Command Palette
Search for a command to run...
Online Tutorial | 32K Context Parsing of Dozens of Pages of Documents at Once: Baidu Open Sources Unlimited OCR, Refactoring Complex Scenarios With Long Documents

Over the past few years, OCR has gradually evolved from "recognizing text in images" to a complete document understanding task. Enterprises and developers not only need to extract text, but also want models capable of recognizing complex page layouts, parsing tables and formulas, understanding multi-column layouts, and ultimately outputting structured results suitable for downstream RAGs, knowledge bases, or office automation. However, when processing long documents such as scanned reports, papers, PPTs, contracts, and multi-page PDFs…Traditional OCR workflows often require page-by-page reasoning followed by post-processing and splicing, which is not only inefficient but also prone to causing fragmentation of contextual information.
Next-generation end-to-end OCR models, exemplified by DeepSeek OCR, significantly improve recognition accuracy and complex layout parsing capabilities by incorporating a large language model as a decoder and fully utilizing language priors. However, a new challenge arises: as output content grows, the model's key-value cache accumulates, leading to increasingly higher memory usage and slower generation speed. In other words,The closer the model is to the end of the document, the higher the inference cost.
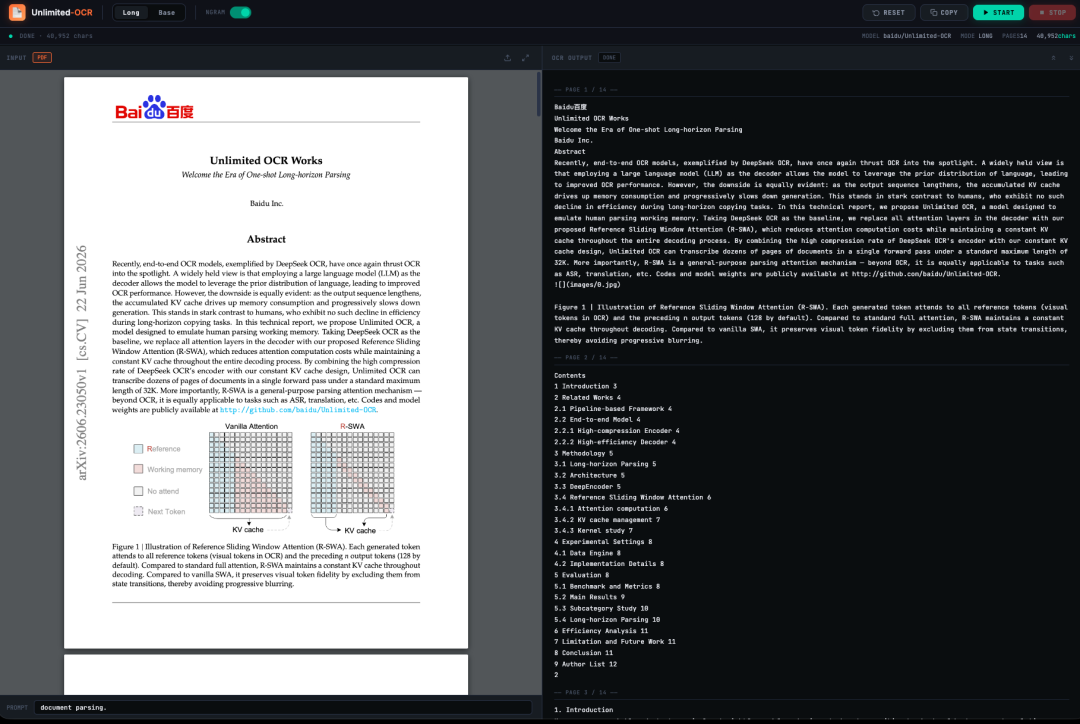
Baidu's recently open-sourced Unlimited OCR addresses this industry pain point. Based on DeepSeek OCR, the model introduces a novel Reference Sliding Window Attention (R-SWA) mechanism, replacing the traditional attention mechanism in the decoder. This reduces the computational cost of attention while maintaining a constant KV cache size throughout the decoding process. Combined with the high information compression capabilities of the DeepSeek OCR encoder,Unlimited OCR can complete OCR and layout parsing of dozens of pages of documents in a single forward inference, within the default 32K context length.This provides a new and more engineering-valuable approach to long document processing. More importantly, R-SWA is not only applicable to OCR, but also has the potential to be extended to long sequence parsing tasks such as Automatic Speech Recognition (ASR) and machine translation.
