HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company

World-R1: Reinforcing 3D Constraints for Text-to-Video Generation


























From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
Video Analysis and Generation via a Semantic Progress Function
SmartPhotoCrafter: Unified Reasoning, Generation and Optimization for Automatic Photographic Image Editing
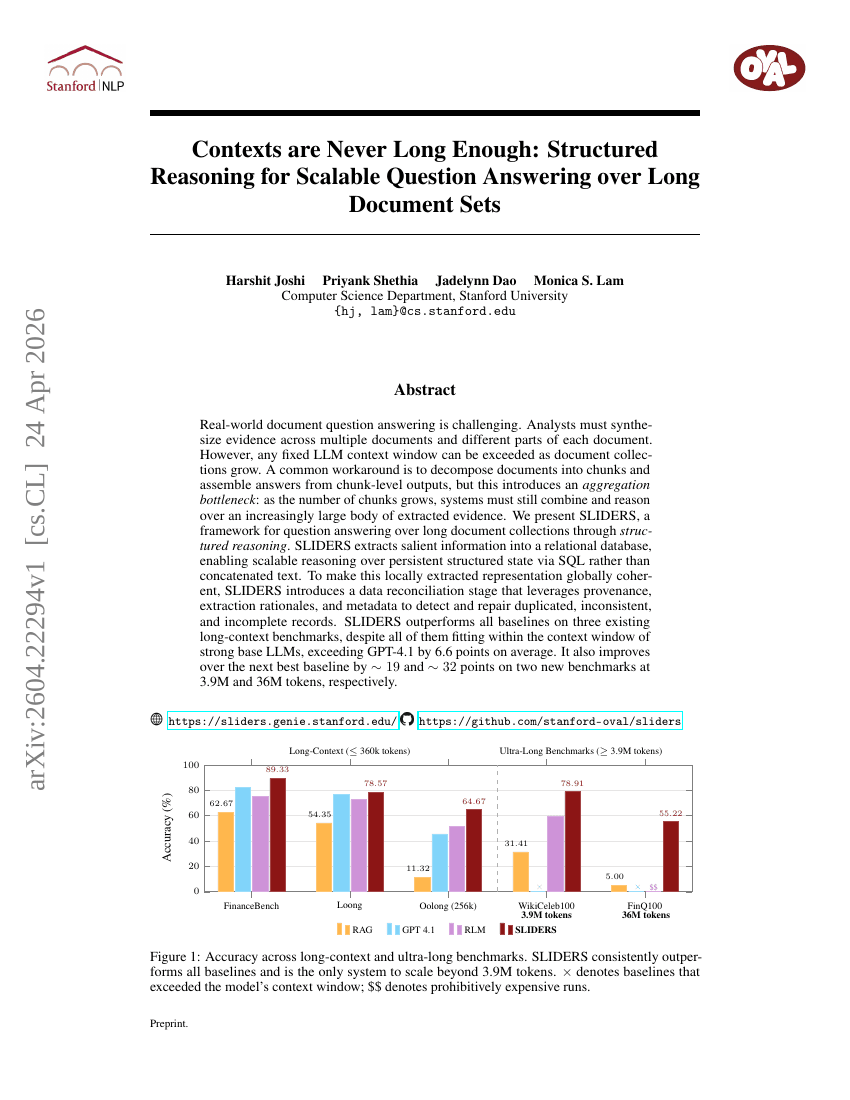
Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
AgentSearchBench: A Benchmark for AI Agent Search in the Wild
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing
LLM Safety From Within: Detecting Harmful Content with Internal Representations
DiffNR: Diffusion-Enhanced Neural Representation Optimization for Sparse-View 3D Tomographic Reconstruction
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Decoupled DiLoCo for Resilient Distributed Pre-training
EVENT TENSOR: A UNIFIED ABSTRACTION FOR COMPILING DYNAMIC MEGAKERNEL
