HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
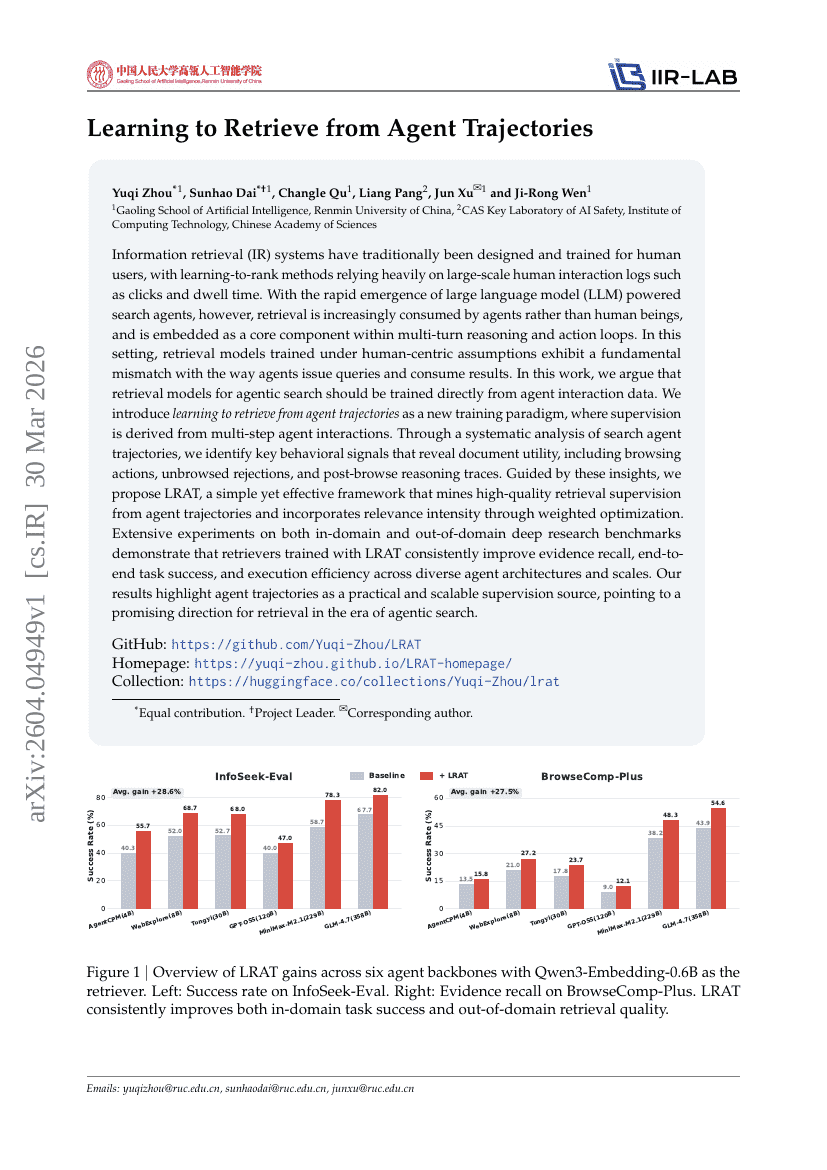
Learning to Retrieve from Agent Trajectories


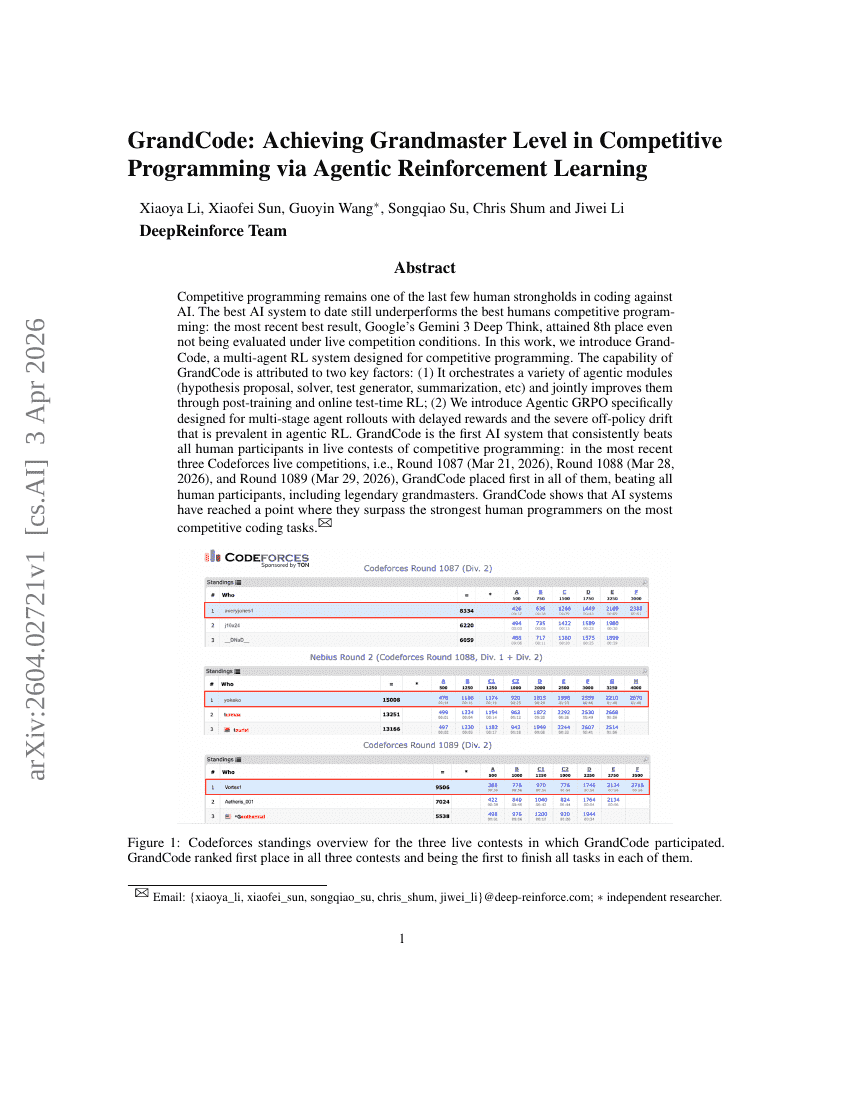
























ACES: Who Tests the Tests? Leave-One-Out AUC Consistency for Code Generation
Learning to Retrieve from Agent Trajectories
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
GrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
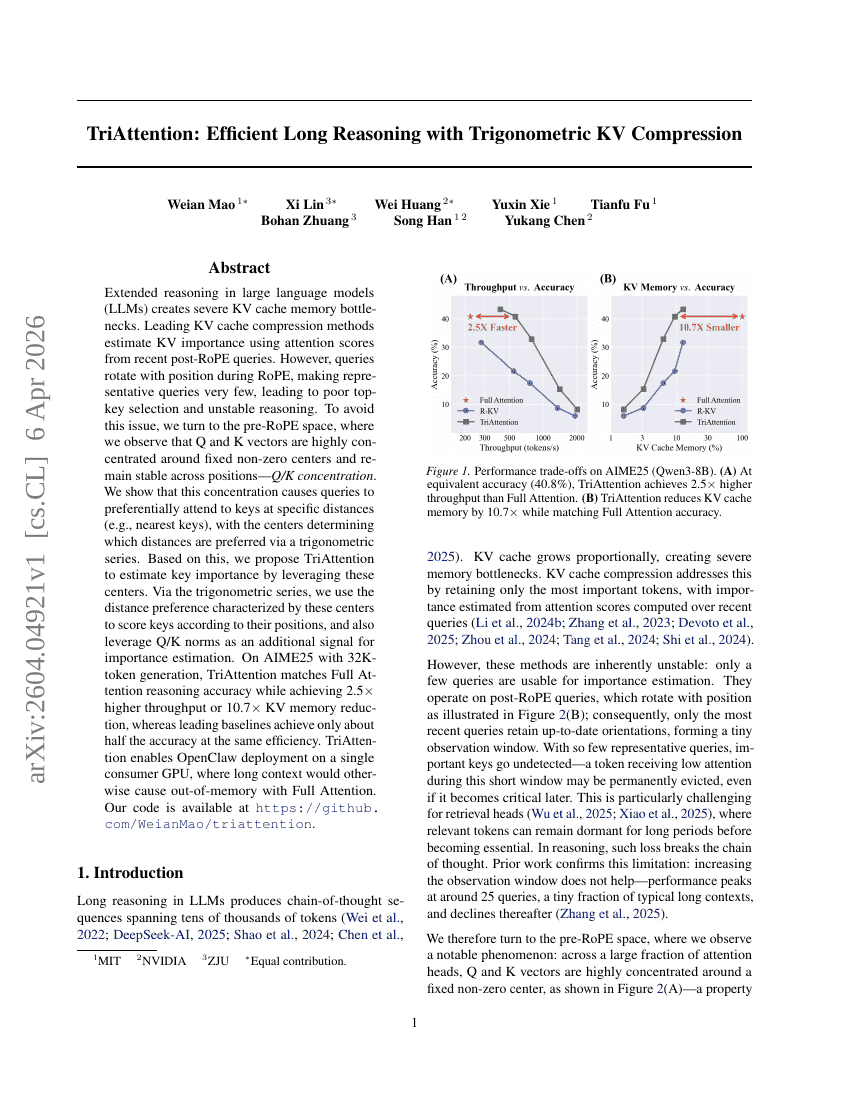
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Adam's Law: Textual Frequency Law on Large Language Models
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
WAXAL: A Large-Scale Multilingual African Language Speech Corpus
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
Token Warping Helps MLLMs Look from Nearby Viewpoints
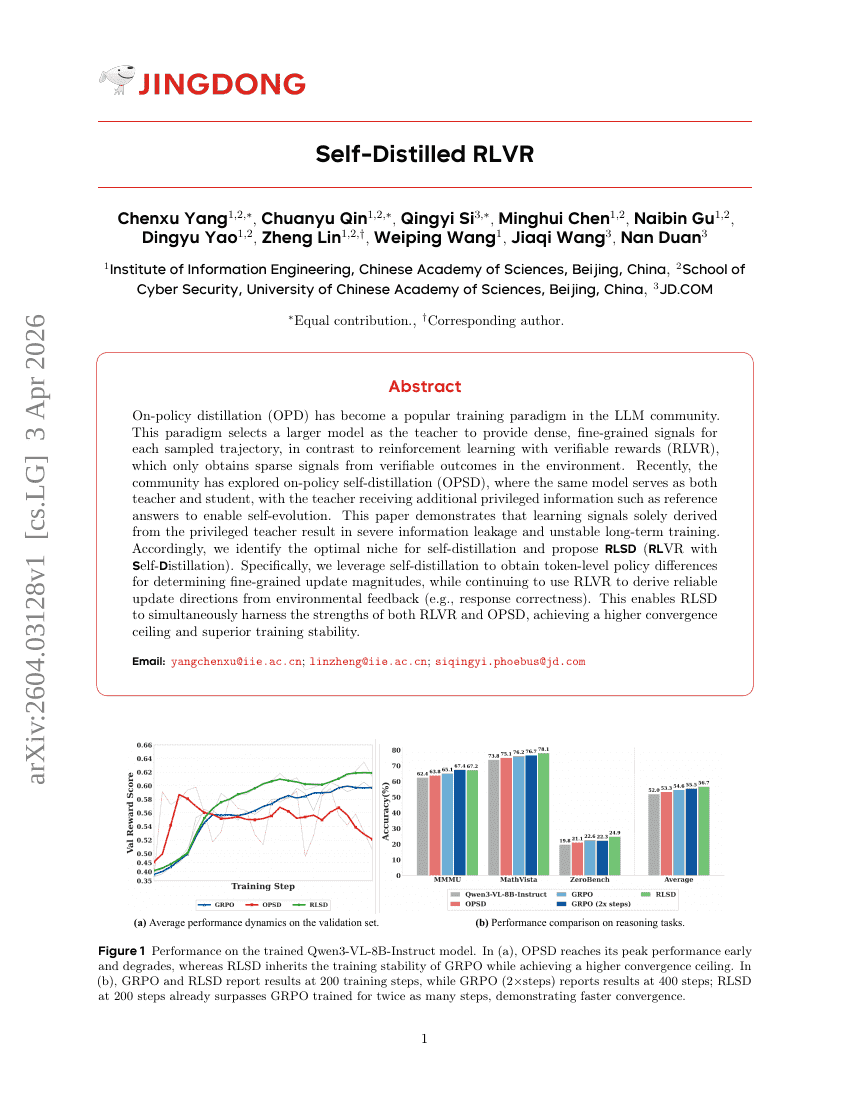
Self-Distilled RLVR
A Simple Baseline for Streaming Video Understanding
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Steerable Visual Representations
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Generative World Renderer
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
QuitoBench: A High-Quality Open Time Series Forecasting Benchmark
Vision2Web: A Hierarchical Benchmark for Visual Website Development with Agent Verification
ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Terminal Agents Suffice for Enterprise Automation
ClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
Cheap Bootstrap for Fast Uncertainty Quantification of Stochastic Gradient Descent
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
GrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Adam's Law: Textual Frequency Law on Large Language Models
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
WAXAL: A Large-Scale Multilingual African Language Speech Corpus
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
Token Warping Helps MLLMs Look from Nearby Viewpoints
Self-Distilled RLVR
A Simple Baseline for Streaming Video Understanding
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Steerable Visual Representations
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Generative World Renderer
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
QuitoBench: A High-Quality Open Time Series Forecasting Benchmark
Vision2Web: A Hierarchical Benchmark for Visual Website Development with Agent Verification
ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Terminal Agents Suffice for Enterprise Automation
ClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
Cheap Bootstrap for Fast Uncertainty Quantification of Stochastic Gradient Descent