Currently, HyperAI (hyper.ai) has launched the "Unlimited-OCR: One-click Deployment of Long Document OCR and Layout Parsing" tutorial, lowering the deployment threshold and helping to quickly validate models. ⬇️
Run online:https://go.hyper.ai/YfaB5
View related papers:https://go.hyper.ai/PZsJo
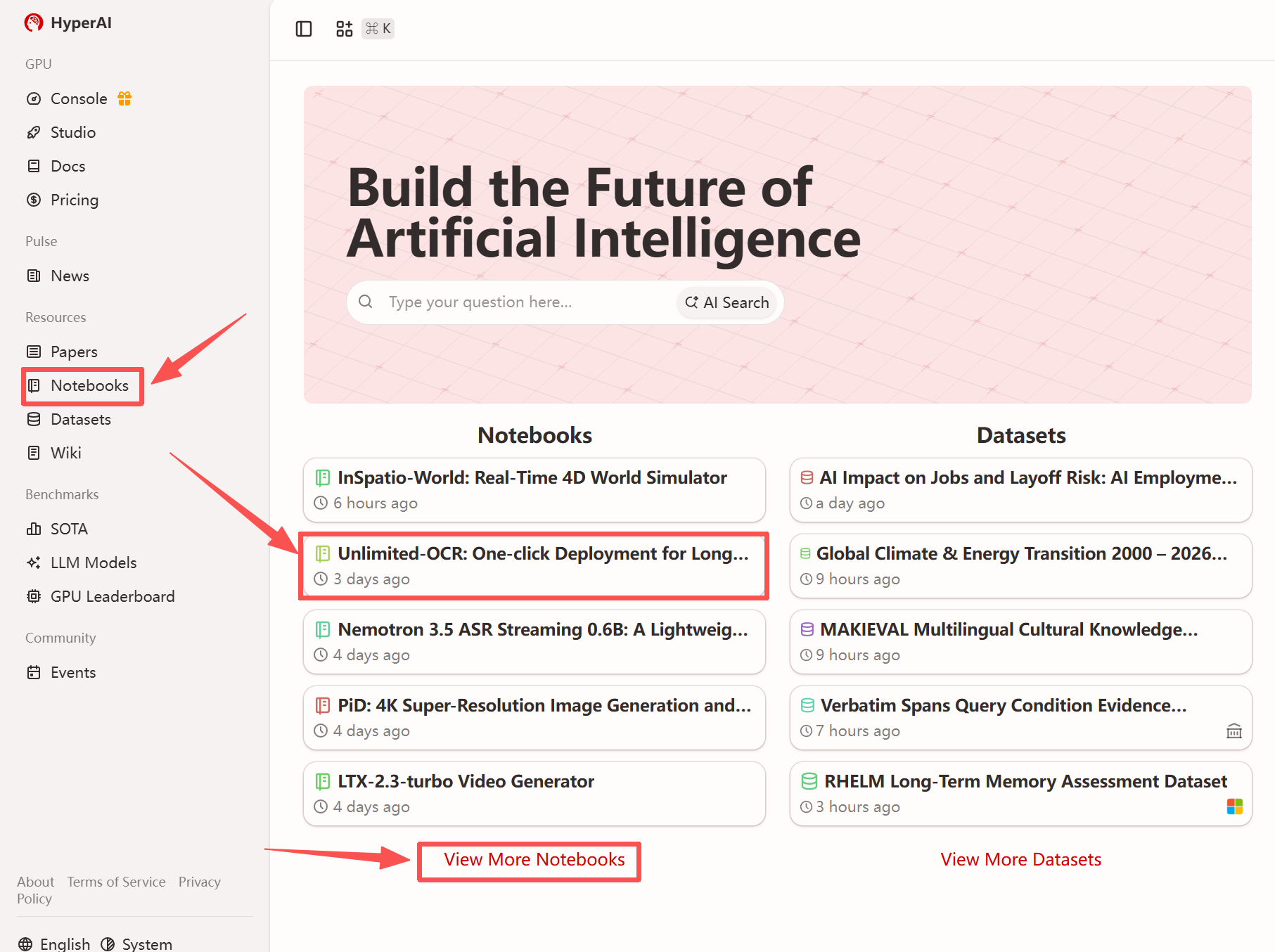
More online tutorials:
Demo Run
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "Unlimited-OCR: One-Click Deployment of Long Document OCR and Layout Parsing", and click "Run this tutorial".
