Command Palette
Search for a command to run...
In Just 30 Minutes, the Biological multi-agent Robin Successfully Integrated 550 Research Papers, Establishing an Autonomous Research Loop and Identifying dAMD Candidate therapies.

With the continuous maturation of biological detection, perturbation experiments, and computational modeling technologies, the precision and scale of life science research are rapidly improving. However, compared with the rapidly growing data production capacity, the intelligent capabilities of the research system in knowledge integration and scientific reasoning are significantly lagging behind.A vast amount of valuable information is scattered across papers, databases, and experimental results. Relying on manual sorting is not only inefficient but also makes it difficult to connect existing conclusions across different fields.This has resulted in many validated findings failing to be translated into new research ideas or clinical protocols in a timely manner.
This problem of "knowledge fragmentation" is particularly evident in the field of "drug repurposing." Whether it was the later discovery of dabrafenib's otoprotective effects or the expansion of ketamine's new therapeutic value, both experienced translational delays of several years or even decades, reflecting the current bottlenecks in knowledge discovery and integration in the scientific research process.
In recent years, Large Language Models (LLMs), with their retrieval, inductive, and logical reasoning capabilities developed through training on massive corpora, have begun to demonstrate their potential in life science research. By combining fine-tuning, Retrieval-Enhanced Generation (RAG), and multi-agent collaboration techniques, these models have achieved or even surpassed human performance in individual tasks such as literature analysis, drug prediction, and scientific hypothesis generation. However,Most existing AI tools still only cover certain parts of the research process and cannot truly connect the entire chain of "hypothesis generation—experimental design—data analysis—result iteration".Therefore, truly closed-loop intelligent scientific research cannot yet be achieved.
To address this issue, a joint team from FutureHouse in San Francisco, the University of Oxford, and Fordham University proposed the Robin biological multi-agent system.This is the first biomedical intelligent system that simultaneously integrates the capabilities of scientific hypothesis generation and experimental data analysis, and achieves a continuous closed-loop workflow.
Robin, through the collaborative operation of a literature retrieval agent and a data analysis agent, can semi-autonomously complete disease mechanism analysis, candidate drug screening, experimental review, and hypothesis iteration. The research team used dry age-related macular degeneration (dAMD), a disease with limited treatment options and urgent clinical needs, as an application scenario to validate Robin's capabilities in intelligent drug screening, providing a new practical paradigm for AI-driven new drug development and drug repurposing.
The relevant research findings, titled "A multi-agent system for automating scientific discovery," have been published in Nature.
Research highlights:
* The Robin system is the first to integrate literature hypothesis generation and biological experimental data analysis into a continuous closed-loop workflow.
* Robin is adaptable to multidisciplinary scientific research findings. In the field of therapeutic drug development, simply input the name of the target disease, and the system can automatically screen key pathological mechanisms of the disease, match in vitro experimental models, propose candidate drugs, complete experimental data analysis, and iteratively update candidate molecules.
Using dAMD as a research example, Robin first proposed a novel strategy for treating dry macular degeneration by using ROCK inhibitors to enhance RPE phagocytic function.

View the paper:
https://www.nature.com/articles/s41586-026-10652-y
Datasets: Covering public literature, bioinformatics benchmarks, and experimental data
This study constructed a three-tiered data system consisting of publicly available literature data, general bioinformatics benchmark data, and self-experimental data.It covers various types of tasks, including literature texts, bioinformatics analysis tasks, cell detection, and transcriptome sequencing.It basically covers the core data scenarios in the AI drug development process.
First, the researchers integrated 551 Chinese and English scientific research papers related to dAMD as the knowledge base for the system to generate scientific hypotheses.This includes 151 studies on disease mechanisms and 400 research papers on the phagocytic function of retinal pigment epithelial cells and its association with diseases.This literature not only serves to clarify disease mechanisms but also provides a theoretical basis for screening in vitro experimental models and generating candidate drugs for drug repurposing. It is the core source for Robin's knowledge mining efforts.
Secondly, the researchers used the general bioinformatics benchmark dataset BixBench to quantitatively evaluate the system's data analysis capabilities.The study selected 170 test questions related to drug development.It covers various task types, including transcriptome analysis, genomics, functional enrichment analysis, sequence analysis, and statistical testing. All questions are accompanied by standardized data packages, standard answers, and distractors, which can be used to systematically evaluate the adaptability and stability of agents in real-world bioinformatics scenarios.
