Command Palette
Search for a command to run...
Zero-sampling TTS Breakthrough! A Few Seconds of Reference Audio, OmniVoice Helps You Easily Clone Hundreds of Languages; 17 Languages All in One Go: MDPbench Solves the Major Problem of Parsing low-resource Text systems.

Existing zero-shot text-to-speech (TTS) models typically only support a limited number of languages, ignoring a large number of low-resource languages. To overcome this limitation,Xiaomi AI Labs' next-generation Kaldi team has launched OmniVoice—a large-scale, multilingual, zero-shot TTS model that supports over 600 languages.It abandons the cumbersome traditional two-stage cascaded architecture and adopts a streamlined single-stage discrete non-autoregressive (NAR) framework to directly map text to acoustic markers. Trained on 581,000 hours of pure open-source data, OmniVoice achieves the broadest language coverage to date.
Currently, the HyperAI website has launched [the relevant section/feature].OmniVoice: Supports high-quality TTS in 600+ languagesCome and try it!
Online use:https://go.hyper.ai/BvKri
Welcome to visit our official website for more information:
A quick overview of hyper.ai's official website updates from April 11th to April 17th:
* High-quality public datasets: 11
* A selection of high-quality tutorials: 6
* Community article analysis: 2 articles
* Popular encyclopedia entries: 5
Top conferences with April deadlines: 2
Visit the official website:hyper.ai
Selected public datasets
1. Stroke Risk Dataset
Stroke Risk is a dataset for stroke risk analysis and prediction in the healthcare context. Built upon common clinical risk factors, this dataset includes demographic information, medical history, lifestyle factors, and key health indicators. It reflects the probability of stroke occurrence under different health and lifestyle conditions, aiming to support machine learning models in predicting and analyzing stroke risk, helping to identify key influencing factors, and thereby improving early screening and prevention capabilities.
Online use:https://go.hyper.ai/6CTH5
2. ToolACE Complex Tool Learning Dialogue Dataset
ToolACE is an automated agent pipeline dataset for tool learning tasks. This dataset contains multi-step conversation examples, calling 26,507 diverse APIs. The samples are generated through multi-agent interactions and undergo a two-layer quality assurance process of rule checking and model validation. Each dialogue represents a multi-step, multi-source information retrieval and analysis task, realistically simulating tool call scenarios and providing high-value training data for LLM (Low-Level Learning).
Online use:https://go.hyper.ai/o3E12
3.CHOCLO Latin American Cultural Benchmark Dataset
The CHOCLO dataset is a benchmark dataset specifically designed to evaluate the knowledge of Latin American culture in language models. It aims to assess the accuracy of language models in representing Latin American culture, and is designed to address real-world issues such as the underestimation, omissions, and biases of Latin American culture in language models.
Online use:https://go.hyper.ai/pjVQi
4. DRACO Cross-Disciplinary In-Depth Research Benchmark Dataset
The DRACO dataset, released by the Perplexity team, is a dataset designed for evaluating complex research tasks and aims to systematically assess the comprehensive capabilities of deep research systems in terms of accuracy, completeness, and objectivity.
Online use:https://go.hyper.ai/hIWgS
5. MDPBench Multilingual Document Parsing Benchmark Dataset
MDPBench is a benchmark dataset for parsing multilingual digital and photographic documents, designed to evaluate and improve models’ ability to parse multilingual documents in real-world, complex scenarios.
Online use:https://go.hyper.ai/1Mc9a
6. World Model Bench dataset
World Model Bench is the world's first benchmark for evaluating the cognitive capabilities of world models and embodied AI systems. It aims to go beyond traditional image and video quality assessments, focusing instead on the cognitive abilities of models. This dataset is built around evaluating world model capabilities, covering three core dimensions: perception, cognition, and embodiment. It is further subdivided into 10 task categories, including environmental understanding, entity recognition and classification, and prediction-based reasoning, and includes 100 diverse scenarios designed to systematically evaluate the cognitive and decision-making abilities of models in complex environments.
Online use:https://go.hyper.ai/hY0aP
7. Credit Card Fraud Detection Dataset
Credit Card Fraud is a dataset for detecting credit card fraud in financial transaction scenarios. It aims to support machine learning models in identifying and modeling abnormal transactions, focusing on solving the problem of extreme class imbalance in financial scenarios, thereby improving the detection capabilities of models in real business environments.
Online use:https://go.hyper.ai/3d8nS
8. Spam Email Detection Dataset
The Spam Email Detection dataset is a labeled email dataset for spam detection tasks. This dataset aims to support research related to classification modeling, natural language processing, and feature engineering, and improve the model's ability to identify spam.
Online use:https://go.hyper.ai/HkpX5
9. Simple Voice Questions dataset
Simple Voice Questions is a short audio dataset released by Google. This multilingual voice dataset contains short audio questions in 17 languages from 26 regions, with a total of approximately 700 speakers. Each speaker provides up to 250 voice samples, covering multiple languages such as Arabic, English, Japanese, Korean, and Hindi, and including diverse recording conditions such as quiet environments, background voices, and traffic noise.
Online use:https://go.hyper.ai/lrKpK
10. COCO-2017-Vietnamese Vietnamese Image Detection Dataset
COCO-2017-Vietnamese is a Vietnamese localization extension dataset built upon the Common Objects in Context 2017 dataset proposed by Microsoft, and compiled and released by the AI Enthusiasm community. This dataset introduces high-quality Vietnamese translations on top of the original English image descriptions, providing a comprehensive benchmark within a bilingual framework, suitable for tasks such as image captioning and multimodal learning.
Online use:https://go.hyper.ai/VM6gY
11. GPT-5.4-step-by-step-reasoning dataset
The GPT-5.4 step-by-step-reasoning dataset is a high-density synthetic reasoning dataset designed for long-chain reasoning (CoT) modeling and complex problem-solving tasks. This dataset contains approximately 1,500 elite-level samples covering high-complexity domains such as mathematics, programming, and medicine, with task difficulty uniformly set at the "Grandmaster" and "Beyond-PhD" levels.
Online use:https://go.hyper.ai/HjJlT
Selected Public Tutorials
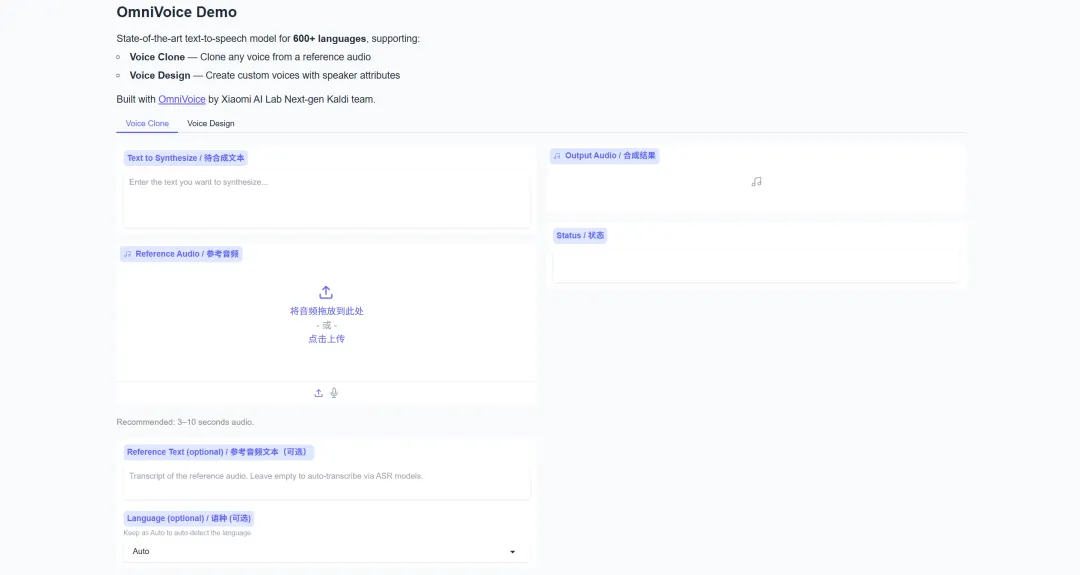
1. OmniVoice: Supports high-quality TTS in 600+ languages.
OmniVoice is a multilingual text-to-speech (TTS) model developed by Xiaomi AI Lab's Next-gen Kaldi team, supporting high-quality speech synthesis in over 600 languages. Based on an iterative unmasked decoding architecture, the project implements three core functions: voice cloning, voice design, and automatic voice.
Run online:https://go.hyper.ai/BvKri
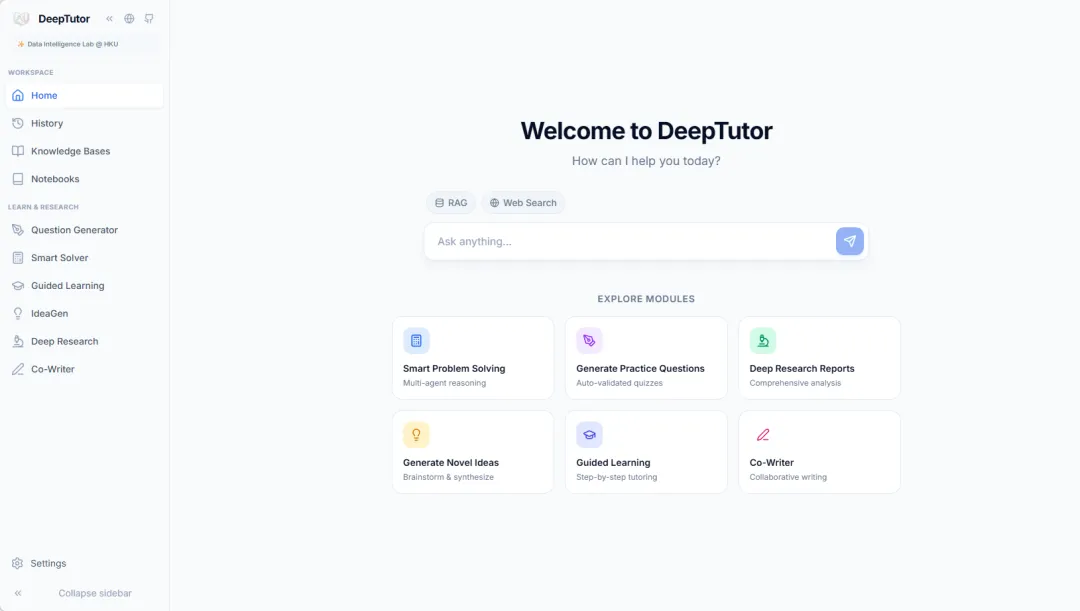
2. DeepTutor Personal Learning Assistant
DeepTutor, launched in March 2026 by the Data Intelligence Lab at the University of Hong Kong, is a comprehensive AI-driven teaching system and a personal learning assistant. The project integrates four core functional modules: massive document-based knowledge Q&A, interactive learning visualization, knowledge reinforcement and practice question generation, and in-depth research and creative generation, providing learners with a one-stop intelligent learning experience.
Run online:https://go.hyper.ai/8YnI3
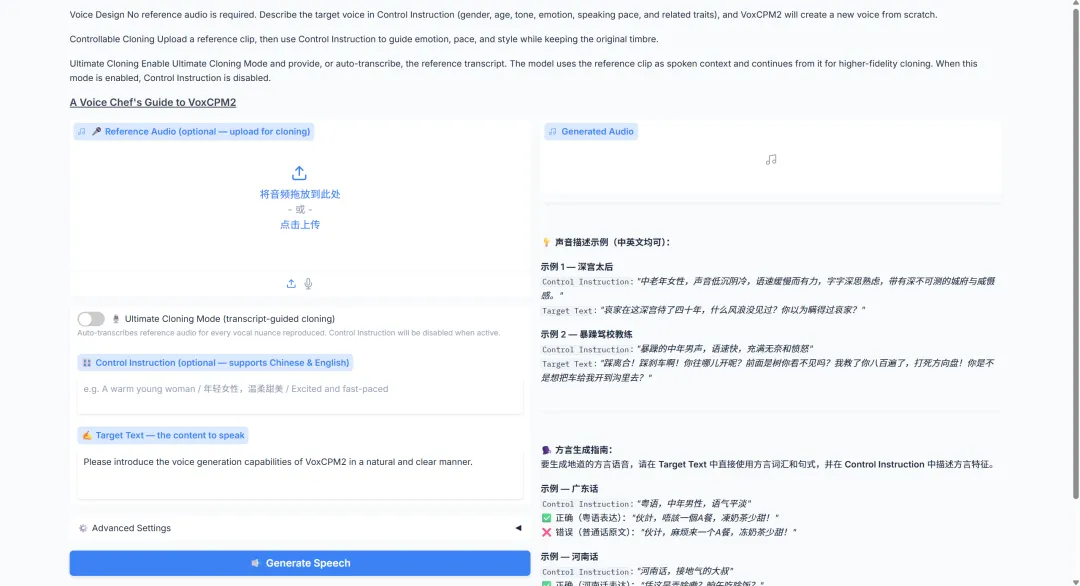
3. VoxCPM2 Voice Reproduction: 30+ Languages, 9 Dialects
VoxCPM2 is a 2B parameter-scale tokenizer-free text-to-speech model released by OpenBMB in April 2026. It supports 30 languages, requires no additional language tags, and covers various use cases, including generating new timbres from scratch, controlled cloning based on reference audio, extreme cloning by combining reference audio with transcribed text, and automatically adjusting tone and expressiveness based on text content. The official specifications also emphasize 48 kHz output, compatibility with 16 kHz reference audio, and context-aware expression.
Run online:https://go.hyper.ai/RLgK9
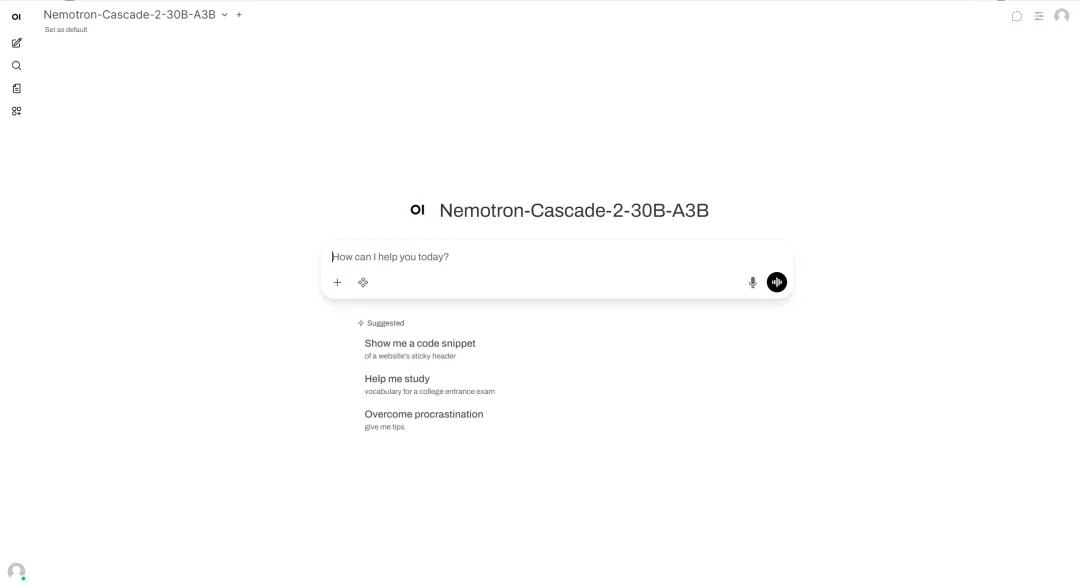
4. One-click deployment of Nemotron-Cascade-2-30B-A3B
Released by NVIDIA in March 2026, Nemotron-Cascade-2-30B-A3B is an open-source large language model with 30B MoE and approximately 3B activated parameters, trained on Nemotron-3-Nano-30B-A3B-Base. The model's core focus is providing strong inference, dialogue, code-related, and agency capabilities, while simultaneously supporting both thinking mode and instruction mode.
Run online:https://go.hyper.ai/GoEaW
5. Netflix VOID: A revolutionary video object removal technology with physical awareness.
Netflix VOID is a video editing model jointly open-sourced by the Netflix team and Sofia University in April 2026. With 5 billion parameters, the Netflix VOID model is designed to solve the physical consistency problem in film post-production, aiming to overcome the limitations of traditional video completion techniques in handling the causal logic of complex object interactions.
Run online:https://go.hyper.ai/uZoMl
6. Fun-CineForge: A unified model for zero-sample dubbing in diverse film and television scenarios
Fun-CineForge is a zero-shot film dubbing project jointly launched by the Tongyi Labs Speech Team and the University of Science and Technology of China in January 2026. The project includes an end-to-end dataset pipeline for producing large-scale dubbing datasets and a dubbing model based on a Large Multimodal Model (LMM), designed for diverse film scenarios.
Run online:https://go.hyper.ai/DyQKk
Community article interpretation
1. AI-driven de novo design of diverse small-molecule binding proteins: A South Korean team discovered a protein that can selectively recognize stress hormones.
A research team from the Department of Biological Sciences at the Korea Advanced Institute of Science and Technology (KAIST) has used deep learning-driven protein structure generation and sequence design methods to de novo design diverse small-molecule binding proteins using the NTF2-like fold as a core "universal backbone," and further transformed them into sensors similar to chemically induced dimerization (CID). The researchers successfully designed a protein capable of selectively recognizing the stress hormone cortisol and developed an artificial intelligence biosensor based on this.
View the full report:https://go.hyper.ai/FpAXm
2. A French team successfully predicted 2.39 million antiphage proteins and used a deep learning model to map bacterial antiviral immunity.
Researchers at the Pasteur Institute in France have developed and fine-tuned three complementary deep learning models for large-scale prediction of phage resistance. The ALBERT_DF model relies solely on local genomic context for inference; ESM_DF uses a protein language model to parse amino acid sequences; and GeneCLR_DF integrates sequence information with genomic context.
View the full report:https://go.hyper.ai/J5Oz3
Popular Encyclopedia Articles
1. Skills
2. Ground Truth
3. Human-in-the-loop
4. Large-Scale Multitasking Language Understanding (MMLU)
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








