HyperAI
HyperAI超神经
首页
算力平台
文档
资讯
论文
教程
数据集
百科
SOTA
LLM 模型天梯
GPU 天梯
顶会
开源项目
全站搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI超神经
Toggle Sidebar
全站搜索…
⌘
K
Command Palette
Search for a command to run...
算力平台
首页
论文
论文
每日更新的前沿 AI 研究论文,助您把握人工智能最新动向
HyperAI
HyperAI超神经
首页
算力平台
文档
资讯
论文
教程
数据集
百科
SOTA
LLM 模型天梯
GPU 天梯
顶会
开源项目
全站搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI超神经
Toggle Sidebar
全站搜索…
⌘
K
Command Palette
Search for a command to run...
算力平台
首页
论文
论文
每日更新的前沿 AI 研究论文,助您把握人工智能最新动向
论文 | HyperAI超神经
视频作为提示:视频生成的统一语义控制
Yuxuan Bian, Xin Chen, Zenan Li, et al.
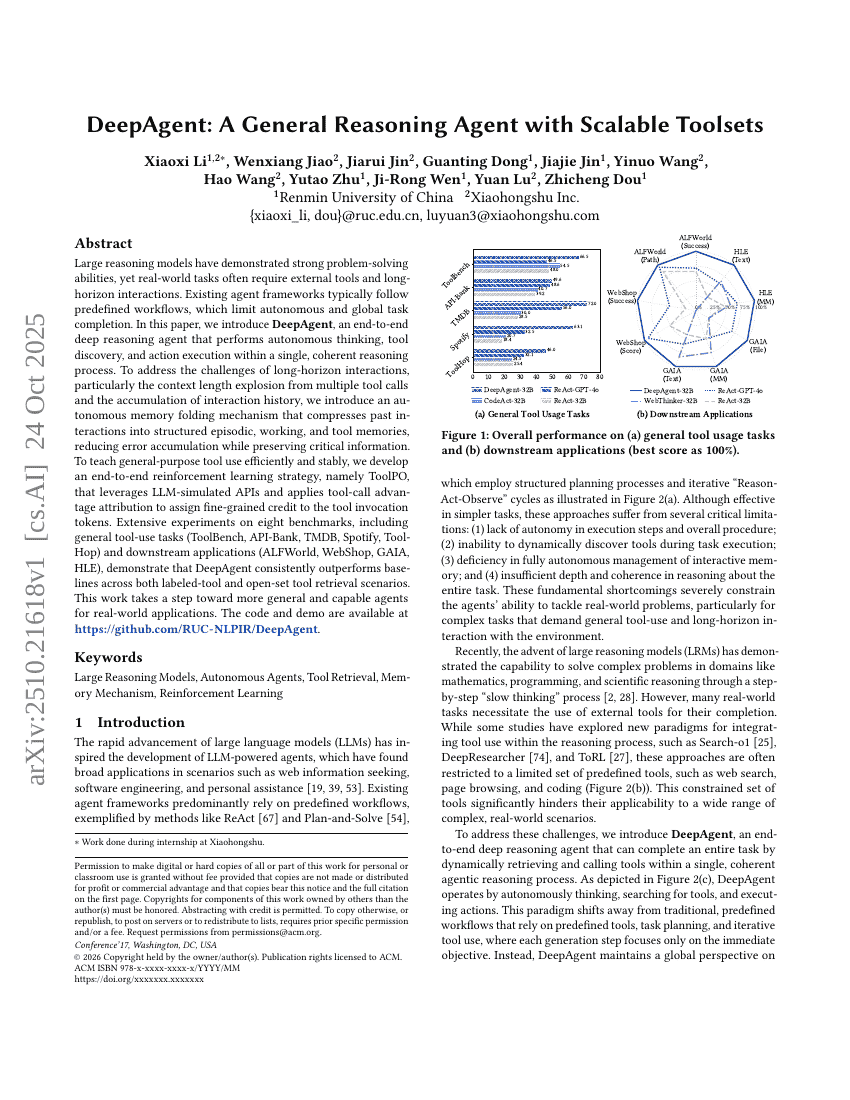
DeepAgent:具备可扩展工具集的通用推理Agent
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
不确定性感知的多目标强化学习引导的扩散模型用于三维从头分子设计
Lianghong Chen, Dongkyu Eugene Kim, Mike Domaratzki, et al.