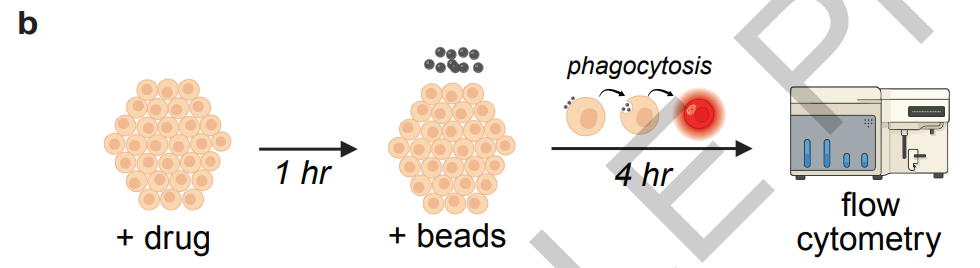
also,The researchers also constructed their own experimental dataset to provide real-world support for model iteration and experimental verification.The data includes flow cytometry results of ARPE-19 cells and human primary retinal pigment epithelial stem cells, RNA-seq transcriptome data after multiple drug treatments, and results of cytotoxicity, immunocytochemical staining, and VEGF enzyme-linked immunosorbent assay. The human cell samples were obtained from the New York Vision Repair Eye Bank, and all were retinal pigment epithelial stem cells from donors aged 60 years or older without any eye diseases, thus ensuring the authenticity and clinical reference value of the experimental data.
Robin: Multi-Agent Systems for Biomedical Science Discovery
Robin, based on the Aviary framework and running in the Jupyter Notebook environment, differs from traditional research AI tools that only perform single tasks. It is the first to achieve a continuous closed-loop workflow of "scientific hypothesis generation—experimental analysis—result feedback—hypothesis iteration."It can semi-autonomously complete the entire scientific research process, including disease mechanism research, candidate drug screening, and experimental data analysis.
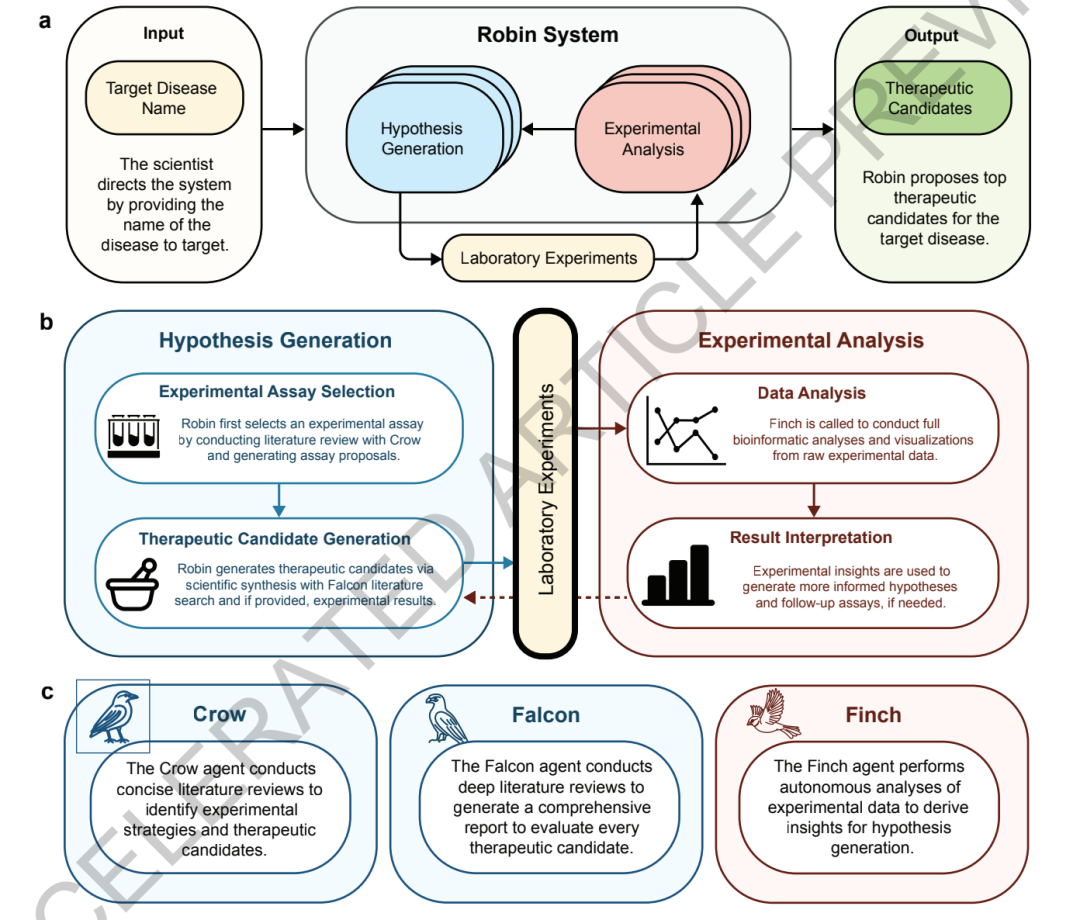
The system adopts a "three-agent" core architecture, consisting of two document agents and one data analysis agent working together.