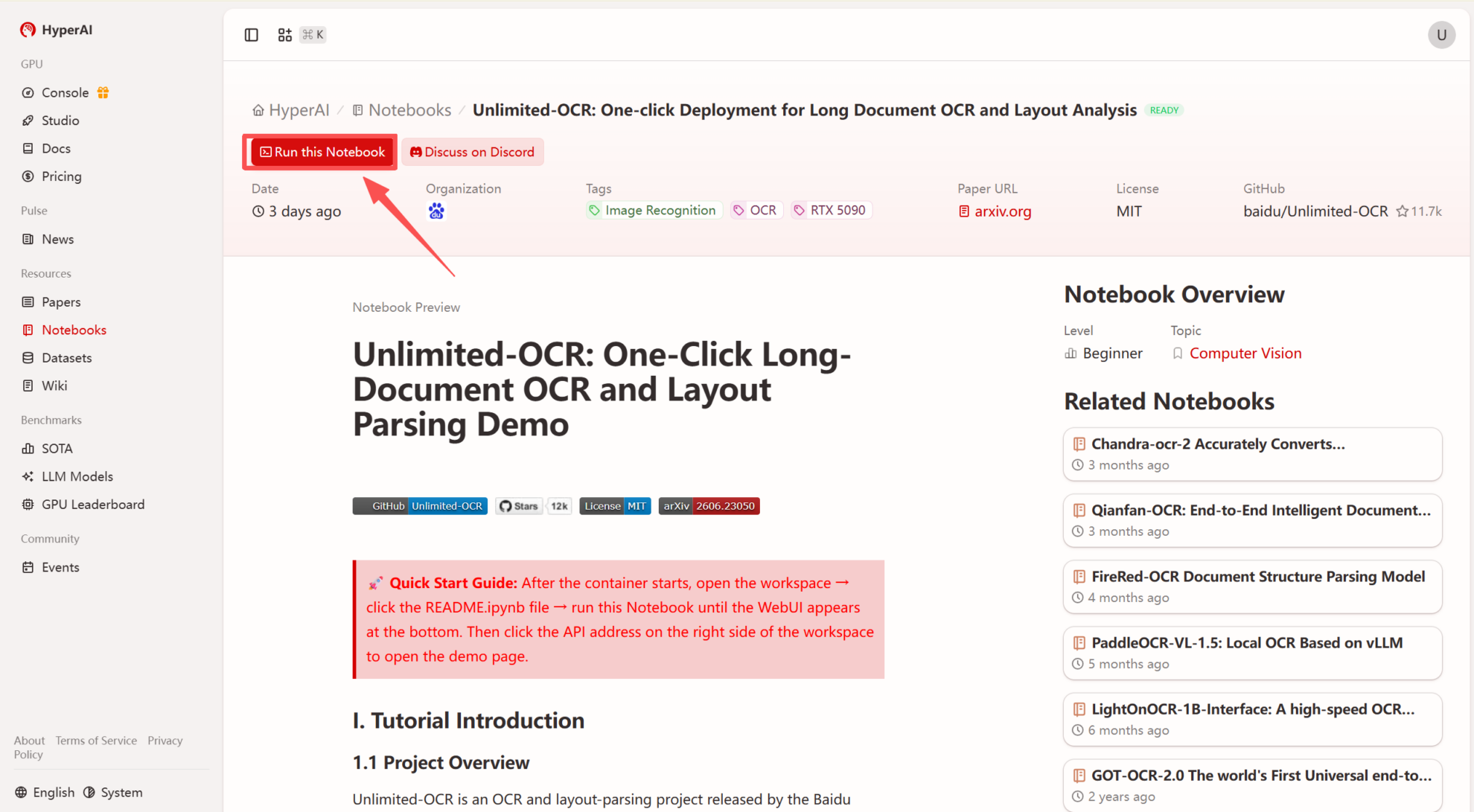
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
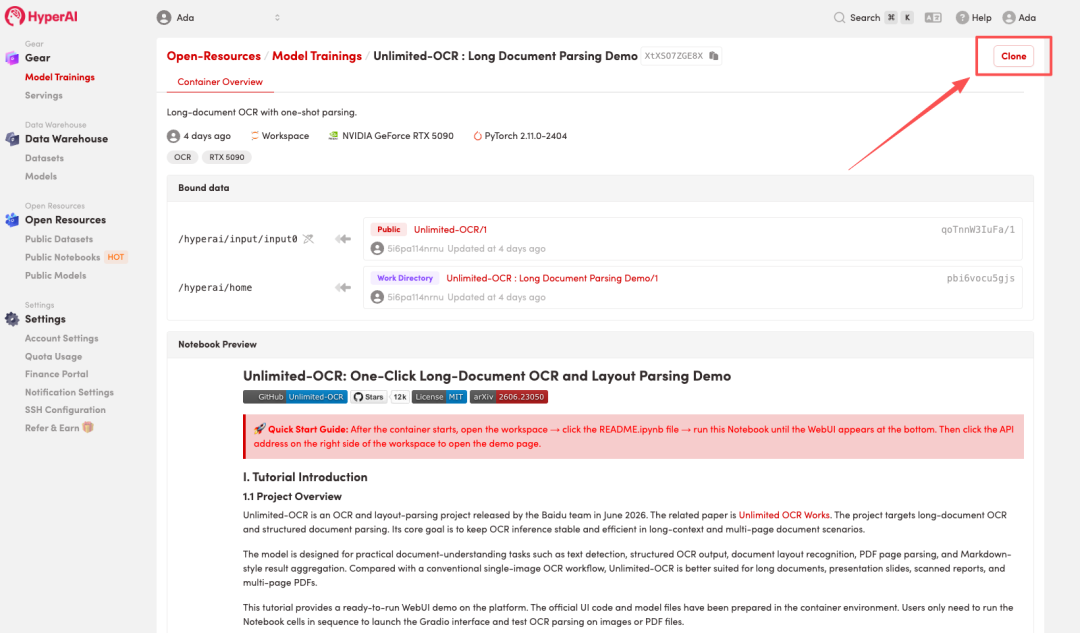