Reac-Discovery:一种由人工智能驱动的连续流催化反应器发现与优化平台
Cristopher Tinajero, Marcileia Zanatta, Julián E. Sánchez-Velandia, et al.
BoltzGen:迈向通用结合剂设计
Hannes Stark, Felix Faltings, MinGyu Choi, et al.
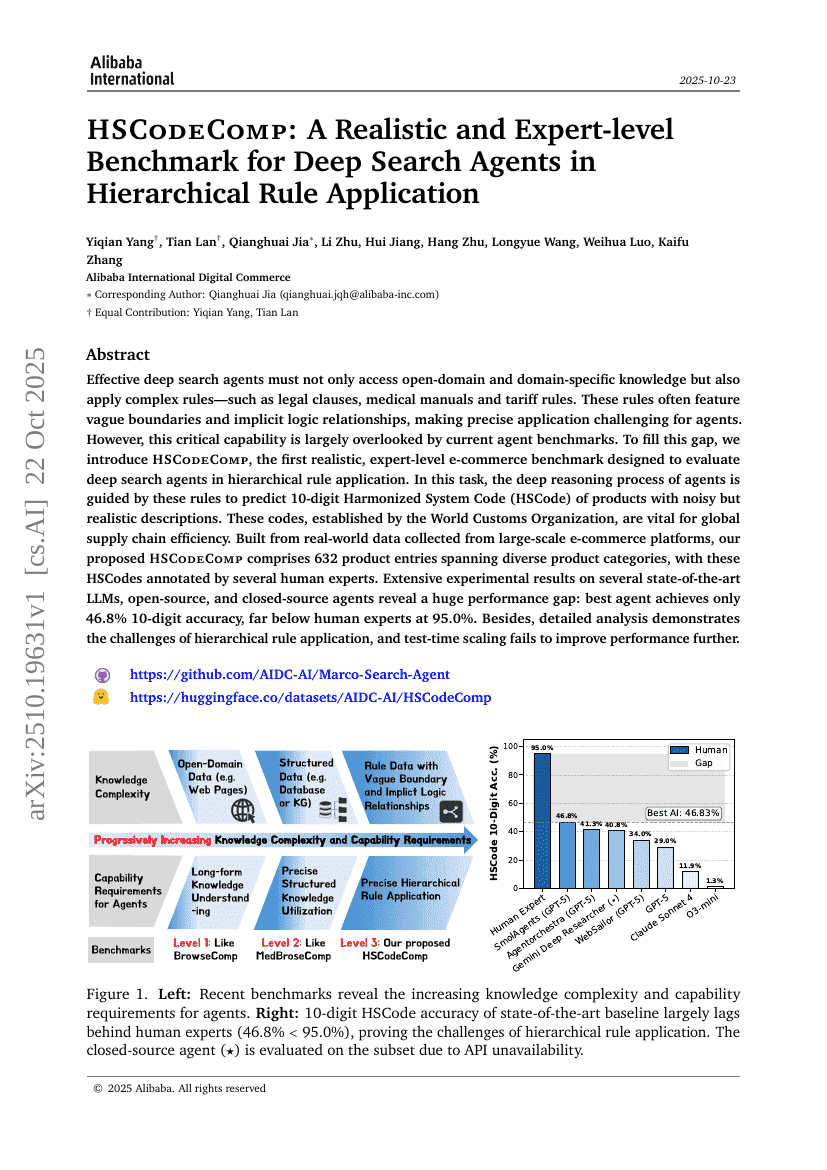
HSCodeComp:面向层级规则应用中深度搜索Agent的现实且专家级基准
Yiqian Yang, Tian Lan, Qianghuai Jia, et al.
DyPE:用于超高分辨率扩散的动态位置外推
Noam Issachar, Guy Yariv, Sagie Benaim, et al.
HoloCine:电影级多镜头长视频叙事的全局生成
Yihao Meng, Hao Ouyang, Yue Yu, et al.
Open-o3 Video:基于显式时空证据的视频推理
Jiahao Meng, Xiangtai Li, Haochen Wang, et al.
AdaSPEC:用于高效推测解码器的可选知识蒸馏
Yuezhou Hu, Jiaxin Guo, Xinyu Feng, et al.
人类-Agent协同的论文到页面制作成本低于0.1美元
Qianli Ma, Siyu Wang, Yilin Chen, et al.
从Token化到视觉阅读
Ling Xing, Alex Jinpeng Wang, Rui Yan, et al.
