HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
SWE-Factory:您的自动化问题解决训练数据和评估基准工厂
代码生成
基准
Lianghong Guo, Yanlin Wang, Caihua Li, et al.
ReasonMed:一个由多代理生成的370K数据集,用于推进医学推理
推理
数据集
Yu Sun, Xingyu Qian, Weiwen Xu, et al.
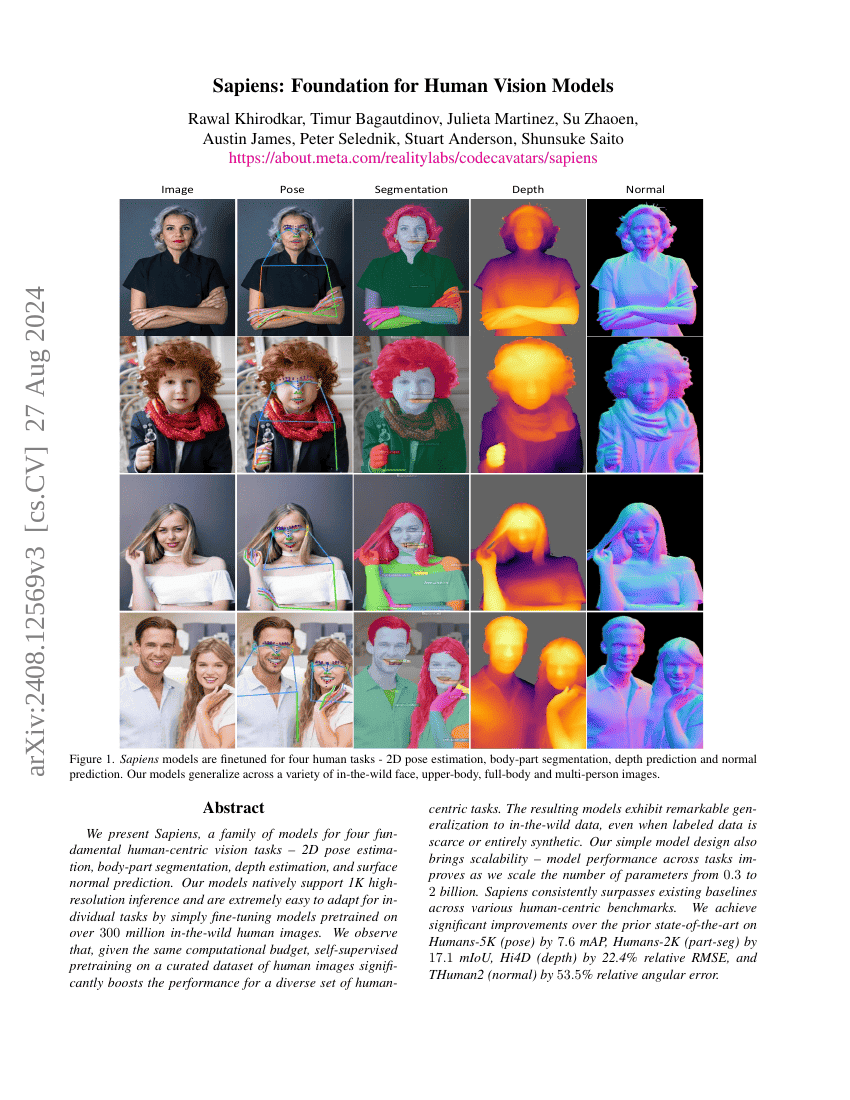
智人:人类视觉模型的基础
计算机视觉
多任务学习
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, et al.
LongVILA:面向长视频的长上下文视觉语言模型扩展
LLM
Transformer
Fuzhao Xue, Yukang Chen, Dacheng Li, et al.
