Command Palette
Search for a command to run...
Token Usage Decreased by 30%. Eywa, a Heterogeneous Intelligent Agent Framework Inspired by "Avatar," Efficiently Combines Language Models With domain-specific Basic models.

In recent years, Agentic AI has become one of the most important evolutionary directions in the field of artificial intelligence. From automated programming and knowledge retrieval to task planning, Large Language Models (LLMs) are gradually evolving from "chatbots" into intelligent agent systems with autonomous reasoning, action, and collaboration capabilities. However, an increasingly obvious problem is also emerging—Almost all mainstream intelligent agent systems are essentially "language-centric" systems.Whether it's task planning, tool invocation, or collaboration between intelligent agents, they are all built on the unified interface of natural language.
This paradigm works well in scenarios such as internet Q&A and office automation. However, when AI begins to truly enter the field of scientific research, problems quickly emerge. This is because the scientific world does not naturally belong to language. Time series, material crystal structures, protein sequences, meteorological grids, remote sensing observation data... these data are often highly structured, and may even be impossible to effectively "textualize".Forcibly translating them into natural language will not only result in the loss of information, but will also cause large models to suffer from extremely high token consumption and inference redundancy.
In this context,A research team from the University of Illinois at Urbana-Champaign (UIUC) has proposed a heterogeneous agent framework called Eywa for connecting language agents with domain-specific foundational models.Researchers have created a new EywaAgent by combining a domain-specific foundational model with a language model. This design enables the language agent to guide the foundational model in its reasoning, planning, and decision-making processes for specialized tasks.
Researchers conducted a systematic evaluation of Eywa across multiple fields, including physical, life, and social sciences. The results showed that, compared to baseline systems relying solely on language models, Eywa consistently improved the utility-cost trade-off. Compared to the Single-LLM-Agent baseline, EywaAgent achieved an average utility improvement of approximately 71 TP3T, a token reduction of approximately 301 TP3T, and a execution time reduction of approximately 101 TP3T on physical, life, and social science tasks. Similarly, in multi-agent scenarios, EywaMAS also achieved improved utility while reducing token consumption and runtime.
The related research findings, titled "Heterogeneous Scientific Foundation Model Collaboration," have been published as a preprint on arXiv.
Research highlights:
* In tasks involving structured data and domain-specific data, Eywa can effectively improve system performance.
* By effectively collaborating with a dedicated underlying model, Eywa reduces its reliance on language-based reasoning.
* Eywa can be extended to multi-agent scenarios: In EywaMAS, EywaAgent can replace the language agent in a traditional multi-agent system; in EywaOrchestra, a planner can dynamically coordinate the language agent and EywaAgent to solve complex tasks.

View the paper:
https://hyper.ai/papers/2604.27351
EywaBench: A scientific evaluation system that is "multi-task, multi-domain, and multi-modal".
Before proposing the model framework, the research team first pointed out a long-standing problem with current scientific AI benchmarks:In other words, most current scientific benchmarks typically either cover only a single task type, focus only on a single domain, or support only one data format.Therefore, it often fails to fully reflect the capabilities truly required by scientific agentic systems.
The research team specifically points out that current benchmarks have long lacked sufficient evaluation of two core modalities: time series and tabular data. These two types of data constitute the core foundation of real-world scientific computing and industrial systems. Therefore, the paper proposes a new evaluation framework:EywaBench is a scalable benchmark for heterogeneous, multi-task, and multi-domain scientific reasoning.
EywaBench is built on multiple existing datasets, including but not limited to:
* DeepPrinciple
* MMLU-Pro
* fev-bench
* TabArena
EywaBench has multi-task and multi-domain coverage capabilities.It includes three core data modalities: natural language, time series, and tabular data.All tasks are organized into three scientific fields: the first is physical science, including materials, energy and aerospace; the second is life science, including biology, clinical and drug development; and the third is social science, covering scenarios such as economics, business and infrastructure.