in,The two document intelligence agents, Crow and Falcon, are primarily responsible for document knowledge mining and scientific hypothesis generation.Both are based on the OpenAI o4-mini model. Crow is responsible for disease-related literature retrieval, pathological mechanism analysis, experimental model screening, and preliminary drug candidate discovery. It can systematically integrate fragmented research and extract key scientific conclusions. Falcon is responsible for in-depth validation and optimization. It further analyzes the pharmacological mechanisms, theoretical basis, and potential limitations of the candidate solutions proposed by Crow, and corrects false citations in the literature, thereby reducing the "illusion" problem of large models.
The third core module, Finch, is an intelligent agent specifically designed for analyzing biological experimental data.Unlike traditional tools that rely on fixed analysis scripts, Finch employs generative inference, generating and executing Python or R code in real time based on experimental data characteristics. This allows it to adaptively perform tasks such as flow cytometry analysis, RNA-seq differential expression analysis, and gene function enrichment. This means the system is no longer limited to predefined analysis workflows but can dynamically adjust its analysis strategies, much like a researcher would.
To reduce the randomness of large models in data analysis,Robin further designed a "multi-trajectory analysis + consensus integration" mechanism.The system can simultaneously launch 8 independent Finch analysis trajectories. Each trajectory independently completes code generation, data analysis, and result output. Finally, the conclusions of multiple trajectories are integrated through meta-analysis, thereby reducing the deviation caused by fluctuations and parameter differences in single-round analysis and improving the stability of the results.
In terms of evaluation mechanisms, Robin also introduced a two-tiered large-scale model review system.The system uses Anthropic's Claude 3.7 Sonnet as the core review model, and combines it with Google Gemini 2.5 Pro to align with domain expert preferences.Candidate mechanisms, experimental models, and drug regimens are evaluated hierarchically through pairwise comparisons and tournament ranking. When the number of regimens to be evaluated is small, full pairing is used; when the number is large, random sampling is used for comparison. The Bradley-Terry-Luce model is used to complete the weighted ranking, ensuring evaluation accuracy while controlling computational costs.
Furthermore, to ensure the reproducibility of the analysis process, all Finch tasks run in independent Docker container environments and come pre-installed with a complete bioinformatics toolchain. The research team also optimized and simplified the workflow through multiple rounds of Prompt engineering, compressing the complex original process into a stable and easy-to-use Jupyter workflow, further enhancing the system's operability in research scenarios.
Robin discovered that lipasudil increases phagocytic ability by 1.89 times.
This study focuses on dAMD as its core application scenario and designs multiple sets of validation experiments around Robin's hypothesis generation capabilities, data analysis capabilities, architectural effectiveness, and real drug development efficiency.
