Command Palette
Search for a command to run...
Can Emojis Control Speech Generation? Irodori-TTS Is a Japanese TTS Based on the RF-DiT Architecture; Eczema and Tinea Skin Disease Datasets: Supporting Medical Image Classification and Transfer learning.

Irodori-TTS, an open-source project released by developer Aratako in 2026, is a new generation of Japanese speech synthesis and zero-shot cloning model that combines high-fidelity audio quality with strong operability.Its core model, the Irodori-TTS-500M-v3, with 500 million parameters, is based on the continuous DACVAE latent space and RF-DiT architecture, which can stably output professional-grade audio at 48 kHz while ensuring computational efficiency.In practical applications, the model has achieved two major breakthroughs: First, it enables extremely fast "zero-sample voice cloning," where users only need to provide 3-10 seconds of reference audio to accurately replicate the target timbre without any fine-tuning; second, it enables "multi-dimensional style control," which combines innovative Emoji annotations with automatic duration prediction to achieve fine-tuning of emotions, tone, and subtle nonverbal expressions.
The HyperAI website now features "Irodori-TTS-500M-v3: Japanese Speech Synthesis and Emoji Style Control." Give it a try!
Online use:https://go.hyper.ai/pFPM5
A quick overview of updates to the hyper.ai website from June 27th to July 3rd:
* High-quality public datasets: 4
* A selection of high-quality tutorials: 12
* Community article analysis: 1 article
* Popular encyclopedia entries: 5
Visit the official website:hyper.ai
Selected public datasets
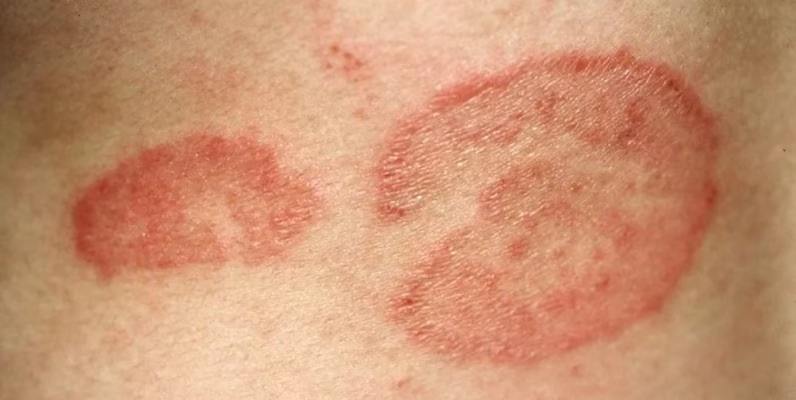
1. Eczema & Tinea Skin Disease Dataset
The Eczema and Tinea Skin Disease dataset is a medical image dataset for eczema and tinea skin diseases. It aims to provide more concise and practical data support for binary image classification tasks and is widely used in skin disease image classification, deep learning model training and evaluation, few-shot and transfer learning research, and medical image analysis teaching and experiments. The dataset contains 2,147 skin disease images.
Online use:https://go.hyper.ai/nheob
2. SASH-VPV Subcutaneous Palmar Vein Recognition Dataset
SASH-VPV is a near-infrared palm vein biometric benchmark dataset for biometric recognition and computer vision research. It aims to study the identity authentication of subcutaneous vein structures in the palm and is widely used in biometric system development, deep learning model training, and cross-session robustness research.
Online use:https://go.hyper.ai/B9xrr

3. Ultimate Anime Rating and Classification Dataset
Ultimate Anime, released in 2026, is an anime rating and classification dataset designed to support the construction of anime recommendation systems, EDA data visualization, and long-term trend and popularity quality comparison analysis in the anime industry. This dataset contains data from 3,994 anime works from the anime databases AniList and MyAnimeList, covering multi-dimensional information such as title, genre, AniList community rating, total number of episodes, broadcast status, year, synopsis, production company, original source, popularity and ranking, cover image, and broadcast time.
Online use:https://go.hyper.ai/tXtT5
4. Rose Leaf Disease Dataset
Rose Leaf Diseases is a dataset of rose leaf diseases designed to provide high-quality image data for the development and benchmarking of models for detecting rose leaf diseases, and is widely used in the construction of plant monitoring systems. The original version of this dataset contains 2,458 rose leaf images from Bangladesh, categorized into five types: black spot, downy mildew, leaf blight, healthy leaves, and insect holes.