Seeing Fast and Slow: Learning the Flow of Time in Videos
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
Image Generators are Generalist Vision Learners
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Exploring Spatial Intelligence from a Generative Perspective
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
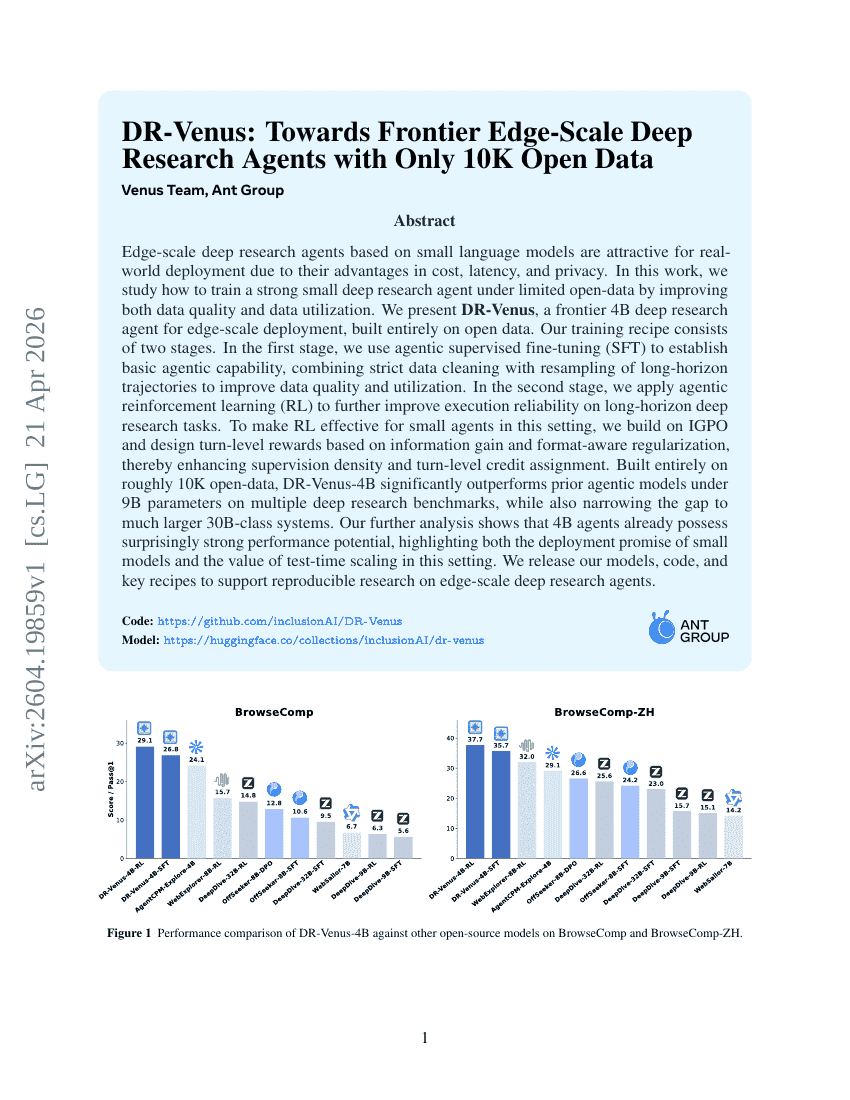
DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
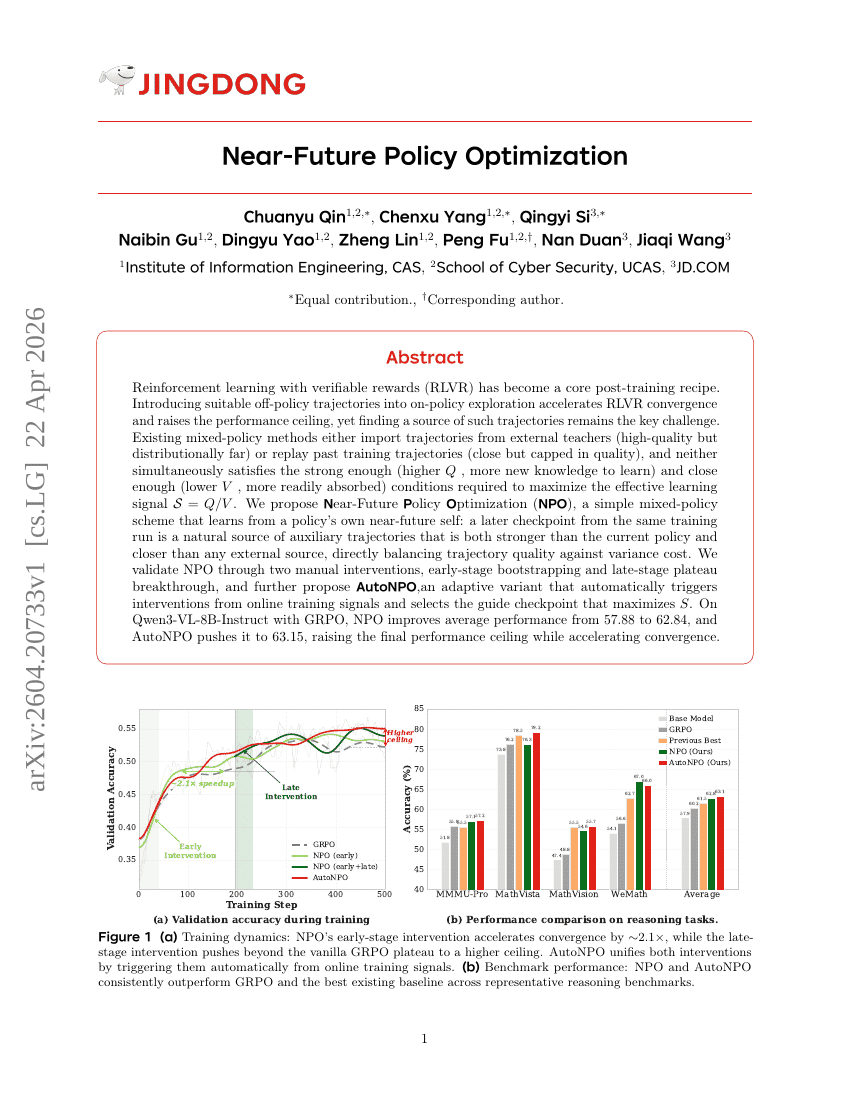
Near-Future Policy Optimization
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
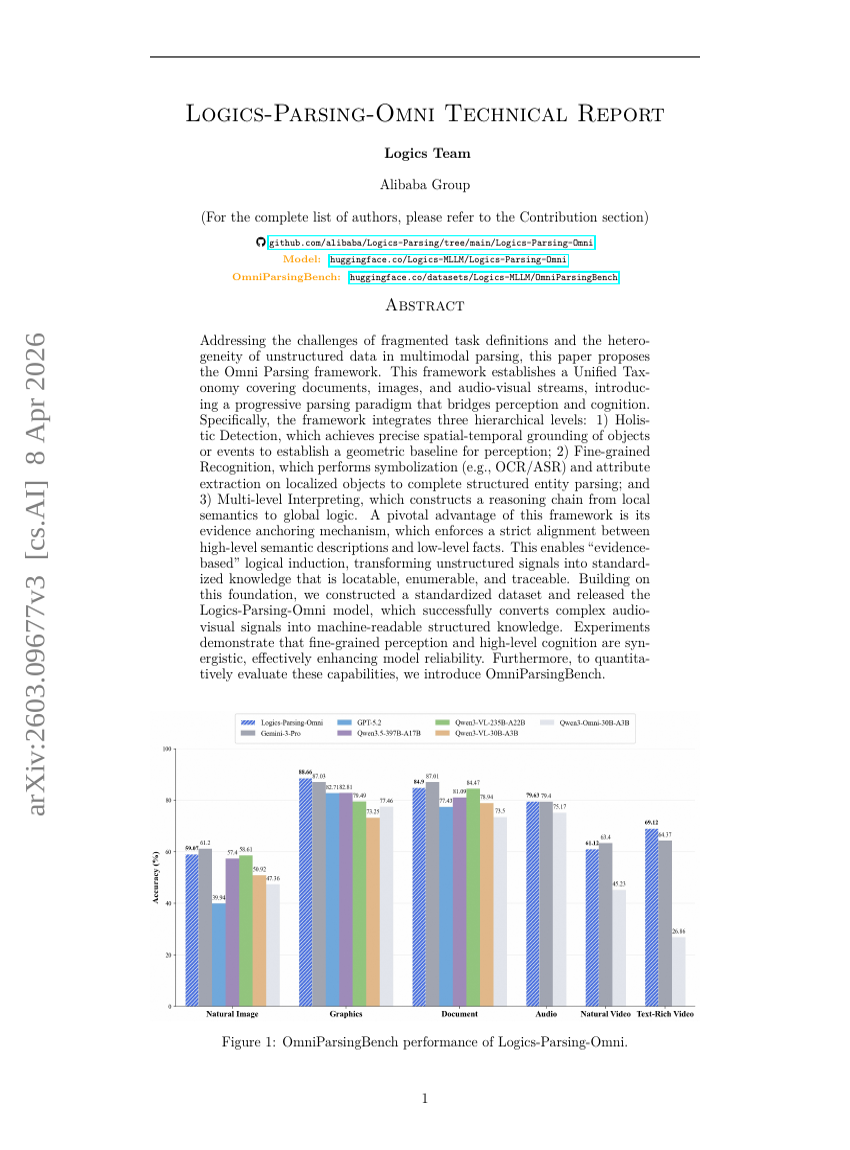
Logics-Parsing-Omni Technical Report
Video Analysis and Generation via a Semantic Progress Function
SmartPhotoCrafter: Unified Reasoning, Generation and Optimization for Automatic Photographic Image Editing
Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
AgentSearchBench: A Benchmark for AI Agent Search in the Wild
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing
LLM Safety From Within: Detecting Harmful Content with Internal Representations
DiffNR: Diffusion-Enhanced Neural Representation Optimization for Sparse-View 3D Tomographic Reconstruction
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Decoupled DiLoCo for Resilient Distributed Pre-training
EVENT TENSOR: A UNIFIED ABSTRACTION FOR COMPILING DYNAMIC MEGAKERNEL
Seeing Fast and Slow: Learning the Flow of Time in Videos
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
UniT: Toward a Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
Image Generators are Generalist Vision Learners
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Exploring Spatial Intelligence from a Generative Perspective
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
Near-Future Policy Optimization
LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Logics-Parsing-Omni Technical Report