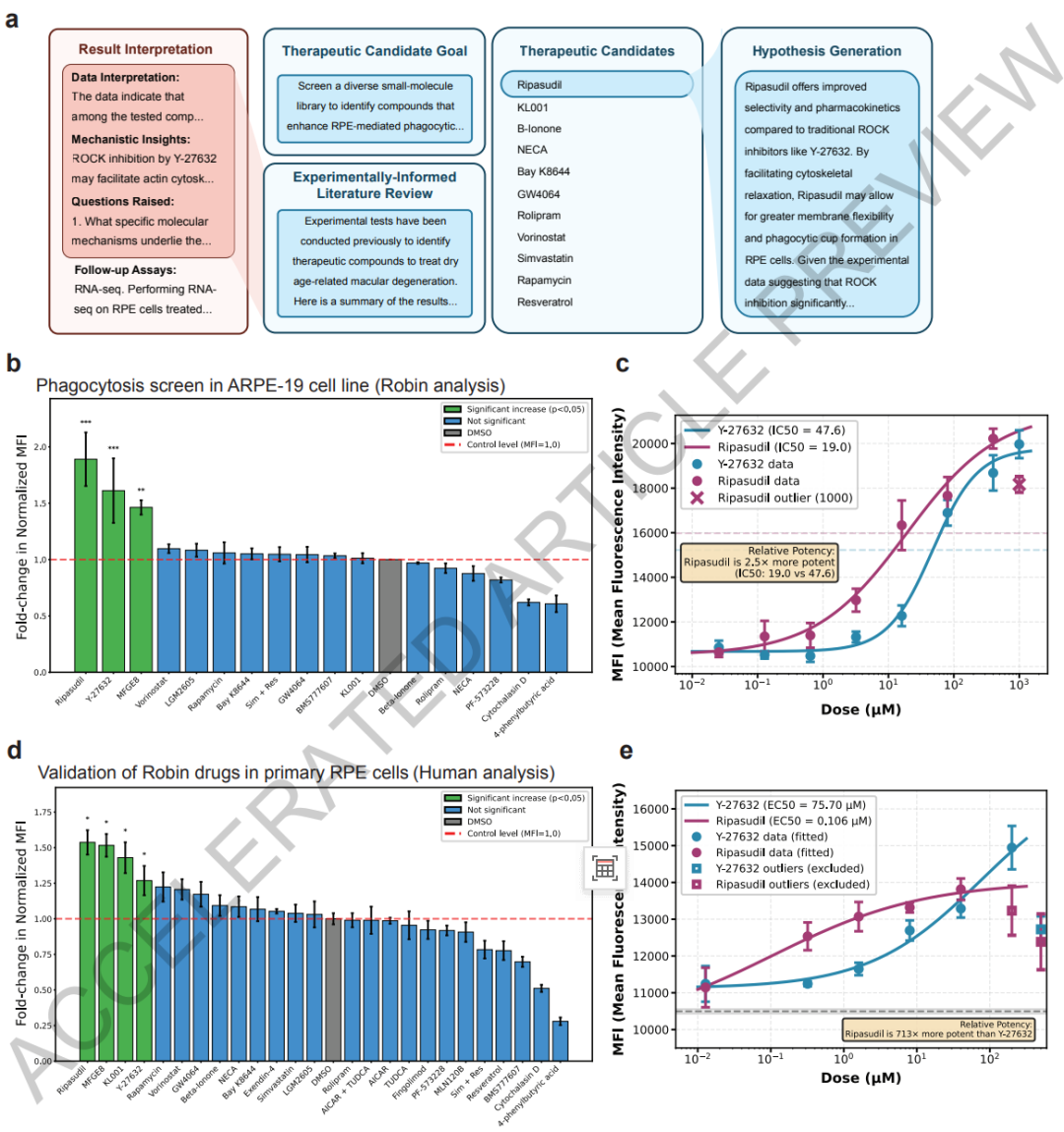
The core experiments focus on candidate drug screening and mechanism of action verification. Robin first identified 10 key pathogenic mechanisms of dAMD through literature analysis and determined "enhancing the phagocytic function of retinal pigment epithelial cells" as the core treatment direction.In the first round of screening, the system proposed 30 candidate drugs. Researchers selected exenatide, fingolimod, Y-27632 and other drugs from them to conduct experiments, and used the known effective drug MFGE8 as a positive control.