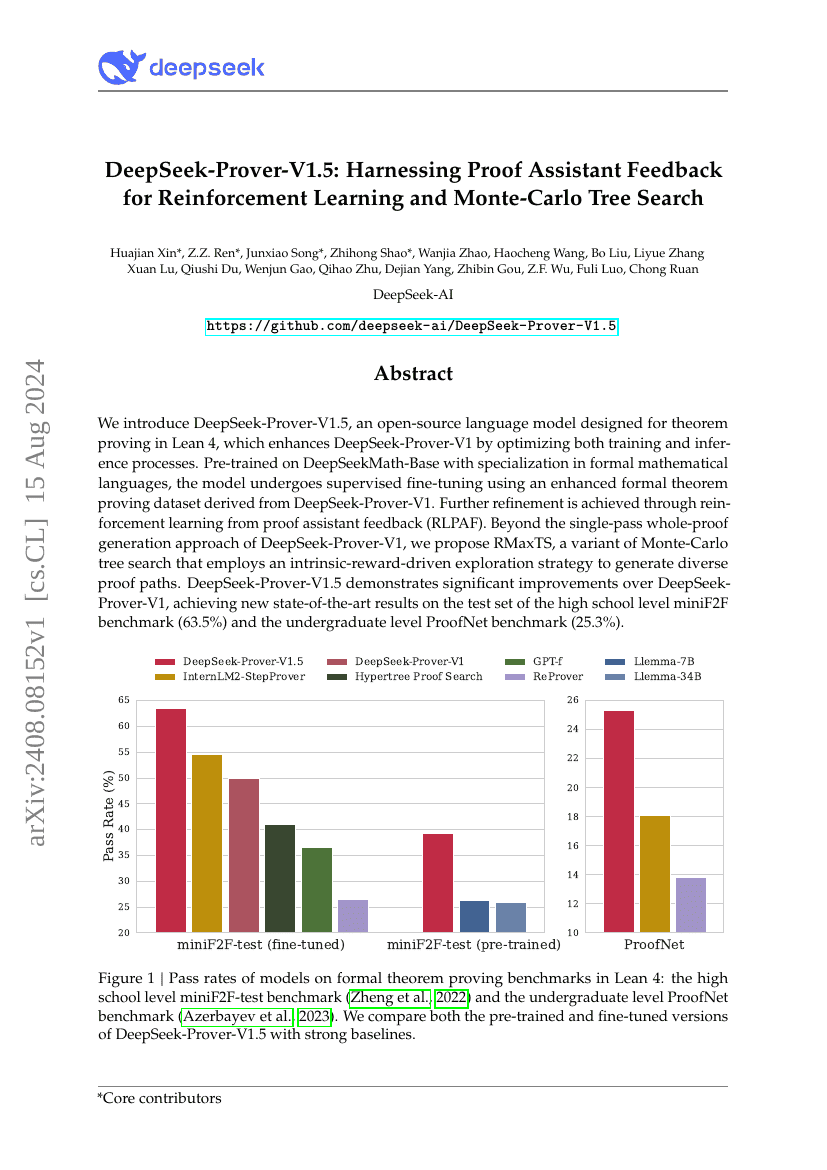
DeepSeek-Prover-V1.5:利用证明助手反馈进行强化学习与蒙特卡洛树搜索
LLM
强化学习
Huajian Xin, Z. Z. Ren, Junxiao Song, et al.
LLaVA-OneVision:简易视觉任务迁移
多模态
视频理解
Bo Li, Yuanhan Zhang, Dong Guo, et al.
SAM 2:图像与视频中的任意分割
计算机视觉
视频理解
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, et al.
Llama 3 模型群
LLM
Transformer
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al.
InternLM-XComposer-2.5:一个支持长上下文输入与输出的通用大视觉语言模型
统一多模态
多模态表征
Pan Zhang, Xiaoyi Dong, Yuhang Zang, et al.
MMDU:面向LVLMs的多轮多图像对话理解基准与指令微调数据集
多模态
数据集
Ziyu Liu, Tao Chu, Yuhang Zang, et al.