3. Select the "NVIDIA RTX 5090" and "PyTorch" images, and click "Continue job execution".
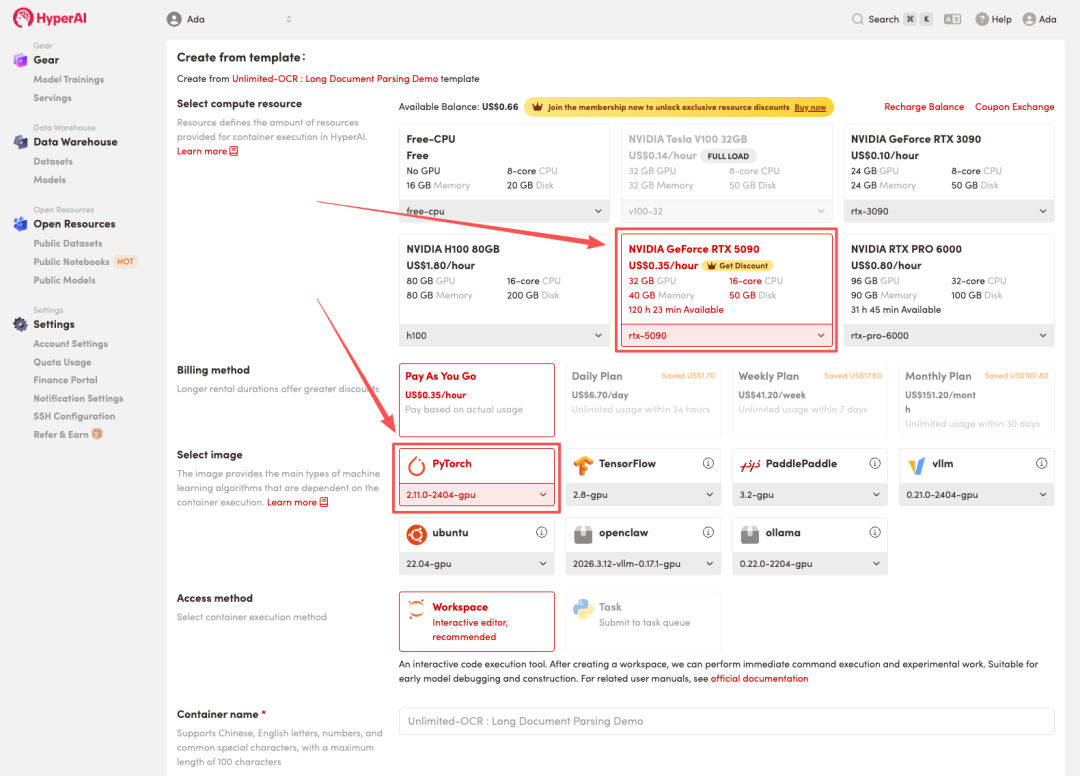