用于微调MLLMs的定向推理注入
Chao Huang, Zeliang Zhang, Jiang Liu, et al.
语言模型是单射的,因此可逆
Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, et al.
自由Transformer
François Fleuret
基于机器学习的量子处理单元(QPU)处理时间预测
Lucy Xing, Sanjay Vishwakarma, David Kremer, et al.
量子遍历性边缘的建设性干涉观测
Google Quantum AI and Collaborators
VideoAgentTrek:从无标签视频中进行计算机使用预训练
Dunjie Lu, Yiheng Xu, Junli Wang, et al.
GigaBrain-0:基于世界模型的视觉-语言-行动模型
GigaBrain Team, Angen Ye, Boyuan Wang, et al.
LoongRL:面向长上下文的高级推理强化学习
Siyuan Wang, Gaokai Zhang, Li Lyna Zhang, et al.
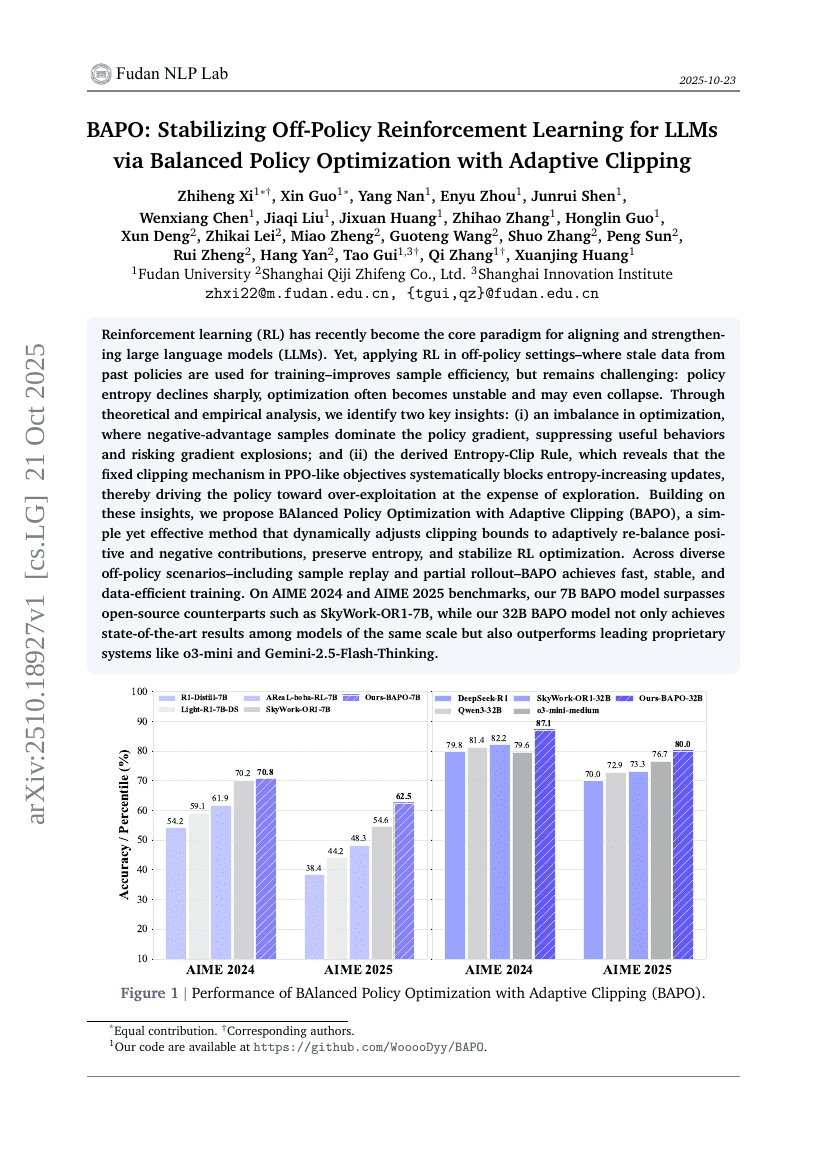
BAPO:通过自适应裁剪的平衡策略优化稳定化LLM的离策略强化学习
Zhiheng Xi, Xin Guo, Yang Nan, et al.
每个Attention都至关重要:一种用于长上下文推理的高效混合架构
Ling Team, Bin Han, Caizhi Tang, et al.
