Command Palette
Search for a command to run...
Online Tutorial | Based on 5 Million Hours of Voice Data, Qwen3-TTS Achieves 3-second Voice Cloning and fine-tuning.

When generative AI is no longer limited to "generating text" but begins to truly "speak," speech is upgraded from an information channel to a programmable and malleable medium of expression. From cross-lingual content creation to real-time voice assistants, from virtual anchors to immersive interactive systems, text-to-speech (TTS) is becoming a core component of the multimodal model system.However, to make the machine speak naturally, stably, and controllably, and maintain millisecond-level response in streaming scenarios, it requires not only acoustic modeling capabilities, but also comprehensive strength in architecture design and system optimization.
Along this technological evolution path, the new generation of models has begun to try to break through the boundaries of traditional TTS—not only pursuing higher fidelity, but also emphasizing multilingual generalization ability and fine-grained control ability.Qwen3-TTS, recently open-sourced by the Qwen team, is based on a dual-track language model (LM) architecture, which allows for fine-grained control of the output speech while performing real-time speech synthesis.
Specifically, Qwen3-TTS supports 3-second voice cloning and description-based voice control. It is trained on over 5 million hours of voice data covering 10 languages and is equipped with two speech tokenizers.
* Qwen-TTS-Tokenizer-25Hz:Employing a single-codebook codec, it focuses on semantic content representation, can be seamlessly integrated with Qwen-Audio, and achieves streaming waveform reconstruction through block-wise DiT.
* Qwen-TTS-Tokenizer-12Hz:Achieving extreme bitrate compression and ultra-low latency streaming output, based on a 12.5Hz, 16-layer multi-codebook design and a lightweight causal convolutional network (causal ConvNet), it can achieve instant first packet output in 97 milliseconds.