Online use:https://go.hyper.ai/IuPUO

Selected Public Tutorials
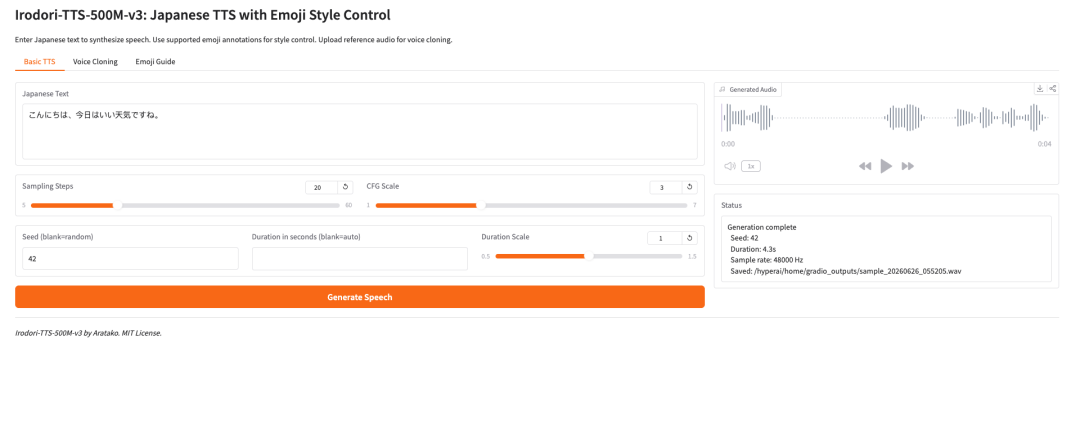
1. Irodori-TTS-500M-v3: Japanese speech synthesis and Emoji style control
The Irodori-TTS project, released by developer Aratako in May 2026, is for Japanese text-to-speech, zero-sample voice cloning, and emoji-driven speech style control. Its innovation lies in using a rectified current diffusion transformer (RF-DiT) to generate 48 kHz speech in a continuous DACVAE latent space, combined with reference audio conditions, automatic duration prediction, and emoji subtleties to control timbre, emotion, and nonverbal embellishment.
Run online:https://go.hyper.ai/pFPM5
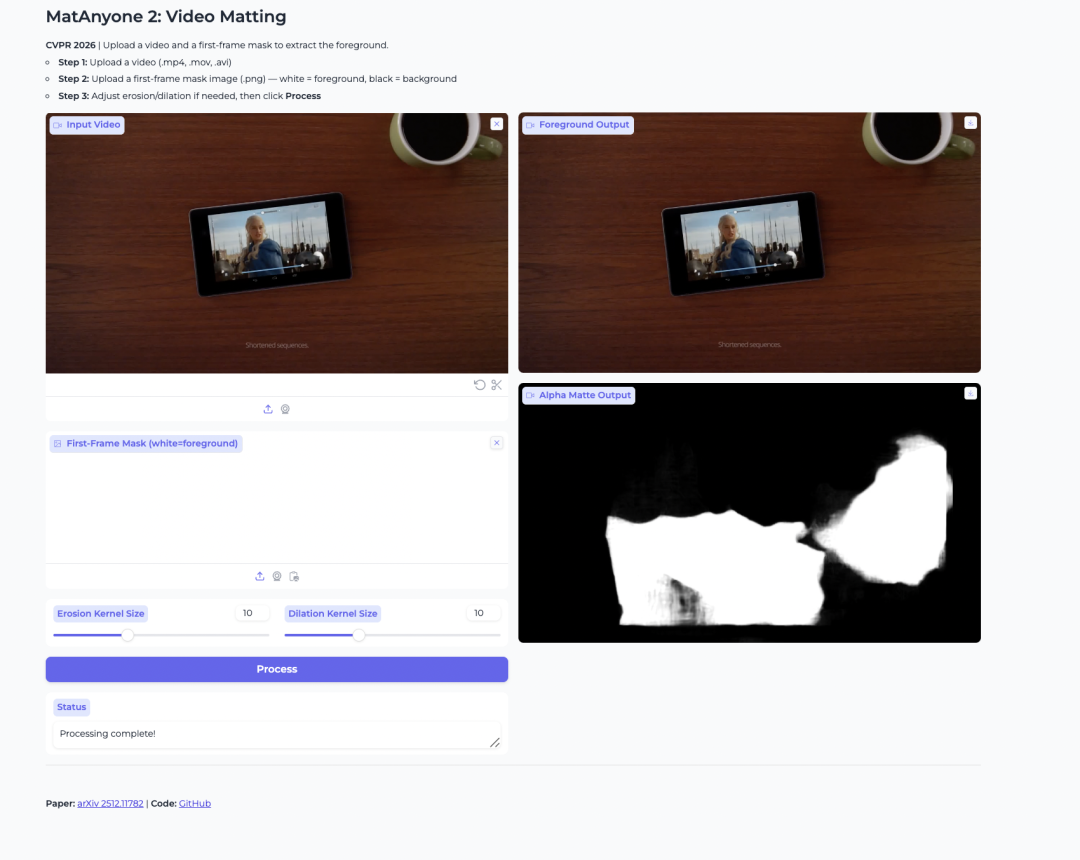
2. MatAnyone 2 video keying model
The MatAnyone 2 project, released in 2026 by Nanyang Technological University's S-Lab and SenseTime, is used for character background removal, foreground extraction, and alpha masking in videos. Its innovation relies on a self-developed quality evaluator to achieve stable background removal, eliminate image boundary artifacts, accurately preserve hair details, and support specified background removal for multiple characters.
