HyperAI
HyperAI超神经
首页
算力平台
文档
资讯
论文
教程
数据集
百科
SOTA
LLM 模型天梯
GPU 天梯
顶会
开源项目
全站搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI超神经
Toggle Sidebar
全站搜索…
⌘
K
Command Palette
Search for a command to run...
算力平台
首页
论文
论文
每日更新的前沿 AI 研究论文,助您把握人工智能最新动向
HyperAI
HyperAI超神经
首页
算力平台
文档
资讯
论文
教程
数据集
百科
SOTA
LLM 模型天梯
GPU 天梯
顶会
开源项目
全站搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI超神经
Toggle Sidebar
全站搜索…
⌘
K
Command Palette
Search for a command to run...
算力平台
首页
论文
论文
每日更新的前沿 AI 研究论文,助您把握人工智能最新动向
论文 | HyperAI超神经
使用PLACER建模蛋白质-小分子构象集合
Ivan Anishchenko, Yakov Kipnis, Indrek Kalvet, et al.
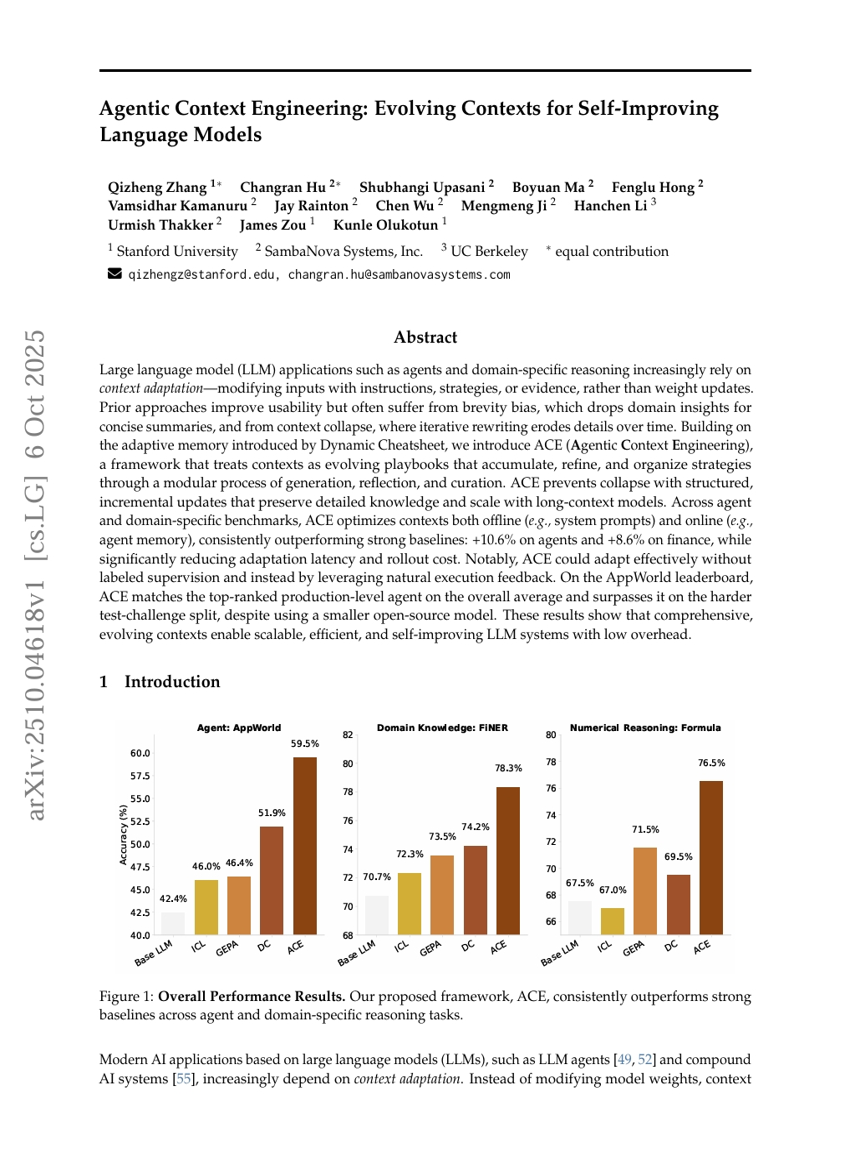
Agentic上下文工程:面向自提升语言模型的上下文演化
Qizheng Zhang, Changran Hu, Shubhangi Upasani, et al.