Extensive experimental results show that this series of models has achieved state-of-the-art (SOTA) performance in multiple objective and subjective benchmark tests, including the TTS multilingual test set and InstructTTSEval.
Currently, "Qwen3-TTS: High-Quality Controllable Multilingual Speech Synthesis Demo" has been uploaded to the "Tutorials" section of the HyperAI website. Come and experience 3-second speech cloning!
Online tutorials:
View the paper:
Demo Run
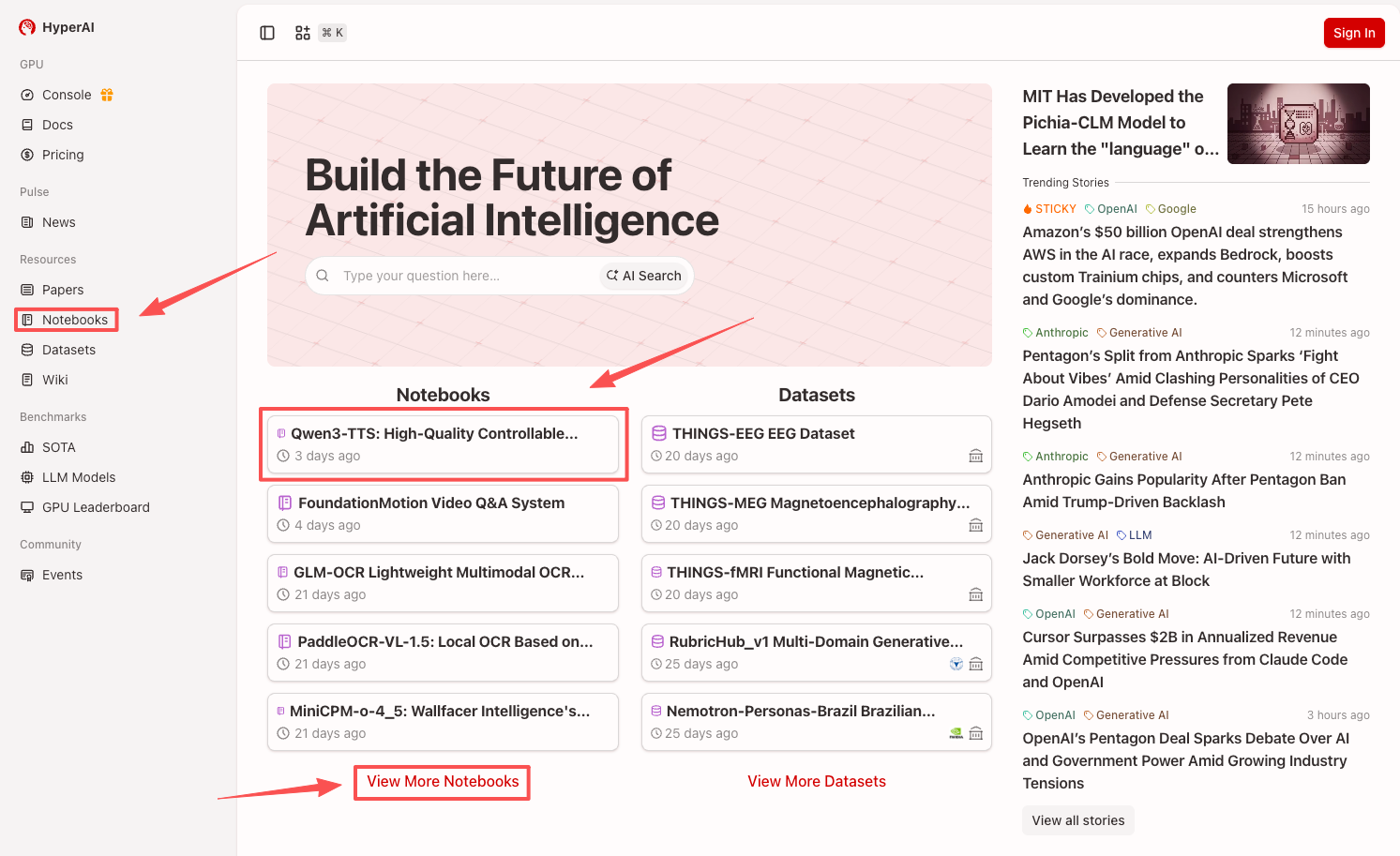