Run online:https://go.hyper.ai/yNeFK
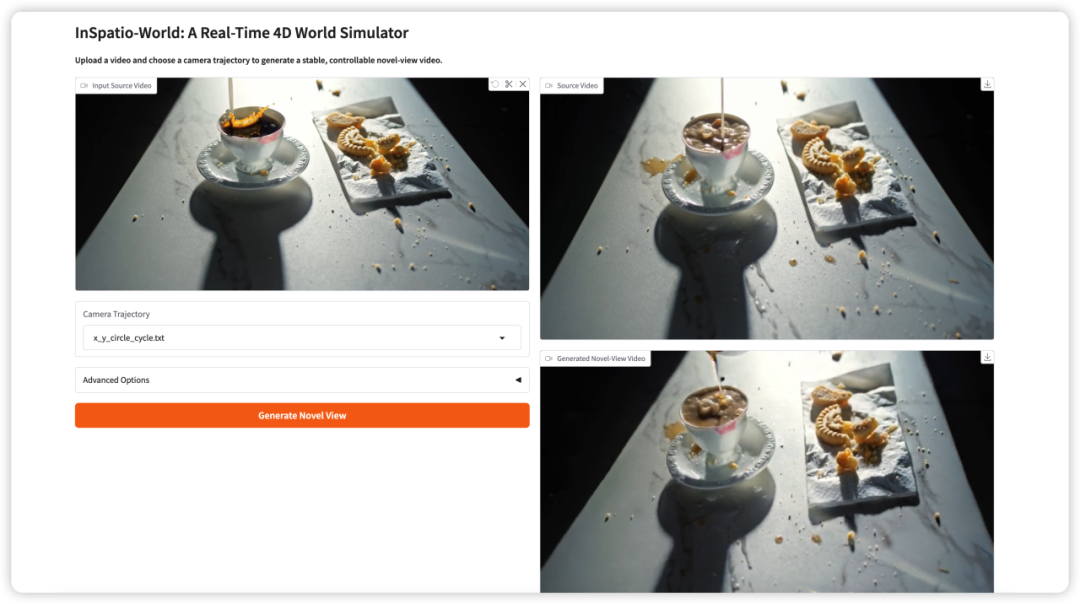
3. InSpatio-World: A Real-Time 4D World Simulator
InSpatio-World is a real-time 4D world simulator based on spatiotemporal autoregressive modeling, released by the InSpatio team on March 19, 2026. It can generate stable and controllable new perspective videos based on input videos and specified camera trajectories, achieving free control of camera paths and time-consistent world evolution.
Run online:https://go.hyper.ai/8FRRy
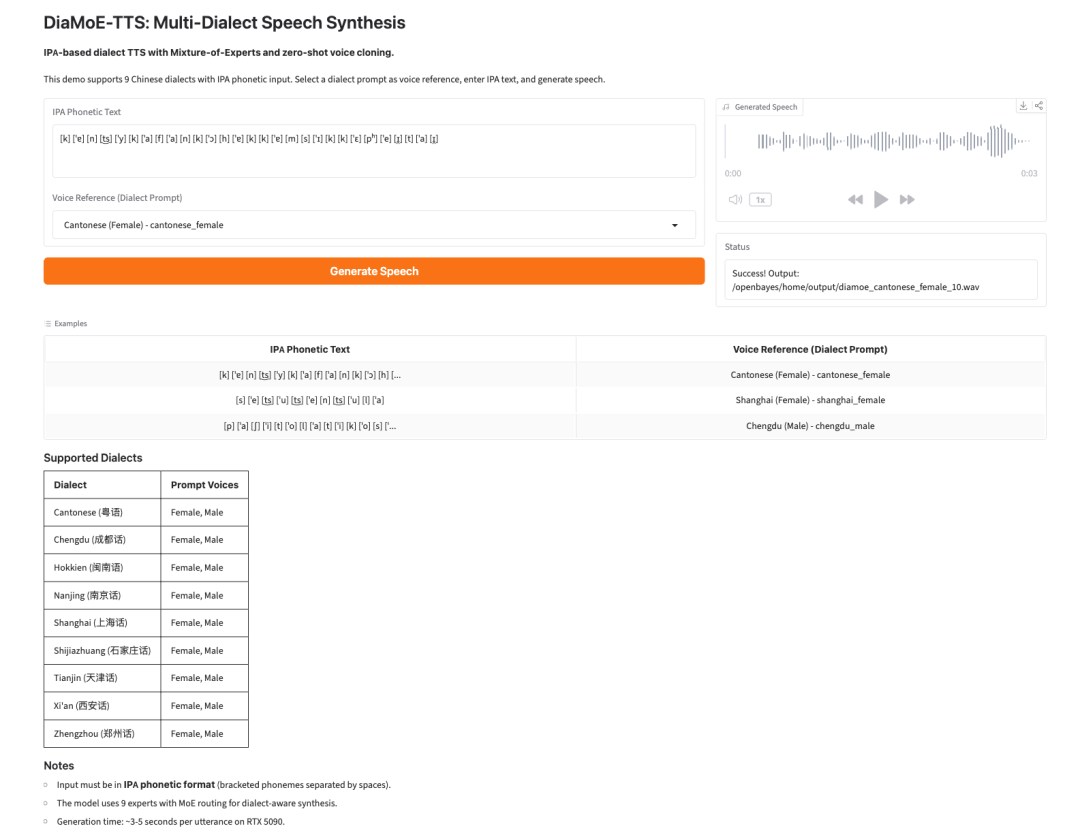
4. DiaMoE-TTS: A Tutorial on Multi-Dialect Speech Synthesis Based on IPA
The DiaMoE-TTS project, launched by Giant AI Lab in September 2025, is used for multi-dialect speech synthesis using