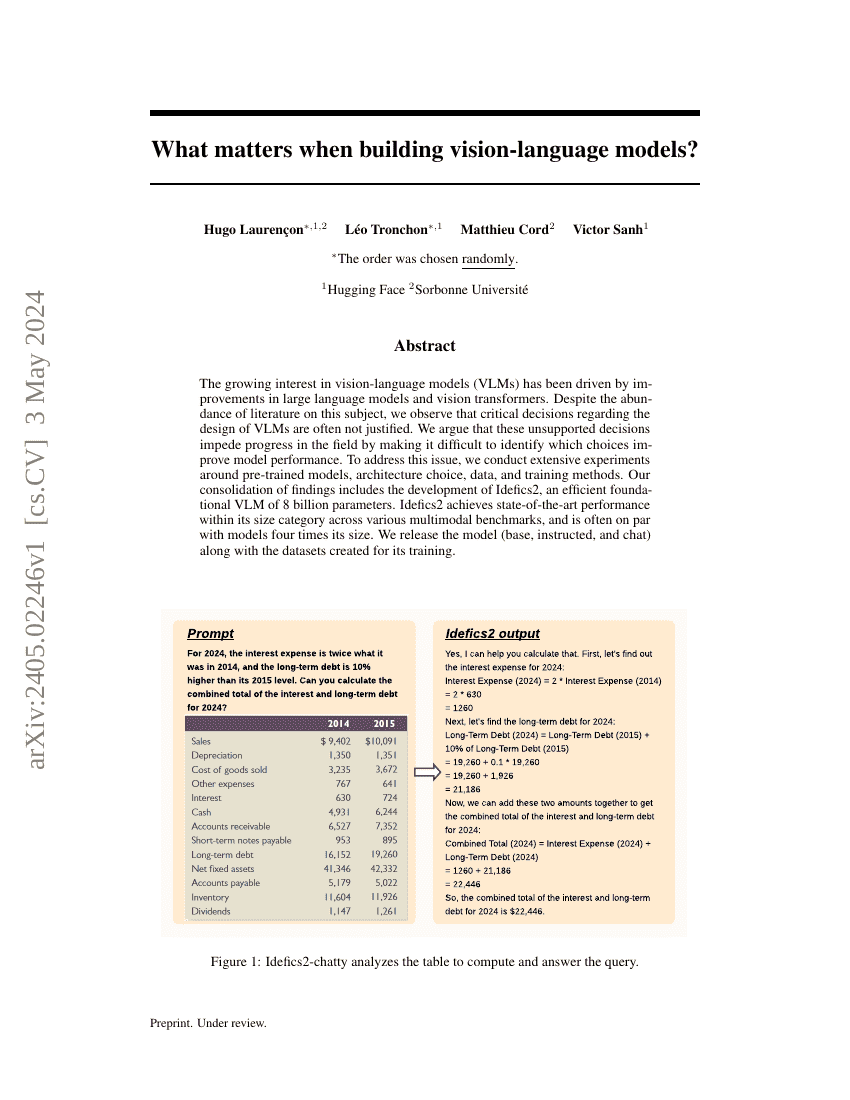
构建视觉-语言模型时,什么因素至关重要?
多模态
Transformer
Hugo Laurençon, Léo Tronchon, Matthieu Cord, et al.
DDOS:无人机深度与障碍物分割数据集
深度估计
语义分割
Benedikt Kolbeinsson, Krystian Mikolajczyk
基于深度学习的按需逆向设计具有任意目标带隙的超材料的框架
深度学习
卷积神经网络
Than V. Tran, S. S. Nanthakumar, Xiaoying Zhuang
PRefLexOR:基于偏好的递归语言建模用于推理与智能体思维的探索性优化
偏好
强化学习
Markus J. Buehler
自回归模型与流匹配模型:文本到音乐生成建模范式的比较研究
音频生成
扩散模型
Tal, Or, Kreuk, et al.
