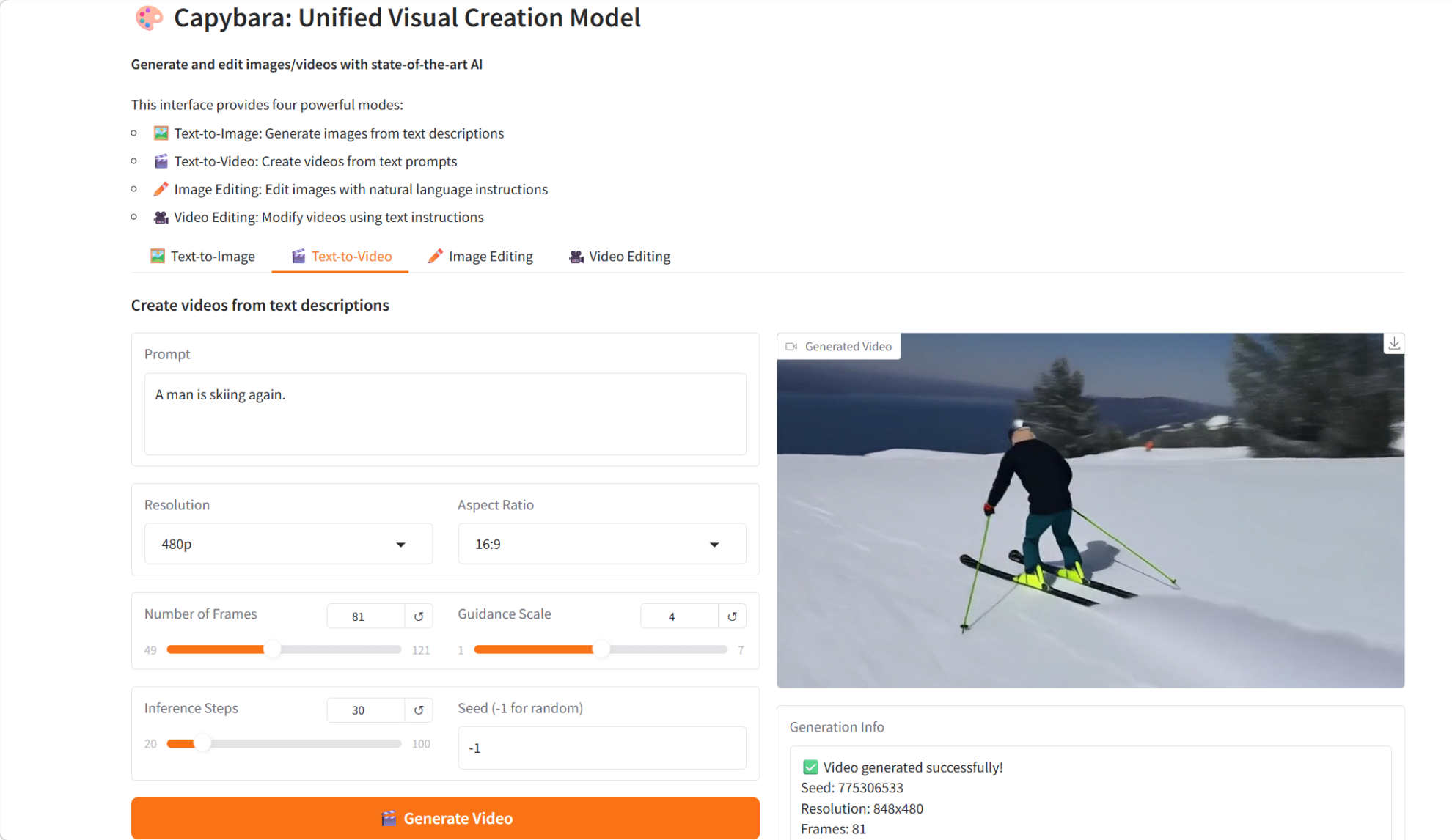
3. Capybara: A unified visual creation model
Capybara, released by the xgen-universe team in February 2026, is a unified visual creation model designed to handle various visual creation tasks, including text-to-image generation, text-to-video generation, instruction-based image editing, and instruction-based video editing. Built on an advanced diffusion model and Transformer architecture, Capybara aims to provide a unified and efficient framework for visual generation and editing.