the International Phonetic Alphabet (IPA) as a unified front end. Its innovation lies in sinking dialect-specific knowledge down to the Mixture-of-Experts (MoE) expert routing and achieving zero-sample rapid adaptation to new dialects through efficient parameter methods such as LoRA / Conditioning Adapter.
Run online:https://go.hyper.ai/wn9i5
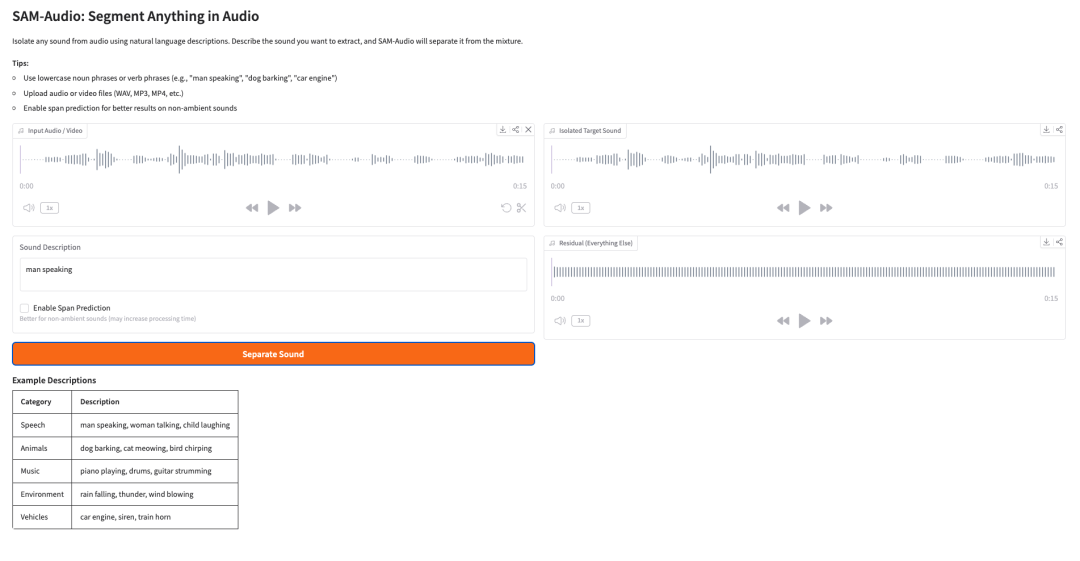
5. SAM-Audio: Separates arbitrary sounds from audio using natural language processing.
SAM-Audio is a foundational audio source separation model released by Meta in December 2025. This model is capable of separating specific sounds from complex audio mixtures using methods such as natural language descriptions, video visual cues, or time segments.
