HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness

GameplayQA: A Benchmarking Framework for Decision-Dense POV-Synced Multi-Video Understanding of 3D Virtual Agents




























AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness
GameplayQA: A Benchmarking Framework for Decision-Dense POV-Synced Multi-Video Understanding of 3D Virtual Agents
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
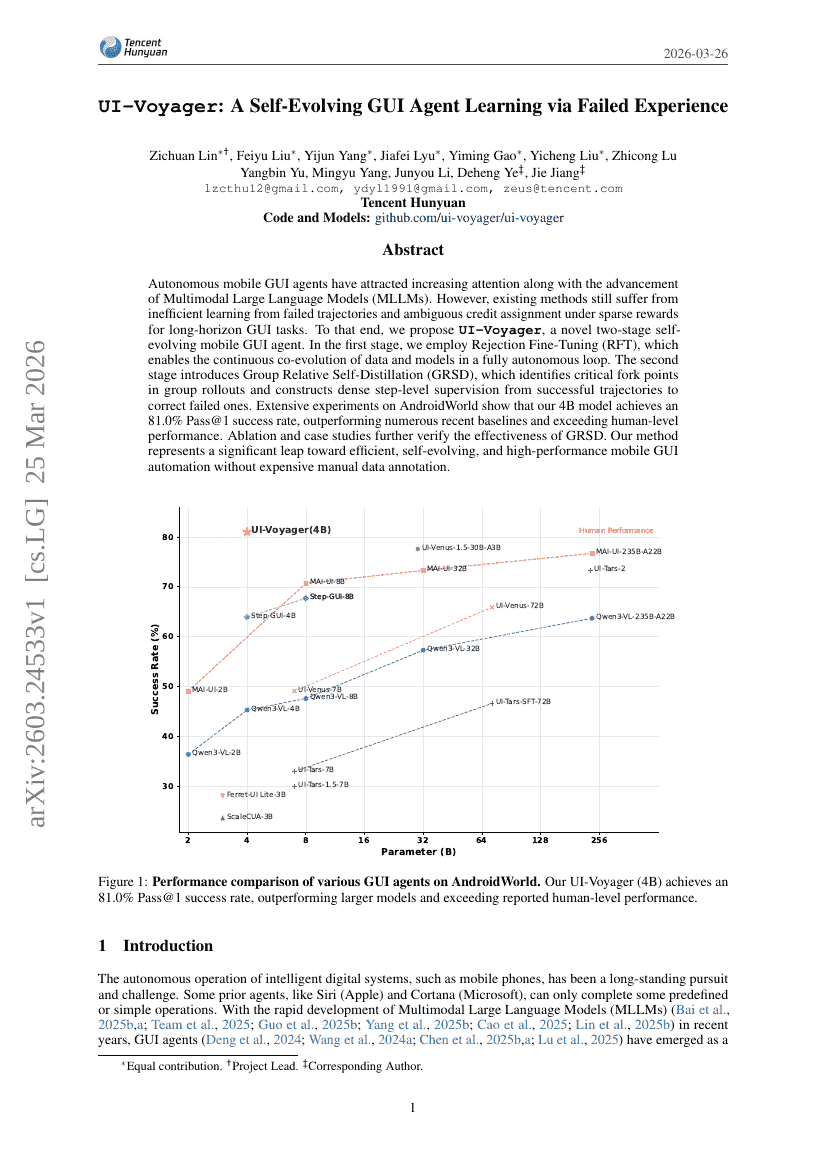
UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
From Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
PEARL: Personalized Streaming Video Understanding Model
WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
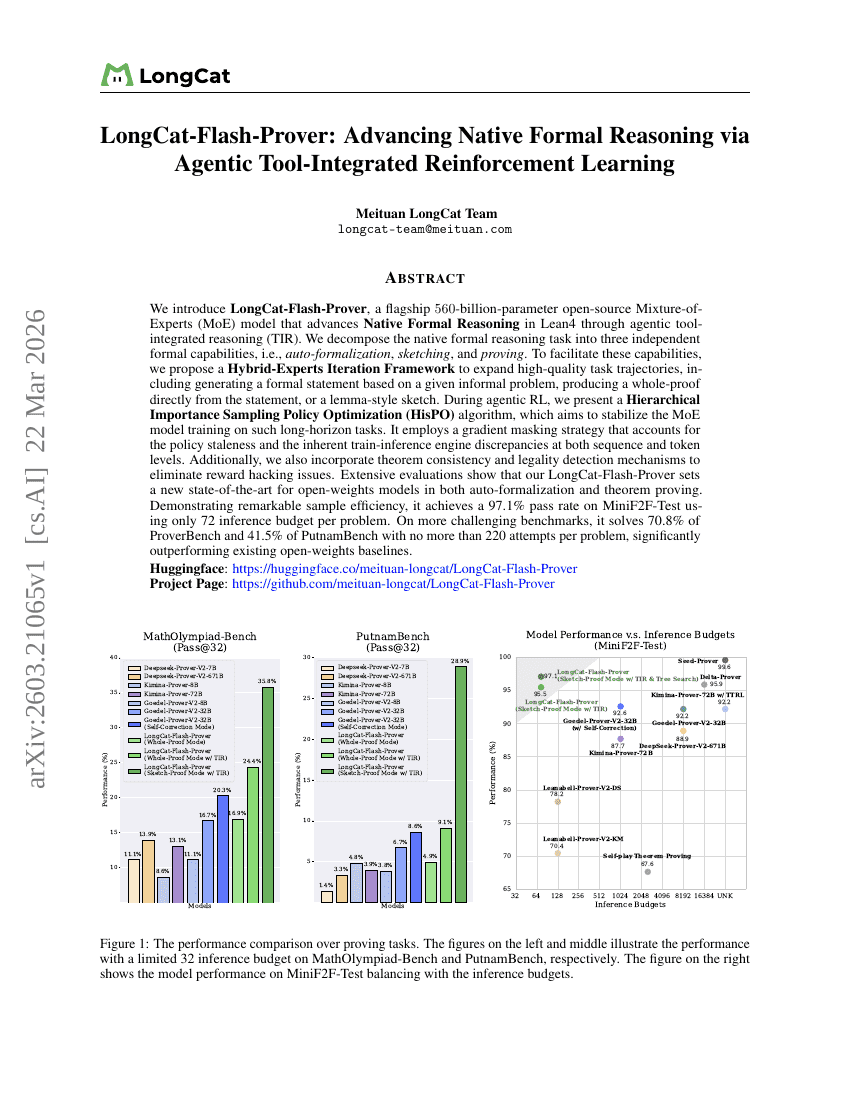
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
PrismAudio: Decomposed Chain-of-Thoughts and Multi-dimensional Rewards for Video-to-Audio Generation
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
From Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
PEARL: Personalized Streaming Video Understanding Model
WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
PrismAudio: Decomposed Chain-of-Thoughts and Multi-dimensional Rewards for Video-to-Audio Generation
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
The Y-Combinator for LLMs: Solving Long-Context Rot with λ-Calculus
ProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer