Command Palette
Search for a command to run...
Anima V1, a brand-new Raw Image Model, Has Been Released, Focusing on anime-style Image Generation; the MemLens Multimodal long-range Memory Evaluation Dataset Covers cross-conversation text-to-image Reasoning and Knowledge Update mechanisms.

Anima V1 is an anime-style image generation model released by CircleStone Labs in 2026, designed specifically for character illustrations, illustrations, and other two-dimensional visual creations.You can quickly output beautiful images by describing the details of the person and the lighting using a text prompt.With the project's integrated Grado interface, developers can say goodbye to cumbersome pure script calls and directly adjust key parameters such as size, sampling steps, and CFG in the browser, making it more perfectly suited for practical workflows such as role setting and proof of concept.
The HyperAI website now features "Anima V1: Anime-style Image Generation," so give it a try!
Online use:https://go.hyper.ai/4PF0Y
Welcome to visit our official website for more information:
A quick overview of hyper.ai's official website updates from May 16th to May 22nd:
* High-quality public datasets: 5
* A selection of high-quality tutorials: 4
* Community article interpretation: 4 articles
* Popular encyclopedia entries: 5
Visit the official website:hyper.ai
Selected public datasets
1. VisCoR-55K Visual Inference Dataset
VisCoR-55K is a high-quality visual reasoning dataset released in 2026 by Huazhong University of Science and Technology in collaboration with Alibaba Cloud. The dataset contains approximately 55,000 visual reasoning samples, each of which generates a corresponding reasoning process using comparative samples. It covers five major categories of high-quality visual reasoning datasets: general, reasoning, mathematical, graph, and OCR, and aims to promote research on reliable and robust visual reasoning using visual language models.
Online use:https://go.hyper.ai/iQlsz
2. AgentTrove intelligent agent interaction trajectory dataset
AgentTrove is a large-scale open-source dataset of agent interaction trajectories released by the OpenThoughts-Agent team. This dataset contains 1,696,847 rows of data from 219 datasets, covering tasks such as code repair, shell scripting, mathematical problem solving, programming competitions, and general computing.
Online use:https://go.hyper.ai/iEMLh
3. Caravan Global Community Large Sample Hydrological Dataset
Caravan is an open, large-scale global community hydrological dataset that standardizes and integrates seven existing large-scale hydrological datasets, containing meteorological forcing data, watershed attributes, and flow data for global watersheds. The dataset contains meteorological driving data, runoff data, and static watershed attributes (e.g., geophysical, social, and climatic attributes) for 6,830 watersheds.
Online use:https://go.hyper.ai/OUa2g
4. MemLens Multimodal Long Context Benchmark Dataset
MemLens is a benchmark dataset for evaluating long-range dialogue memory in visual language models. It tests the model's ability to retrieve, recall, update, and infer visual and textual information embedded in multi-conversation dialogues within context windows of 32K, 64K, 128K, and 256K. The dataset contains 789 questions covering five evaluation types: information retrieval, knowledge updating, temporal reasoning, multi-conversation reasoning, and rejection (Abstention), and provides four context length configurations (32K/64K/128K/256K).
Online use:https://go.hyper.ai/ZR0s9
5. LongBlocks Long Context Multilingual Question Answering Dataset
LongBlocks is a multilingual synthetic dataset with long context, released in 2026 by the University of Lisbon, the Institute of Telecomunicações, TransPerfect, and other institutions. This dataset contains approximately 194,000 long-context question-and-answer examples, covering long document corpora such as books, web page text, Wikipedia entries, arXiv papers, programming code, and community Q&A.
Online use:https://go.hyper.ai/dc0W6
Selected Public Tutorials
1. Anima V1: Anime-style Image Generation
Anima V1 is an anime-style image generation model released by CircleStone Labs in 2026, designed for scenarios such as character illustrations, artwork, concept art, and 2D visual creation. Users can describe characters, clothing, poses, lighting, and atmosphere using text prompts, generating images with anime aesthetics.