Run online:https://go.hyper.ai/svjXe
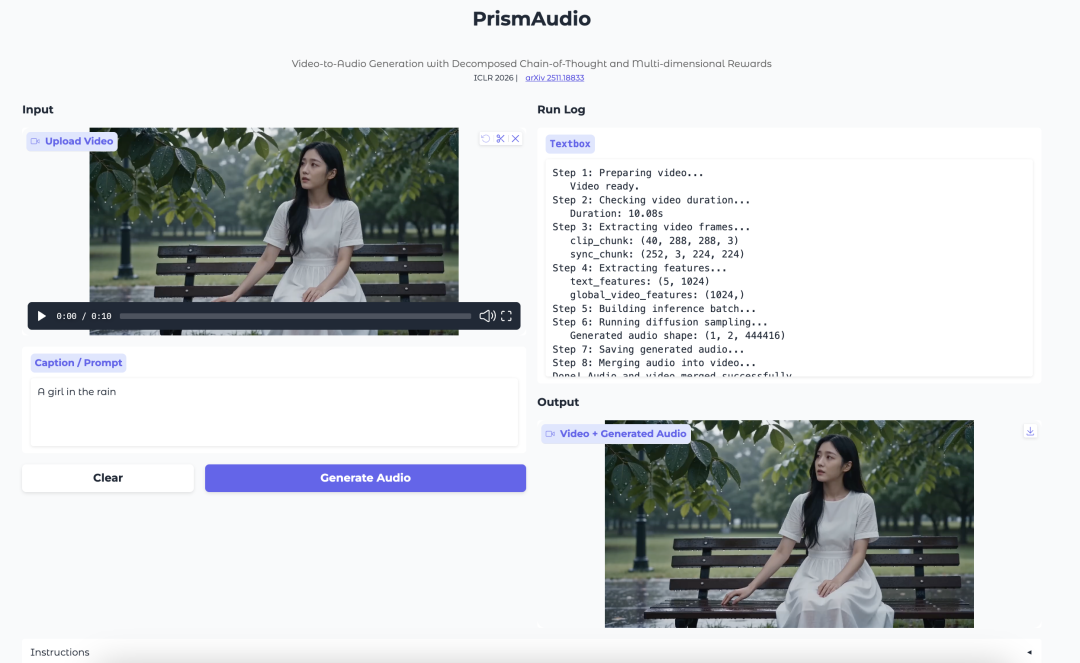
6. PrismAudio: V2A based on CoT decomposition and multidimensional rewards
PrismAudio is a video-to-audio (V2A) generation model released by Tongyi Labs in November 2025. This model is the first framework to introduce reinforcement learning into V2A generation, built upon ThinkSound's Chain of Thought (CoT) planning mechanism. The model breaks down a single reasoning process into four specialized CoT modules: semantic, temporal, aesthetic, and spatial, and equips each module with a targeted reward function, achieving multi-dimensional reinforcement learning optimization and comprehensively improving the reasoning quality across all perceptual dimensions.
Run online:https://go.hyper.ai/BRGSk
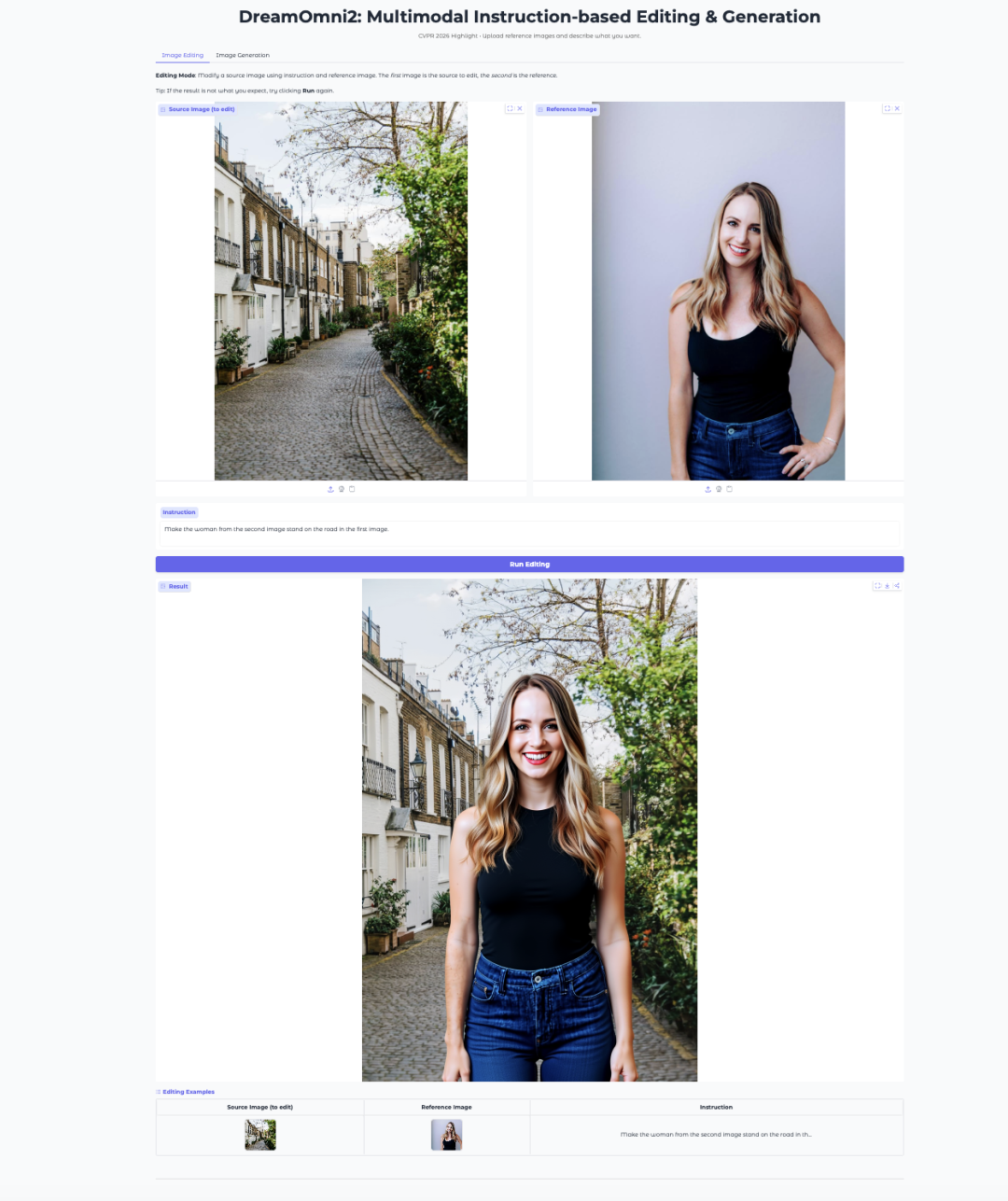
7. DreamOmni2: Multimodal instruction-driven image editing and generation