正确着色:连接感知色彩空间与文本嵌入以提升扩散生成效果
Sung-Lin Tsai, Bo-Lun Huang, Yu Ting Shen, et al.
基于视觉-语言模型的自指多视角场景空间推理
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, et al.
LoFT:面向开放世界场景中长尾半监督学习的参数高效微调
Jiahao Chen, Zhiyuan Huang, Yurou Liu, et al.
FLOWER:通过高效的视觉-语言-动作流策略实现通用机器人策略的民主化
Moritz Reuss, Hongyi Zhou, Marcel Rühle, et al.
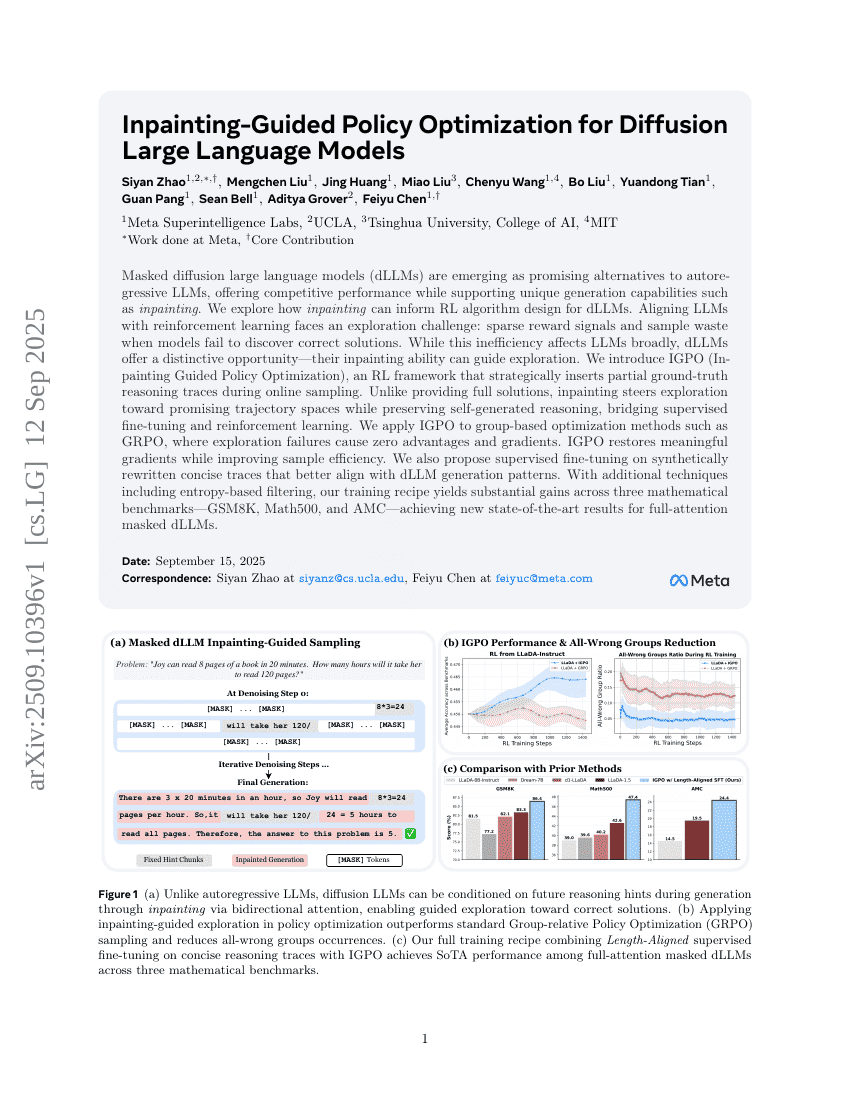
基于图像修复引导的扩散型大语言模型策略优化
Siyan Zhao, Mengchen Liu, Jing Huang, et al.
MCP-AgentBench:通过MCP中介工具评估真实世界语言Agent性能
Zikang Guo, Benfeng Xu, Chiwei Zhu, et al.
扩散模型中的缓存方法综述:面向高效多模态生成
Jiacheng Liu, Xinyu Wang, Yuqi Lin, et al.
重新思考驾驶世界模型作为感知任务的合成数据生成器
Kai Zeng, Zhanqian Wu, Kaixin Xiong, et al.
空间可变对焦
Yingsi Qin, Aswin C. Sankaranarayanan, Matthew O'Toole
何时进行集成:识别用于稳定且快速LLM集成的token级点
Heecheol Yun, Kwangmin Ki, Junghyun Lee, et al.