Run online:https://go.hyper.ai/4PF0Y

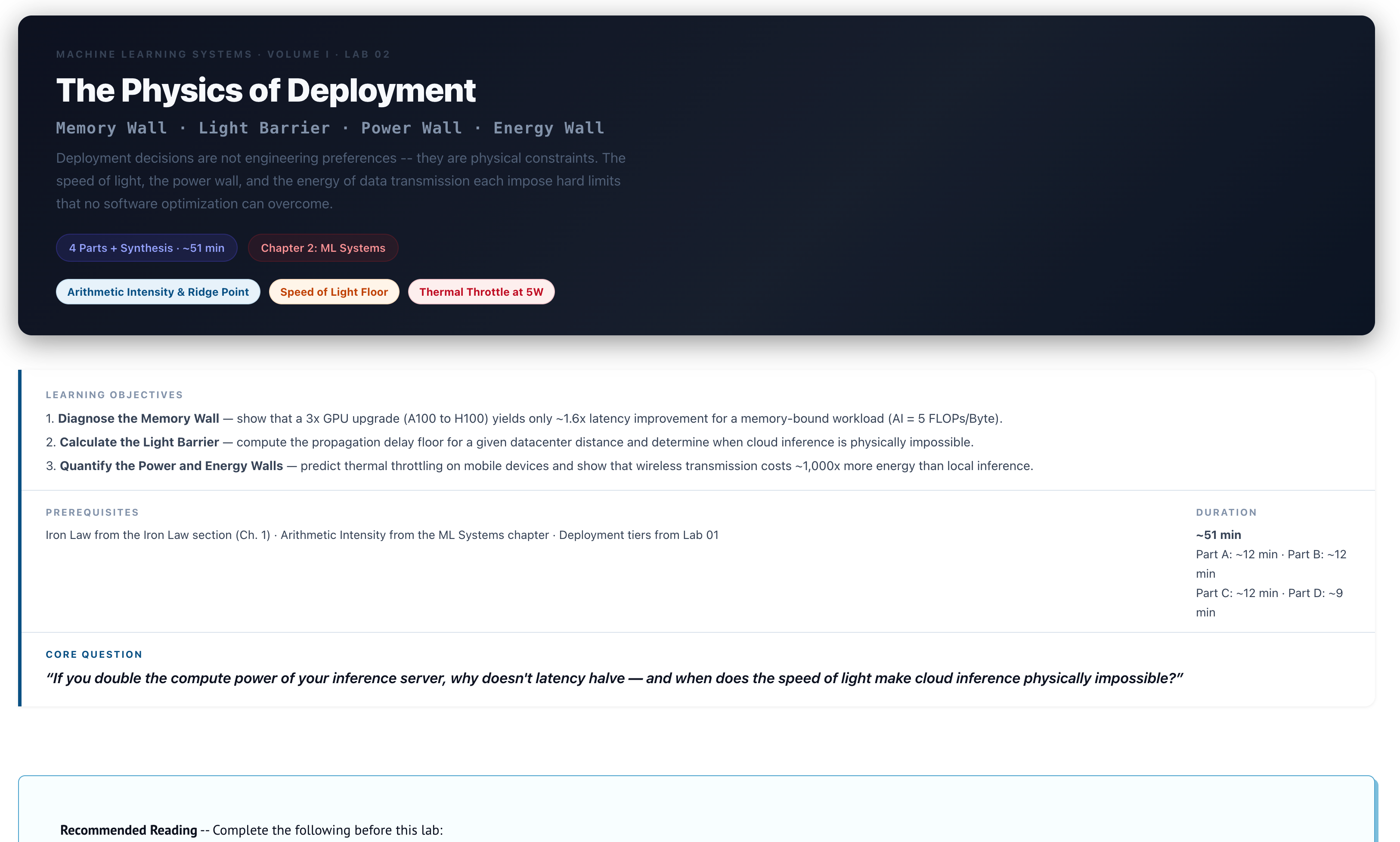
2. MLSysBook: Co-Labs Interactive Experiments
MLSysBook Interactive Labs is an interactive teaching platform for machine learning systems developed by Harvard University. It contains 33 labs that can be run directly in a browser without requiring any software installation or environment configuration. Each lab takes approximately 50 minutes and follows a "predict-discover-explain" learning cycle, guiding learners to solve real-world machine learning system problems.