DreamOmni2 is a multimodal instruction-driven image editing and generation model released by the JIA Lab at the Chinese University of Hong Kong in October 2025. The paper has been accepted as a highlight paper at CVPR 2026. This model is based on the FLUX.1-Kontext-dev base model and combines it with a finely tuned Qwen2.5-VL-7B visual language model, supporting image editing and generation through natural language instructions combined with reference images.
Run online:https://go.hyper.ai/1iqNO
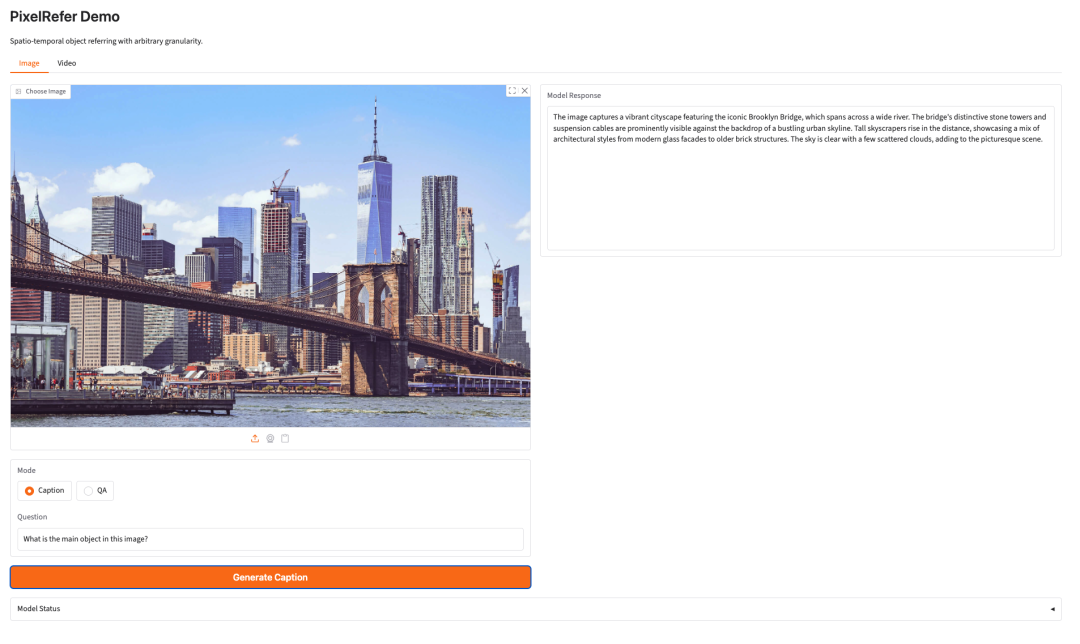
8. PixelRefer: A unified framework for fine-grained object understanding of images and videos.
Released by Alibaba DAMO Academy in October 2025, PixelRefer aims to enable fine-grained object center identification, caption generation, and question answering in images and videos. Its innovation lies in its adoption of a unified region-level multi-level linear model framework (MLLM), combined with a scale-adaptive object segmenter (SAOT) and the efficient PixelRefer-Lite object-specific framework, for constructing compact object representations.