DiaMoE-TTS:一种基于IPA的统一方言TTS框架,支持多专家模型与参数高效零样本适配
Ziqi Chen, Gongyu Chen, Yihua Wang, et al.
AI辅助的AR装配:用于增强现实辅助装配的物体识别与计算机视觉
Alexander Htet Kyaw, Haotian Ma, Sasa Zivkovic, et al.
在针堆中越狱
Rishi Rajesh Shah, Chen Henry Wu, Shashwat Saxena, et al.
CritiCal:批判性反馈能否帮助LLM不确定性或置信度校准?
Qing Zong, Jiayu Liu, Tianshi Zheng, et al.
通过优化文本嵌入缓解大型视觉-语言模型中的幻觉问题
Aakriti Agrawal, Gouthaman KV, Rohith Aralikatti, et al.
视觉空间调谐
Rui Yang, Ziyu Zhu, Yanwei Li, et al.
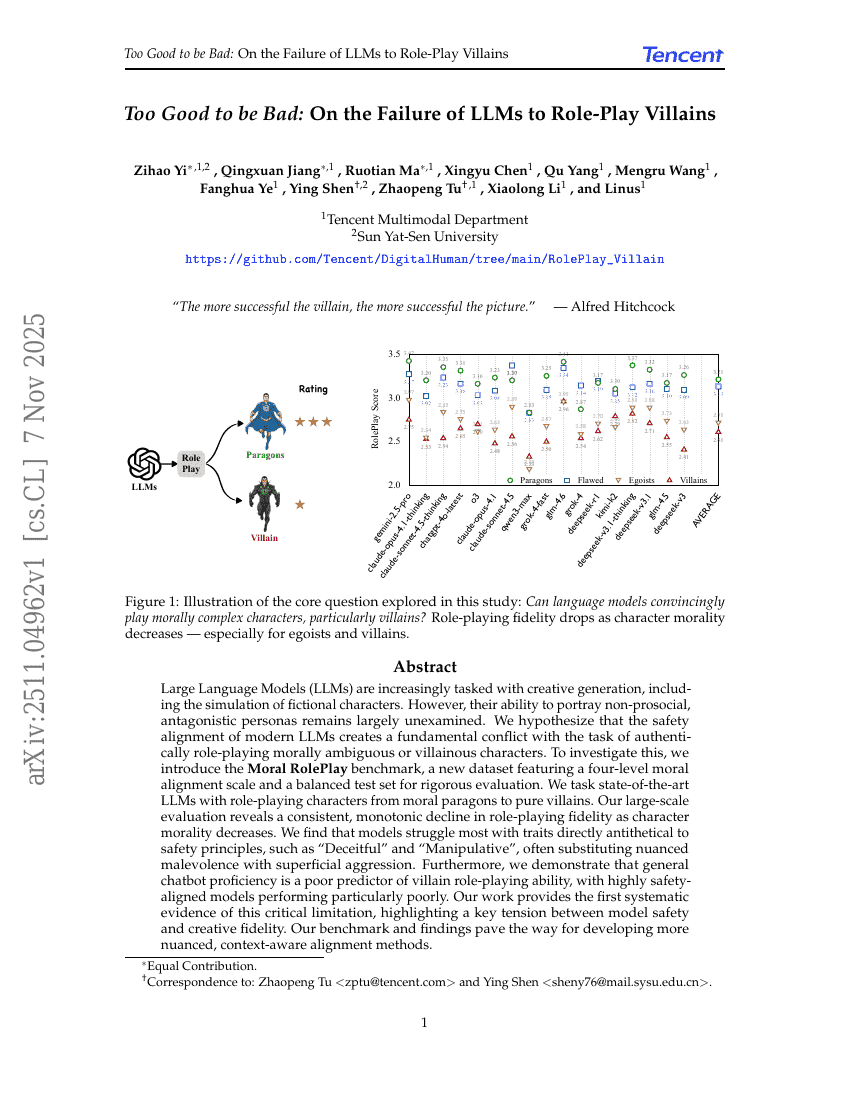
好到不像反派:论LLMs在扮演反派角色时的失败
Zihao Yi, Qingxuan Jiang, Ruotian Ma, et al.