SeerAttention-R:用于长推理的稀疏注意力适应
Transformer
自然语言处理
Gao, Yizhao, Guo, et al.
PlayerOne:以自我为中心的世界模拟器
视频生成
图生视频
Yuanpeng Tu, Hao Luo, Xi Chen, et al.
ComfyUI-R1:探索用于工作流生成的推理模型
ComfyUI
推理
Zhenran Xu, Yiyu Wang, Xue Yang, et al.
自回归对抗后训练在实时交互视频生成中的应用
视频生成
扩散模型
Shanchuan Lin, Ceyuan Yang, Hao He, et al.
信心即一切:语言模型的少样本强化学习微调
强化学习
监督式微调
Li, Pengyi, Skripkin, et al.
1
45
46
47
48
SWE-Factory:您的自动化问题解决训练数据和评估基准工厂
代码生成
基准
Lianghong Guo, Yanlin Wang, Caihua Li, et al.
ReasonMed:一个由多代理生成的370K数据集,用于推进医学推理
推理
数据集
Yu Sun, Xingyu Qian, Weiwen Xu, et al.
智人:人类视觉模型的基础
计算机视觉
多任务学习
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, et al.
LongVILA:面向长视频的长上下文视觉语言模型扩展
LLM
Transformer
Fuzhao Xue, Yukang Chen, Dacheng Li, et al.
DeepSeek-Prover-V1.5:利用证明助手反馈进行强化学习与蒙特卡洛树搜索
LLM
强化学习
Huajian Xin, Z. Z. Ren, Junxiao Song, et al.
LLaVA-OneVision:简易视觉任务迁移
多模态
视频理解
Bo Li, Yuanhan Zhang, Dong Guo, et al.
SAM 2:图像与视频中的任意分割
计算机视觉
视频理解
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, et al.
Llama 3 模型群
LLM
Transformer
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al.
InternLM-XComposer-2.5:一个支持长上下文输入与输出的通用大视觉语言模型
统一多模态
多模态表征
Pan Zhang, Xiaoyi Dong, Yuhang Zang, et al.
MMDU:面向LVLMs的多轮多图像对话理解基准与指令微调数据集
多模态
数据集
Ziyu Liu, Tao Chu, Yuhang Zang, et al.
构建视觉-语言模型时,什么因素至关重要?
多模态
Transformer
Hugo Laurençon, Léo Tronchon, Matthieu Cord, et al.
DDOS:无人机深度与障碍物分割数据集
深度估计
语义分割
Benedikt Kolbeinsson, Krystian Mikolajczyk
基于深度学习的按需逆向设计具有任意目标带隙的超材料的框架
深度学习
卷积神经网络
Than V. Tran, S. S. Nanthakumar, Xiaoying Zhuang
PRefLexOR:基于偏好的递归语言建模用于推理与智能体思维的探索性优化
偏好
强化学习
Markus J. Buehler
自回归模型与流匹配模型:文本到音乐生成建模范式的比较研究
音频生成
扩散模型
Tal, Or, Kreuk, et al.
SeerAttention-R:用于长推理的稀疏注意力适应
Transformer
自然语言处理
Gao, Yizhao, Guo, et al.
PlayerOne:以自我为中心的世界模拟器
视频生成
图生视频
Yuanpeng Tu, Hao Luo, Xi Chen, et al.
ComfyUI-R1:探索用于工作流生成的推理模型
ComfyUI
推理
Zhenran Xu, Yiyu Wang, Xue Yang, et al.
自回归对抗后训练在实时交互视频生成中的应用
视频生成
扩散模型
Shanchuan Lin, Ceyuan Yang, Hao He, et al.
信心即一切:语言模型的少样本强化学习微调
强化学习
监督式微调
Li, Pengyi, Skripkin, et al.
1
45
46
47
48