Run online:https://go.hyper.ai/ETjjw
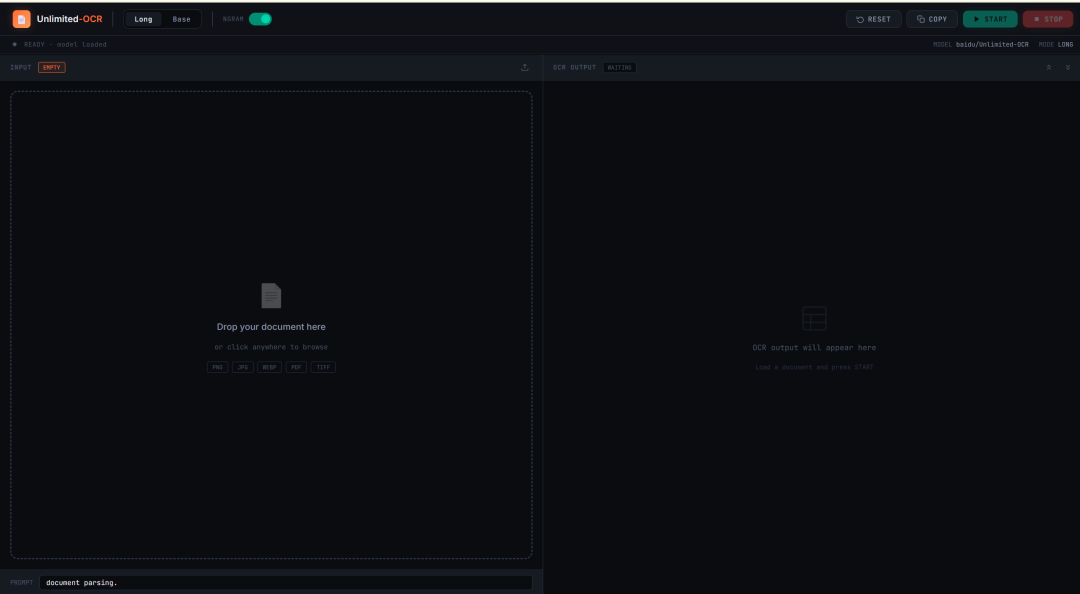
9. Unlimited-OCR: One-click deployment of long document OCR and layout parsing
The Unlimited-OCR project was released by the Baidu team in June 2026. This project targets long document OCR and layout parsing scenarios, with its core goal of maintaining stable parsing efficiency within a longer context, achieving one-shot long-horizon parsing. The model can process single document images, multi-page images, and page images converted from PDFs, making it suitable for text recognition and structured parsing of papers, reports, scanned documents, long tables, and multi-page documents.