DeepEyesV2:迈向代理型多模态模型
Jack Hong, Chenxiao Zhao, ChengLin Zhu, et al.
基于机器学习的连续血糖监测用于识别代谢亚表型并指导精准生活方式干预
Ahmed A. Metwally, Heyjun Park, Yue Wu, et al.
在测试阶段重用预训练数据是一种计算倍增器
Alex Fang, Thomas Voice, Ruoming Pang, et al.
NVIDIA Nemotron Nano V2 VL
NVIDIA, Amala Sanjay Deshmukh, Kateryna Chumachenko, et al.
CostBench:评估LLM工具使用Agent在动态环境中多轮成本最优规划与适应性
Jiayu Liu, Cheng Qian, Zhaochen Su, et al.
寒武纪-S:迈向视频中的空间超感知
Shusheng Yang, Jihan Yang, Pinzhi Huang, et al.
通过经验合成实现Agent学习的扩展
Zhaorun Chen, Zhuokai Zhao, Kai Zhang, et al.
V-Thinker:与图像交互的思考
Runqi Qiao, Qiuna Tan, Minghan Yang, et al.
基于视频的思考:视频生成作为一种有前景的多模态推理范式
Jingqi Tong, Yurong Mou, Hangcheng Li, et al.
Amber生物分子模拟的最新进展
David A. Case, David S. Cerutti, Vinicius Wilian D. Cruzeiro, et al.
UltraHR-100K:基于大规模高质量数据集增强UHR图像合成
Chen Zhao, En Ci, Yunzhe Xu, et al.
从五个维度到众多维度:大型语言模型作为精准且可解释的心理画像工具
Yi-Fei Liu, Yi-Long Lu, Di He, et al.
基于节点的多模态生成:文本、音频、图像与视频
Alexander Htet Kyaw, Lenin Ravindranath Sivalingam
DR. WELL:基于符号世界模型的具身LLM多Agent协作中的动态推理与学习
Narjes Nourzad, Hanqing Yang, Shiyu Chen, et al.
Orion-MSP:用于表格上下文学习的多尺度稀疏注意力
Mohamed Bouadi, Pratinav Seth, Aditya Tanna, et al.
TabTune:用于表格基础模型推理与微调的统一库
Aditya Tanna, Pratinav Seth, Mohamed Bouadi, et al.