Run online:https://go.hyper.ai/0XrSs
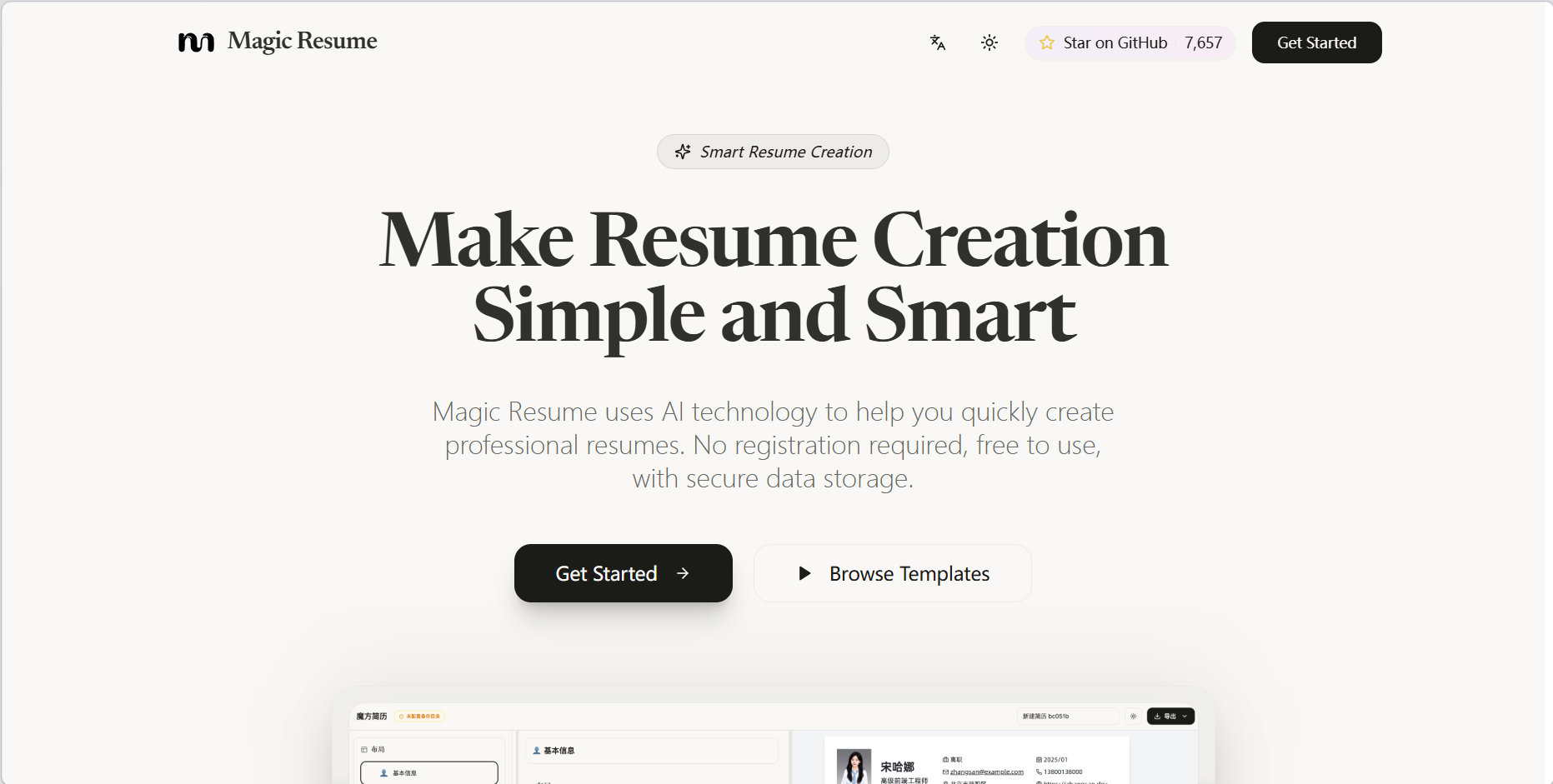
3. Magic-Resume: AI-powered resume editor
Magic Resume is a free online AI resume editor open-sourced by Siyue in 2025. This project is not a traditional collection of static resume templates, but rather a modern online resume workbench designed for job seekers. It supports real-time preview, automatic saving, local storage, custom themes, dark mode, responsive layout, and PDF export. Users can fill in personal information, education, project experience, work experience, and other modules in the editing area and instantly view the final resume.