Run online:https://go.hyper.ai/yX0Pc
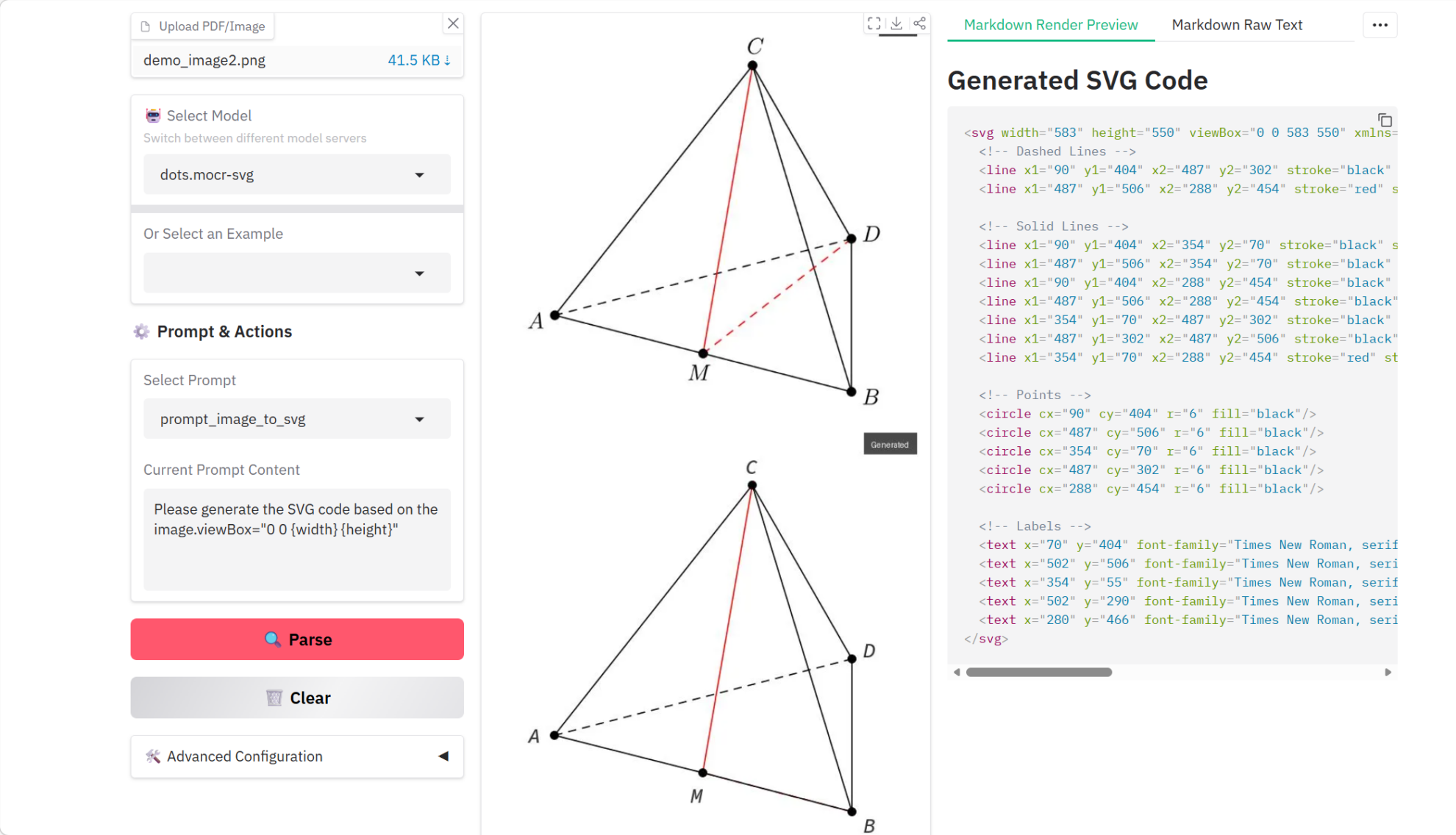
4. dots.mocr Multimodal Document Parsing Tutorial
dots.mocr is a multimodal OCR document parsing model jointly released by Huazhong University of Science and Technology and Xiaohongshu HI-Lab in March 2026. Among models of similar scale, it achieves state-of-the-art (SOTA) performance on standard multilingual document parsing tasks. In addition to document parsing, dots.mocr also excels at directly converting structured graphics (such as charts, UI layouts, scientific diagrams, etc.) into SVG code.
Run online:https://go.hyper.ai/g2oB3
5. Qianfan-OCR: End-to-End Intelligent Document Model
Qianfan-OCR is an end-to-end document intelligence model open-sourced by Baidu AI Cloud Qianfan in March 2026. Based on a 4B parameter visual language architecture, it integrates document parsing, layout analysis, text recognition, and semantic understanding. Its core innovation lies in the Layout-as-Thought mechanism: before generating results, the model enters a "thinking phase," explicitly modeling the document structure (such as element positions, types, and reading order) before completing the overall parsing. This allows for a unified framework that balances structure awareness and semantic understanding, improving accuracy and stability in complex document scenarios.