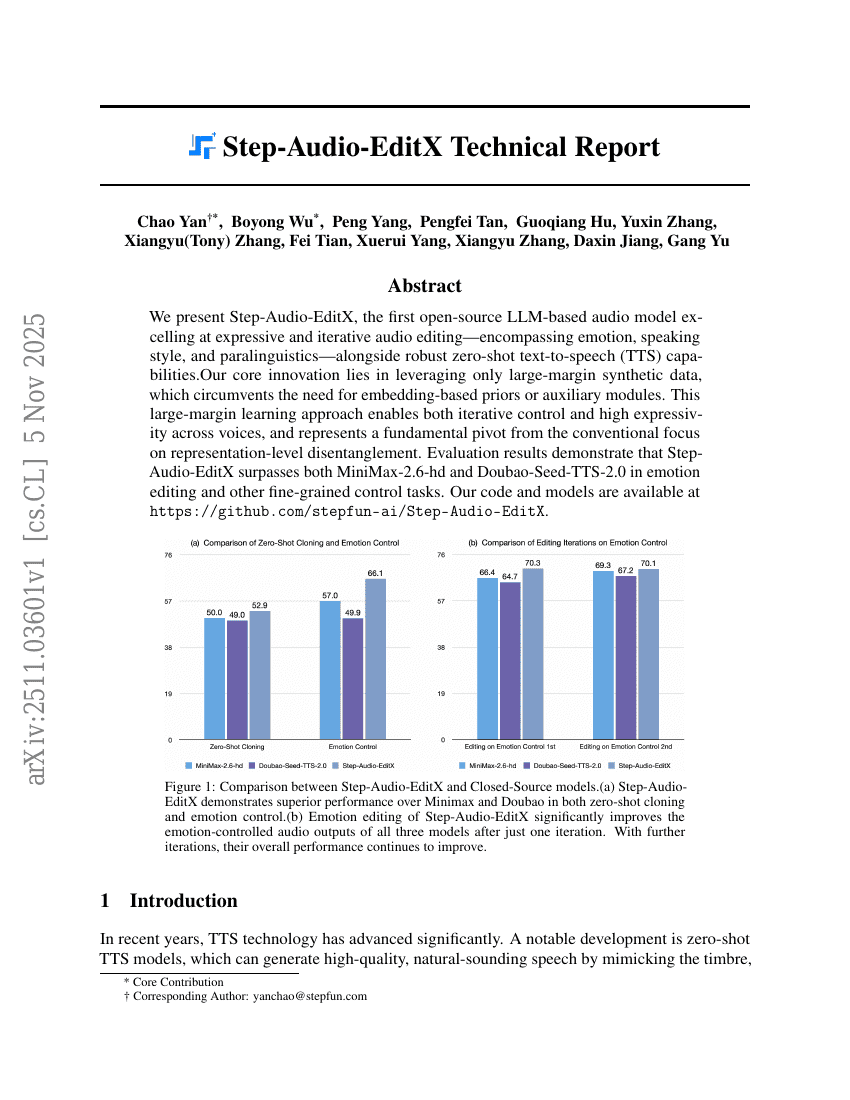
Step-Audio-EditX 技术报告
Chao Yan, Boyong Wu, Peng Yang, et al.
LEGO-Eval:面向通过工具增强合成3D具身环境的细粒度评估
Gyeom Hwangbo, Hyungjoo Chae, Minseok Kang, et al.
UniAVGen:具有非对称跨模态交互的统一音频与视频生成
Guozhen Zhang, Zixiang Zhou, Teng Hu, et al.
扩散语言模型是超数据学习者
Jinjie Ni, Qian Liu, Longxu Dou, et al.
UNO-Bench:一个用于探索Omni模型中单模态与全模态之间组合规律的统一基准
Chen Chen, ZeYang Hu, Fengjiao Chen, et al.
基于扩散模型的动态人口分布感知人类轨迹生成
Qingyue Long, Can Rong, Tong Li, et al.
基于3D生成式AI与视觉语言模型的文本到机器人多组件物体装配
Alexander Htet Kyaw, Richa Gupta, Dhruv Shah, et al.
1
4
5
6
7
8
9
10
37
使用PLACER建模蛋白质-小分子构象集合
Ivan Anishchenko, Yakov Kipnis, Indrek Kalvet, et al.
Agentic上下文工程:面向自提升语言模型的上下文演化
Qizheng Zhang, Changran Hu, Shubhangi Upasani, et al.
DiaMoE-TTS:一种基于IPA的统一方言TTS框架,支持多专家模型与参数高效零样本适配
Ziqi Chen, Gongyu Chen, Yihua Wang, et al.
AI辅助的AR装配:用于增强现实辅助装配的物体识别与计算机视觉
Alexander Htet Kyaw, Haotian Ma, Sasa Zivkovic, et al.
在针堆中越狱
Rishi Rajesh Shah, Chen Henry Wu, Shashwat Saxena, et al.