Run online:https://go.hyper.ai/oLXO5
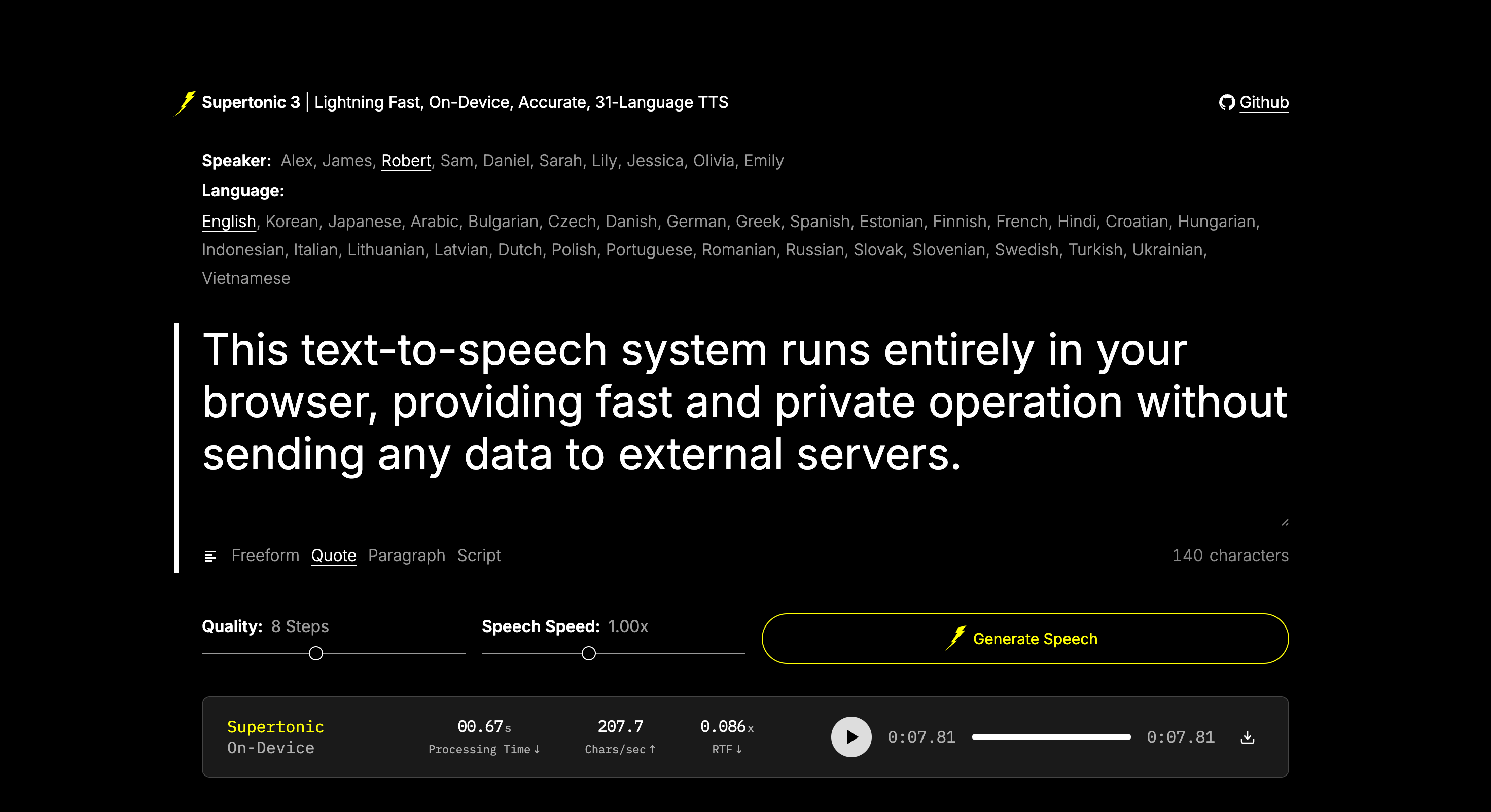
4. Supertonic-3: A lightweight local multilingual speech synthesis system
Released by the Supertone team in May 2026, Supertonic-3 is a lightweight multilingual text-to-speech model for local, offline, and edge computing scenarios. The official implementation provides a high-level inference approach based on the Supertonic Python SDK, while the underlying speech synthesis is performed through the ONNX Runtime, making it suitable for rapid verification and application prototyping in a CPU environment.
Run online:https://go.hyper.ai/uRYzv
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community article interpretation
1. With an accuracy of 94%, a Spanish team has achieved automated near-Earth object and satellite stripe detection based on YOLO11, with stable identification across consecutive frames.
The StreakMind system, developed by the Astronomical Observatory of the Royal Naval Academy of Spain, can automatically identify linear trails left by satellites or asteroids in astronomical images, extracting the length, position, and direction of these trails to provide standardized output for subsequent astronomical measurements and database entry. On an independent test set, the model demonstrated reliable performance for short, medium, and long trails, achieving an overall precision of 941 TP3T and a recall of 971 TP3T, successfully detecting 107 trails out of 110 real-world trails.
View the full report:https://go.hyper.ai/lo6jI
2. With a speedup of 252 times, Stanford, UCLA, and other institutions have used LSTM to bring second-order nonlinear optical simulations into the millisecond era.
Inspired by previous research on the application of recurrent neural networks (RNNs) to fiber pulse propagation, a team from Stanford University, UCLA, and SLAC National Accelerator Laboratory proposed a surrogate model based on long short-term memory networks that can quickly and accurately predict the output optical field of SFG while significantly reducing computational costs.