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "Qwen3-TTS: High-Quality Controllable Multilingual Speech Synthesis Demo", and click "Run this tutorial online".
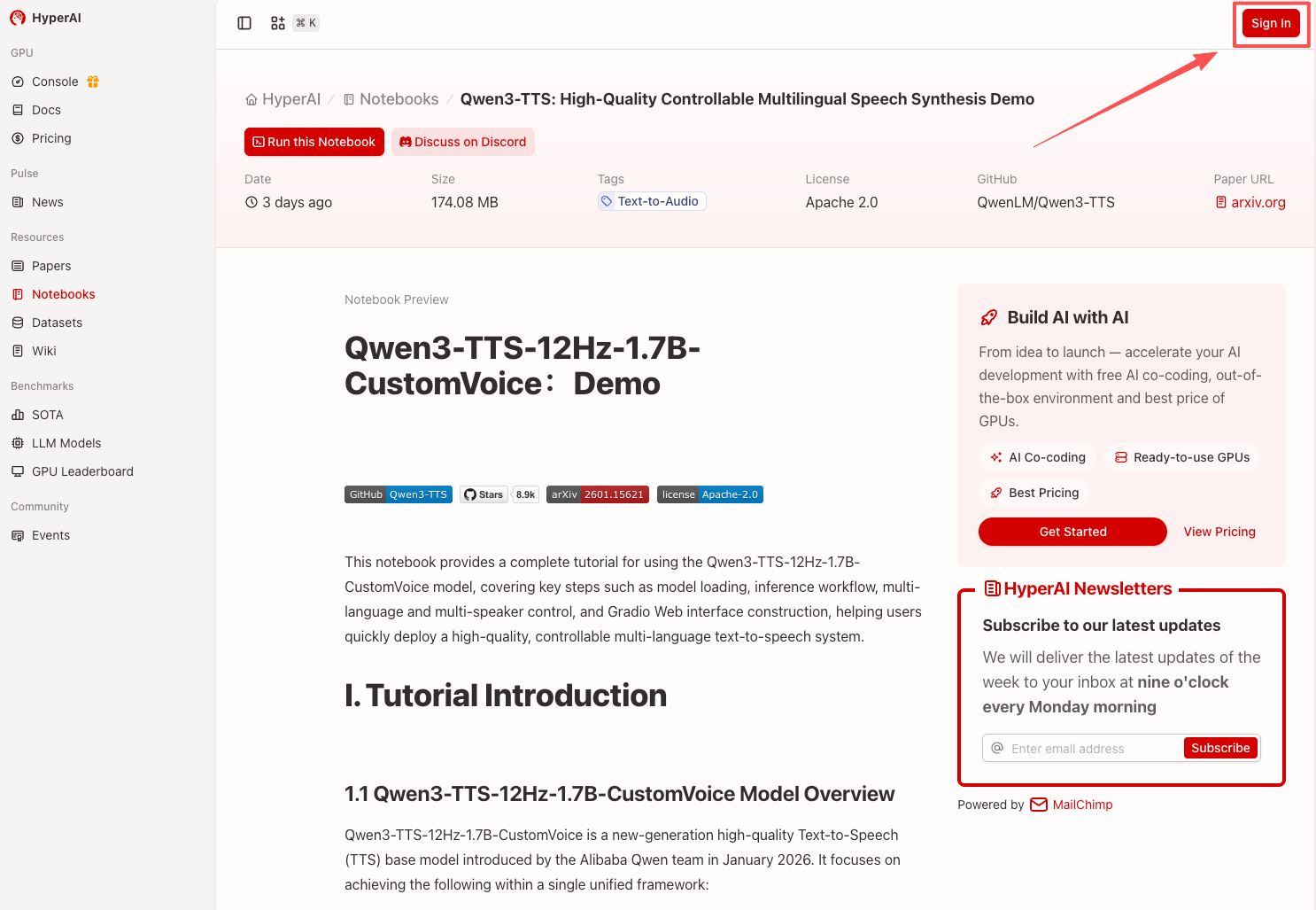
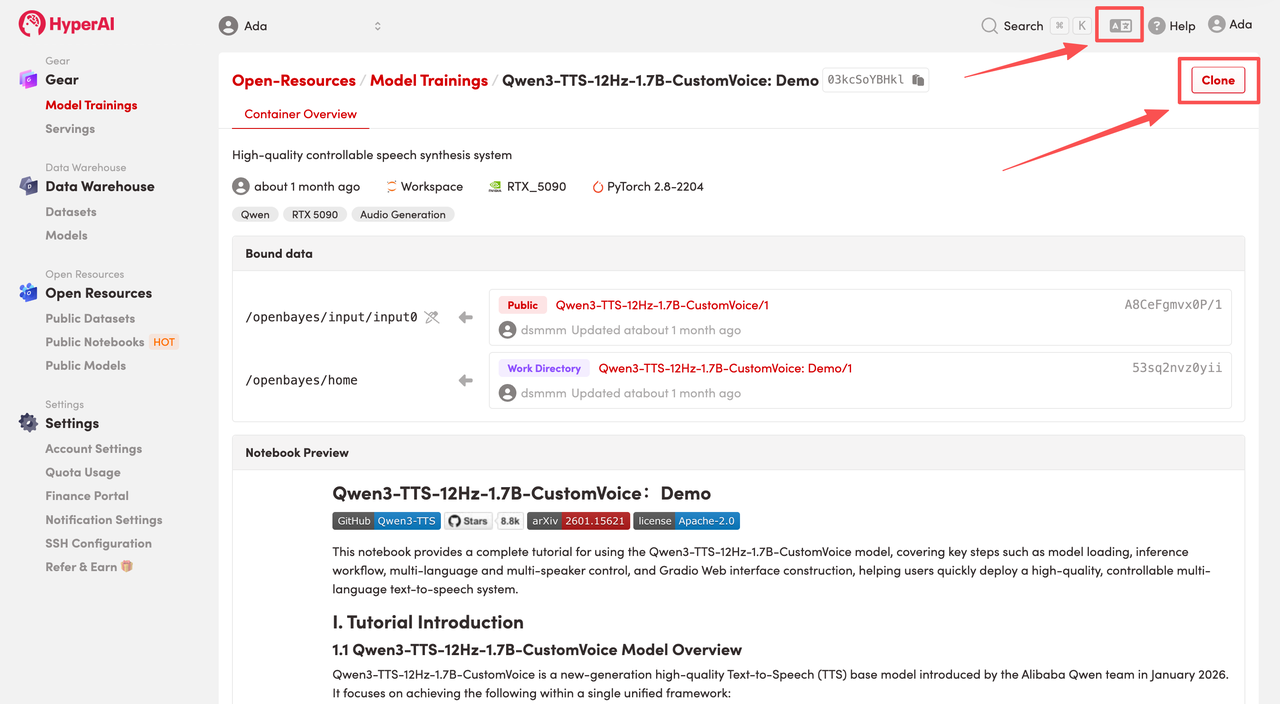
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
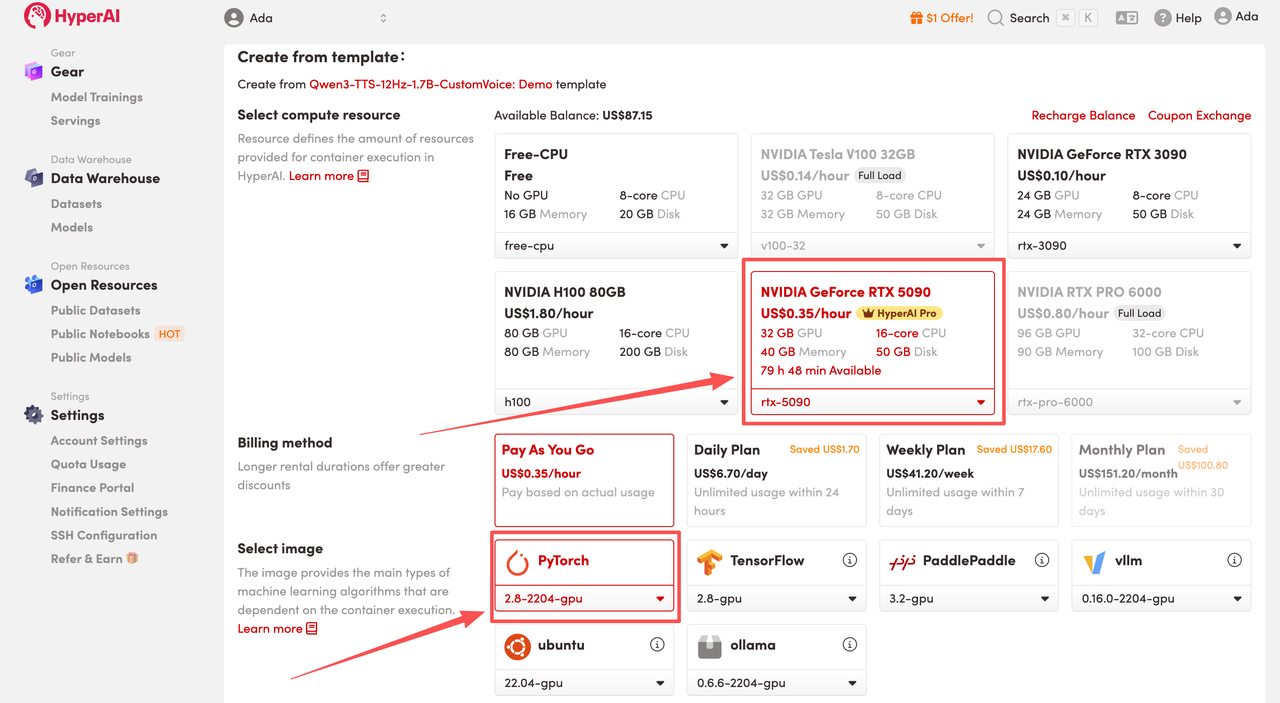
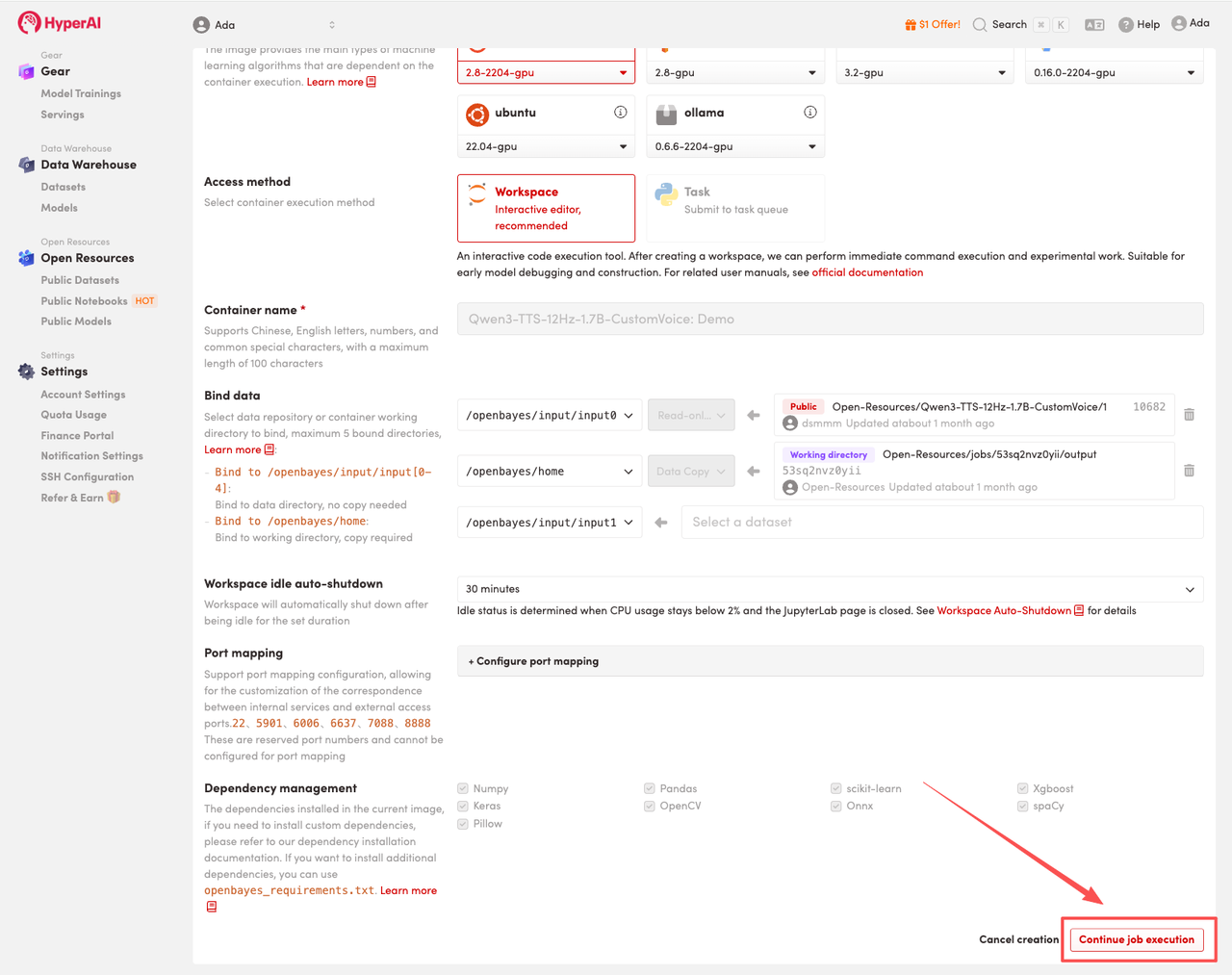
3. Select the "NVIDIA GeForce RTX 5090" and "PyTorch" images, and choose "Pay As You Go" or "Daily Plan/Weekly Plan/Monthly Plan" as needed, then click "Continue job execution".
HyperAI is offering registration benefits for new users.For just $1, you can get 20 hours of RTX 5090 computing power (original price $7).The resource is permanently valid.