Run online:https://go.hyper.ai/Bp69q
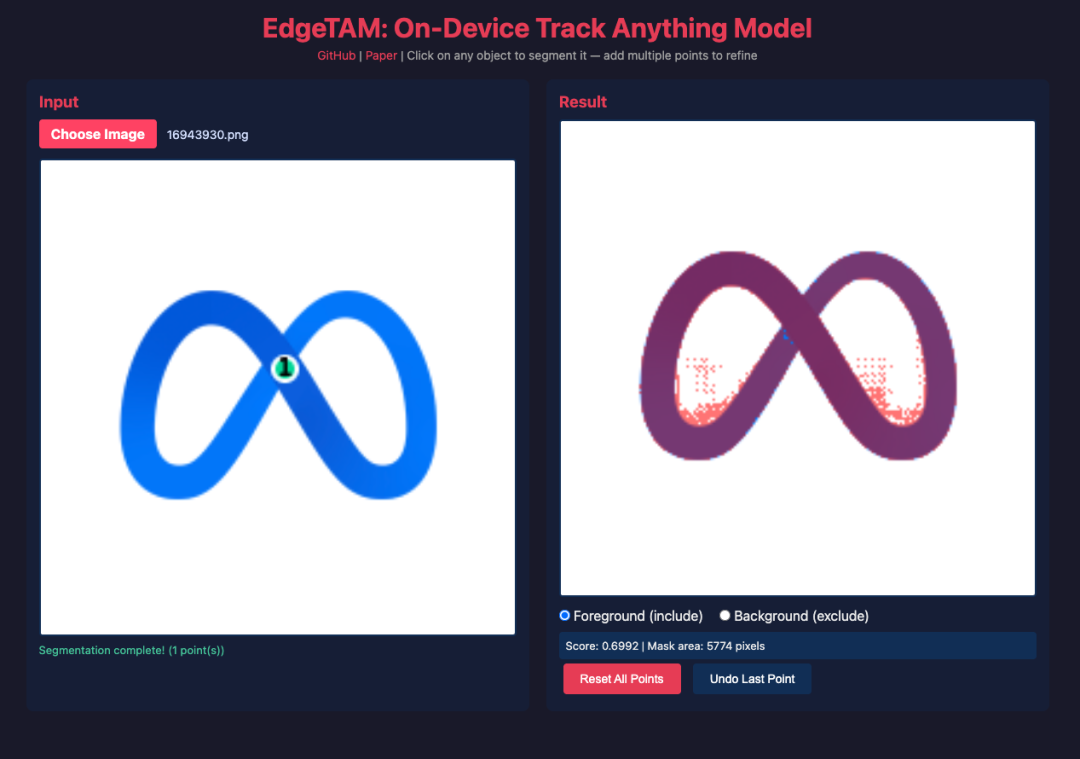
10. EdgeTAM: A cue-enabled image and video segmentation model for edge devices.
The EdgeTAM project, jointly launched by Meta Reality Labs and Nanyang Technological University's S-Lab in January 2025, is designed for cue-enabled image segmentation and video object tracking tasks on resource-constrained devices. Its core innovation is the use of a 2D spatial perceptron combined with a distillation process, which reduces the memory attention bottleneck of SAM 2 while maintaining segmentation quality, thereby enabling efficient on-device "Track Anything" interaction.
Run online:https://go.hyper.ai/yZoqO
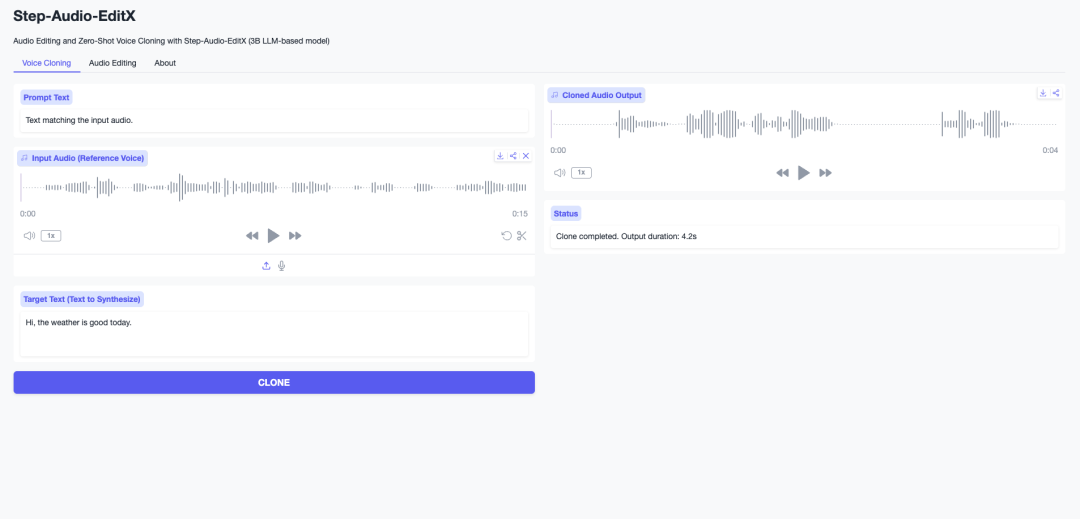
11. Step-Audio-EditX: Zero-Shot Speech Cloning and Expression-Based Audio Editing Based on 3B LLM
The Step-Audio-EditX project, released by StepFun in November 2025, targets zero-shot speech cloning and iterative, expressive audio editing tasks. Its innovation lies in combining a large language model with 3 billion parameters with reinforcement learning, making emotion, speaking style, and paralinguistic events composable discrete control terms. The model supports Mandarin, English, Sichuanese, Cantonese, Japanese, and Korean.
Run online:https://go.hyper.ai/UL7Hg
12. Nemotron 3.5 ASR Streaming 0.6B: A lightweight ASR model for streaming speech recognition
Nemotron 3.5 ASR Streaming 0.6B is an automatic speech recognition and low-latency streaming transcription model with 60 million parameters, released by NVIDIA in June 2026. This model employs a cache-aware FastConformer-RNNT architecture, which reuses encoder context during streaming inference, reducing redundant computation. It also supports language ID cueing conditions, enabling transcription across multiple language regions.
Run online:https://go.hyper.ai/mFejg
Community article interpretation
1. Meta proposes AI data scientists, and Autodata builds high-quality training/evaluation datasets.
The Meta Basic Artificial Intelligence Research Team proposed a general method called Autodata, in which an intelligent agent, acting as a "data scientist," is responsible for building and organizing data. Its behavior mimics the process of a human data scientist to generate high-quality data. This process includes not only the initial data generation but also the data analysis phase, evaluating its performance, summarizing experiences, and iteratively generating better data solutions based on these experiences.
View the full report:https://go.hyper.ai/UThkc
Popular Encyclopedia Articles
1. Large Language Model (LLM)
2. World Action Model WAM
3. Harmonic Mean
4. Virtual Screening
5. Reinforcement Learning Based on AI Feedback (RLAIF)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provides domestic accelerated download nodes for 2100+ public datasets
* Includes 700+ classic and popular online tutorials
* Analyzing 300+ AI4Science Paper Cases
* Supports searching for 700+ related terms
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