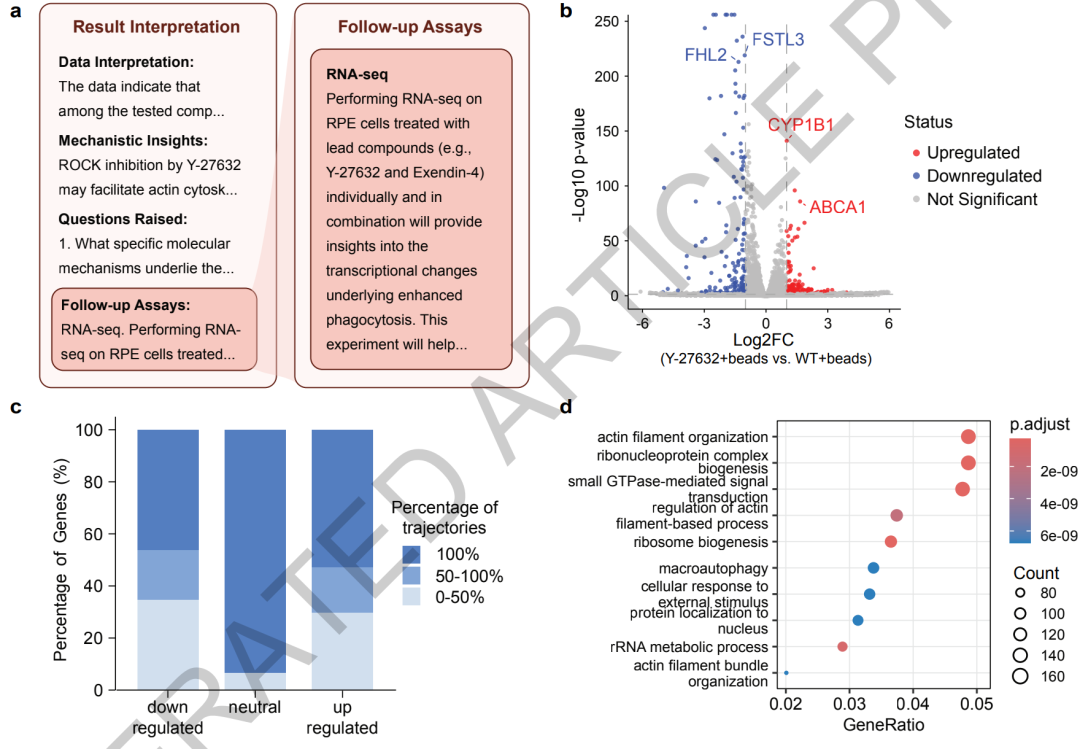
Subsequently, Robin independently proposed a transcriptome sequencing experimental protocol, and Finch completed the data analysis. The results showed that Y-27632 can achieve transcriptome reprogramming of retinal pigment epithelial cells by regulating the actin cytoskeleton, autophagy pathway, and the key lipid transport gene ABCA1, revealing a previously unknown mechanism of action.
To further enhance the clinical relevance of drug screening, the study subsequently conducted a second round of drug iteration experiments. Robin added 10 new drug candidates and found that the marketed glaucoma drug ribasudil was more effective than Y-27632, increasing cellular phagocytosis capacity by approximately 1.89 times.The research team then used human primary retinal pigment epithelial stem cells, which are closer to the real physiological environment, for rescreening. The results once again verified the dose-dependent effects of ribasudil and Y-27632, and showed that ribasudil does not have obvious cytotoxicity and has high potential for clinical translation.
Notably, Robin also discovered that the circadian rhythm regulator KL001 also has the potential to enhance phagocytic function, providing a new research direction for the treatment of dAMD. Subsequent transcriptome validation further confirmed that ripasudil can stably upregulate ABCA1 expression, thus clarifying its core pathway of action.
In a comparison with competing general AI research systems, the research team used the same instructions to call the OpenAI Deep Research Agent. None of the 17 candidate drugs generated showed phagocytic enhancement activity, nor did they identify the core mechanism of ROCK inhibition, further highlighting Robin's adaptability advantages in specific biomedical scenarios.
Furthermore, in the BixBench benchmark test,The overall accuracy of the Finch agent reached 22.8±1.7%, which is significantly higher than the 1.6±1.2% of the pure large language model.The accuracy rates for biostatistics tasks reached 47.9 ± 1.51 TP3T, basic flow cytometry analysis reached 1001 TP3T, and RNA-seq analysis reached 861 TP3T. These results indicate that the specially designed research agent framework can significantly improve the practical capabilities of general-purpose large models in biological data analysis; however, there is still room for further optimization in complex, multi-step bioinformatics tasks.
Robin also demonstrates a clear advantage in terms of efficiency and cost. Research statistics show that the average cost of a single complete research workflow using the system is only about $10.76; meanwhile,Robin was able to complete the integrated analysis of 551 documents within 30 minutes.The same amount of work would typically require more than 800 hours to process manually. Overall, the system completes a single round of the research process in less than 2 hours, which is about 200 times more efficient than traditional manual research processes.
Final Thoughts
Robin's significance extends beyond the discovery of several potential drug candidates. More importantly, it demonstrates for the first time the potential for artificial intelligence to evolve from an "assistive tool" to a "semi-autonomous research system" in the life sciences. Of course, such systems are still far from being truly "autonomous scientists." Issues such as complex experimental design, understanding biological mechanisms across scales, and the interpretability of results still heavily rely on the participation of domain experts. However, Robin's emergence at least shows that AI is no longer merely a tool to help researchers "improve efficiency," but is gradually acquiring the ability to participate in scientific discovery itself.