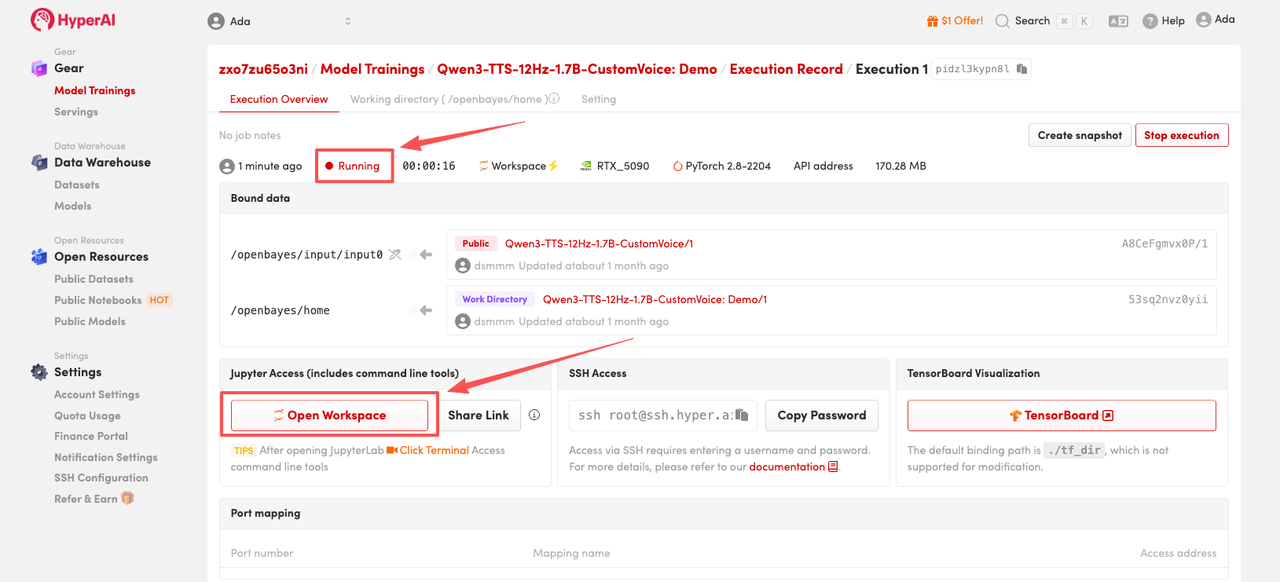
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
Effect Demonstration
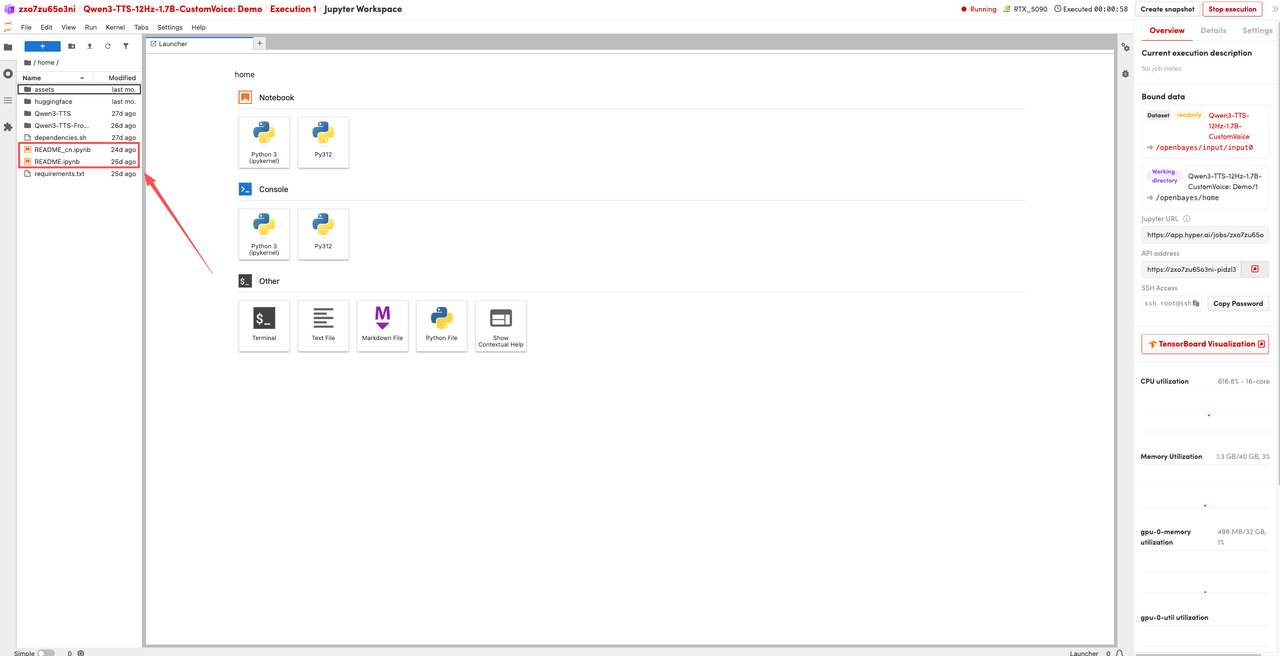
1. After the page redirects, click