More importantly, EywaBench itself is scalable, allowing research teams to continuously expand the scale of their tasks by adding new time windows, variable combinations, and context configurations; it can also access new time series datasets and tabular datasets to expand into new scientific fields.
Eywa: Connecting Language Agents with Domain-Specific Foundation Models
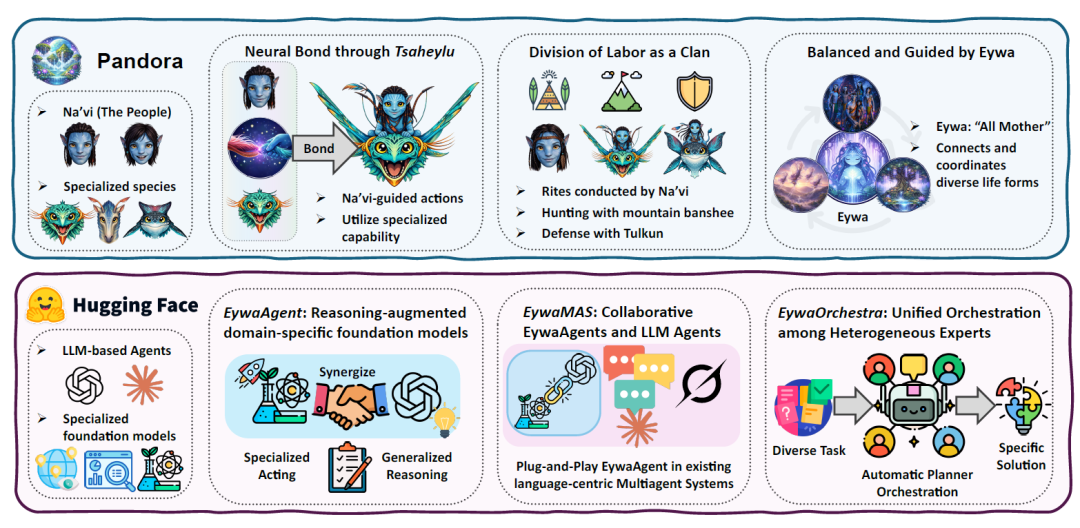
Eywa's core inspiration comes from the "Tsaheylu" concept in the movie Avatar. On Pandora, the Na'vi can establish direct collaborative relationships with different species such as dragons and warhorses through neural connections, thereby enabling different creatures to form a unified action capability.
The research team believes that current Agentic Systems also face similar problems. LLMs possess high-level reasoning and planning capabilities but are not adept at handling raw scientific data; domain-based models possess strong professional capabilities but are unable to perform complex task reasoning.Therefore, the paper proposes the FM–LLM "Tsaheylu" interface, which essentially establishes a bidirectional communication mechanism between the language model and the domain foundation model, as shown in the figure below:
Step 1: Build EywaAgent
The first step towards the Eywa agent framework is to propose EywaAgent—a unified abstract framework that adds a language-based reasoning interface to the base model, enabling it to participate in high-level reasoning processes within agent systems.Its core idea is to establish a strong bond between the language model for executing high-level planning and control and the domain-specific basic model that provides professional capabilities.
EywaAgent combines language-based reasoning with domain-specific computation through a bidirectional communication interface called the FM-LLM "Tsaheylu" chain.This link enables the language model to be correctly configured and to call upon the underlying model for specialized computations.At the same time, the output is seamlessly reintegrated into the inference process.
The Tsaheylu interface is formalized as a pair of functions: the query compiler ϕk is responsible for translating task states into structured calls to the base model, and the response adapter ψk is responsible for converting the output of the base model into a representation in a compatible language. This communication pipeline allows the agent to dynamically decide whether to perform computation internally or delegate it to the base model, thus flexibly adapting between general inference and specialized execution.