View the full report:https://go.hyper.ai/7VsCZ
3. A new breakthrough in small-sample biomedical research: a German team has achieved data augmentation based on a generative AI model, potentially reducing the number of laboratory animals required by 30-50 per TP3T.
A joint research team from the University of Frankfurt and the Fraunhofer Institute for ITMP has developed genESOM—a generative AI model based on emergent self-organizing maps, specifically designed for small-sample biomedical data. The core innovation of this model is the decoupling of structure learning from the data generation process, blocking error propagation through dimensionality adjustment, and introducing a negative control variable to monitor the quality of generated data in real time.
View the full report:https://go.hyper.ai/4kngS
4. Google's global flood forecasting system has been upgraded to version 2, extending reliable forecast duration by 6 days and significantly improving accuracy.
Google Research's second-generation global flood forecasting system (v2) is now operational and serves as the core engine of the Google FloodHub river forecasting module. Compared to the first version, v2 addresses three key long-standing challenges hindering its commercialization: insufficient training data, limited time series length, and input data distribution bias. These improvements significantly enhance the stability and reliability of global-scale runoff forecasts.
View the full report:https://go.hyper.ai/xI1Xe
Popular Encyclopedia Articles
1. Agent Memory
2. Human-in-the-loop
3. Federated Learning
4. Learning While Deploying
5. Multi-Agent Architecture
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