1
7
8
9
10
11
12
13
37
视频作为提示:视频生成的统一语义控制
Yuxuan Bian, Xin Chen, Zenan Li, et al.
DeepAgent:具备可扩展工具集的通用推理Agent
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
不确定性感知的多目标强化学习引导的扩散模型用于三维从头分子设计
Lianghong Chen, Dongkyu Eugene Kim, Mike Domaratzki, et al.
Reac-Discovery:一种由人工智能驱动的连续流催化反应器发现与优化平台
Cristopher Tinajero, Marcileia Zanatta, Julián E. Sánchez-Velandia, et al.
BoltzGen:迈向通用结合剂设计
Hannes Stark, Felix Faltings, MinGyu Choi, et al.
HSCodeComp:面向层级规则应用中深度搜索Agent的现实且专家级基准
Yiqian Yang, Tian Lan, Qianghuai Jia, et al.
DyPE:用于超高分辨率扩散的动态位置外推
Noam Issachar, Guy Yariv, Sagie Benaim, et al.
HoloCine:电影级多镜头长视频叙事的全局生成
Yihao Meng, Hao Ouyang, Yue Yu, et al.
Open-o3 Video:基于显式时空证据的视频推理
Jiahao Meng, Xiangtai Li, Haochen Wang, et al.
AdaSPEC:用于高效推测解码器的可选知识蒸馏
Yuezhou Hu, Jiaxin Guo, Xinyu Feng, et al.
人类-Agent协同的论文到页面制作成本低于0.1美元
Qianli Ma, Siyu Wang, Yilin Chen, et al.
从Token化到视觉阅读
Ling Xing, Alex Jinpeng Wang, Rui Yan, et al.
用于微调MLLMs的定向推理注入
Chao Huang, Zeliang Zhang, Jiang Liu, et al.
语言模型是单射的,因此可逆
Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, et al.
自由Transformer
François Fleuret
基于机器学习的量子处理单元(QPU)处理时间预测
Lucy Xing, Sanjay Vishwakarma, David Kremer, et al.
量子遍历性边缘的建设性干涉观测
Google Quantum AI and Collaborators
VideoAgentTrek:从无标签视频中进行计算机使用预训练
Dunjie Lu, Yiheng Xu, Junli Wang, et al.
GigaBrain-0:基于世界模型的视觉-语言-行动模型
GigaBrain Team, Angen Ye, Boyuan Wang, et al.
LoongRL:面向长上下文的高级推理强化学习
Siyuan Wang, Gaokai Zhang, Li Lyna Zhang, et al.
BAPO:通过自适应裁剪的平衡策略优化稳定化LLM的离策略强化学习
Zhiheng Xi, Xin Guo, Yang Nan, et al.
每个Attention都至关重要:一种用于长上下文推理的高效混合架构
Ling Team, Bin Han, Caizhi Tang, et al.
正确着色:连接感知色彩空间与文本嵌入以提升扩散生成效果
Sung-Lin Tsai, Bo-Lun Huang, Yu Ting Shen, et al.
基于视觉-语言模型的自指多视角场景空间推理
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, et al.
LoFT:面向开放世界场景中长尾半监督学习的参数高效微调
Jiahao Chen, Zhiyuan Huang, Yurou Liu, et al.
FLOWER:通过高效的视觉-语言-动作流策略实现通用机器人策略的民主化
Moritz Reuss, Hongyi Zhou, Marcel Rühle, et al.
基于图像修复引导的扩散型大语言模型策略优化
Siyan Zhao, Mengchen Liu, Jing Huang, et al.
MCP-AgentBench:通过MCP中介工具评估真实世界语言Agent性能
Zikang Guo, Benfeng Xu, Chiwei Zhu, et al.
扩散模型中的缓存方法综述:面向高效多模态生成
Jiacheng Liu, Xinyu Wang, Yuqi Lin, et al.
重新思考驾驶世界模型作为感知任务的合成数据生成器
Kai Zeng, Zhanqian Wu, Kaixin Xiong, et al.
空间可变对焦
Yingsi Qin, Aswin C. Sankaranarayanan, Matthew O'Toole
何时进行集成:识别用于稳定且快速LLM集成的token级点
Heecheol Yun, Kwangmin Ki, Junghyun Lee, et al.
1
7
8
9
10
11
12
13
37