Step 2: Extend to the Eywa agent system
After defining EywaAgent as a plug-and-play agent module, the research team further extended this paradigm to multi-agent scenarios to support more complex and heterogeneous collaborative cooperation. To this end, the paper proposes two complementary system-level abstractions:
EywaMAS
EywaAgent is extended to distributed multi-agent environments, enabling multiple specialized agents to interact and collaborate. EywaMAS's communication and state update dynamics follow the standard multi-agent system model, where agents update their state and generate messages based on received information, and interactions are controlled by the communication topology. This method supports flexible combinations of different language models, base models, and agent types.
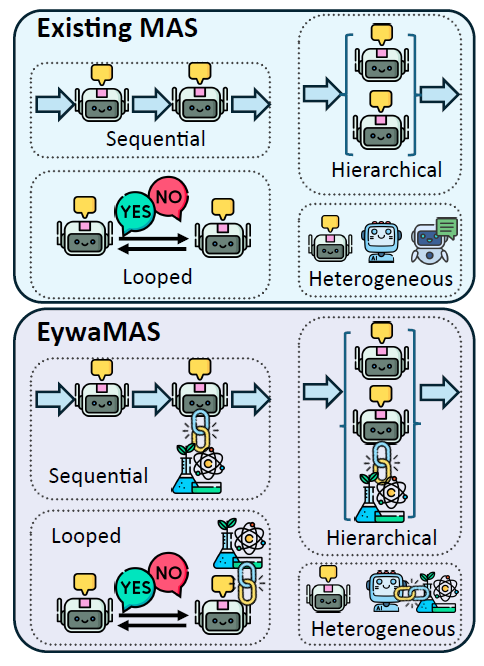
EywaMAS is an extension of existing multi-agent systems.
EywaOrchestra
To address the diverse real-world task requirements for varying agent and topology configurations, the framework introduces EywaOrchestra, a dynamic orchestration system. EywaOrchestra acts as a director, dynamically instantiating heterogeneous multi-agent systems based on the input task by selecting appropriate language models, base models, and communication topologies. This adaptive orchestration allows the system to overcome the limitations of static design, leveraging model and structural adaptability to select the optimal configuration for each task.
Eywa achieves continuous improvement in the "utility-cost" trade-off.
The research team tested all methods using EywaBench under a unified experimental protocol. The table below shows the overall performance of all methods on the EywaBench scientific task, and the experimental results reveal several key conclusions:
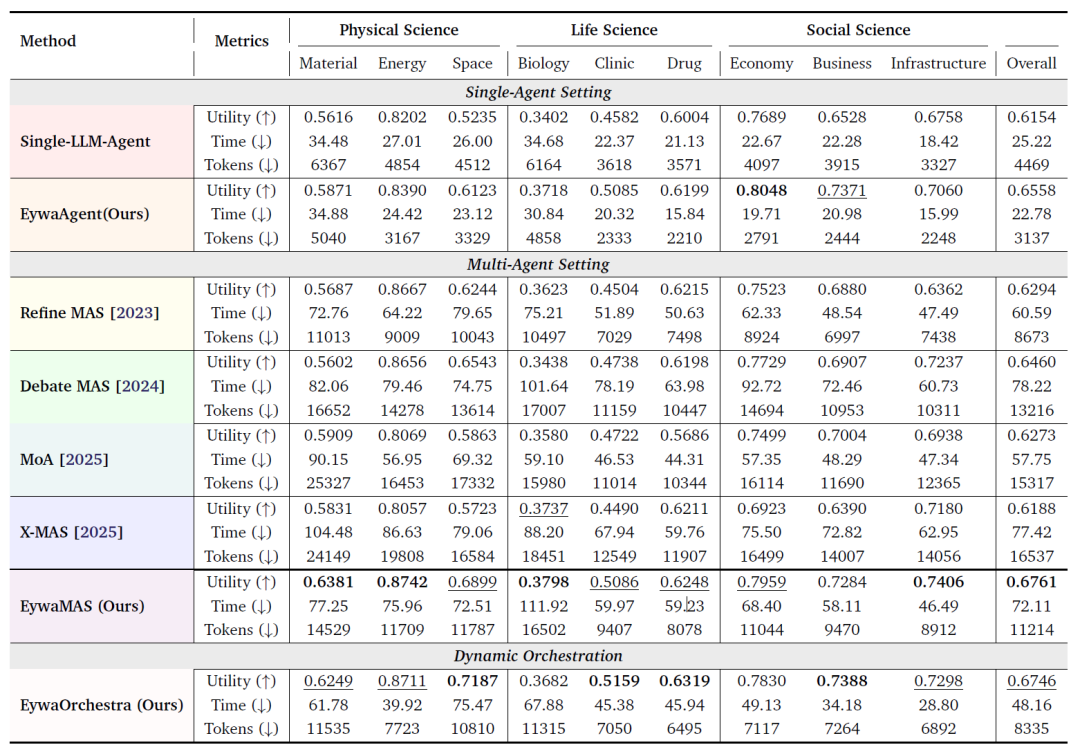
Overall performance comparison of EywaBench in science missions
Note: The table compares all methods across three dimensions: utility (↑ higher, better), inference time (↓ lower, better), and token consumption (↓ lower, better). Optimal results are indicated in bold, and second-best results are indicated by underline.
First, EywaAgent improves both system quality and efficiency under the same backbone conditions.Compared to the corresponding single-agent LLM baseline, EywaAgent improves average utility by 6.61 TP3T. Meanwhile, due to the significant delegation of computation to the domain-specific underlying model, its inference latency is significantly reduced, and token consumption is also reduced by nearly 301 TP3T.