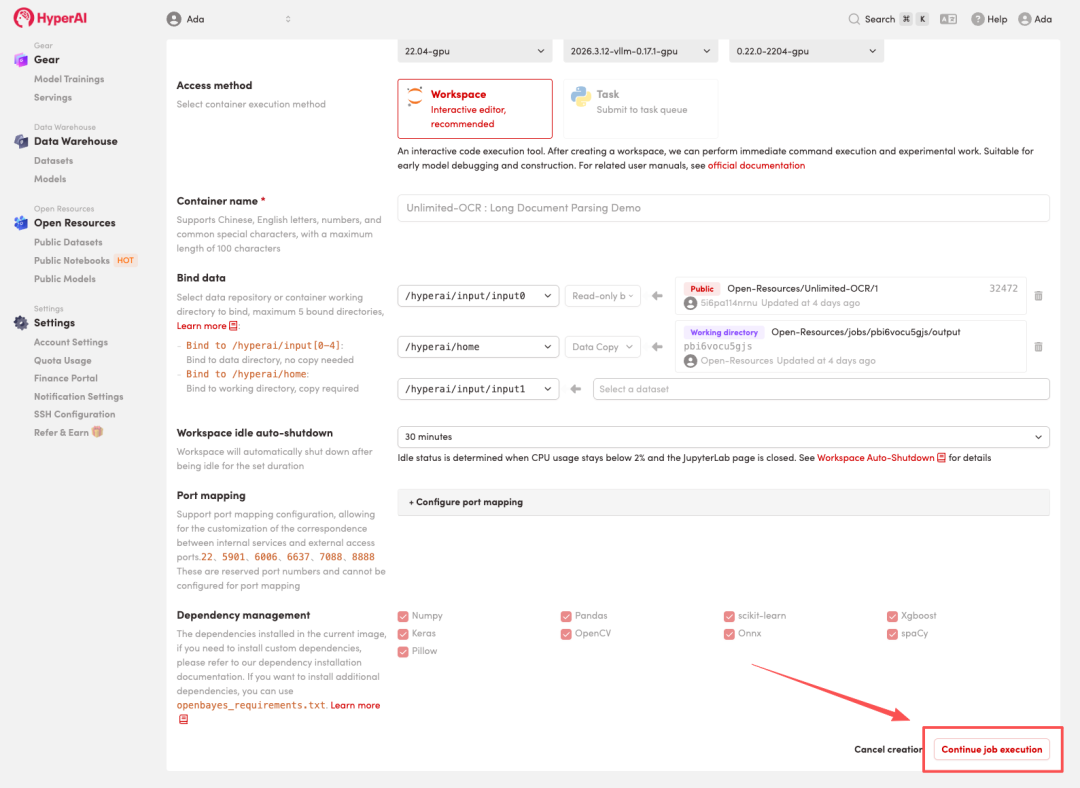
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
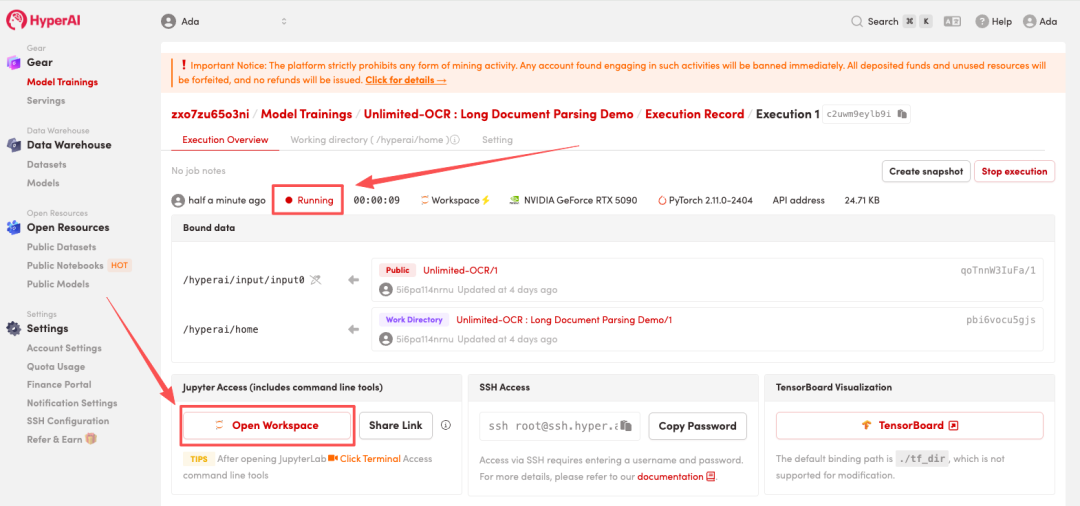
Effect display