on the README page on the left, and then click Run at the top.
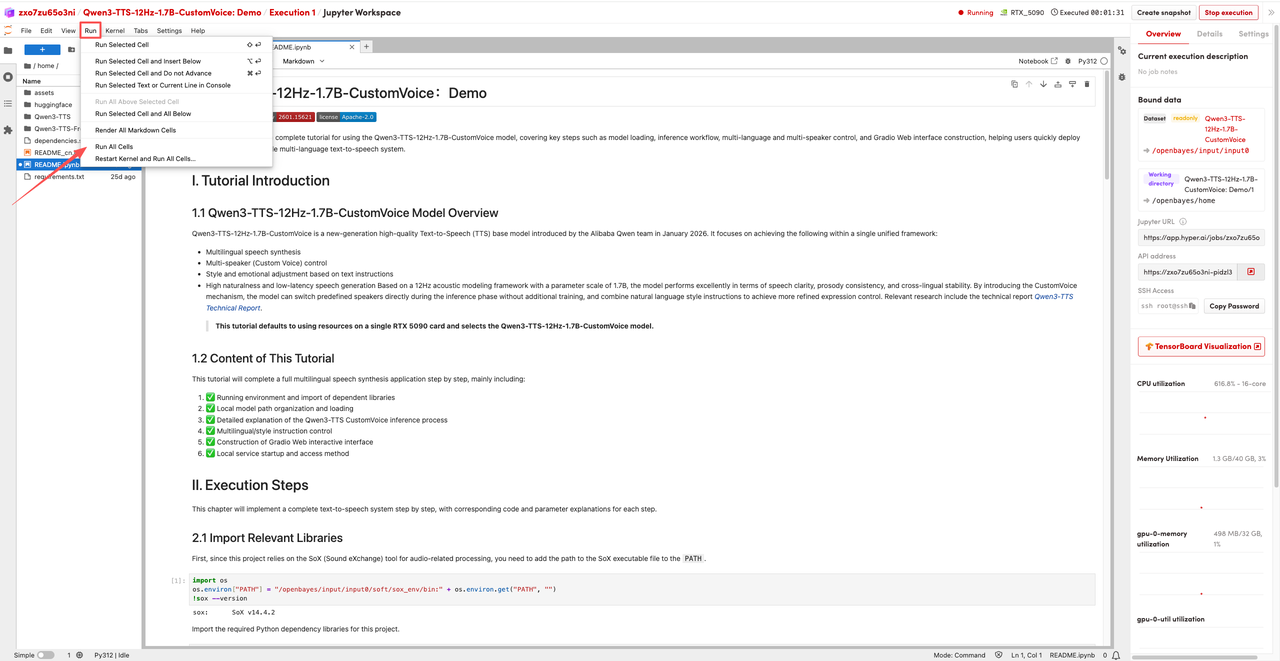
2. Once the process is complete, click the API address on the right to jump to the demo page.