Secondly, EywaMAS significantly outperforms traditional isomorphic multi-agent systems in scientific scenarios.Experiments show that EywaMAS achieves the highest overall utility among all methods. Compared to Refine, EywaMAS has a significant performance advantage; and compared to Debate, EywaMAS not only has higher utility but also requires fewer tokens under the same debate topology.
The third important finding is that relying solely on "heterogeneous language models" is insufficient to solve scientific tasks.The heterogeneous LLM-only MAS methods (such as MoA and X-MAS) presented in the paper did not consistently outperform the strongly homogeneous multi-agent baseline. This suggests that for scientific tasks, the truly crucial element is not "the combination of multiple different LLMs," but rather the introduction of "cross-modal heterogeneity." In other words, a financial time series model or a biological prediction model is often more valuable than adding a language model.
The paper also points out that not all domains can benefit from more complex multi-agent collaboration. In subdomains such as economics and business, single-agent EywaAgent is already highly competitive. This means that complex multi-agent topologies are not always the optimal choice. In some tasks, excessive collaboration may even incur additional overhead.
The experiment also showed that EywaOrchestra, at a lower cost and with a higher degree of automation, has achieved near-perfect performance compared to the expert-designed EywaMAS. Unlike EywaMAS, which requires manual configuration,EywaOrchestra's system architecture is built entirely automatically by conductor.Nevertheless, its utility is approaching that of manually designed systems, and even surpasses them in several subdomains. Meanwhile, the dynamic orchestration mechanism significantly reduces inference latency and token consumption. This demonstrates that task-adaptive system orchestration not only improves automation levels but also effectively optimizes inference costs.
Conclusion
Over the past few years, the main theme of the AI industry has almost always revolved around "large models"—larger parameters, longer context, and stronger reasoning capabilities. The entire industry is trying to build "a general model that can solve all problems".
However, the direction represented by Eywa illustrates that "modality-native collaboration" can effectively enhance the capabilities of multi-agent systems in scientific scenarios and provides a new development path for collaborative reasoning of heterogeneous basic models in the future. In other words, what will truly matter in the future is not "an all-powerful AI," but "an AI system capable of organizing heterogeneous experts to work collaboratively."
References:
https://arxiv.org/abs/2604.27351
https://hyper.ai/cn/papers/2604.27351