Run online:https://go.hyper.ai/WZIRF
6. Deploying sarvam-30b using vLLM + Open WebUI
Sarvam-30B is an open-source large language model released by Sarvam AI in March 2026. As the 30B version in Sarvam's latest open-source model series, it adopts a Mixture-of-Experts (MoE) architecture, with a total parameter size of 30B and approximately 2.4B parameters activated per token. It has been systematically optimized for multilingual dialogue, inference, encoding, and practical deployment scenarios.
Run online:https://go.hyper.ai/UUJWe
7. Phi-4-reasoning-vision-15B Multimodal Reasoning Visual Model Demo
Phi-4-reasoning-vision-15B is a 15 billion parameter multimodal reasoning visual language model released by Microsoft in March 2026. Based on the Phi-4 architecture, this model combines powerful text reasoning and visual understanding capabilities, enabling it to handle complex text-image reasoning tasks.
Run online:https://go.hyper.ai/JQlDE
8. Slime: A SGLang-Native post-training framework designed for RL Scaling
Slime is an LLM post-training framework released by the Knowledge Engineering Lab (THUDM) at Tsinghua University, specifically designed for extending reinforcement learning. This framework achieves a perfect combination of high-performance training and flexible data generation by connecting Megatron and SGLang.
Run online:https://go.hyper.ai/Xrxev
9. One-click deployment of NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4
The NVIDIA Nemotron 3 Super NVFP4 was released by NVIDIA Corporation in March 2026. This model is a large language model with 120 total parameters and 12 activation parameters, employing a LatentMoE hybrid architecture and supporting contexts of up to 1M tokens. It is designed for scenarios involving long-context reasoning, agent workflows, tool calls, RAGs, and high-throughput question answering. In terms of interaction, the model supports both enabling and disabling a reasoning mode and allows switching between normal question answering and enhanced reasoning modes via standardized chat template parameters.
Run online:https://go.hyper.ai/WJmbe
10. One-click deployment of Qwen 3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled is a high-performance dialogue model developed by Jackrong in March 2026. It is based on the Qwen3.5-27B platform model and incorporates Claude-4.6 and Opus reasoning capabilities for knowledge distillation. This model significantly enhances complex reasoning abilities and the interactive dialogue experience while maintaining the original language understanding capabilities.
Run online:https://go.hyper.ai/SNlOk
Community article interpretation
1. Based on simulated spectral data of 2,000 semiconductor materials, an MIT team proposed DefectNet, which can analyze six coexisting substitution defects.
A research team from MIT has proposed a fundamental machine learning model, DefectNet, that can directly predict the chemical types and concentrations of substitution point defects from vibrational spectra, even in the case of multiple elements coexisting. The model demonstrates good generalization ability in unseen crystals containing 56 elements and can be fine-tuned using experimental data.
View the full report:https://go.hyper.ai/4qtAH
2. AI discovers 118 new exoplanets! A team from the University of Warwick proposed RAVEN, enabling one-to-one comparison of planetary scenarios with each false positive scenario.
A research team from the University of Warwick has proposed RAVEN, a novel screening and validation process for TESS candidates. This process introduces a synthetic training dataset, moving beyond reliance solely on Threshold Out-of-Bounds (TCE) data generated by the task itself. This improvement significantly expands and enhances the parameter space of planetary and false positive scenarios covered by the machine learning model. On an independent external test set containing 1361 pre-classified TESS candidates, the process achieved an overall accuracy of 91%, demonstrating its effectiveness in automatically ranking TESS candidates.
View the full report:https://go.hyper.ai/phEO5
3. MIT proposed VibeGen, the first end-to-end dynamic protein generation model, which achieves a bidirectional mapping between sequence and vibration.
A research team from MIT and Carnegie Mellon University has proposed VibeGen, a protein-generating intelligent agent model that enables de novo protein design by combining sequence generation with vibrational dynamics prediction. The results show that proteins designed by this generative agent can not only fold into stable and novel structures, but also reproduce the distribution characteristics of target vibrational amplitudes at the main chain level.
View the full report:https://go.hyper.ai/jDaSW
Popular Encyclopedia Articles
1. Reverse sorting combined with RRF
2. Artificial Neural Networks (NNs)
3. Visual Language Model (VLM)
4. Rotational Position Encoding (RoPE)
5. Bidirectional Long Short-Term Memory (Bi-LSTM)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!