CritiCal:批判性反馈能否帮助LLM不确定性或置信度校准?
Qing Zong, Jiayu Liu, Tianshi Zheng, et al.
通过优化文本嵌入缓解大型视觉-语言模型中的幻觉问题
Aakriti Agrawal, Gouthaman KV, Rohith Aralikatti, et al.
视觉空间调谐
Rui Yang, Ziyu Zhu, Yanwei Li, et al.
好到不像反派:论LLMs在扮演反派角色时的失败
Zihao Yi, Qingxuan Jiang, Ruotian Ma, et al.
DeepEyesV2:迈向代理型多模态模型
Jack Hong, Chenxiao Zhao, ChengLin Zhu, et al.
基于机器学习的连续血糖监测用于识别代谢亚表型并指导精准生活方式干预
Ahmed A. Metwally, Heyjun Park, Yue Wu, et al.
在测试阶段重用预训练数据是一种计算倍增器
Alex Fang, Thomas Voice, Ruoming Pang, et al.
NVIDIA Nemotron Nano V2 VL
NVIDIA, Amala Sanjay Deshmukh, Kateryna Chumachenko, et al.
CostBench:评估LLM工具使用Agent在动态环境中多轮成本最优规划与适应性
Jiayu Liu, Cheng Qian, Zhaochen Su, et al.
寒武纪-S:迈向视频中的空间超感知
Shusheng Yang, Jihan Yang, Pinzhi Huang, et al.
通过经验合成实现Agent学习的扩展
Zhaorun Chen, Zhuokai Zhao, Kai Zhang, et al.
V-Thinker:与图像交互的思考
Runqi Qiao, Qiuna Tan, Minghan Yang, et al.
基于视频的思考:视频生成作为一种有前景的多模态推理范式
Jingqi Tong, Yurong Mou, Hangcheng Li, et al.
Amber生物分子模拟的最新进展
David A. Case, David S. Cerutti, Vinicius Wilian D. Cruzeiro, et al.
UltraHR-100K:基于大规模高质量数据集增强UHR图像合成
Chen Zhao, En Ci, Yunzhe Xu, et al.
从五个维度到众多维度:大型语言模型作为精准且可解释的心理画像工具
Yi-Fei Liu, Yi-Long Lu, Di He, et al.
基于节点的多模态生成:文本、音频、图像与视频
Alexander Htet Kyaw, Lenin Ravindranath Sivalingam
DR. WELL:基于符号世界模型的具身LLM多Agent协作中的动态推理与学习
Narjes Nourzad, Hanqing Yang, Shiyu Chen, et al.
Orion-MSP:用于表格上下文学习的多尺度稀疏注意力
Mohamed Bouadi, Pratinav Seth, Aditya Tanna, et al.
TabTune:用于表格基础模型推理与微调的统一库
Aditya Tanna, Pratinav Seth, Mohamed Bouadi, et al.
Step-Audio-EditX 技术报告
Chao Yan, Boyong Wu, Peng Yang, et al.
LEGO-Eval:面向通过工具增强合成3D具身环境的细粒度评估
Gyeom Hwangbo, Hyungjoo Chae, Minseok Kang, et al.
UniAVGen:具有非对称跨模态交互的统一音频与视频生成
Guozhen Zhang, Zixiang Zhou, Teng Hu, et al.
扩散语言模型是超数据学习者
Jinjie Ni, Qian Liu, Longxu Dou, et al.
UNO-Bench:一个用于探索Omni模型中单模态与全模态之间组合规律的统一基准
Chen Chen, ZeYang Hu, Fengjiao Chen, et al.
基于扩散模型的动态人口分布感知人类轨迹生成
Qingyue Long, Can Rong, Tong Li, et al.
基于3D生成式AI与视觉语言模型的文本到机器人多组件物体装配
Alexander Htet Kyaw, Richa Gupta, Dhruv Shah, et al.
1
4
5
6
7
8
9
10
37