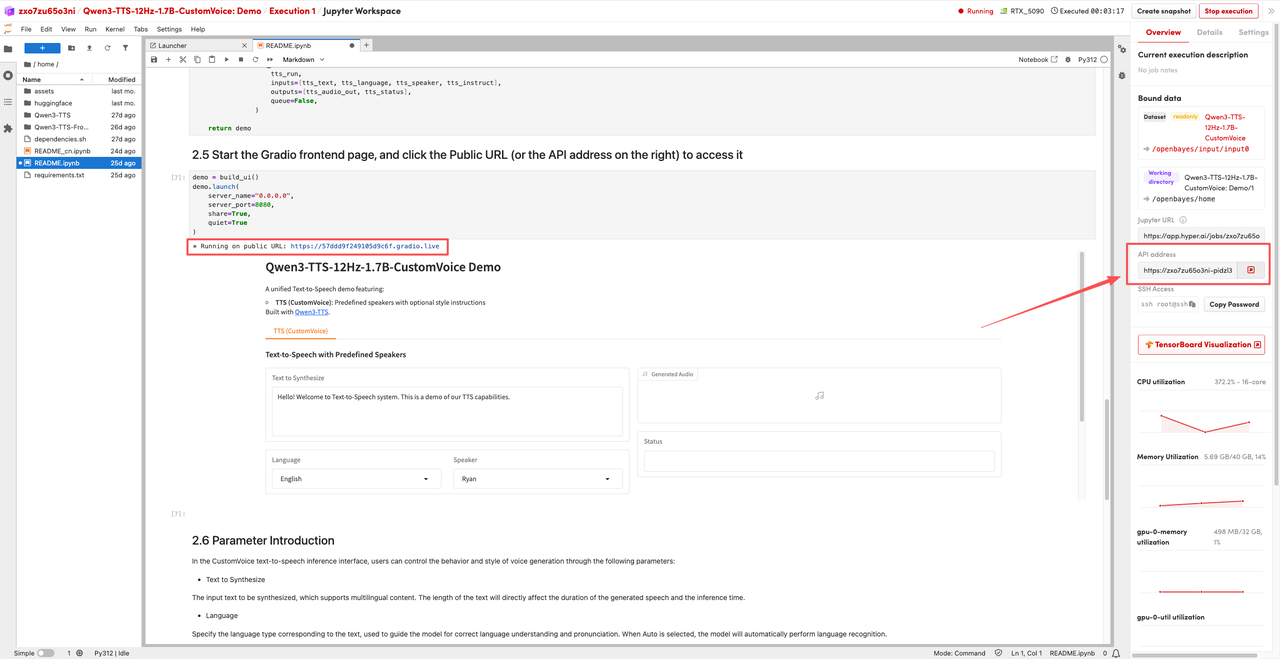
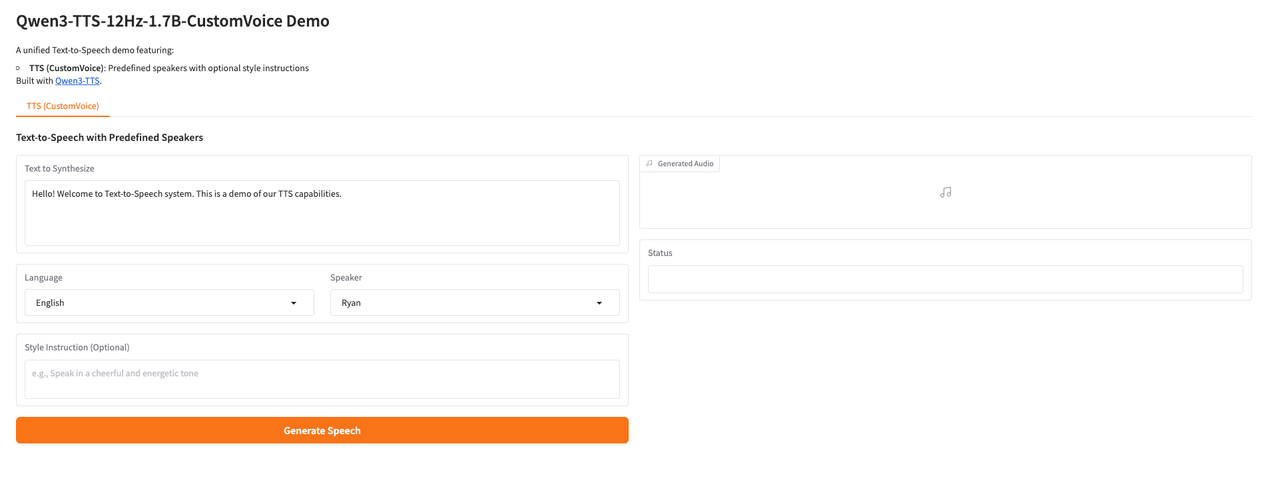
The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
Tutorial Link:https://go.hyper.ai/1xEOr