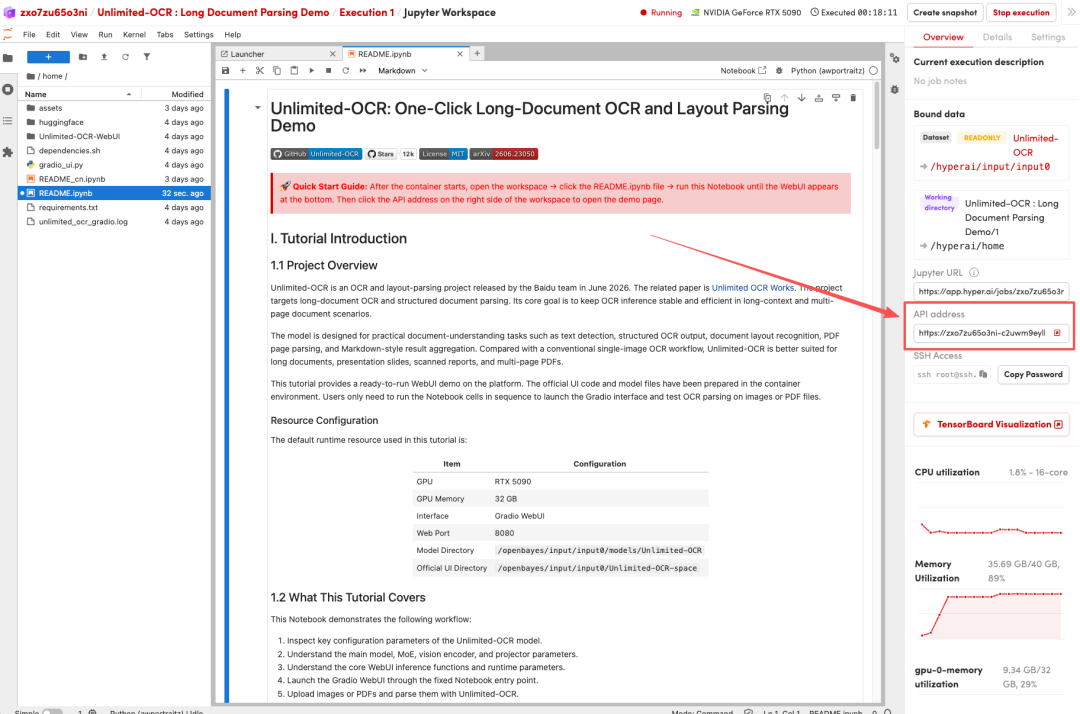
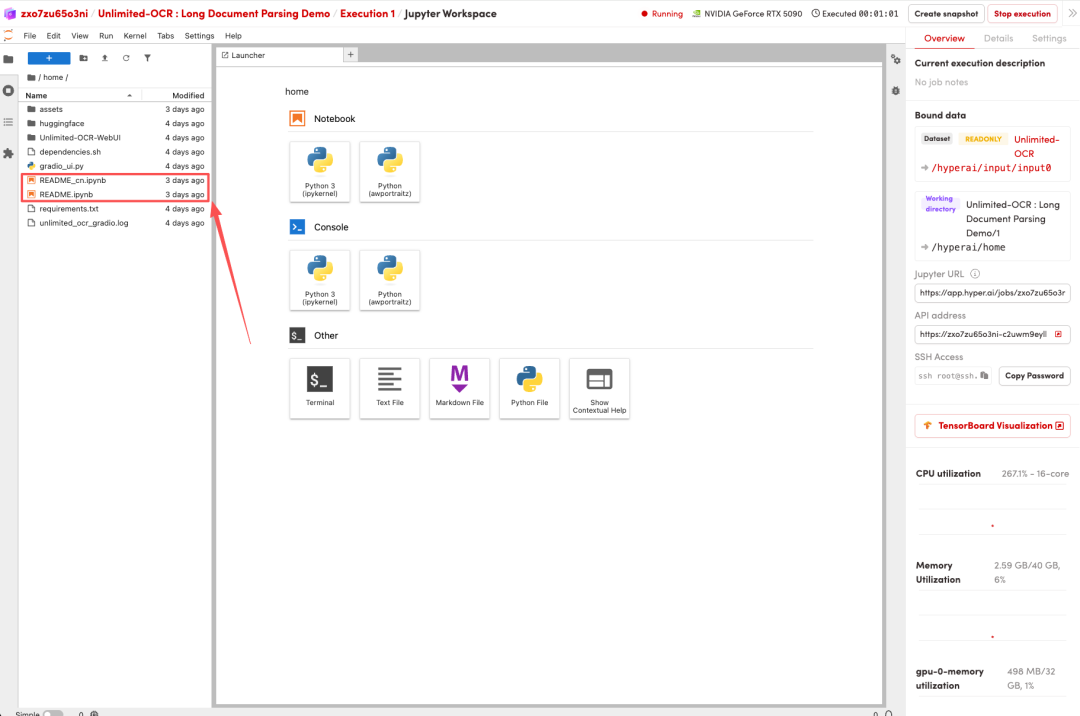
1. After the page redirects, click on the README file on the left, and then click on Run at the top.
2. After the process is complete, click the API address on the right to open the Demo interface.